CROSSFORMER: TRANSFORMER UTILIZING CROSSDIMENSION DEPENDENCY FOR MULTIVARIATE TIME SERIES FORECASTIN

本论文Published as a conference paper at ICLR 2023
和Transformer做时间序列相关的论文。这篇文章提出了CrossFrormer,用来解决多元时间序列问题。CrossFromer主要的切入点在于,之前的Transformer更多的考虑是如何通过时间维度attention建立时序上的关系,而缺少面对多元时间序列预测时,对不同变量关系之间的刻画。这篇文章填补了这个空白,提出了时间维度、变量维度两阶段attention,尤其是在变量维度,提出了一种高效的路由attention机制。
下载地址:https://openreview.net/pdf?id=vSVLM2j9eie
framework
Motivation
之前用Transformer解决时间序列问题的工作,大多集中在如何更合理的进行时间维度的关系建模上。利用时间维度的自注意力机制,建立不同时间步之间的关系。
而在多元时间序列预测中,各个变量之间的关系也很重要。之前的解法,主要是将每个时间步的多元变量压缩成一个embedding(如下图中的b),再进行时间维度的attention。这种方法的问题是缺少对不同变量之间关系的建模。因为时间序列不同变量的含义是不同的,每个变量应该在哪个时间片段进行对齐无法提前预知,直接每个时间步融合的方式显然太粗糙了。
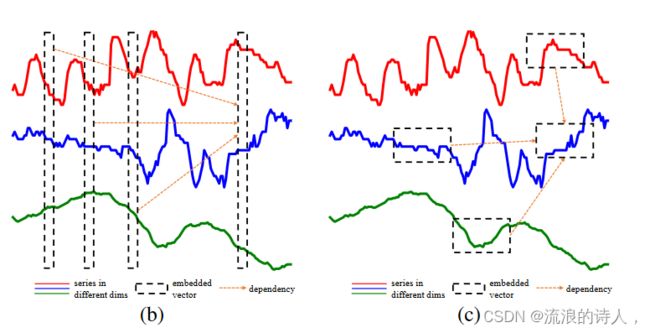
基于以上考虑,本文对Transformer在多元时间序列预测的应用中进行了改造,将多元时间序列转换成patch,增加了变量维度之间的attention(如上图中的c),并考虑到效率问题,提出了基于路由的变量间attention机制。
模型结构概览
模型整体包含3个主要模块:
Dimension-Segment-Wise Embedding:这个模块的主要目标是将时间序列分成patch形式,得到patch embedding,作为后续模型的输入,将每个变量的时间序列按照一定的窗口与划分成多个区块,每个区块通过全连接进行映射,本文不再详细介绍;
Two-Stage Attention Layer:两阶段的attention,第一阶段在时间维度进行attention,第二阶段在多变量之间进行attention;
Hierarchical Encoder-Decoder:采用不同的patch尺寸和划分方式,形成层次的编码和解码结构。
两阶段Attention机制
两阶段Attention指的是时间维度attention和空间维度attention。输入先过一层时间维度attention,独立的进行每个序列时序上的建模;然后徐再输入到一层空间维度attention,对齐不同变量各个时间步的编码,这部分也是本文的核心点。
时间维度attention就是正常的Transformer模型,每个变量的时间序列转换成patch后,输入到Transformer中,输出self-attention后每个变量每个patch的表示
空间维度的attention,指的是对齐不同变量的各个时间步。如下图,空间维度的对齐,目的是在变量之间寻找两两时间步的关系,这样能深入刻画一个变量对另一个变量的影响。具体的做法为,在变量维度做self-attention,如下面的图b。
但是这种歌做法会导致运算复杂度较高,因此本文提出了使用路由的方式,增加几个中间向量,将变量各个时间步的信息先利用一层attention汇聚到中间向量上,再利用中间向量和原序列做self-attention,中间向量可以看成是一种路由,也有点像胶囊网络的思路,先对输入信息做个聚类,再进一步分发,起到了降低运算量的作用。上图的图c为示意图,具体的计算公式如下:

其中,R是中间向量,B是序列和中间向量进行self-attention后的结果,这个结果会和序列再次做self-attention,得到最终的变量间信息交互的编码结果。
层次Encoder-Decoder
本文提出的层次Encoder-Decoder架构图下图所示,它基于上面提到的两阶段attention网络,对输入进行了不同尺寸的patch生成。例如下面图中,序列从上到下被分成了2个、4个、8个等不同的patch,每层的每个patch所包含的窗口长度不同。模型的输入最开始是细粒度patch,随着层数增加逐渐聚合成更粗粒度的patch。这种形式可以让模型从不同的粒度提取信息,也有点像空洞卷积的架构。Decoder会利用不同层次的编码进行预测,各层的预测结果加和到一起,得到最终的预测结果。

ABSTRACT
最近,人们提出了许多用于多变量时间序列(MTS)预测的深度模型。其中,基于 Transformer 的模型因能捕捉长期依赖性而显示出巨大潜力。然而,现有的基于 Transformer 的模型主要侧重于时间依赖性(跨时依赖性)建模,但往往忽略了不同变量之间的依赖性(跨维依赖性),而这对于 MTS 预测至关重要。为了填补这一空白,我们提出了基于 Transformer 的 Crossformer 模型,利用跨维度依赖性进行 MTS 预测。在 Crossformer 中,输入的 MTS 通过维-分-维嵌入(DSW)被嵌入到二维矢量阵列中,以保留时间和维度信息。然后提出了两阶段注意(TSA)层,以有效捕捉跨时间和跨维度的依赖性。利用 DSW 嵌入和 TSA 层,Crossformer 建立了分层编码器-解码器(HED),利用不同尺度的信息进行最终预测。在六个真实世界数据集上进行的大量实验结果表明,Crossformer 比以往的先进技术更有效。
1 INTRODUCTION
多变量时间序列(MTS)是具有多个维度的时间序列,其中每个维度代表一个特定的单变量时间序列(如天气的气候特征)。多变量时间序列预测旨在利用多变量时间序列的历史值预测其未来值。MTS 预测有利于下游任务的决策,被广泛应用于天气(Angryk 等人,2020 年)、能源(Demirel 等人,2012 年)、金融(Patton,2013 年)等多个领域。随着深度学习的发展,许多模型被提出并在 MTS 预测中取得了优异的表现(Lea 等人,2017;Qin 等人,2017;Flunkert 等人,2017;Rangapuram 等人,2018;Li 等人,2019a;Wu 等人,2020;Li 等人,2021)。其中,最近基于 Transformer 的模型(Li 等人,2019b;Zhou 等人,2021;Wu 等人,2021a;Liu 等人,2021a;Zhou 等人,2022;Chen 等人,2022)因其捕捉长期时间依赖性(跨时间依赖性)的能力而显示出巨大的潜力。
除了跨时间相关性,跨维度相关性对于 MTS 预测也至关重要,即对于某一特定维度,其他维度的相关序列信息可能会改善预测。例如,在预测未来气温时,不仅历史气温有助于预测,历史风速也有助于预测。之前的一些神经模型明确捕捉了跨维度的依赖性,即在潜在特征空间中保留维度信息,并使用卷积神经网络(CNN)(Lai 等人,2018 年)或图神经网络(GNN)(Wu 等人,2020 年;Cao 等人,2020 年)来捕捉其依赖性。然而,最近基于 Transformer 的模型只是通过嵌入隐式地利用了这种依赖性。一般来说,基于变换器的模型会将同一时间步的所有维度的数据点嵌入特征向量中,并尝试捕捉不同时间步之间的依赖性(如图 1 (b))。这样,跨时间的依赖性被很好地捕捉到了,但跨维度的依赖性却没有,这可能会限制其预测能力。
为了填补这一空白,我们提出了 Crossformer 模型,这是一种基于 Transformer 的模型,可明确利用跨维度依赖性进行 MTS 预测。具体来说,我们设计了维度-分段嵌入(DSW)来处理历史时间序列。在 DSW 嵌入中,每个维度的序列首先被分割成段,然后嵌入到特征向量中。DSW 嵌入的输出是一个二维向量数组,其中两个轴分别对应时间和维度。然后,我们提出了两阶段关注(TSA)层,以有效捕捉二维向量阵列之间的跨时间和跨维度依赖性。利用 DSW 嵌入和 TSA 层,Crossformer 建立了用于预测的分层编码器-解码器(HED)。在 HED 中,每一层都对应一个刻度。编码器的上层合并下层输出的相邻片段,以更粗的尺度捕捉相关性。解码器层生成不同尺度的预测结果,并将其相加作为最终预测结果。本文的贡献在于:
1) 我们深入研究了现有的基于变换器的 MTS 预测模型,发现这些模型并没有很好地利用跨维度依赖性:这些模型只是将特定时间步的所有维度的数据点嵌入到一个单一的向量中,并专注于捕捉不同时间步之间的跨时间依赖性。由于没有充分、明确地挖掘和利用跨维度依赖性,经验表明这些模型的预测能力有限。
2) 我们开发了 Crossformer,一个利用跨维度依赖性进行 MTS 预测的变换器模型。这是少数几个明确探索和利用跨维度依赖性进行 MTS 预测的变换器模型之一(据我们所知,这也许是第一个)。
3) 在六个真实世界基准上进行的大量实验结果表明,我们的 Crossformer 与以往的先进技术相比非常有效。具体来说,在不同预测长度和指标的 58 种设置中,Crossformer 在 36 种设置中的 9 个比较模型中排名第一,在 51 种设置中排名第二。
2 RELATED WORKS
Multivariate Time Series Forecasting.
MTS 预测模型大致可分为统计模型和神经模型。向量自回归(VAR)模型(Kilian & L ̃ Atkepohl,2017 年)和向量自回归移动平均(VARMA)是典型的统计模型,它们假设线性跨维度和跨时间依赖性。随着深度学习的发展,人们提出了许多神经模型,这些模型往往在经验上显示出比统计模型更好的性能。TCN(Lea 等人,2017 年)和 DeepAR(Flunkert 等人,2017 年)将 MTS 数据视为向量序列,并使用 CNN/RNN 捕捉时间依赖性。LSTnet(Lai 等人,2018 年)使用 CNN 捕捉跨维度依赖性,使用 RNN 捕捉跨时间依赖性。另一类作品使用图神经网络(GNN)明确捕捉跨维度依赖性进行预测(Li 等人,2018 年;Yu 等人,2018 年;Cao 等人,2020 年;Wu 等人,2020 年)。例如,MTGNN(Wu 等人,2020 年)使用时间卷积层和图卷积层来捕捉跨时间和跨维度的依赖性。这些神经模型通过 CNN 或 RNN 来捕捉跨时间依赖性,但它们难以模拟长期依赖性。
Transformers for MTS Forecasting.
Transformers(Vaswani 等人,2017 年)在自然语言处理(NLP)(Devlin 等人,2019 年)、视觉(CV)(Dosovitskiy 等人,2021 年)和语音处理(Dong 等人,2018 年)方面取得了成功。最近,许多基于变换器的模型被提出用于 MTS 预测,并显示出巨大的潜力(Li 等人,2019b;Zhou 等人,2021;Wu 等人,2021a;Liu 等人,2021a;Zhou 等人,2022;Du 等人,2022)。LogTrans(Li等人,2019b)提出了LogSparse注意,将Transformer的计算复杂度从O(L2)降低到O (L(log L)2)1。Informer(Zhou等人,2021)通过KL发散估计利用注意力得分的稀疏性,提出了ProbSparse自注意力,实现了O(L log L)复杂度。Autoformer (Wu 等人,2021a)在 Transformer 的基础上引入了一种具有自动相关机制的分解架构,也实现了 O(L log L) 的复杂度。Pyraformer (Liu 等人,2021a) 引入了一个金字塔注意模块,该模块可以总结不同分辨率下的特征,并对不同范围的时间依赖性进行建模,其复杂度为 O(L)。FEDformer (Zhou 等人,2022 年)提出时间序列在频域具有稀疏表示,并开发了一种频率增强变换器,其复杂度为 O(L)。Preformer(Du 等人,2022 年)将嵌入的特征向量序列划分为若干段,并利用基于分段相关性的注意力用于预测。这些模型主要侧重于降低跨时间依赖建模的复杂性,但忽略了对于 MTS 预测至关重要的跨维度依赖。
Vision Transformers.
Transformer最初应用于NLP用于序列建模, 最近的工作将 Transformer 应用于 CV 任务来处理图像(Dosovitskiy 等人,2021;Touvron 等人,2021;Liu 等人,2021b;Chen 等人,2021;Han 等人,2021)。这些作品在 CV 的各种任务上实现了最先进的性能,并激励了我们的工作。ViT(Dosovitskiy et al., 2021)是视觉变形器的先驱之一。 ViT 的基本思想是将图像分割成不重叠的中等大小的 patch,然后将这些 patch 重新排列成一个序列以输入到 Transformer。将图像分割成补丁的想法启发了我们的 DSW 嵌入,其中 MTS 被分割成维度片段。 Swin Transformer(Liu et al., 2021b)在窗口内执行局部注意力以降低复杂性,并通过合并图像块来构建分层特征图。读者可以参考最近的调查(Han et al., 2022)对视觉变换器进行全面的研究。
3 METHODOLOGY
在多元时间序列预测中,目标是在给定历史 x1:T ∈ RT ×D 的情况下预测时间序列 xT +1:T +τ ∈ Rτ×D 的未来值,其中 τ , T 是时间序列中的时间步数。分别是未来和过去2。 D > 1 是维数。一个自然的假设是这些 D 系列是相关的(例如天气的气候特征),这有助于提高预报准确性。为了利用跨维度依赖性,在第 3.1 节中,我们使用维度分段方式 (DSW) 嵌入来嵌入 MTS。在 3.2 节中,我们提出了一个两阶段注意力(TSA)层来有效地捕获嵌入片段之间的依赖关系。在 3.3 节中,使用 DSW 嵌入和 TSA 层,我们构建了一个分层编码器-解码器(HED),以利用不同尺度的信息进行最终预测。
3.1 DIMENSION-SEGMENT-WISE EMBEDDING
为了激发我们的方法,我们首先分析了之前基于 Transformer 的 MTS 预测模型的嵌入方法(Zhou et al., 2021; Wu et al., 2021a; Liu et al., 2021a; Zhou et al., 2022) 。如图1(b)所示,现有方法将同时步长的数据点嵌入到向量中:xt → ht,xt ∈ RD,ht ∈ Rdmodel ,其中xt表示第t步D维度中的所有数据点。这样,输入 x1:T 就被嵌入到 T 个向量 {h1, h2, ... 中。 。 。 , H T }。然后捕获 T 向量之间的依赖性以进行预测。因此,之前基于Transformer的模型主要捕获跨时间依赖性,而在嵌入过程中并未明确捕获跨维度依赖性,这限制了其预测能力。Transformer 最初是为 NLP 开发的(Vaswani 等人,2017),其中每个嵌入向量代表一个信息丰富的单词。对于 MTS,仅一步的单个值提供的信息很少。

图 1:我们的 DSW 嵌入示意图。 (a) 在 ETTh1 上训练的 2 层 Transformer 的自注意力分数,表明 MTS 数据倾向于分段。 (b) 先前基于 Transformer 的模型的嵌入方法 (Li et al., 2019b; Zhou et al., 2021; Wu et al., 2021a; Liu et al., 2021a):同一步骤中不同维度的数据点被嵌入到向量中。 (c) Crossformer 的 DSW 嵌入:在每个维度中,随着时间的推移,附近的点形成一段用于嵌入。
同时它在时域中与附近的值形成信息模式。图1(a)显示了原始Transformer用于MTS预测的典型注意力得分图。我们可以看到注意力值有分段的趋势,即接近的数据点具有相似的注意力权重.基于以上两点,我们认为嵌入向量应该表示单维的一系列片段(图1(c)),而不是单步的所有维度的值(图1(b))。为此,我们提出 Dimension-Segment-Wise (DSW) 嵌入,其中每个维度中的点被分为长度为 Lseg 的段,然后嵌入:
 其中 x(s) i,d ∈ RLseg 是维度 d 中长度为 Lseg 的第 i 个段。为了方便起见,我们假设 T、τ 可被 Lseg3 整除。然后使用添加位置嵌入的线性投影将每个片段嵌入到一个向量中:
其中 x(s) i,d ∈ RLseg 是维度 d 中长度为 Lseg 的第 i 个段。为了方便起见,我们假设 T、τ 可被 Lseg3 整除。然后使用添加位置嵌入的线性投影将每个片段嵌入到一个向量中:

其中 E ∈ Rdmodel×Lseg 表示可学习的投影矩阵,E(pos) i,d ∈ Rdmodel 表示位置 (i, d) 的可学习位置嵌入。嵌入后,我们得到一个二维向量数组 H= { hi,d|1 ≤ i ≤ T Lseg , 1 ≤ d ≤ D } ,其中每个 hi,d 代表一个单变量时间序列段。 Du 等人也使用了分割的思想。 (2022),它将嵌入的一维向量序列分割成段来计算段相关性,以增强局部性并降低计算复杂度。然而,与其他用于 MTS 预测的 Transformer 一样,它没有明确捕获跨维度依赖性。
3.2 TWO-STAGE ATTENTION LAYER
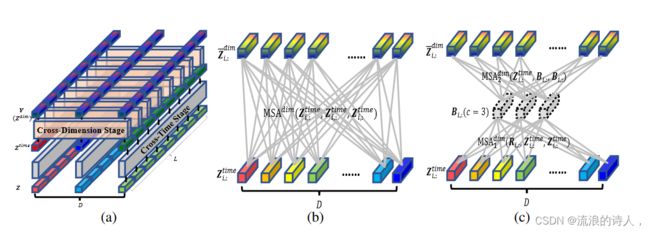
对于获得的2D数组H,可以将其展平为一维序列,以便可以将其输入到视觉中的ViT(Dosovitskiy et al., 2021)那样的规范Transformer中。虽然我们有具体的考虑: 1)与高度和宽度轴可以互换的图像不同,MTS 的时间轴和维度轴具有不同的含义,因此应该区别对待。 2)直接在2D数组上应用self-attention会导致O(D2 T 2 Ls2eg )的复杂度,这对于大D来说是无法承受的。因此,我们提出了两阶段注意力(TSA)层来捕获跨时间和交叉- 2D向量阵列之间的维度依赖性,如图2(a)所示。

图 2:TSA 层。 (a) 两阶段注意力层,用于处理表示多元时间序列的 2D 向量数组:每个向量指原始序列的一个片段。整个向量数组经过跨时间阶段和跨维度阶段,得到对应的依赖关系。
(b) 在 Cross-Dimension Stage 中直接使用 MSA 来构建 D 到 D 连接会导致 O(D2) 复杂度。
(c)跨维度阶段的路由器机制:一小部分固定数量的(c)“路由器”收集来自各个维度的信息,然后分发收集到的信息。复杂度降低至 O(2cD) = O(D)。
Cross-Time Stage
给定一个 2D 数组 Z ∈ RL×D×dmodel 作为 TSA 层的输入,其中 L 和 D 分别是段数和维度。这里的 Z 可以是 DSW 嵌入或较低 TSA 层的输出。为了方便起见,下文中我们用 Zi,: 表示时间步 i 处所有维度的向量,Z:,d 表示维度 d 处所有时间步的向量。在跨时间阶段,我们直接将多头自注意力(MSA)应用到每个维度:

其中 1 ≤ d ≤ D,LayerNorm 表示 Vaswani 等人广泛采用的层归一化。 (2017);多索维茨基等人。 (2021);周等人。 (2021),MLP 表示多层(本文为两层)前馈网络,MSA(Q, K, V) 表示多头自注意力 (Vaswani et al., 2017) 层,其中 Q, K, V用作查询、键和值。所有维度 (1 ≤ d ≤ D) 共享相同的 MSA 层。 ^ Ztime,Ztime表示MSA和MLP的输出。
其中 1 ≤ d ≤ D,LayerNorm 表示 Vaswani 等人广泛采用的层归一化。 (2017);多索维茨基等人。 (2021);周等人。 (2021),MLP 表示多层(本文为两层)前馈网络,MSA(Q, K, V) 表示多头自注意力 (Vaswani et al., 2017) 层,其中 Q, K, V用作查询、键和值。所有维度 (1 ≤ d ≤ D) 共享相同的 MSA 层。 ^ Ztime,Ztime表示MSA和MLP的输出。
Cross-Dimension Stage
我们可以在DSW Embedding中对长序列使用大的Lseg来减少跨时间阶段的段L的数量。而在跨维度阶段,我们不能划分维度,直接应用MSA会导致O(D2)的复杂度(如图2(b)所示),这对于大D的数据集来说是无法承受的。相反,我们建议如图 2(c)所示,我们为每个时间步 i 设置一个固定的小数量(c << D)可学习向量作为路由器。这些路由器首先使用路由器作为 MSA 中的查询,并使用所有维度的向量作为键和值来聚合来自所有维度的消息。然后,路由器使用维度向量作为查询,将聚合消息作为键和值,在维度之间分发接收到的消息。这样就建立了D维度之间的全对全连接:

其中 R ∈ RL×c×dmodel (c 是常数)是用作路由器的可学习向量数组。 B ∈ RL×c×dmodel 是所有维度的聚合消息。 Zdim表示路由器机制的输出。所有时间步 (1 ≤ i ≤ L) 共享相同的 MSAdim 1 、 MSAdim 2 。 Zdim、Zdim 分别表示跳跃连接和 MLP 的输出。路由器机制将复杂度从O(D2L)降低到O(DL)。
将方程式相加3 和等式。 4、我们将这两个阶段建模为:

其中 Z, Y ∈ RL×D×dmodel 分别表示 TSA 层的输入和输出向量数组。请注意,整体计算复杂度
TSA 层的复杂度为 O(DL2 + DL) = O(DL2)。在跨时间和跨维度阶段之后,Z 中的每两个段(即 Zi1,d1 , Zi2,d2 )被连接,因此跨时间和跨维度依赖关系都在 Y 中捕获。
3.3 HIERARCHICAL ENCODER-DECODER
分层结构广泛应用于 Transformer 中的 MTS 预测,以捕获不同尺度的信息(Zhou et al., 2021;Liu et al., 2021a)。在本节中,我们使用所提出的 DSW 嵌入、TSA 层和段合并来构建分层编码器-解码器(HED)。如图3所示,上层利用较粗尺度的信息进行预测。将不同尺度的预测值相加,输出最终结果。

图 3:Crossformer 中具有 3 个编码器层的分层编码器-解码器架构。每个向量的长度表示覆盖的时间范围。编码器(左)使用 TSA 层和分段合并来捕获不同尺度的依赖性:上层中的向量覆盖较长的范围,从而导致较粗尺度的依赖性。探索不同的尺度,解码器(右)通过在每个尺度上进行预测并将它们相加来做出最终的预测。
Encoder
在编码器的每一层(第一层除外),时域中每两个相邻向量被合并以获得更粗糙级别的表示。然后应用 TSA 层来捕获此规模的依赖性。这个过程被建模为 Zenc,l = Encoder(Zenc,l−1):

其中H表示DSW嵌入得到的2D数组; Zenc,l表示第l个编码器层的输出; M ∈ Rdmodel×2dmodel 表示用于分段合并的可学习矩阵; [·]表示串联操作; Ll−1 表示第 l − 1 层中每个维度的段数,如果它不能被 2 整除,我们将 Zenc,l−1 填充到适当的长度; ˆ Zenc,l 表示第 i 层段合并后的数组。假设编码器中有 N 层,我们使用 Zenc,0, Zenc,1,...。 。 。 , Zenc,N , (Zenc,0 = H) 表示编码器的 N + 1 个输出。每个编码器层的复杂度是O(D T 2 Ls2eg )。
Decoder
获得编码器输出的 N + 1 个特征数组,我们在解码器中使用 N + 1 层(索引为 0, 1, ..., N )进行预测。第l层将第l个编码数组作为输入,然后输出第l层的解码2D数组。这个过程总结为 Zdec,l = Decoder(Zdec,l−1, Zenc,l):

其中 E(dec) ∈ R τ Lseg ×D×dmodel 表示解码器的可学习位置嵌入。 ̃ Zdec,l 是 TSA 的输出。 MSA 层以 ̃ Zdec,l :,d 作为查询,以 Zenc,l :,d 作为键和值来构建编码器和解码器之间的连接。 MSA 的输出表示为 Zdec,l :,d 。 ˆ Zdec,l、Zdec,l 分别表示跳跃连接和 MLP 的输出。我们使用 Zdec,0, Zenc,1, 。 。 。 , Zdec,N 表示解码器输出。每个解码器层的复杂度为 O ( D τ (T +τ ) Ls2eg )
将线性投影应用于每一层的输出以产生该层的预测。将各层预测相加得出最终预测(对于 l = 0, . . . , N ):

其中 Wlr Lseg×model 是一个可学习矩阵,用于将向量投影到时间序列段。 x(s),li,dE Lseg 表示预测的 d 维中的第 i 个片段。
4 EXPERIMENTS
4.1 PROTOCOLS
Datasets
我们按照 Zhou 等人的研究,在六个现实世界数据集上进行了实验。 (2021);吴等人。 (2021a)。 1) ETTh1(电力变压器温度 - 每小时), 2) ETTm1(电力变压器温度 - 分钟), 3) WTH(天气), 4) ECL(电力消耗负载), 5) ILI(流感样疾病), 6)交通。前四个数据集的训练/验证/测试分割与 Zhou 等人相同。 (2021),后两者按照 Wu 等人的比例 0.7:0.1:0.2 进行分割。 (2021a)。
Baselines
我们使用以下流行的 MTS 预测模型作为基线:1) LSTMa (Bahdanau et al., 2015)、2) LSTnet (Lai et al., 2018)、3) MTGNN (Wu et al., 2020) 和最近的基于 Transformer 的 MTS 预测模型:4) Transformer (Vaswani et al., 2017)、5) Informer (Zhou et al., 2021)、6) Autoformer (Wu et al., 2021a)、7) Pyraformer (Liu et al., 2021)等人,2021a) 和 8) FEDformer(Zhou 等人,2022)。
Setup
我们使用与 Zhou 等人相同的设置。 (2021):训练/验证/测试集使用训练集的平均值和标准差进行零均值归一化。在每个数据集上,我们评估未来窗口大小 τ 变化时的性能。对于每个 τ ,过去的窗口大小 T 被视为要搜索的超参数,这是最近 MTS Transformer 文献中的常见协议(Zhou 等人,2021;Liu 等人,2021a)。我们以 stride = 1 滚动整个集合以生成不同的输入输出对。使用均方误差(MSE)和平均绝对误差(MAE)作为评估指标。所有实验均重复 5 次,并报告指标的平均值。我们的 Crossformer 仅利用过去的序列来预测未来,而基线模型则使用其他协变量,例如一天中的某个时间。有关数据集、基线、实现、超参数的详细信息请参见附录 A。
4.2 MAIN RESULTS
如表 1 所示,Crossformer 在大多数数据集以及不同的预测长度设置上都显示出领先的性能,总共 58 个案例中,有 36 个 top-1 和 51 个 top-2 案例。值得注意的是,也许由于通过 GNN 显式使用跨维度依赖,MTGNN 的性能优于许多基于 Transformer 的基线。虽然现有的 MTGNN 很少被比较MTS 预测文献的变压器。 FEDformer 和 Autoformer 在 ILI 上的表现优于我们的模型。我们推测这是因为数据集ILI的规模很小,并且这两个模型将序列分解的先验知识引入到网络结构中,这使得它们在数据有限时表现良好。 Crossformer 在此数据集上的性能仍然优于其他基线。

4.3 ABLATION STUDY
在我们的方法中,包含三个组件:DSW 嵌入、TSA 层和 HED。我们根据 Zhou 等人对 ETTh1 数据集进行消融研究。 (2021);刘等人。 (2021a)。我们使用 Transformer 作为基线,DSW+TSA+HED 表示没有消融的 Crossformer。比较了三种消融版本:1) DSW 2) DSW+TSA 3) DSW+HED。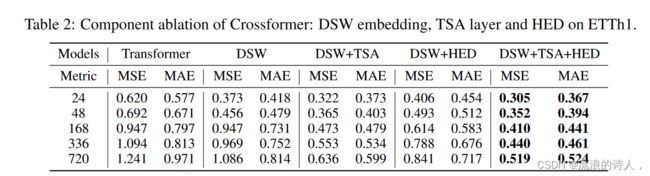
我们分析了表 2 中所示的结果。 1) DSW 在大多数设置上都比 Transformer 表现更好。 DSW 和 Transformer 唯一的区别是嵌入方法,这表明了 DSW 嵌入的有用性以及跨维度依赖的重要性。 2)TSA不断提高预报准确度。这表明以不同方式对待时间和维度是合理的。此外,TSA 使得在维数较大的数据集上使用 Crossformer 成为可能(例如,数据集 Traffic 的 D = 862)。 3)DSW+HED与DSW相比,HED在预测长度较短时降低了预测精度,但在长期预测时提高了预测精度。可能的原因是不同尺度的信息有助于长期预测。 4) 结合 DSW、TSA 和 HED,我们的 Crossformer 在所有设置下都能产生最佳结果。
4.4 EFFECT OF HYPER-PARAMETERS

图 4:超参数影响和计算效率评估。
(a) MSE 与 ETTh1 上 DSW 嵌入中的超参数段长度 Lseg 的关系。
(b) ETTh1 上 TSA 层的跨维度阶段中针对路由器 c 的超参数数量的 MSE。
(c) ETTh1 上输入长度 T 的内存占用情况。
(d) 具有不同维数的合成数据集上的维数 D 的内存占用。
我们评估两个超参数的影响:段长度(等式 1 中的 Lseg)和 TSA 中的路由器数量(TSA 的跨维度阶段中的 c)对 ETTh1 数据集的影响。分段长度:在图4(a)中,我们将分段长度从4延长到24,并使用不同的预测窗口评估MSE。对于短期预测(τ = 24, 48),较小的分段会产生相对较好的结果,但预测精度稳定。对于长期预测(τ ≥ 168),将段长度从 4 延长到 24 会导致 MSE 降低。这表明应使用长段进行长期预测。我们进一步将分段长度延长至 48,τ = 336, 720,MSE 略大于 24。可能的原因是 24 小时与该数据集的每日周期完全匹配,而 48 太粗略,无法捕获精细的数据。粒度信息。 TSA层路由器数量:路由器数量c控制各个维度之间的信息带宽。如图 4(b) 所示,当 τ ≤ 336 时,Crossformer 的性能相对于 c 是稳定的。对于 τ = 720,MSE 为当c=3时较大,但当c≥5时减小并稳定。在实践中,我们设置c=10来平衡预测精度和计算效率。
4.5 COMPUTATIONAL EFFICIENCY ANALYSIS

表 3 比较了基于 Transformer 的模型每层的理论复杂度。Crossformer 编码器的复杂度是 T 的二次方。然而,对于使用大 Lseq 的长期预测,系数 1 Ls2eq 项可以显着降低其实际复杂度。我们在 ETTh1.4 上评估这些模型的内存占用。我们设置预测窗口 τ = 336 并延长输入长度 T 。对于 Crossformer,Lseg 设置为 24,这是 τ ≥ 168 时的最佳值(见图 4(a))。图4(c)的结果表明,在测试的长度范围内,Crossformer在五种方法中实现了最好的效率。理论上,当 T 接近无穷大时,Informer、Autoformer 和 FEDformer 的效率更高。实际上,当 T 不是很大时(例如 T ≤ 104),Crossformer 的性能会更好。
我们还评估了维度 D 的内存占用。对于未明确建模跨维度依赖的基线模型,D 几乎没有影响。因此,我们在 4.3 节中将 Crossformer 与其消融版本进行比较。我们还评估了在 Cross-Dimension Stage 中直接使用 MSA 而不使用 Router 机制的 TSA 层,表示为 TSA(w/o Router)。图 4(d)显示,没有 TSA 层(DSW 和 DSW+HED)的 Crossformer 的复杂度是 D 的二次方。TSA(w/o Router)有助于降低复杂度,而 Router 机制进一步使复杂度呈线性,因此 Crossformer 可以处理D = 300的数据。此外,HED可以稍微降低内存成本,我们分析这是因为分段合并后上层的向量较少(见图3)。除内存占用外,实际运行时间评估见附录B.6。
5 CONCLUSIONS AND FUTURE WORK
我们提出了 Crossformer,这是一种基于 Transformer 的模型,利用跨维度依赖性进行多元时间序列 (MTS) 预测。具体来说,维度分段嵌入(DSW)将输入数据嵌入到二维向量数组中,以保留时间和维度的信息。两阶段注意力(TSA)层旨在捕获嵌入式阵列的跨时间和跨维度依赖性。使用 DSW 嵌入和 TSA 层,设计了分层编码器-解码器 (HED) 以利用不同尺度的信息。六个真实世界数据集的实验结果表明其比以前最先进的技术更有效。
我们分析了我们工作的局限性,并简要讨论了未来研究的一些方向:1)在跨维度阶段,我们在维度之间建立简单的全连接,这可能会在高维数据集上引入噪声。最近的稀疏且高效的图变换器(Wu et al., 2022)可以使我们的 TSA 层在这个问题上受益。 2)该工作提交后被接受的一项并行工作(Zeng et al., 2023)引起了我们的关注。它质疑 Transformers 用于 MTS 预测的有效性,并提出 DLinear 在六个数据集中的三个数据集上优于所有 Transformer,包括我们的 Crossformer(详细信息参见附录 B.2)。它认为主要原因是 Transformer 中的 MSA 是排列不变的。因此,增强Transformers的顺序保持能力是克服这一缺点的一个有前途的方向。 3)考虑到MTS分析中使用的数据集比视觉和文本中使用的数据集小得多且简单得多,除了新模型之外,未来的研究还需要具有各种模式的大型数据集。