目标检测 pytorch复现CenterNet目标检测项目
目标检测 pytorch复现CenterNet目标检测项目
- 1、项目创新点
- 2、CenterNet网络结构
- 3、CenterNet的模型计算流程如下:
- 4、详细实现原理
-
- 4.1、heatmap(热力图)理解和生成
-
- 4.1.1 heatmap生成
- 4.1.2 heatmap高斯函数半径的确定
- 4.1.3 CenterNet中生成高斯核的部分代码进行解析:
- 5、预处理数据增强
- 6、损失函数
- 7、pytorch复现CenterNet目标检测项目[项目地址](https://download.csdn.net/download/guoqingru0311/87771100)
-
- 7.1 环境搭建
- 7.2 数据集准备
- 7.3 修改配置信息
- 7.4 训练数据
- 7.5 验证模型
- 7.6 测试数据
- 7.7 批量保存每张图片的预测结果(bbox,id,score)
- 8、另一个版本的基于CenterNet的目标检测项目
1、项目创新点
CenterNet是在2019年论文Objects as points中提出,相比yolo,ssd,faster_rcnn依靠大量anchor的检测网络,CenterNet是一种anchor-free的目标检测网络,在速度和精度上都比较有优势

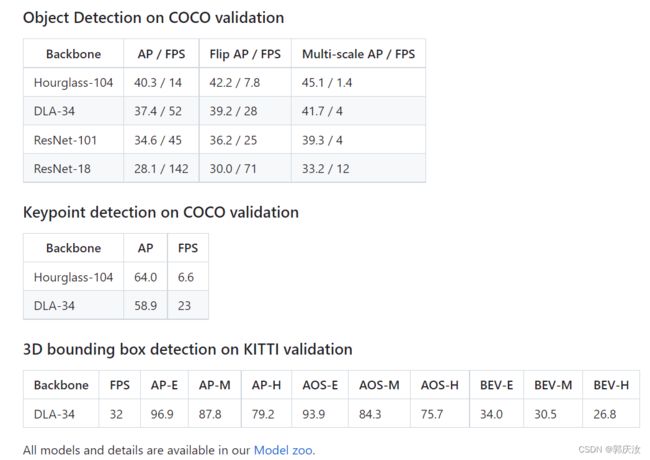

2、CenterNet网络结构

实际工作中我主要用CenterNet进行目标检测,常用Resnet50作为backbone,这里主要介绍resnet50_center_net,其网络结构如下:
可以发现CenterNet网络比较简单,主要包括resnet50提取图片特征,然后是反卷积模块Deconv(三个反卷积)对特征图进行上采样,最后三个分支卷积网络用来预测heatmap, 目标的宽高和目标的中心点坐标。值得注意的是反卷积模块,其包括三个反卷积组,每个组都包括一个3*3的卷积和一个反卷积,每次反卷积都会将特征图尺寸放大一倍,有很多代码中会将反卷积前的3x3的卷积替换为DCNv2(https://github.com/CharlesShang/DCNv2)(Deformable ConvetNets V2)来提高模型拟合能力。

3、CenterNet的模型计算流程如下:

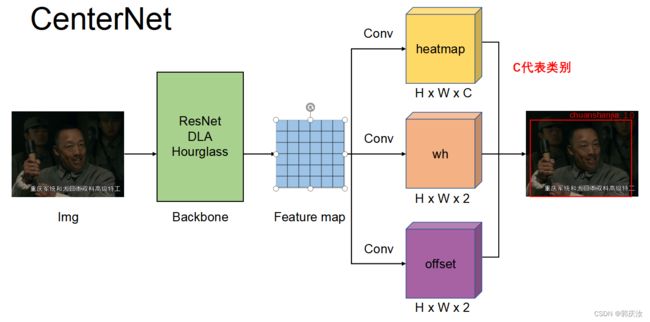
4、详细实现原理

4.1、heatmap(热力图)理解和生成
4.1.1 heatmap生成

4.1.2 heatmap高斯函数半径的确定
heatmap上的关键点之所以采用二维高斯核来表示,是由于对于在目标中心点附近的一些点,期预测出来的box和gt_box的IOU可能会大于0.7,不能直接对这些预测值进行惩罚,需要温和一点,所以采用高斯核。借用下大佬们的解释,如下图所示:

关于高斯圆的半径确定,主要还是依赖于目标box的宽高,其计算方法为下图所示。 实际情况中会取IOU=0.7,即下图中的overlap=0.7作为临界值,然后分别计算出三种情况的半径,取最小值作为高斯核的半径r:

def gaussian_radius(det_size, min_overlap=0.7):
height, width = det_size
a1 = 1
b1 = (height + width)
c1 = width * height * (1 - min_overlap) / (1 + min_overlap)
sq1 = np.sqrt(b1 ** 2 - 4 * a1 * c1)
r1 = (b1 + sq1) / 2 # 此处没有乘以a1,不过影响不大
a2 = 4
b2 = 2 * (height + width)
c2 = (1 - min_overlap) * width * height
sq2 = np.sqrt(b2 ** 2 - 4 * a2 * c2)
r2 = (b2 + sq2) / 2
a3 = 4 * min_overlap
b3 = -2 * min_overlap * (height + width)
c3 = (min_overlap - 1) * width * height
sq3 = np.sqrt(b3 ** 2 - 4 * a3 * c3)
r3 = (b3 + sq3) / 2
return min(r1, r2, r3)
4.1.3 CenterNet中生成高斯核的部分代码进行解析:
二维高斯函数的公式
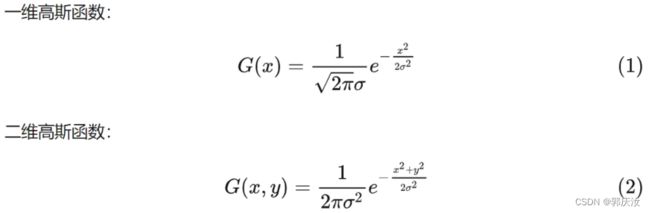
CenterNet源码中二维高斯函数实现如下:
def gaussian2D(shape, sigma=1):
m, n = [(ss - 1.) / 2. for ss in shape]
y, x = np.ogrid[-m:m + 1, -n:n + 1]#np.orgin 生成二维网格坐标
h = np.exp(-(x * x + y * y) / (2 * sigma * sigma))
h[h < np.finfo(h.dtype).eps * h.max()] = 0 #np.finfo()常用于生成一定格式,数值较小的偏置项eps,以避免分母或对数变量为零
return h
高斯核半径的计算
从代码上看就是一元二次方程的求根公式
这里要注意的代码中计算高斯半径是根据框的角点进行计算,而在Centernet中需要计算的是框的中心点的高斯半径,其实道理是一样的 Centernet 框的角点的偏移可以近似对于框中心点的偏移
情况一:两角点均在真值框内
情况二:两角点均在真值框外
情况三:一角点在真值框内,一角点在真值框外
求解代码:
def gaussian_radius(det_size, min_overlap=0.7):
height, width = det_size
a1 = 1
b1 = (height + width)
c1 = width * height * (1 - min_overlap) / (1 + min_overlap)
sq1 = np.sqrt(b1 ** 2 - 4 * a1 * c1)
r1 = (b1 + sq1) / 2
a2 = 4
b2 = 2 * (height + width)
c2 = (1 - min_overlap) * width * height
sq2 = np.sqrt(b2 ** 2 - 4 * a2 * c2)
r2 = (b2 + sq2) / 2
a3 = 4 * min_overlap
b3 = -2 * min_overlap * (height + width)
c3 = (min_overlap - 1) * width * height
sq3 = np.sqrt(b3 ** 2 - 4 * a3 * c3)
r3 = (b3 + sq3) / 2
return min(r1, r2, r3)
CenterNet源码中 draw_umich_gaussian 函数实现如下:
def draw_umich_gaussian(heatmap, center, radius, k=1):
diameter = 2 * radius + 1
gaussian = gaussian2D((diameter, diameter), sigma=diameter / 6)
x, y = int(center[0]), int(center[1])
height, width = heatmap.shape[0:2]
left, right = min(x, radius), min(width - x, radius + 1)
top, bottom = min(y, radius), min(height - y, radius + 1)
masked_heatmap = heatmap[y - top:y + bottom, x - left:x + right]
masked_gaussian = gaussian[radius - top:radius + bottom, radius - left:radius + right]
if min(masked_gaussian.shape) > 0 and min(masked_heatmap.shape) > 0: # TODO debug
np.maximum(masked_heatmap, masked_gaussian * k, out=masked_heatmap)#逐个元素比较大小,保留大的值
return heatmap

import numpy as np
import math
import xml.etree.ElementTree as ET
import glob
from image import draw_dense_reg, draw_msra_gaussian, draw_umich_gaussian
from image import get_affine_transform, affine_transform, gaussian_radius
data_dir = r"*.jpg"
a_file = glob.glob(data_dir)[0]
print(a_file, a_file.replace(".jpg", ".xml"))
tree = ET.parse(a_file.replace(".jpg", ".xml"))
root = tree.getroot()
size = root.find('size')
width = int(size.find('width').text)
height = int(size.find('height').text)
print(f"原图宽:{width} 高:{height}")
num_classes = 3
output_h = height
output_w = width
hm = np.zeros((num_classes, output_h, output_w), dtype=np.float32)
anns = []
for obj in root.iter('object'):
bbox = obj.find('bndbox')
cate = obj.find('name').text
# print(cate, bbox.find("xmin").text, bbox.find("xmax").text,
# bbox.find("ymin").text, bbox.find("ymax").text)
xyxy = [int(bbox.find("xmin").text), int(bbox.find("ymin").text),
int(bbox.find("xmax").text),int(bbox.find("ymax").text)]
anns.append({"bbox" : xyxy,'category_id':int(cate)})
num_objs = len(anns)
flipped = False #是否经过全图翻转
import matplotlib.pyplot as plt
plt.figure(figsize=(19, 6))
plt.ion()
plt.subplot(131)
img = plt.imread(a_file)
plt.title('Origin_img')
plt.imshow(img)
for k in range(num_objs):
ann = anns[k]
bbox = ann['bbox']
cls_id = ann['category_id']
if flipped:
bbox[[0, 2]] = width - bbox[[2, 0]] - 1
# bbox[:2] = affine_transform(bbox[:2], trans_output)# 仿射变换
# bbox[2:] = affine_transform(bbox[2:], trans_output)
# bbox[[0, 2]] = np.clip(bbox[[0, 2]], 0, output_w - 1)#裁剪
# bbox[[1, 3]] = np.clip(bbox[[1, 3]], 0, output_h - 1)
h, w = bbox[3] - bbox[1], bbox[2] - bbox[0]
if h > 0 and w > 0:
radius = gaussian_radius((math.ceil(h), math.ceil(w)))
radius = max(0, int(radius))
# radius = self.opt.hm_gauss if self.opt.mse_loss else radius
ct = np.array(
[(bbox[0] + bbox[2]) / 2, (bbox[1] + bbox[3]) / 2], dtype=np.float32)
ct_int = ct.astype(np.int32)
plt.subplot(133)
hm_out, gaussian = draw_umich_gaussian(hm[cls_id], ct_int, radius)
plt.title('Umich Heatmap')
# hm_out = draw_msra_gaussian(hm[cls_id], ct_int, radius)
# print(hm_out.shape)
# plt.title("Mara Heatmap")
plt.text(ct[0], ct[1], f"(class:{cls_id})", c='white')
plt.plot([bbox[0], bbox[2], bbox[2], bbox[0], bbox[0]], [bbox[1], bbox[1], bbox[3], bbox[3], bbox[1]])
plt.imshow(hm_out)
plt.subplot(132)
plt.title(f'Gaussian: bbox_h={h},bbox_w={w}, radius={radius}')
plt.imshow(gaussian)
plt.pause(2)
5、预处理数据增强
关于CenterNet还有一点值得注意的是其数据增强部分,采用了仿射变换warpAffine,其实就是对原图中进行裁剪,然后缩放到512x512的大小(长边缩放,短边补0)。实际过程中先确定一个中心点,和一个裁剪的长宽,然后进行仿射变换,如下图所示,绿色框住的图片会被裁剪出来,然后缩放到512x512(实际效果见图二中六个子图中第一个)
下面是上图选择不同中心点和长度进行仿射变换得到的样本。除了中心点,裁剪长度,仿射变换还可以设置角度,CenterNet中没有设置角度(代码中为0),是由于加上旋转角度后,gt_box会变的不是很准确,如最右边两个旋转样本
数据预处理转换代码:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import torch.utils.data as data
import numpy as np
import torch
import json
import cv2
import os
from utils.image import flip, color_aug
from utils.image import get_affine_transform, affine_transform
from utils.image import gaussian_radius, draw_umich_gaussian, draw_msra_gaussian
from utils.image import draw_dense_reg
import math
class CTDetDataset(data.Dataset):
def _coco_box_to_bbox(self, box):
bbox = np.array([box[0], box[1], box[0] + box[2], box[1] + box[3]],
dtype=np.float32)
return bbox
def _get_border(self, border, size):
i = 1
while size - border // i <= border // i:
i *= 2
return border // i
def __getitem__(self, index):
img_id = self.images[index]
file_name = self.coco.loadImgs(ids=[img_id])[0]['file_name'] # 获取文件名
img_path = os.path.join(self.img_dir, file_name) # 获取图片的路径
ann_ids = self.coco.getAnnIds(imgIds=[img_id])
anns = self.coco.loadAnns(ids=ann_ids) # 获取单个样本的标注信息
num_objs = min(len(anns), self.max_objs)
img = cv2.imread(img_path) # 读取数据
#### resize图片步骤开始
height, width = img.shape[0], img.shape[1]
c = np.array([img.shape[1] / 2., img.shape[0] / 2.], dtype=np.float32)
if self.opt.keep_res:
input_h = (height | self.opt.pad) + 1
input_w = (width | self.opt.pad) + 1
s = np.array([input_w, input_h], dtype=np.float32)
else:
s = max(img.shape[0], img.shape[1]) * 1.0
input_h, input_w = self.opt.input_h, self.opt.input_w
flipped = False
if self.split == 'train':
if not self.opt.not_rand_crop:
s = s * np.random.choice(np.arange(0.6, 1.4, 0.1))
w_border = self._get_border(128, img.shape[1])
h_border = self._get_border(128, img.shape[0])
c[0] = np.random.randint(low=w_border, high=img.shape[1] - w_border)
c[1] = np.random.randint(low=h_border, high=img.shape[0] - h_border)
else:
sf = self.opt.scale
cf = self.opt.shift
c[0] += s * np.clip(np.random.randn()*cf, -2*cf, 2*cf)
c[1] += s * np.clip(np.random.randn()*cf, -2*cf, 2*cf)
s = s * np.clip(np.random.randn()*sf + 1, 1 - sf, 1 + sf)
if np.random.random() < self.opt.flip:
flipped = True
img = img[:, ::-1, :]
c[0] = width - c[0] - 1
trans_input = get_affine_transform(
c, s, 0, [input_w, input_h])
inp = cv2.warpAffine(img, trans_input,
(input_w, input_h),
flags=cv2.INTER_LINEAR)
inp = (inp.astype(np.float32) / 255.)
if self.split == 'train' and not self.opt.no_color_aug:
color_aug(self._data_rng, inp, self._eig_val, self._eig_vec)
inp = (inp - self.mean) / self.std
inp = inp.transpose(2, 0, 1)
####### resiza图片步骤结束
output_h = input_h // self.opt.down_ratio # 128
output_w = input_w // self.opt.down_ratio
num_classes = self.num_classes
trans_output = get_affine_transform(c, s, 0, [output_w, output_h]) # 获取到变换矩阵,将原始图像映射到128x128
# 创建GT
hm = np.zeros((num_classes, output_h, output_w), dtype=np.float32) # 初始胡heatMap GT
wh = np.zeros((self.max_objs, 2), dtype=np.float32) # 初始化宽度与高度的GT
dense_wh = np.zeros((2, output_h, output_w), dtype=np.float32)
reg = np.zeros((self.max_objs, 2), dtype=np.float32) # 初始化中心点偏置的回归
ind = np.zeros((self.max_objs), dtype=np.int64)
reg_mask = np.zeros((self.max_objs), dtype=np.uint8)
cat_spec_wh = np.zeros((self.max_objs, num_classes * 2), dtype=np.float32)
cat_spec_mask = np.zeros((self.max_objs, num_classes * 2), dtype=np.uint8)
# 默认使用draw_msra_gaussian函数 # 根据求得的radius往heatMap上绘制高斯分布
draw_gaussian = draw_msra_gaussian if self.opt.mse_loss else \
draw_umich_gaussian
gt_det = []
for k in range(num_objs): # 遍历标注内的每个objects
ann = anns[k]
bbox = self._coco_box_to_bbox(ann['bbox']) # 转换成左上角和右下角坐标
cls_id = int(self.cat_ids[ann['category_id']]) # 获取当前物体类别
if flipped:
bbox[[0, 2]] = width - bbox[[2, 0]] - 1
# 将标注的坐标缩放到128x128的尺寸上
bbox[:2] = affine_transform(bbox[:2], trans_output) # 利用变换矩阵,将bdbox在原始图像的坐标变换到128x128上
bbox[2:] = affine_transform(bbox[2:], trans_output) # 利用变换矩阵,将bdbox在原始图像的坐标变换到128x128上
# 防止坐标超出范围
bbox[[0, 2]] = np.clip(bbox[[0, 2]], 0, output_w - 1)
bbox[[1, 3]] = np.clip(bbox[[1, 3]], 0, output_h - 1)
h, w = bbox[3] - bbox[1], bbox[2] - bbox[0] # 计算bbox的高度与宽度
if h > 0 and w > 0:
radius = gaussian_radius((math.ceil(h), math.ceil(w))) # 计算满足高斯分布的半径
radius = max(0, int(radius))
radius = self.opt.hm_gauss if self.opt.mse_loss else radius
ct = np.array(
[(bbox[0] + bbox[2]) / 2, (bbox[1] + bbox[3]) / 2], dtype=np.float32) # 获取中心点坐标
ct_int = ct.astype(np.int32) # 取整
draw_gaussian(hm[cls_id], ct_int, radius) # 根据求得的radius往heatMap上绘制高斯分布 hm[cls_id]:对应类别的channel
wh[k] = 1. * w, 1. * h
ind[k] = ct_int[1] * output_w + ct_int[0] # 表示拉成一个一维数据后,其index的位置
reg[k] = ct - ct_int # 浮点类型-整型
reg_mask[k] = 1 # 表示赋值完毕的设置为1,没有赋值的为0
cat_spec_wh[k, cls_id * 2: cls_id * 2 + 2] = wh[k]
cat_spec_mask[k, cls_id * 2: cls_id * 2 + 2] = 1
if self.opt.dense_wh:
draw_dense_reg(dense_wh, hm.max(axis=0), ct_int, wh[k], radius)
gt_det.append([ct[0] - w / 2, ct[1] - h / 2,
ct[0] + w / 2, ct[1] + h / 2, 1, cls_id])
ret = {'input': inp, 'hm': hm, 'reg_mask': reg_mask, 'ind': ind, 'wh': wh}
if self.opt.dense_wh:
hm_a = hm.max(axis=0, keepdims=True)
dense_wh_mask = np.concatenate([hm_a, hm_a], axis=0)
ret.update({'dense_wh': dense_wh, 'dense_wh_mask': dense_wh_mask})
del ret['wh']
elif self.opt.cat_spec_wh:
ret.update({'cat_spec_wh': cat_spec_wh, 'cat_spec_mask': cat_spec_mask})
del ret['wh']
if self.opt.reg_offset:
ret.update({'reg': reg})
if self.opt.debug > 0 or not self.split == 'train':
gt_det = np.array(gt_det, dtype=np.float32) if len(gt_det) > 0 else \
np.zeros((1, 6), dtype=np.float32)
meta = {'c': c, 's': s, 'gt_det': gt_det, 'img_id': img_id}
ret['meta'] = meta
return ret
6、损失函数

FocalLoss代码:
原作者的代码是没有对pred输出做限制,我在实际训练中如果不加以限制,则会导致pred经过log计算之后的输出为NaN或Inf,所以使用torch.clamp()进行截取,相关代码如下:
def _neg_loss(pred, gt):
''' Modified focal loss. Exactly the same as CornerNet.
Runs faster and costs a little bit more memory
Arguments:
pred (batch x c x h x w)
gt_regr (batch x c x h x w)
'''
pos_inds = gt.eq(1).float()
neg_inds = gt.lt(1).float()
neg_weights = torch.pow(1 - gt, 4)
loss = 0
pos_loss = torch.log(pred) * torch.pow(1 - pred, 2) * pos_inds
neg_loss = torch.log(1 - pred) * torch.pow(pred, 2) * neg_weights * neg_inds
num_pos = pos_inds.float().sum()
pos_loss = pos_loss.sum()
neg_loss = neg_loss.sum()
if num_pos == 0:
loss = loss - neg_loss
else:
loss = loss - (pos_loss + neg_loss) / num_pos
return loss
WidthHeight和Offset的损失由l1 loss计算,原理比较简单
class L1Loss(nn.Module):
def __init__(self):
super(L1Loss, self).__init__()
def forward(self, output, mask, ind, target):
pred = _transpose_and_gather_feat(output, ind)
mask = mask.unsqueeze(2).expand_as(pred).float()
loss = F.l1_loss(pred * mask, target * mask, reduction='elementwise_mean')
return loss
7、pytorch复现CenterNet目标检测项目项目地址
7.1 环境搭建
本项目官方建议pytorch版本是1.4以下,我是用的1.2版本,因为需要编译DCNv2模块**,安装COCOAPI**
1、项目下载
CenterNet_ROOT=/path/to/clone/CenterNet
git clone https://github.com/xingyizhou/CenterNet $CenterNet_ROOT
2、编译DCNv2模块
注意:因为官方提供的DCNv2版本过老,需要去DCNv2官网下载该模块,替换点项目中的该文件
cd $CenterNet_ROOT/src/lib/models/networks/DCNv2
./make.sh
Compile NMS if your want to use multi-scale testing or test ExtremeNet
cd $CenterNet_ROOT/src/lib/external
make
7.2 数据集准备
7-1 在data文件夹下新建两个文件夹:food、image_and_xml;
其中food为你自己数据集的名称,我这里要做的是识别一个菜品的任务,所以命名为food,image_and_xml存放的是你所有的图片和xml文件;
7-2 新建一个python文件,文件代码为xml_to_json,即将voc数据集的xml文件格式转为coco数据集的json文件格式,记得在运行之前要把相应的文件路径以及一些参数设置好;
# coding:utf-8
# 运行前请先做以下工作:
# pip install lxml
# 将所有的图片及xml文件存放到xml_dir指定的文件夹下,并将此文件夹放置到当前目录下
#
import os
import glob
import json
import shutil
import numpy as np
import xml.etree.ElementTree as ET
START_BOUNDING_BOX_ID = 1
save_path = "."
def get(root, name):
return root.findall(name)
def get_and_check(root, name, length):
vars = get(root, name)
if len(vars) == 0:
raise NotImplementedError('Can not find %s in %s.' % (name, root.tag))
if length and len(vars) != length:
raise NotImplementedError('The size of %s is supposed to be %d, but is %d.' % (name, length, len(vars)))
if length == 1:
vars = vars[0]
return vars
def convert(xml_list, json_file):
json_dict = {"images": [], "type": "instances", "annotations": [], "categories": []}
categories = pre_define_categories.copy()
bnd_id = START_BOUNDING_BOX_ID
all_categories = {}
for index, line in enumerate(xml_list):
# print("Processing %s"%(line))
xml_f = line
tree = ET.parse(xml_f)
root = tree.getroot()
filename = os.path.basename(xml_f)[:-4] + ".jpg"
image_id = 20190000001 + index
size = get_and_check(root, 'size', 1)
width = int(get_and_check(size, 'width', 1).text)
height = int(get_and_check(size, 'height', 1).text)
image = {'file_name': filename, 'height': height, 'width': width, 'id': image_id}
json_dict['images'].append(image)
# Currently we do not support segmentation
segmented = get_and_check(root, 'segmented', 1).text
assert segmented == '0'
for obj in get(root, 'object'):
category = get_and_check(obj, 'name', 1).text
if category in all_categories:
all_categories[category] += 1
else:
all_categories[category] = 1
if category not in categories:
if only_care_pre_define_categories:
continue
new_id = len(categories) + 1
print(
"[warning] category '{}' not in 'pre_define_categories'({}), create new id: {} automatically".format(
category, pre_define_categories, new_id))
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, 'bndbox', 1)
xmin = int(float(get_and_check(bndbox, 'xmin', 1).text))
ymin = int(float(get_and_check(bndbox, 'ymin', 1).text))
xmax = int(float(get_and_check(bndbox, 'xmax', 1).text))
ymax = int(float(get_and_check(bndbox, 'ymax', 1).text))
assert (xmax > xmin), "xmax <= xmin, {}".format(line)
assert (ymax > ymin), "ymax <= ymin, {}".format(line)
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {'area': o_width * o_height, 'iscrowd': 0, 'image_id':
image_id, 'bbox': [xmin, ymin, o_width, o_height],
'category_id': category_id, 'id': bnd_id, 'ignore': 0,
'segmentation': []}
json_dict['annotations'].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {'supercategory': 'food', 'id': cid, 'name': cate}
json_dict['categories'].append(cat)
json_fp = open(json_file, 'w')
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
print("------------create {} done--------------".format(json_file))
print("find {} categories: {} -->>> your pre_define_categories {}: {}".format(len(all_categories),
all_categories.keys(),
len(pre_define_categories),
pre_define_categories.keys()))
print("category: id --> {}".format(categories))
print(categories.keys())
print(categories.values())
if __name__ == '__main__':
# 定义你自己的类别
classes = ['aaa', 'bbb', 'ccc', 'ddd', 'eee', 'fff']
pre_define_categories = {}
for i, cls in enumerate(classes):
pre_define_categories[cls] = i + 1
# 这里也可以自定义类别id,把上面的注释掉换成下面这行即可
# pre_define_categories = {'a1': 1, 'a3': 2, 'a6': 3, 'a9': 4, "a10": 5}
only_care_pre_define_categories = True # or False
# 保存的json文件
save_json_train = 'train_food.json'
save_json_val = 'val_food.json'
save_json_test = 'test_food.json'
# 初始文件所在的路径
xml_dir = "./image_and_xml"
xml_list = glob.glob(xml_dir + "/*.xml")
xml_list = np.sort(xml_list)
# 打乱数据集
np.random.seed(100)
np.random.shuffle(xml_list)
# 按比例划分打乱后的数据集
train_ratio = 0.8
val_ratio = 0.1
train_num = int(len(xml_list) * train_ratio)
val_num = int(len(xml_list) * val_ratio)
xml_list_train = xml_list[:train_num]
xml_list_val = xml_list[train_num: train_num+val_num]
xml_list_test = xml_list[train_num+val_num:]
# 将xml文件转为coco文件,在指定目录下生成三个json文件(train/test/food)
convert(xml_list_train, save_json_train)
convert(xml_list_val, save_json_val)
convert(xml_list_test, save_json_test)
# # 将图片按照划分后的结果进行存放
# if os.path.exists(save_path + "/annotations"):
# shutil.rmtree(save_path + "/annotations")
# os.makedirs(save_path + "/annotations")
# if os.path.exists(save_path + "/images_divide/train"):
# shutil.rmtree(save_path + "/images_divide/train")
# os.makedirs(save_path + "/images_divide/train")
# if os.path.exists(save_path + "/images_divide/val"):
# shutil.rmtree(save_path + "/images_divide/val")
# os.makedirs(save_path + "/images_divide/val")
# if os.path.exists(save_path + "/images_divide/test"):
# shutil.rmtree(save_path + "/images_divide/test")
# os.makedirs(save_path + "/images_divide/test")
# # 按需执行,生成3个txt文件,存放相应的文件名称
# f1 = open("./train.txt", "w")
# for xml in xml_list_train:
# img = xml[:-4] + ".jpg"
# f1.write(os.path.basename(xml)[:-4] + "\n")
# shutil.copyfile(img, save_path + "/images_divide/train/" + os.path.basename(img))
#
# f2 = open("val.txt", "w")
# for xml in xml_list_val:
# img = xml[:-4] + ".jpg"
# f2.write(os.path.basename(xml)[:-4] + "\n")
# shutil.copyfile(img, save_path + "/images_divide/val/" + os.path.basename(img))
#
# f3 = open("test.txt", "w")
# for xml in xml_list_val:
# img = xml[:-4] + ".jpg"
# f2.write(os.path.basename(xml)[:-4] + "\n")
# shutil.copyfile(img, save_path + "/images_divide/test/" + os.path.basename(img))
#
# f1.close()
# f2.close()
# f3.close()
print("-" * 50)
print("train number:", len(xml_list_train))
print("val number:", len(xml_list_val))
print("test number:", len(xml_list_val))
运行完之后,会得到三个json文件,分别代表训练,测试和验证。
7-3 进入到food数据集下,新建两个文件夹:images和annotations:
images:存放你的所有图片文件;
annotations:把上一步生成的三个json文件复制或剪切到这个文件夹下;

7.3 修改配置信息
计算所有的图片的均值和标准差,直接将图片存放到同一个文件夹,把路径改下即可
import cv2, os, argparse
import numpy as np
from tqdm import tqdm
def main():
dirs = r'F:\Pycharm Professonal\CenterNet\CenterNet\data\food\images' # 修改你自己的图片路径
img_file_names = os.listdir(dirs)
m_list, s_list = [], []
for img_filename in tqdm(img_file_names):
img = cv2.imread(dirs + '/' + img_filename)
img = img / 255.0
m, s = cv2.meanStdDev(img)
m_list.append(m.reshape((3,)))
s_list.append(s.reshape((3,)))
m_array = np.array(m_list)
s_array = np.array(s_list)
m = m_array.mean(axis=0, keepdims=True)
s = s_array.mean(axis=0, keepdims=True)
print("mean = ", m[0][::-1])
print("std = ", s[0][::-1])
if __name__ == '__main__':
main()
7-3 写一个数据类
到src/lib/datasets/dataset目录下,新建一个python文件,这里需要自己写一个数据类,我这里命名为food.py,;
(1)第14行的类名改为自己的类型名,这里定义为Food;
(2)第15行的num_class改为自己数据集的类别数;
(3)第16行的default_resolution为默认的分辨率,这里按原作者给出的[512, 512],如果觉得自己的硬件设备跟不上,可以适当的改小,注意上面所计算出来的整个数据集的均值和标准差也要同步;
(4)第17-20行的均值和方差填上去;
(5)第23行super类的继承改为你自己定义的类名称;
(6)修改读取json文件的路径;
(7)修改类别名字和id;
总的可参考下面的代码:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import pycocotools.coco as coco
from pycocotools.cocoeval import COCOeval
import numpy as np
import json
import os
import torch.utils.data as data
class Food(data.Dataset):
num_classes = 6
default_resolution = [512, 512]
mean = np.array([0.472459, 0.475080, 0.482652],
dtype=np.float32).reshape((1, 1, 3))
std = np.array([0.255084, 0.254665, 0.257073],
dtype=np.float32).reshape((1, 1, 3))
def __init__(self, opt, split):
super(Food, self).__init__()
self.data_dir = os.path.join(opt.data_dir, 'food')
self.img_dir = os.path.join(self.data_dir, 'images')
if split == 'val':
self.annot_path = os.path.join(
self.data_dir, 'annotations', 'val_food.json')
else:
if opt.task == 'exdet':
self.annot_path = os.path.join(
self.data_dir, 'annotations', 'train_food.json')
if split == 'test':
self.annot_path = os.path.join(
self.data_dir, 'annotations', 'test_food.json')
else:
self.annot_path = os.path.join(
self.data_dir, 'annotations', 'train_food.json')
self.max_objs = 128
self.class_name = [
'__background__', 'aaa', 'bbb', 'ccc', 'ddd', 'eee', 'fff']
self._valid_ids = [1, 2, 3, 4, 5, 6]
self.cat_ids = {v: i for i, v in enumerate(self._valid_ids)}
self.voc_color = [(v // 32 * 64 + 64, (v // 8) % 4 * 64, v % 8 * 32) \
for v in range(1, self.num_classes + 1)]
self._data_rng = np.random.RandomState(123)
self._eig_val = np.array([0.2141788, 0.01817699, 0.00341571],
dtype=np.float32)
self._eig_vec = np.array([
[-0.58752847, -0.69563484, 0.41340352],
[-0.5832747, 0.00994535, -0.81221408],
[-0.56089297, 0.71832671, 0.41158938]
], dtype=np.float32)
# self.mean = np.array([0.485, 0.456, 0.406], np.float32).reshape(1, 1, 3)
# self.std = np.array([0.229, 0.224, 0.225], np.float32).reshape(1, 1, 3)
self.split = split
self.opt = opt
print('==> initializing food {} data.'.format(split))
self.coco = coco.COCO(self.annot_path)
self.images = self.coco.getImgIds()
self.num_samples = len(self.images)
print('Loaded {} {} samples'.format(split, self.num_samples))
@staticmethod
def _to_float(x):
return float("{:.2f}".format(x))
def convert_eval_format(self, all_bboxes):
# import pdb; pdb.set_trace()
detections = []
for image_id in all_bboxes:
for cls_ind in all_bboxes[image_id]:
category_id = self._valid_ids[cls_ind - 1]
for bbox in all_bboxes[image_id][cls_ind]:
bbox[2] -= bbox[0]
bbox[3] -= bbox[1]
score = bbox[4]
bbox_out = list(map(self._to_float, bbox[0:4]))
detection = {
"image_id": int(image_id),
"category_id": int(category_id),
"bbox": bbox_out,
"score": float("{:.2f}".format(score))
}
if len(bbox) > 5:
extreme_points = list(map(self._to_float, bbox[5:13]))
detection["extreme_points"] = extreme_points
detections.append(detection)
return detections
def __len__(self):
return self.num_samples
def save_results(self, results, save_dir):
json.dump(self.convert_eval_format(results),
open('{}/results.json'.format(save_dir), 'w'))
def run_eval(self, results, save_dir):
# result_json = os.path.join(save_dir, "results.json")
# detections = self.convert_eval_format(results)
# json.dump(detections, open(result_json, "w"))
self.save_results(results, save_dir)
coco_dets = self.coco.loadRes('{}/results.json'.format(save_dir))
coco_eval = COCOeval(self.coco, coco_dets, "bbox")
coco_eval.evaluate()
coco_eval.accumulate()
coco_eval.summarize()
7-4 将数据集加入src/lib/datasets/dataset_factory里面
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from .sample.ddd import DddDataset
from .sample.exdet import EXDetDataset
from .sample.ctdet import CTDetDataset
from .sample.multi_pose import MultiPoseDataset
from .dataset.coco import COCO
from .dataset.pascal import PascalVOC
from .dataset.kitti import KITTI
from .dataset.coco_hp import COCOHP
from .dataset.food import Food
dataset_factory = {
'coco': COCO,
'pascal': PascalVOC,
'kitti': KITTI,
'coco_hp': COCOHP,
'food': Food
}
_sample_factory = {
'exdet': EXDetDataset,
'ctdet': CTDetDataset,
'ddd': DddDataset,
'multi_pose': MultiPoseDataset
}
def get_dataset(dataset, task):
class Dataset(dataset_factory[dataset], _sample_factory[task]):
pass
return Dataset
7-5 在/src/lib/opts.py文件中修改
self.parser.add_argument('--dataset', default='food',
help='food | coco | kitti | coco_hp | pascal')
7-6 修改src/lib/utils/debugger.py文件(变成自己数据的类别和名字,前后数据集名字一定保持一致)
(1)第45行下方加入两行:
elif num_classes == 6 or dataset == 'food':
self.names = food_class_name
(2)第460行下方加入自己所定义的类别,不包含背景:
food_class_name = ['aaa', 'bbb', 'ccc', 'ddd', 'eee', 'fff']
7.4 训练数据
在./src/目录下,运行main.py文件,这里food改成你自己要保存的实验结果文件夹名称即可:
7.4.1 不加载预训练权重:
python main.py ctdet --exp_id food --batch_size 32 --lr 1.25e-4 --gpus 0
7.4.2 加载预训练权重:
python main.py ctdet --exp_id food --batch_size 32 --lr 1.25e-4 --gpus 0 --load_model ../models/ctdet_dla_2x.pth
7.4.3 多卡训练,其中master_batch_sizes 表示的是你在主GPU上要放置多大的batch_size,其余分配到其它卡上:
python main.py ctdet --exp_id food --batch_size 32 --lr 1.25e-4 --gpus 0,1 --load_model ../models/ctdet_dla_2x.pth --master_batch_size 8
如果运行报错,可参考以下多GPU训练语句
CUDA_VISIBLE_DEVICES=0,3 python -m torch.distributed.launch --nproc_per_node=2 --use_env train_multi_GPU.py
7.4.4 断点恢复训练,比如你将结果保存在这个exp_id=food,那么food文件夹下就会有model_last.pth这个,想继续恢复训练:
python main.py ctdet --exp_id food --batch_size 32 --lr 1.25e-4 --gpus 0 --resume
若提示报错,则尝试修改opts文件中的num_workers改为0,或者将batch_size调小。
训练完成后,在./exp/ctdet/food/文件夹下会出现一堆文件;
其中,model_last是最后一次epoch的模型;model_best是val最好的模型;
7.5 验证模型
运行demo文件检查下训练的模型,–demo设置你要预测的图片/图片文件夹/视频所在的路径;
也可以加入参数–debug 2 查看heatMap输出效果
7.5.1 原始预测
python demo.py ctdet --demo ../data/food/images/food1.jpg --load_model ../exp/ctdet/food/model_best.pth
7.5.2 带数据增强预测
python demo.py ctdet --demo ../data/food/images/food1.jpg --load_model ../exp/ctdet/food/model_best.pth --flip_test
7.5.3 多尺度预测
python demo.py ctdet --demo ../data/food/images/food1.jpg --load_model ../exp/ctdet/food/model_best.pth --test_scales 0.5,0.75,1.0,1.25,1.5
注意,如果多尺度预测报错,一般就是你自己没有编译nms
编译方法:到 path/to/CenterNet/src/lib/externels 目录下,运行
python setup.py build_ext --inplace
如果需要保存你的预测结果,可以到目录 path/to/CenterNet/src/lib/detecors/ctdet.py下,在show_results函数中的末尾加入这句:
# path替换成你所需要保存的路径,并确定这个文件夹是否存在
debugger.save_all_imgs(path='/CenterNet-master/outputs', genID=True)
或者可以:下图有默认的存储路径,需要进入相应的类函数内设置默认路径:
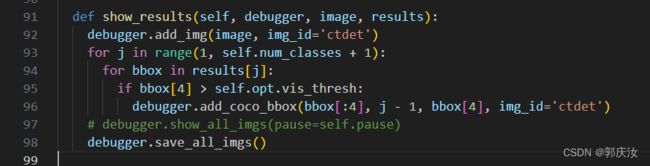
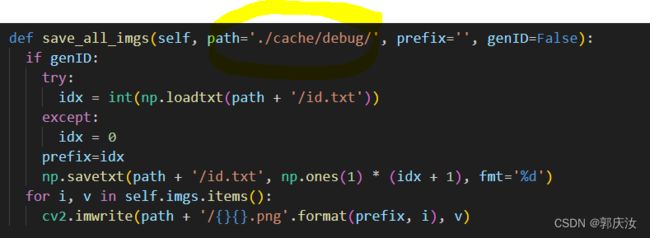
7.5.4 人体关键点检测:
python demo.py multi_pose --demo /path/to/image/or/folder/or/video/or/webcam --load_model ../models/multi_pose_dla_3x.pth
也可以加入参数–debug 2 查看heatMap输出效果
注意:也需要修改对应模块的保存路径,否则报错

7.6 测试数据
python test.py --exp_id food --not_prefetch_test ctdet --load_model ../CenterNet/exp/ctdet/food/model_best.pth
7.7 批量保存每张图片的预测结果(bbox,id,score)
7.7.1 进入到CenterNet/src/lib/utils/debugger.py,Ctrl+F找到add_coco_bbox()这个方法,将方法替换为
def add_coco_bbox(self, bbox, cat, conf=1, show_txt=True, img_id='default'):
bbox = np.array(bbox, dtype=np.int32)
# cat = (int(cat) + 1) % 80
cat = int(cat)
# print('cat', cat, self.names[cat])
c = self.colors[cat][0][0].tolist()
if self.theme == 'white':
c = (255 - np.array(c)).tolist()
txt = '{}{:.1f}'.format(cat, conf)
bbox_info = [int(bbox[0]), int(bbox[1]), int(bbox[2]), int(bbox[3])]
info = [bbox_info, self.names[cat], float(conf)]
font = cv2.FONT_HERSHEY_SIMPLEX
cat_size = cv2.getTextSize(txt, font, 0.5, 2)[0]
cv2.rectangle(
self.imgs[img_id], (bbox[0], bbox[1]), (bbox[2], bbox[3]), c, 2)
if show_txt:
cv2.rectangle(self.imgs[img_id],
(bbox[0], bbox[1] - cat_size[1] - 2),
(bbox[0] + cat_size[0], bbox[1] - 2), c, -1)
cv2.putText(self.imgs[img_id], txt, (bbox[0], bbox[1] - 2),
font, 0.5, (0, 0, 0), thickness=1, lineType=cv2.LINE_AA)
return info
这里info便保存了每张图片的每个预测框,对应的类别和置信度信息。
7.7.2 进入到CenterNet/src/lib/detectors/ctdet.py,这个文件夹当中,找到show_results这个方法,替换为
def show_results(self, debugger, image, results):
debugger.add_img(image, img_id='ctdet')
infos = []
for j in range(1, self.num_classes + 1):
for bbox in results[j]:
if bbox[4] > self.opt.vis_thresh:
info = debugger.add_coco_bbox(bbox[:4], j - 1, bbox[4], img_id='ctdet')
infos.append(info)
debugger.show_all_imgs(pause=self.pause)
return infos
7.7.3 进入到CenterNet/src/lib/detectors/base_detector.py,找到run这个方法,替换为:
def run(self, image_or_path_or_tensor, meta=None):
load_time, pre_time, net_time, dec_time, post_time = 0, 0, 0, 0, 0
merge_time, tot_time = 0, 0
debugger = Debugger(dataset=self.opt.dataset, ipynb=(self.opt.debug == 3),
theme=self.opt.debugger_theme)
start_time = time.time()
pre_processed = False
if isinstance(image_or_path_or_tensor, np.ndarray):
image = image_or_path_or_tensor
elif type(image_or_path_or_tensor) == type(''):
image = cv2.imread(image_or_path_or_tensor)
else:
image = image_or_path_or_tensor['image'][0].numpy()
pre_processed_images = image_or_path_or_tensor
pre_processed = True
loaded_time = time.time()
load_time += (loaded_time - start_time)
detections = []
for scale in self.scales: # scales = [1]
scale_start_time = time.time()
if not pre_processed:
# 运行这里
images, meta = self.pre_process(image, scale, meta)
else:
# import pdb; pdb.set_trace()
images = pre_processed_images['images'][scale][0]
meta = pre_processed_images['meta'][scale]
meta = {k: v.numpy()[0] for k, v in meta.items()}
images = images.to(self.opt.device)
torch.cuda.synchronize()
pre_process_time = time.time()
pre_time += pre_process_time - scale_start_time
output, dets, forward_time = self.process(images, return_time=True)
torch.cuda.synchronize()
net_time += forward_time - pre_process_time
decode_time = time.time()
dec_time += decode_time - forward_time
if self.opt.debug >= 2:
self.debug(debugger, images, dets, output, scale)
dets = self.post_process(dets, meta, scale)
torch.cuda.synchronize()
post_process_time = time.time()
post_time += post_process_time - decode_time
detections.append(dets)
results = self.merge_outputs(detections)
torch.cuda.synchronize()
end_time = time.time()
merge_time += end_time - post_process_time
tot_time += end_time - start_time
if self.opt.debug >= 1:
info = self.show_results(debugger, image, results)
return {'results': results, 'tot': tot_time, 'load': load_time,
'pre': pre_time, 'net': net_time, 'dec': dec_time,
'post': post_time, 'merge': merge_time}, info
7.7.4 最后将CenterNet/src/demo.py 这个文件的内容替换为:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import _init_paths
import os
import cv2
import json
from opts import opts
from detectors.detector_factory import detector_factory
image_ext = ['jpg', 'jpeg', 'png', 'webp']
video_ext = ['mp4', 'mov', 'avi', 'mkv']
time_stats = ['tot', 'load', 'pre', 'net', 'dec', 'post', 'merge']
def demo():
os.environ['CUDA_VISIBLE_DEVICES'] = opt.gpus_str
opt.debug = max(opt.debug, 1)
Detector = detector_factory[opt.task]
detector = Detector(opt)
if opt.demo == 'webcam' or \
opt.demo[opt.demo.rfind('.') + 1:].lower() in video_ext:
cam = cv2.VideoCapture(0 if opt.demo == 'webcam' else opt.demo)
detector.pause = False
while True:
_, img = cam.read()
cv2.imshow('input', img)
ret = detector.run(img)
time_str = ''
for stat in time_stats:
time_str = time_str + '{} {:.3f}s |'.format(stat, ret[stat])
print(time_str)
if cv2.waitKey(1) == 27:
return # esc to quit
else:
if os.path.isdir(opt.demo):
image_names = []
ls = os.listdir(opt.demo)
for file_name in sorted(ls):
ext = file_name[file_name.rfind('.') + 1:].lower()
if ext in image_ext:
image_names.append(os.path.join(opt.demo, file_name))
else:
image_names = [opt.demo]
results = {}
for (image_name) in image_names:
ret, info = detector.run(image_name)
save_name = image_name.split('/')[-1]
results[save_name] = info
time_str = ''
for stat in time_stats:
time_str = time_str + '{} {:.3f}s |'.format(stat, ret[stat])
print(time_str)
results_str = json.dumps(results)
with open(opt.save_dir+"/{}.json".format(opt.exp_id), 'w') as json_file:
json_file.write(results_str)
if __name__ == '__main__':
opt = opts().init()
demo()
上面将预测信息保存为一个json文件,保存路径可自己设置。
8、另一个版本的基于CenterNet的目标检测项目

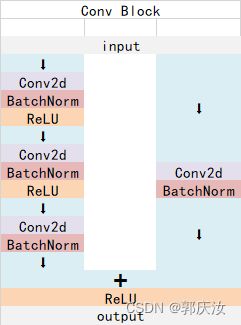
Identity Block的结构如下:

这两个都是残差网络结构。
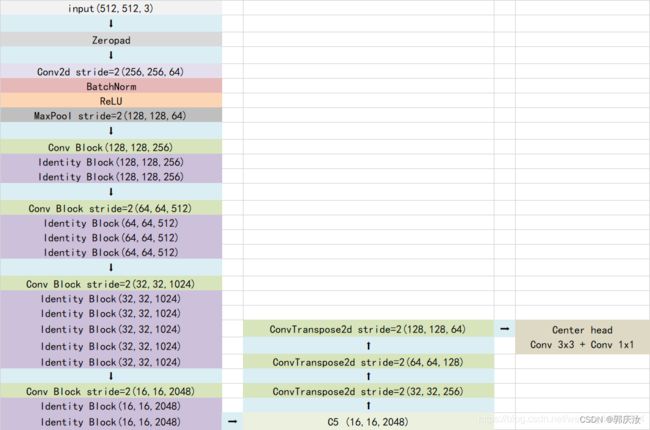
当我们输入的图片是512x512x3的时候,整体的特征层shape变化为:

我们取出最终一个block的输出进行下一步的处理。也就是图上的C5,它的shape为16x16x2048。利用主干特征提取网络,我们获取到了一个初步的特征层,其shape为16x16x2048。
from __future__ import absolute_import, division, print_function
import math
import torch.nn as nn
from torchvision.models.utils import load_state_dict_from_url
model_urls = {
'resnet18': 'https://s3.amazonaws.com/pytorch/models/resnet18-5c106cde.pth',
'resnet34': 'https://s3.amazonaws.com/pytorch/models/resnet34-333f7ec4.pth',
'resnet50': 'https://s3.amazonaws.com/pytorch/models/resnet50-19c8e357.pth',
'resnet101': 'https://s3.amazonaws.com/pytorch/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://s3.amazonaws.com/pytorch/models/resnet152-b121ed2d.pth',
}
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, stride=stride, bias=False) # change
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, # change
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
#-----------------------------------------------------------------#
# 使用Renset50作为主干特征提取网络,最终会获得一个
# 16x16x2048的有效特征层
#-----------------------------------------------------------------#
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(ResNet, self).__init__()
# 512,512,3 -> 256,256,64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
# 256x256x64 -> 128x128x64
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=0, ceil_mode=True) # change
# 128x128x64 -> 128x128x256
self.layer1 = self._make_layer(block, 64, layers[0])
# 128x128x256 -> 64x64x512
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
# 64x64x512 -> 32x32x1024
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
# 32x32x1024 -> 16x16x2048
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def resnet50(pretrained = True):
model = ResNet(Bottleneck, [3, 4, 6, 3])
if pretrained:
state_dict = load_state_dict_from_url(model_urls['resnet50'], model_dir = 'model_data/')
model.load_state_dict(state_dict)
#----------------------------------------------------------#
# 获取特征提取部分
#----------------------------------------------------------#
features = list([model.conv1, model.bn1, model.relu, model.maxpool, model.layer1, model.layer2, model.layer3, model.layer4])
features = nn.Sequential(*features)
return features
2、利用初步特征获得高分辨率特征图


class resnet50_Decoder(nn.Module):
def __init__(self, inplanes, bn_momentum=0.1):
super(resnet50_Decoder, self).__init__()
self.bn_momentum = bn_momentum
self.inplanes = inplanes
self.deconv_with_bias = False
#----------------------------------------------------------#
# 16,16,2048 -> 32,32,256 -> 64,64,128 -> 128,128,64
# 利用ConvTranspose2d进行上采样。
# 每次特征层的宽高变为原来的两倍。
#----------------------------------------------------------#
self.deconv_layers = self._make_deconv_layer(
num_layers=3,
num_filters=[256, 128, 64],
num_kernels=[4, 4, 4],
)
def _make_deconv_layer(self, num_layers, num_filters, num_kernels):
layers = []
for i in range(num_layers):
kernel = num_kernels[i]
planes = num_filters[i]
layers.append(
nn.ConvTranspose2d(
in_channels=self.inplanes,
out_channels=planes,
kernel_size=kernel,
stride=2,
padding=1,
output_padding=0,
bias=self.deconv_with_bias))
layers.append(nn.BatchNorm2d(planes, momentum=self.bn_momentum))
layers.append(nn.ReLU(inplace=True))
self.inplanes = planes
return nn.Sequential(*layers)
def forward(self, x):
return self.deconv_layers(x)
3、Center Head从特征获取预测结果

class resnet50_Head(nn.Module):
def __init__(self, num_classes=80, channel=64, bn_momentum=0.1):
super(resnet50_Head, self).__init__()
#-----------------------------------------------------------------#
# 对获取到的特征进行上采样,进行分类预测和回归预测
# 128, 128, 64 -> 128, 128, 64 -> 128, 128, num_classes
# -> 128, 128, 64 -> 128, 128, 2
# -> 128, 128, 64 -> 128, 128, 2
#-----------------------------------------------------------------#
# 热力图预测部分
self.cls_head = nn.Sequential(
nn.Conv2d(64, channel,
kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(64, momentum=bn_momentum),
nn.ReLU(inplace=True),
nn.Conv2d(channel, num_classes,
kernel_size=1, stride=1, padding=0))
# 宽高预测的部分
self.wh_head = nn.Sequential(
nn.Conv2d(64, channel,
kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(64, momentum=bn_momentum),
nn.ReLU(inplace=True),
nn.Conv2d(channel, 2,
kernel_size=1, stride=1, padding=0))
# 中心点预测的部分
self.reg_head = nn.Sequential(
nn.Conv2d(64, channel,
kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(64, momentum=bn_momentum),
nn.ReLU(inplace=True),
nn.Conv2d(channel, 2,
kernel_size=1, stride=1, padding=0))
def forward(self, x):
hm = self.cls_head(x).sigmoid_()
wh = self.wh_head(x)
offset = self.reg_head(x)
return hm, wh, offset
4、预测结果的解码

def pool_nms(heat, kernel = 3):
pad = (kernel - 1) // 2
hmax = nn.functional.max_pool2d(heat, (kernel, kernel), stride=1, padding=pad)
keep = (hmax == heat).float()
return heat * keep
def decode_bbox(pred_hms, pred_whs, pred_offsets, confidence, cuda):
#-------------------------------------------------------------------------#
# 当利用512x512x3图片进行coco数据集预测的时候
# h = w = 128 num_classes = 80
# Hot map热力图 -> b, 80, 128, 128,
# 进行热力图的非极大抑制,利用3x3的卷积对热力图进行最大值筛选
# 找出一定区域内,得分最大的特征点。
#-------------------------------------------------------------------------#
pred_hms = pool_nms(pred_hms)
b, c, output_h, output_w = pred_hms.shape
detects = []
#-------------------------------------------------------------------------#
# 只传入一张图片,循环只进行一次
#-------------------------------------------------------------------------#
for batch in range(b):
#-------------------------------------------------------------------------#
# heat_map 128*128, num_classes 热力图
# pred_wh 128*128, 2 特征点的预测宽高
# pred_offset 128*128, 2 特征点的xy轴偏移情况
#-------------------------------------------------------------------------#
heat_map = pred_hms[batch].permute(1, 2, 0).view([-1, c])
pred_wh = pred_whs[batch].permute(1, 2, 0).view([-1, 2])
pred_offset = pred_offsets[batch].permute(1, 2, 0).view([-1, 2])
yv, xv = torch.meshgrid(torch.arange(0, output_h), torch.arange(0, output_w))
#-------------------------------------------------------------------------#
# xv 128*128, 特征点的x轴坐标
# yv 128*128, 特征点的y轴坐标
#-------------------------------------------------------------------------#
xv, yv = xv.flatten().float(), yv.flatten().float()
if cuda:
xv = xv.cuda()
yv = yv.cuda()
#-------------------------------------------------------------------------#
# class_conf 128*128, 特征点的种类置信度
# class_pred 128*128, 特征点的种类
#-------------------------------------------------------------------------#
class_conf, class_pred = torch.max(heat_map, dim = -1)
mask = class_conf > confidence
#-----------------------------------------#
# 取出得分筛选后对应的结果
#-----------------------------------------#
pred_wh_mask = pred_wh[mask]
pred_offset_mask = pred_offset[mask]
if len(pred_wh_mask) == 0:
detects.append([])
continue
#----------------------------------------#
# 计算调整后预测框的中心
#----------------------------------------#
xv_mask = torch.unsqueeze(xv[mask] + pred_offset_mask[..., 0], -1)
yv_mask = torch.unsqueeze(yv[mask] + pred_offset_mask[..., 1], -1)
#----------------------------------------#
# 计算预测框的宽高
#----------------------------------------#
half_w, half_h = pred_wh_mask[..., 0:1] / 2, pred_wh_mask[..., 1:2] / 2
#----------------------------------------#
# 获得预测框的左上角和右下角
#----------------------------------------#
bboxes = torch.cat([xv_mask - half_w, yv_mask - half_h, xv_mask + half_w, yv_mask + half_h], dim=1)
bboxes[:, [0, 2]] /= output_w
bboxes[:, [1, 3]] /= output_h
detect = torch.cat([bboxes, torch.unsqueeze(class_conf[mask],-1), torch.unsqueeze(class_pred[mask],-1).float()], dim=-1)
detects.append(detect)
return detects

import math
import cv2
import numpy as np
from PIL import Image
from torch.utils.data.dataset import Dataset
from utils.utils import cvtColor, preprocess_input
def draw_gaussian(heatmap, center, radius, k=1):
diameter = 2 * radius + 1
gaussian = gaussian2D((diameter, diameter), sigma=diameter / 6)
x, y = int(center[0]), int(center[1])
height, width = heatmap.shape[0:2]
left, right = min(x, radius), min(width - x, radius + 1)
top, bottom = min(y, radius), min(height - y, radius + 1)
masked_heatmap = heatmap[y - top:y + bottom, x - left:x + right]
masked_gaussian = gaussian[radius - top:radius + bottom, radius - left:radius + right]
if min(masked_gaussian.shape) > 0 and min(masked_heatmap.shape) > 0: # TODO debug
np.maximum(masked_heatmap, masked_gaussian * k, out=masked_heatmap)
return heatmap
def gaussian2D(shape, sigma=1):
m, n = [(ss - 1.) / 2. for ss in shape]
y, x = np.ogrid[-m:m + 1, -n:n + 1]
h = np.exp(-(x * x + y * y) / (2 * sigma * sigma))
h[h < np.finfo(h.dtype).eps * h.max()] = 0
return h
def gaussian_radius(det_size, min_overlap=0.7):
height, width = det_size
a1 = 1
b1 = (height + width)
c1 = width * height * (1 - min_overlap) / (1 + min_overlap)
sq1 = np.sqrt(b1 ** 2 - 4 * a1 * c1)
r1 = (b1 + sq1) / 2
a2 = 4
b2 = 2 * (height + width)
c2 = (1 - min_overlap) * width * height
sq2 = np.sqrt(b2 ** 2 - 4 * a2 * c2)
r2 = (b2 + sq2) / 2
a3 = 4 * min_overlap
b3 = -2 * min_overlap * (height + width)
c3 = (min_overlap - 1) * width * height
sq3 = np.sqrt(b3 ** 2 - 4 * a3 * c3)
r3 = (b3 + sq3) / 2
return min(r1, r2, r3)
class CenternetDataset(Dataset):
def __init__(self, annotation_lines, input_shape, num_classes, train):
super(CenternetDataset, self).__init__()
self.annotation_lines = annotation_lines
self.length = len(self.annotation_lines)
self.input_shape = input_shape
self.output_shape = (int(input_shape[0]/4) , int(input_shape[1]/4))
self.num_classes = num_classes
self.train = train
def __len__(self):
return self.length
def __getitem__(self, index):
index = index % self.length
#-------------------------------------------------#
# 进行数据增强
#-------------------------------------------------#
image, box = self.get_random_data(self.annotation_lines[index], self.input_shape, random = self.train)
batch_hm = np.zeros((self.output_shape[0], self.output_shape[1], self.num_classes), dtype=np.float32)
batch_wh = np.zeros((self.output_shape[0], self.output_shape[1], 2), dtype=np.float32)
batch_reg = np.zeros((self.output_shape[0], self.output_shape[1], 2), dtype=np.float32)
batch_reg_mask = np.zeros((self.output_shape[0], self.output_shape[1]), dtype=np.float32)
if len(box) != 0:
boxes = np.array(box[:, :4],dtype=np.float32)
boxes[:, [0, 2]] = np.clip(boxes[:, [0, 2]] / self.input_shape[1] * self.output_shape[1], 0, self.output_shape[1] - 1)
boxes[:, [1, 3]] = np.clip(boxes[:, [1, 3]] / self.input_shape[0] * self.output_shape[0], 0, self.output_shape[0] - 1)
for i in range(len(box)):
bbox = boxes[i].copy()
cls_id = int(box[i, -1])
h, w = bbox[3] - bbox[1], bbox[2] - bbox[0]
if h > 0 and w > 0:
radius = gaussian_radius((math.ceil(h), math.ceil(w)))
radius = max(0, int(radius))
#-------------------------------------------------#
# 计算真实框所属的特征点
#-------------------------------------------------#
ct = np.array([(bbox[0] + bbox[2]) / 2, (bbox[1] + bbox[3]) / 2], dtype=np.float32)
ct_int = ct.astype(np.int32)
#----------------------------#
# 绘制高斯热力图
#----------------------------#
batch_hm[:, :, cls_id] = draw_gaussian(batch_hm[:, :, cls_id], ct_int, radius)
#---------------------------------------------------#
# 计算宽高真实值
#---------------------------------------------------#
batch_wh[ct_int[1], ct_int[0]] = 1. * w, 1. * h
#---------------------------------------------------#
# 计算中心偏移量
#---------------------------------------------------#
batch_reg[ct_int[1], ct_int[0]] = ct - ct_int
#---------------------------------------------------#
# 将对应的mask设置为1
#---------------------------------------------------#
batch_reg_mask[ct_int[1], ct_int[0]] = 1
image = np.transpose(preprocess_input(image), (2, 0, 1))
return image, batch_hm, batch_wh, batch_reg, batch_reg_mask
def rand(self, a=0, b=1):
return np.random.rand()*(b-a) + a
def get_random_data(self, annotation_line, input_shape, jitter=.3, hue=.1, sat=1.5, val=1.5, random=True):
line = annotation_line.split()
#------------------------------#
# 读取图像并转换成RGB图像
#------------------------------#
image = Image.open(line[0])
image = cvtColor(image)
#------------------------------#
# 获得图像的高宽与目标高宽
#------------------------------#
iw, ih = image.size
h, w = input_shape
#------------------------------#
# 获得预测框
#------------------------------#
box = np.array([np.array(list(map(int,box.split(',')))) for box in line[1:]])
if not random:
scale = min(w/iw, h/ih)
nw = int(iw*scale)
nh = int(ih*scale)
dx = (w-nw)//2
dy = (h-nh)//2
#---------------------------------#
# 将图像多余的部分加上灰条
#---------------------------------#
image = image.resize((nw,nh), Image.BICUBIC)
new_image = Image.new('RGB', (w,h), (128,128,128))
new_image.paste(image, (dx, dy))
image_data = np.array(new_image, np.float32)
#---------------------------------#
# 对真实框进行调整
#---------------------------------#
if len(box)>0:
np.random.shuffle(box)
box[:, [0,2]] = box[:, [0,2]]*nw/iw + dx
box[:, [1,3]] = box[:, [1,3]]*nh/ih + dy
box[:, 0:2][box[:, 0:2]<0] = 0
box[:, 2][box[:, 2]>w] = w
box[:, 3][box[:, 3]>h] = h
box_w = box[:, 2] - box[:, 0]
box_h = box[:, 3] - box[:, 1]
box = box[np.logical_and(box_w>1, box_h>1)] # discard invalid box
return image_data, box
#------------------------------------------#
# 对图像进行缩放并且进行长和宽的扭曲
#------------------------------------------#
new_ar = w/h * self.rand(1-jitter,1+jitter) / self.rand(1-jitter,1+jitter)
scale = self.rand(.25, 2)
if new_ar < 1:
nh = int(scale*h)
nw = int(nh*new_ar)
else:
nw = int(scale*w)
nh = int(nw/new_ar)
image = image.resize((nw,nh), Image.BICUBIC)
#------------------------------------------#
# 将图像多余的部分加上灰条
#------------------------------------------#
dx = int(self.rand(0, w-nw))
dy = int(self.rand(0, h-nh))
new_image = Image.new('RGB', (w,h), (128,128,128))
new_image.paste(image, (dx, dy))
image = new_image
#------------------------------------------#
# 翻转图像
#------------------------------------------#
flip = self.rand()<.5
if flip: image = image.transpose(Image.FLIP_LEFT_RIGHT)
#------------------------------------------#
# 色域扭曲
#------------------------------------------#
hue = self.rand(-hue, hue)
sat = self.rand(1, sat) if self.rand()<.5 else 1/self.rand(1, sat)
val = self.rand(1, val) if self.rand()<.5 else 1/self.rand(1, val)
x = cv2.cvtColor(np.array(image,np.float32)/255, cv2.COLOR_RGB2HSV)
x[..., 0] += hue*360
x[..., 0][x[..., 0]>1] -= 1
x[..., 0][x[..., 0]<0] += 1
x[..., 1] *= sat
x[..., 2] *= val
x[x[:,:, 0]>360, 0] = 360
x[:, :, 1:][x[:, :, 1:]>1] = 1
x[x<0] = 0
image_data = cv2.cvtColor(x, cv2.COLOR_HSV2RGB)*255
#---------------------------------#
# 对真实框进行调整
#---------------------------------#
if len(box)>0:
np.random.shuffle(box)
box[:, [0,2]] = box[:, [0,2]]*nw/iw + dx
box[:, [1,3]] = box[:, [1,3]]*nh/ih + dy
if flip: box[:, [0,2]] = w - box[:, [2,0]]
box[:, 0:2][box[:, 0:2]<0] = 0
box[:, 2][box[:, 2]>w] = w
box[:, 3][box[:, 3]>h] = h
box_w = box[:, 2] - box[:, 0]
box_h = box[:, 3] - box[:, 1]
box = box[np.logical_and(box_w>1, box_h>1)]
return image_data, box
# DataLoader中collate_fn使用
def centernet_dataset_collate(batch):
imgs, batch_hms, batch_whs, batch_regs, batch_reg_masks = [], [], [], [], []
for img, batch_hm, batch_wh, batch_reg, batch_reg_mask in batch:
imgs.append(img)
batch_hms.append(batch_hm)
batch_whs.append(batch_wh)
batch_regs.append(batch_reg)
batch_reg_masks.append(batch_reg_mask)
imgs = np.array(imgs)
batch_hms = np.array(batch_hms)
batch_whs = np.array(batch_whs)
batch_regs = np.array(batch_regs)
batch_reg_masks = np.array(batch_reg_masks)
return imgs, batch_hms, batch_whs, batch_regs, batch_reg_masks

def focal_loss(pred, target):
pred = pred.permute(0,2,3,1)
pos_inds = target.eq(1).float()
neg_inds = target.lt(1).float()
neg_weights = torch.pow(1 - target, 4)
pred = torch.clamp(pred, 1e-12)
pos_loss = torch.log(pred) * torch.pow(1 - pred, 2) * pos_inds
neg_loss = torch.log(1 - pred) * torch.pow(pred, 2) * neg_weights * neg_inds
num_pos = pos_inds.float().sum()
pos_loss = pos_loss.sum()
neg_loss = neg_loss.sum()
if num_pos == 0:
loss = -neg_loss
else:
loss = -(pos_loss + neg_loss) / num_pos
return loss
def reg_l1_loss(pred, target, mask):
pred = pred.permute(0,2,3,1)
expand_mask = torch.unsqueeze(mask,-1).repeat(1,1,1,2)
loss = F.l1_loss(pred * expand_mask, target * expand_mask, reduction='sum')
loss = loss / (mask.sum() + 1e-4)
return loss
c_loss = focal_loss(hm, batch_hms)
wh_loss = 0.1*reg_l1_loss(wh, batch_whs, batch_reg_masks)
off_loss = reg_l1_loss(offset, batch_regs, batch_reg_masks)
loss = c_loss + wh_loss + off_loss
loss.backward()
optimizer.step()

'''
annotation_mode用于指定该文件运行时计算的内容
annotation_mode为0代表整个标签处理过程,包括获得VOCdevkit/VOC2007/ImageSets里面的txt以及训练用的2007_train.txt、2007_val.txt
annotation_mode为1代表获得VOCdevkit/VOC2007/ImageSets里面的txt
annotation_mode为2代表获得训练用的2007_train.txt、2007_val.txt
'''
annotation_mode = 0
'''
必须要修改,用于生成2007_train.txt、2007_val.txt的目标信息
与训练和预测所用的classes_path一致即可
如果生成的2007_train.txt里面没有目标信息
那么就是因为classes没有设定正确
仅在annotation_mode为0和2的时候有效
'''
classes_path = 'model_data/voc_classes.txt'
'''
trainval_percent用于指定(训练集+验证集)与测试集的比例,默认情况下 (训练集+验证集):测试集 = 9:1
train_percent用于指定(训练集+验证集)中训练集与验证集的比例,默认情况下 训练集:验证集 = 9:1
仅在annotation_mode为0和1的时候有效
'''
trainval_percent = 0.9
train_percent = 0.9
'''
指向VOC数据集所在的文件夹
默认指向根目录下的VOC数据集
'''
VOCdevkit_path = 'VOCdevkit'

#-------------------------------#
# 是否使用Cuda
# 没有GPU可以设置成False
#-------------------------------#
Cuda = True
#--------------------------------------------------------#
# 训练前一定要修改classes_path,使其对应自己的数据集
#--------------------------------------------------------#
classes_path = 'model_data/voc_classes.txt'
#----------------------------------------------------------------------------------------------------------------------------#
# 权值文件请看README,百度网盘下载。数据的预训练权重对不同数据集是通用的,因为特征是通用的。
# 预训练权重对于99%的情况都必须要用,不用的话权值太过随机,特征提取效果不明显,网络训练的结果也不会好。
#
# 如果想要断点续练就将model_path设置成logs文件夹下已经训练的权值文件。
# 当model_path = ''的时候不加载整个模型的权值。
#
# 此处使用的是整个模型的权重,因此是在train.py进行加载的,pretrain不影响此处的权值加载。
# 如果想要让模型从主干的预训练权值开始训练,则设置model_path = '',pretrain = True,此时仅加载主干。
# 如果想要让模型从0开始训练,则设置model_path = '',pretrain = Fasle,Freeze_Train = Fasle,此时从0开始训练,且没有冻结主干的过程。
#----------------------------------------------------------------------------------------------------------------------------#
model_path = 'model_data/centernet_resnet50_voc.pth'
#------------------------------------------------------#
# 输入的shape大小,32的倍数
#------------------------------------------------------#
input_shape = [512, 512]
#-------------------------------------------#
# 主干特征提取网络的选择
# resnet50和hourglass
#-------------------------------------------#
backbone = "resnet50"
#----------------------------------------------------------------------------------------------------------------------------#
# 是否使用主干网络的预训练权重,此处使用的是主干的权重,因此是在模型构建的时候进行加载的。
# 如果设置了model_path,则主干的权值无需加载,pretrained的值无意义。
# 如果不设置model_path,pretrained = True,此时仅加载主干开始训练。
# 如果不设置model_path,pretrained = False,Freeze_Train = Fasle,此时从0开始训练,且没有冻结主干的过程。
#----------------------------------------------------------------------------------------------------------------------------#
pretrained = False
#----------------------------------------------------#
# 训练分为两个阶段,分别是冻结阶段和解冻阶段。
# 显存不足与数据集大小无关,提示显存不足请调小batch_size。
# 受到BatchNorm层影响,batch_size最小为2,不能为1。
#----------------------------------------------------#
#----------------------------------------------------#
# 冻结阶段训练参数
# 此时模型的主干被冻结了,特征提取网络不发生改变
# 占用的显存较小,仅对网络进行微调
#----------------------------------------------------#
Init_Epoch = 0
Freeze_Epoch = 50
Freeze_batch_size = 16
Freeze_lr = 1e-3
#----------------------------------------------------#
# 解冻阶段训练参数
# 此时模型的主干不被冻结了,特征提取网络会发生改变
# 占用的显存较大,网络所有的参数都会发生改变
#----------------------------------------------------#
UnFreeze_Epoch = 100
Unfreeze_batch_size = 8
Unfreeze_lr = 1e-4
#------------------------------------------------------#
# 是否进行冻结训练,默认先冻结主干训练后解冻训练。
#------------------------------------------------------#
Freeze_Train = True
#------------------------------------------------------#
# 用于设置是否使用多线程读取数据
# 开启后会加快数据读取速度,但是会占用更多内存
# 内存较小的电脑可以设置为2或者0
#------------------------------------------------------#
num_workers = 4
#----------------------------------------------------#
# 获得图片路径和标签
#----------------------------------------------------#
train_annotation_path = '2007_train.txt'
val_annotation_path = '2007_val.txt'
