Zama TFHE-rs白皮书(1)
1. 引言
前序博客有:
- 基于[Discretized] Torus的全同态加密指引(1)
- 基于[Discretized] Torus的全同态加密指引(2)
- TFHE——基于[Discretized] Torus的全同态加密 代码解析
- Zama TFHE-rs
Zama TFHE-rs白皮书,见:
- Zama团队Ilaria Chillotti、Marc Joye、Pascal Paillier论文《Programmable Bootstrapping Enables Efficient Homomorphic Inference of Deep Neural Networks∗》
很多情况下,人们认为机器学习和隐私是对立的。对于包含敏感数据的情况,隐私尤其受关注。本文实现了具有隐私保护的深度神经网络推理。
Zama TFHE-rs为首个TFHE全同态加密方案尝试,其底层关键技术为programmable bootstrapping:
- 支持对密文的任意函数的同态evaluation,具备可控的噪声。
- 与之前的成果相比,无需对模型进行重新训练。
本文基本结构为:
- 1)回顾一些有用概念的定义,以及确定一些标记法。
- 2)介绍了TFHE方案的离散化变种。同时详述了如何对密文做基础leveled operations。
- 3)展示了本文核心技术:programmable bootstrapping。首先介绍了常规bootstrapping,然后将其归纳为programmable bootstrapping。
- 4)将本文成果用于神经网络同态评估。 描述了常用于构建神经网络的不同layers,及其使用本文架构的实现。
- 5)汇总了一些试验和benchmarks。
- 6)本文结论。
1.1 机器学习革命
从数据中学习的基本前提是从一组观察结果中揭示一个过程。机器学习在提取有用信息方面非常有效,并且可在给定数据和期望目标的情况下动态适应特定任务。因此,与经典的统计方法不同,机器学习从数据本身学习模型的重要影响因素。
机器学习可开发许多应用程序:回归、分类、推荐、聚类、异常检测等等。如今,机器学习被广泛应用于各个行业,并提供多种服务,包括:
- 欺诈检测
- 风险管理
- 人脸识别
- 辅助驾驶
- 电子邮件分类
- 自动翻译
- 医疗诊断等。
1.2 隐私需求
机器学习算法在很多领域都很有用,但其处理的数据类型通常是敏感的。典型例子有:
- 根据DNA样本探测特定基因疾病
- 人脸识别
- 邮件分类等等。
这些例子中,机器学习算法所处理的数据包含了用户的私人信息,且可被用于很多其它场景——从广告定投,到,勒索,甚至某些情况下的威胁。这也是为何包含机器学习应用程序中所使用的数据是至关重要的。
处理用户数据的公司所必须遵守的最新法规(如欧洲的GDPR(通用数据保护条例)或美国的CCPA(加州消费者隐私法)),也推动了隐私要求。
1.3 全同态加密
对于数据保护,密码学技术是一种可选策略。但传统的加密算法只是在数据传输或静止时保护数据。事实上,传统加密方案的一个局限性和结构特性是:
- 数据在处理之前首先需要解密。
因此,传统加密方案 不适用于机器学习应用程序。
对于传统的加密方案,隐私控制权掌握在加密数据的接收者手中。一种根本不同的方法是依赖全同态加密(FHE)。FHE在1978年首次提出挑战,直到2009年Gentry的突破性结果才解决。与传统的加密方案相比,全同态加密方案允许接收方直接对加密数据进行操作。
基于FHE的方法非常适合机器学习即服务(MLaaS,Machine-learning-as-a-service)的用例。一个典型的应用场景如下图所示。它涉及用户将数据发送到为给定任务(如,医疗诊断)运行经过训练的模型的服务提供商(服务端)。

1.4 噪声控制
Gentry成果的核心在于自举(bootstrapping)技术。全同态加密方案的所有已知实例都会产生带噪声密文。对这些密文运行同态运算反过来又增加了所得密文中的噪声水平。在某个时刻,密文中存在的噪声可能变得太大,且密文不再是可解密的。支持预定噪声阈值的同态加密方案被称为leveled(或homomorphic)。bootstrapping是一种允许刷新密文的通用技术。因此,它能够将leveled同态加密方案转化为全同态加密方案,从而能evaluate密文上的任何可能函数。自举背后的关键思想是对解密电路进行同态evaluate。为了执行自举过程,必须提供(与用于产生密文的加密密钥相匹配的)解密密钥的加密,该加密被称为自举密钥。如下图所示:

Gentry论文之后的研究旨在提出新的方案或改进自举,以提高FHE在实践中的效率。最著名的结构是DGHV[13]、BGV[7]、GSW[18]及其变体。虽然相继提出的结构使自举更加实用,但它仍然构成了瓶颈(每次自举需要几分钟时间)。Ducas和Micciancio[15]后来设计了一种基于GSW类型方案的更快的自举,将自举时间缩短到了一瞬间。他们的技术得到了进一步的改进和完善,这导致了TFHE方案的发展[12]。
1.5 本文技术和贡献
本文基于state-of-the-art TFHE方案,并将TFHE技术扩展至深度神经网络的同态evaluate。
TFHE有2种运行方式:
- 1)leveled TFHE:支持线性组合和预定数量的乘积次数。leveled TFHE方式下,其evaluate operations会让噪声总是增长。
- 可用于evaluate small-depth电路。
- 2)bootstrapped TFHE:一旦噪声超过特定阈值时,通过将噪声降到指定级别,可很好地控制噪声。此外,bootstrapped方式是可编程的,从而支持对更复杂函数的evaluate。对于具有large depth电路的问题,仅bootstrapped TFHE方式才是可行的。深度神经网络,就属于具有large depth电路的问题。
早期的研究成果,尝试使用全同态加密来对神经网络进行evaluate:
- cryptonets[14]为首个以此为目标的论文。其能够针对MNIST数据集在5层上进行同态推理[24]。为了限制噪声的增长,用平方函数代替了标准的激活函数。底层加密方案是YASHE[4]的leveled版本。
- 随后的许多论文都采用了类似的方法,并在各个方向上进行了改进。其中,值得一提的是iDASH竞赛的结果[20],其目标是在基因组分析的背景下找到保护隐私的解决方案。最近两个版本的同态加密轨道的获胜解决方案(即2018年的[3,22]和2019年的[21])都有共同点,都依赖于leveled同态加密。
然而,leveled解决方案在其可执行的任务类型方面受到固有的限制。特别是,在神经网络场景,leveled解决方案只能容纳具有适度层数的网络。在本文,想强调的是,depth不再一定是一个问题,深度神经网络实际上可以用同态来evaluate。对于一种特殊类型的网络,Bourse等人的一篇论文[6]已经指出了这一点:特别地,对于signals被限制在set { − 1 , 1 } \{−1,1\} {−1,1} 且激活函数是sign函数的离散化神经网络。其可扩展构建的核心是TFHE方案的自适应,以便能够在自举步骤期间评估[非线性]sign函数。在最近的一项工作中,Boura等人[5]研究了全同态加密对classical经典深度神经网络的适用性。他们通过将正态分布中的噪声值添加到中间值来模拟噪声传播的影响,同时对模型进行清晰的评估。这些实验是用利用标准ReLU激活函数的模型进行的,但也用利用其FHE友好变体的模型进行。通过用FHE友好的average-pooling层替换max-pooling层来运行类似的实验。作为他们研究的结论,[5]的作者建议支持FHE友好操作,因为它们通常对噪声扰动更有弹性。
本文与之前的研究方向有所不同。本文不寻求设计新的操作或修改拓扑结构,以使某特定神经网络更适合基于FHE的实现。相反,本文坚持使用原始的神经网络模型。这提供了不需要重新训练新模型的巨大优势。由于操作和拓扑结构不变,已经训练好的模型可按原样使用。训练神经网络的努力不应被忽视。这是一项既昂贵又耗时的操作。此外,在许多情况下,生成新模型甚至是不可能的,因为这意味着可访问训练数据集,这可能需要数据所有者或一些监管机构的事先批准。
本文,通过可编程自举技术和分级操作(leveled operations)的结合,实现了对复杂函数的evaluate:
- 可编程意味着可获得输入密文的任何函数(包括非线性函数)作为自举的输出。有趣的是,生成的密文具有可控的噪声水平。因此,这个过程可以反复迭代。因此,在机器学习应用的情况下,神经网络的深度可以任意大。本文技术是高效的,可直接对选定大小的words进行操作。
2. 准备工作
2.1 Torus和Torus多项式
TFHE中的‘T’,是指real torus T = R / Z \mathbb{T}=\mathbb{R/Z} T=R/Z,即为real numbers modulo 1 1 1的集合。
T \mathbb{T} T中任意2个元素可added modulo 1 1 1: ( T , + ) (\mathbb{T,+}) (T,+)会形成一个abelian group。
但, T \mathbb{T} T不是ring,因未定义torus元素的internal product × \times ×。
但定义了整数与torus元素的external product ⋅ \cdot ⋅:
- 已知 k ∈ Z k\in\mathbb{Z} k∈Z和 t ∈ T t\in\mathbb{T} t∈T,元素 k ⋅ t ∈ T k\cdot t\in\mathbb{T} k⋅t∈T定义为:
- 若 k ≥ 0 k\geq 0 k≥0,则 k ⋅ t = t + ⋯ + t ( ∣ k ∣ 倍) k\cdot t=t+\cdots+t(|k|倍) k⋅t=t+⋯+t(∣k∣倍)。
- 若 k < 0 k<0 k<0,则 k ⋅ t = ( − k ) ⋅ ( − t ) = ( − t ) + ⋯ + ( − t ) ( ∣ k ∣ 倍) k\cdot t=(-k)\cdot (-t)=(-t)+\cdots+(-t)(|k|倍) k⋅t=(−k)⋅(−t)=(−t)+⋯+(−t)(∣k∣倍)。
- 数学上, T \mathbb{T} T具有 Z \mathbb{Z} Z-module结构,对于任意的 k , l ∈ Z k,l\in\mathbb{Z} k,l∈Z和 a , b ∈ T a,b\in\mathbb{T} a,b∈T,有:
- ( k + l ) ⋅ a = k ⋅ a + l ⋅ a (k+l)\cdot a=k\cdot a+l\cdot a (k+l)⋅a=k⋅a+l⋅a
- k ⋅ ( a + b ) = k ⋅ a + k ⋅ b k\cdot (a+b)=k\cdot a+k\cdot b k⋅(a+b)=k⋅a+k⋅b
- external product是同态的,对于任意的 k , l ∈ Z k,l\in\mathbb{Z} k,l∈Z和 t ∈ T t\in\mathbb{T} t∈T,有:
k ⋅ ( l ⋅ t ) = ( k l ) ⋅ t k\cdot (l\cdot t)=(kl)\cdot t k⋅(l⋅t)=(kl)⋅t
定义torus多项式,以让密码学运算更可行。
令 Φ : = Φ ( X ) \Phi:=\Phi(X) Φ:=Φ(X)表示 M M M-th cyclotomic多项式(即,对于任意的 k < M k
基于性能考虑,选 M M M为power of 2 2 2,这样有 N = M / 2 N=M/2 N=M/2和 Φ ( X ) = X N + 1 \Phi(X)=X^N+1 Φ(X)=XN+1。
考虑多项式rings R N [ X ] : = R [ X ] / ( X N + 1 ) \mathbb{R}_N[X]:=\mathbb{R}[X]/(X^N+1) RN[X]:=R[X]/(XN+1)和 Z N [ X ] : = Z [ X ] / ( X N + 1 ) \mathbb{Z}_N[X]:=\mathbb{Z}[X]/(X^N+1) ZN[X]:=Z[X]/(XN+1),定义 Z N [ X ] \mathbb{Z}_N[X] ZN[X]-module为:
T N [ X ] : = R N [ X ] / Z N [ X ] = T [ X ] / ( X N + 1 ) \mathbb{T}_N[X]:=\mathbb{R}_N[X]/\mathbb{Z}_N[X]=\mathbb{T}[X]/(X^N+1) TN[X]:=RN[X]/ZN[X]=T[X]/(XN+1)
即 Z N [ X ] \mathbb{Z}_N[X] ZN[X]元素,可看成是模 X N + 1 X^N+1 XN+1的多项式,该多项式的系数为real torus T \mathbb{T} T。
由于是 Z N [ X ] \mathbb{Z}_N[X] ZN[X]-module的, T N [ X ] \mathbb{T}_N[X] TN[X]元素可相加,且与 Z N [ X ] \mathbb{Z}_N[X] ZN[X]多项式(外)乘。
向量可看成是行矩阵,并以粗体字表示。 Z \mathbb{Z} Z或 T \mathbb{T} T中元素以罗马字体表示,而多项式以书法体表示。
- B \mathbb{B} B为整数子集 { 0 , 1 } \{0,1\} {0,1}。
- N N N为power of 2 2 2。
- B N [ X ] \mathbb{B}_N[X] BN[X]为 Z N [ X ] \mathbb{Z}_N[X] ZN[X]中多项式子集, B N [ X ] \mathbb{B}_N[X] BN[X]内元素多项式的系数为 B \mathbb{B} B元素(即为 0 0 0或 1 1 1)。
- 向量 z ∈ ( Z / q Z ) n \mathbf{z}\in(\mathbb{Z}/q\mathbb{Z})^n z∈(Z/qZ)n,其norm ∣ ∣ z ∣ ∣ ||\mathbf{z}|| ∣∣z∣∣定义为 Z n \mathbb{Z}^n Zn中 z ∈ ( Z / q Z ) n \mathbf{z}\in(\mathbb{Z}/q\mathbb{Z})^n z∈(Z/qZ)n等价classes之间的最短norm。
- Z N [ X ] \mathbb{Z}_N[X] ZN[X]中的多项式,可 以 Z N \mathbb{Z}^N ZN向量表示:即对于多项式 p = p 0 + p 1 X + ⋯ + p N − 1 X N − 1 \mathfrak{p}=p_0+p_1X+\cdots +p_{N-1}X^{N-1} p=p0+p1X+⋯+pN−1XN−1,关联的向量为 ( p 0 , p 1 , ⋯ , p N − 1 ) (p_0,p_1,\cdots,p_{N-1}) (p0,p1,⋯,pN−1)。
- 多项式的norm,定义为其关联向量的norm。
2.2 概率分布
将使用2种概率分布:
- 1)均匀分布uniform distribution,表示为 U \mathcal{U} U。若均匀分布 U \mathcal{U} U定义于间隔 [ a , b ] [a,b] [a,b],可表示为 U [ a , b ] \mathcal{U}[a,b] U[a,b]。离散间隔以双括号表示为 ⟦ a , b ⟧ \llbracket a,b\rrbracket [[a,b]]。
- 2)高斯分布(又名正态分布)normal(a.k.a Gaussian)distribution,表示为 N \mathcal{N} N。正态分布以均值 μ \mu μ和方差 σ 2 \sigma^2 σ2来表示为 N ( μ , σ 2 ) \mathcal{N}(\mu,\sigma^2) N(μ,σ2)。基于实数的正态分布,推导出,基于 Z / q Z \mathbb{Z}/q\mathbb{Z} Z/qZ的离散化正态分布:对于实数 X ∈ R X\in\mathbb{R} X∈R,对应某正数 Z = ⌈ x q ⌋ ( m o d q ) Z=\lceil xq\rfloor (\mod q) Z=⌈xq⌋(modq),其中 − q / 2 ≤ Z ≤ q / 2 -q/2\leq Z\leq q/2 −q/2≤Z≤q/2。
若 D \mathcal{D} D为基于某space S S S的某分布,则 s ← D ( S ) s\leftarrow \mathcal{D}(S) s←D(S)表示 s s s为根据 D \mathcal{D} D从 S S S中随机选择的, s ← U ( S ) s\leftarrow \mathcal{U}(S) s←U(S)可简写为 s ← § S s\xleftarrow{\S} S s§S。
2.3 复杂度假设
2005年,Regev [28] 引入了learning with errors(LWE)problem。并随后在[25, 30] 将其归纳扩展到ring结构。
TFHE的安全性依赖于:
- torus-based problems的hardness。此处的所谓torus-based problems,是指:
- 基于torus的LWE假设
- 和 基于torus的GLWE假设
Definition 1(基于torus的LWE难题):
- 令 n ∈ N n\in\mathbb{N} n∈N, s = ( s 1 , ⋯ , s n ) ← § B n \mathbf{s}=(s_1,\cdots,s_n)\xleftarrow{\S}\mathbb{B}^n s=(s1,⋯,sn)§Bn, X \mathcal{X} X为基于 R \mathbb{R} R的error分布。基于torus的LWE难题,是指区分如下2种分布:
D 0 = { ( a , r ) ∣ a ← § T n , r ← § T } \mathcal{D}_0=\{(\mathbf{a},r)|\mathbf{a}\xleftarrow{\S}\mathbb{T}^n,r\xleftarrow{\S}\mathbb{T}\} D0={(a,r)∣a§Tn,r§T}
D 1 = { ( a , r ) ∣ a = ( a 1 , ⋯ , a n ) ← § T n , r = ∑ j = 1 n s j ⋅ a j + e , e ← X } \mathcal{D}_1=\{(\mathbf{a},r)|\mathbf{a}=(a_1,\cdots,a_n)\xleftarrow{\S}\mathbb{T}^n,r=\sum_{j=1}^{n}s_j\cdot a_j+e,e\leftarrow \mathcal{X}\} D1={(a,r)∣a=(a1,⋯,an)§Tn,r=∑j=1nsj⋅aj+e,e←X}
Definition 2(基于torus的GLWE难题):
- 令 N , k ∈ N N,k\in\mathbb{N} N,k∈N且 N N N为power of 2 2 2, s = ( s 1 , ⋯ , s k ) ← § B N [ X ] k \mathfrak{s}=(\mathfrak{s}_1,\cdots,\mathfrak{s}_k)\xleftarrow{\S}\mathbb{B}_N[X]^k s=(s1,⋯,sk)§BN[X]k, X \mathcal{X} X为基于 R N [ X ] \mathbb{R}_N[X] RN[X]的error分布。基于torus的GLWE难题,是指区分如下2种分布:
D 0 = { ( a , r ) ∣ a ← § T N [ X ] k , r ← § T N [ X ] } \mathcal{D}_0=\{(\mathfrak{a},\mathfrak{r})|\mathfrak{a}\xleftarrow{\S}\mathbb{T}_N[X]^k,\mathfrak{r}\xleftarrow{\S}\mathbb{T}_N[X]\} D0={(a,r)∣a§TN[X]k,r§TN[X]}
D 1 = { ( a , r ) ∣ a = ( a 1 , ⋯ , a k ) ← § T N [ X ] k , r = ∑ j = 1 k s j ⋅ a j + e , e ← X } \mathcal{D}_1=\{(\mathfrak{a},\mathfrak{r})|\mathfrak{a}=(\mathfrak{a}_1,\cdots,\mathfrak{a}_k)\xleftarrow{\S}\mathbb{T}_N[X]^k,\mathfrak{r}=\sum_{j=1}^{k}\mathfrak{s}_j\cdot \mathfrak{a}_j+e,e\leftarrow \mathcal{X}\} D1={(a,r)∣a=(a1,⋯,ak)§TN[X]k,r=∑j=1ksj⋅aj+e,e←X}
decisional LWE假设(或decisional GLWE假设),是指对于某安全参数 λ \lambda λ,有 n : = n ( λ ) , X : = X ( λ ) n:=n(\lambda),\mathcal{X}:=\mathcal{X}(\lambda) n:=n(λ),X:=X(λ)(或, N : = N ( λ ) , k : = k ( λ ) , X : = X ( λ ) N:=N(\lambda),k:=k(\lambda),\mathcal{X}:=\mathcal{X}(\lambda) N:=N(λ),k:=k(λ),X:=X(λ)),asserts断言,解决LWE难题(或GLWE难题)是不可行的。
3. 离散化TFHE
基于torus的LWE假设,是指,对于随机torus元素 r ∈ T r\in\mathbb{T} r∈T,即使已知torus向量 ( a 1 , ⋯ , a n ) (a_1,\cdots,a_n) (a1,⋯,an),有很难将其与 r = ∑ j = 1 n s j ⋅ a j + e r=\sum_{j=1}^{n}s_j\cdot a_j+e r=∑j=1nsj⋅aj+e区分。
torus元素 r = ∑ j = 1 n s j ⋅ a j + e r=\sum_{j=1}^{n}s_j\cdot a_j+e r=∑j=1nsj⋅aj+e可用作隐藏“明文消息” μ ∈ T \mu\in\mathbb{T} μ∈T的random mask,从而构成密文:
- c = ( a 1 , ⋯ , a n , r + μ ) ∈ T n + 1 \mathbf{c}=(a_1,\cdots,a_n,r+\mu)\in\mathbb{T}^{n+1} c=(a1,⋯,an,r+μ)∈Tn+1
其中:
- s = ( s 1 , ⋯ , s n ) ∈ B n s=(s_1,\cdots,s_n)\in\mathbb{B}^n s=(s1,⋯,sn)∈Bn承担私人加密密钥角色。
- 噪声 e e e从正态错误分布 X = N ( 0 , σ 2 ) \mathcal{X=N}(0,\sigma^2) X=N(0,σ2)中随机采样。
相应的,基于torus的GLWE假设,是指,对 T N [ X ] \mathbb{T}_N[X] TN[X]的加密机制:
- 基于key s = ( s 1 , ⋯ , s k ) ← § B N [ X ] k \mathfrak{s}=(\mathfrak{s}_1,\cdots,\mathfrak{s}_k)\xleftarrow{\S}\mathbb{B}_N[X]^k s=(s1,⋯,sk)§BN[X]k 对 μ ∈ T N [ X ] \mu\in\mathbb{T}_N[X] μ∈TN[X]的加密为: c = ( a 1 , ⋯ , a k , r + μ ) ∈ T N [ X ] k + 1 \mathfrak{c}=(\mathfrak{a}_1,\cdots,\mathfrak{a}_k,\mathfrak{r}+\mu)\in\mathbb{T}_N[X]^{k+1} c=(a1,⋯,ak,r+μ)∈TN[X]k+1
其中:
- r = ∑ j = 1 k s j ⋅ a j + e \mathfrak{r}=\sum_{j=1}^{k}\mathfrak{s}_j\cdot \mathfrak{a}_j+e r=∑j=1ksj⋅aj+e
- 噪声 e e e从基于 R N [ X ] \mathbb{R}_N[X] RN[X]的正态错误分布 X = N ( 0 , σ 2 ) \mathcal{X=N}(0,\sigma^2) X=N(0,σ2)中随机采样,即基于 R N [ X ] \mathbb{R}_N[X] RN[X]多项式,其系数源自 N ( 0 , σ 2 ) \mathcal{N}(0,\sigma^2) N(0,σ2)。
[12]中指出,LWE-based密文,为GLWE-based密文的特例情况,即 ( k , N ) = ( n , 1 ) (k,N)=(n,1) (k,N)=(n,1)。确实,当 N = 1 N=1 N=1时,有 R N [ X ] = R , Z N [ X ] = Z , T N [ X ] = T \mathbb{R}_N[X]=\mathbb{R},\mathbb{Z}_N[X]=\mathbb{Z},\mathbb{T}_N[X]=\mathbb{T} RN[X]=R,ZN[X]=Z,TN[X]=T。为让表述更通用,本文针对的GLWE设置,而LWE-based加密为GLWE的特例情况。
在大多数通用设置下,密文 c = ( a 1 , ⋯ , a k , r + μ ) \mathfrak{c}=(\mathfrak{a}_1,\cdots,\mathfrak{a}_k,\mathfrak{r}+\mu) c=(a1,⋯,ak,r+μ)为基于 T N [ X ] \mathbb{T}_N[X] TN[X]的多项式向量。这些多项式也可看成是基于 T \mathbb{T} T的向量。在实际实现中,torus元素以有限精度表示(通常为32位或64位)。令 Ω \Omega Ω表示位精度,如 Ω = 32 \Omega=32 Ω=32,是指密文元素由32位精度表示。此时,torus元素限定为 ∑ i = 1 Ω t i ⋅ 2 − i ( m o d 1 ) \sum_{i=1}^{\Omega}t_i\cdot 2^{-i}(\mod 1) ∑i=1Ωti⋅2−i(mod1)格式,其中 t i ∈ { 0 , 1 } t_i\in\{0,1\} ti∈{0,1}。
本质上,基于有限精度,是指替换 T \mathbb{T} T为submodule:
T ^ : = q − 1 Z / Z ⊂ T \hat{\mathbb{T}}:=q^{-1}\mathbb{Z}/\mathbb{Z}\sub \mathbb{T} T^:=q−1Z/Z⊂T,其中 q = 2 Ω q=2^{\Omega} q=2Ω。
且,计算是针对 T ^ N [ X ] : = T ^ [ X ] / ( X N + 1 ) \hat{\mathbb{T}}_N[X]:=\hat{\mathbb{T}}[X]/(X^N+1) T^N[X]:=T^[X]/(XN+1)。
将 1 q \frac{1}{q} q1看成是 T ^ N [ X ] \hat{\mathbb{T}}_N[X] T^N[X]中某元素,任意多项式 μ ∈ T ^ N [ X ] \mu\in\hat{\mathbb{T}}_N[X] μ∈T^N[X]可写成:
KaTeX parse error: Undefined control sequence: \cdt at position 14: \mu=\bar{\mu}\̲c̲d̲t̲ ̲\frac{1}{q}
其中:
- μ ˉ ∈ Z ^ N [ X ] \bar{\mu}\in\hat{\mathbb{Z}}_N[X] μˉ∈Z^N[X]
- Z ^ N [ X ] : = ( Z / q Z ) [ X ] / ( X N + 1 ) \hat{\mathbb{Z}}_N[X]:=(\mathbb{Z}/q\mathbb{Z})[X]/(X^N+1) Z^N[X]:=(Z/qZ)[X]/(XN+1)
3.1 message编解码
加密之前的input message,可为任意格式。编解码的角色,是让input message与加密方案兼容。
在此,需引入一些术语:
- 1)cleartext,原文,是指特定有限message space M \mathcal{M} M中的原文 m m m。
- 2)plaintext,明文,是指与加密算法匹配的明文,为将原文编码后的结果,如匹配 m m m编码后的元素 μ ˉ ∈ Z ^ N [ X ] = E n c o d e ( m ) \bar{\mu}\in\hat{\mathbb{Z}}_N[X]=Encode(m) μˉ∈Z^N[X]=Encode(m)。
对于任意的原文 m ∈ M m\in\mathcal{M} m∈M,需满足 D e c o d e ( E n c o d e ( m ) ) = m Decode(Encode(m))=m Decode(Encode(m))=m。 - 3)ciphertext,密文。是指对明文的加密结果。
令 μ ˉ = μ ˉ 0 + μ ˉ 1 X + ⋯ + μ ˉ N − 1 X N − 1 ∈ Z ^ N [ X ] \bar{\mu}=\bar{\mu}_0+\bar{\mu}_1X+\cdots+\bar{\mu}_{N-1}X^{N-1}\in\hat{\mathbb{Z}}_N[X] μˉ=μˉ0+μˉ1X+⋯+μˉN−1XN−1∈Z^N[X]为明文。因密文是待噪声的,该噪声添加到右侧(即低有效位),仅 μ ˉ i \bar{\mu}_i μˉi的upper bits用于编码原文消息。特定同态运算,要求 μ ˉ i \bar{\mu}_i μˉi的leading bits设置为 0 0 0。
大多数情况下:
- 以 w ˉ ≥ 0 \bar{w}\geq 0 wˉ≥0来表示leading bits数,又名padding bits数。
- 以 w ≥ 1 w\geq 1 w≥1,为实际表示input cleartexts的位数。即原文位数。
- 有 w ˉ + w ≤ Ω \bar{w}+w\leq \Omega wˉ+w≤Ω。
定义 p = 2 w ˉ + w p=2^{\bar{w}+w} p=2wˉ+w:
- w w w为原文的位精度。
- p p p为原文的modulus。
明文多项式 μ ˉ ∈ Z ^ N [ X ] \bar{\mu}\in\hat{\mathbb{Z}}_N[X] μˉ∈Z^N[X]的系数格式为 μ ˉ i = 2 Ω − ( w ˉ + w ) ( v ˉ i m o d 2 w ) \bar{\mu}_i=2^{\Omega-(\bar{w}+w)}(\bar{v}_i \mod 2^{w}) μˉi=2Ω−(wˉ+w)(vˉimod2w),如下图所示:

对于任意元素 x ˉ = x ˉ H q p ± x ˉ L ∈ Z / q Z \bar{x}=\bar{x}_H\frac{q}{p}\pm\bar{x}_L\in\mathbb{Z}/q\mathbb{Z} xˉ=xˉHpq±xˉL∈Z/qZ,其中 0 ≤ x ˉ L ≤ q 2 p 0\leq \bar{x}_L\leq \frac{q}{2p} 0≤xˉL≤2pq,定义返回 x ˉ H q p \bar{x}_H\frac{q}{p} xˉHpq值的Upper函数:
Z / q Z → Z / q Z , x ˉ ↦ U p p e r ( x ˉ ) \mathbb{Z}/q\mathbb{Z}\rightarrow \mathbb{Z}/q\mathbb{Z},\bar{x}\mapsto Upper(\bar{x}) Z/qZ→Z/qZ,xˉ↦Upper(xˉ),其中:
U p p e r q , p ( x ˉ ) = q p ⌈ p ∗ lift ( x ˉ ) q ⌋ ( m o d q ) Upper_{q,p}(\bar{x})=\frac{q}{p}\lceil\frac{p* \text{lift}(\bar{x})}{q}\rfloor(\mod q) Upperq,p(xˉ)=pq⌈qp∗lift(xˉ)⌋(modq)
其中:
- lift \text{lift} lift 函数,会将 Z / q Z \mathbb{Z}/q\mathbb{Z} Z/qZ元素,lift到 Z \mathbb{Z} Z元素。
- 通过对每个系数进行操作, U p p e r Upper Upper函数很自然地扩展为 Z ^ N [ X ] \hat{\mathbb{Z}}_N[X] Z^N[X]多项式。
特别地,但 q = 2 Ω , p = 2 w ˉ + w q=2^{\Omega},p=2^{\bar{w}+w} q=2Ω,p=2wˉ+w时,相应的 U p p e r Upper Upper函数为:
U p p e r q , p ( x ˉ ) = 2 Ω − ( w ˉ + w ) ⌈ 2 w ˉ + w ∗ lift ( x ˉ ) 2 Ω ⌋ ( m o d q ) Upper_{q,p}(\bar{x})=2^{\Omega-(\bar{w}+w)}\lceil\frac{2^{\bar{w}+w}* \text{lift}(\bar{x})}{2^{\Omega}}\rfloor(\mod q) Upperq,p(xˉ)=2Ω−(wˉ+w)⌈2Ω2wˉ+w∗lift(xˉ)⌋(modq)。
注意,若 x ˉ = x ˉ H 2 Ω − ( w ˉ + w ) ± x ˉ L ∈ Z / q Z \bar{x}=\bar{x}_H2^{\Omega-(\bar{w}+w)}\pm \bar{x}_L\in\mathbb{Z}/q\mathbb{Z} xˉ=xˉH2Ω−(wˉ+w)±xˉL∈Z/qZ,其中 0 ≤ x ˉ L ≤ 2 Ω − ( w ˉ + w ) − 1 0\leq \bar{x}_L\leq 2^{\Omega-(\bar{w}+w)-1} 0≤xˉL≤2Ω−(wˉ+w)−1,则 U p p e r q , p ( x ˉ ) = x ˉ H 2 Ω − ( w ˉ + w ) Upper_{q,p}(\bar{x})=\bar{x}_H2^{\Omega-(\bar{w}+w)} Upperq,p(xˉ)=xˉH2Ω−(wˉ+w)。
3.2 有限精度的GLWE加解密描述
以 G L W E ‾ \overline{GLWE} GLWE来表示有限精度的TFHE加密方案, L W E ‾ \overline{LWE} LWE为 ( k , N ) = ( n , 1 ) (k,N)=(n,1) (k,N)=(n,1)的特例情况。相应的加密方案关键算法有:
-
1) K e y G e n ( 1 λ ) KeyGen(1^{\lambda}) KeyGen(1λ):输入为安全参数 λ \lambda λ,整数 ( k , N ) (k,N) (k,N),其中 k ≥ 1 k\geq 1 k≥1, N N N为power of 2 2 2。
- 同时定义某基于 R N [ X ] \mathbb{R}_N[X] RN[X]的正态错误分布 X = N ( 0 , σ 2 ) \mathcal{X=N}(0,\sigma^2) X=N(0,σ2)。
- 随机均匀采样获得向量 s = ( s 1 , ⋯ , s k ) ← § B N [ X ] k \mathfrak{s}=(\mathfrak{s}_1,\cdots,\mathfrak{s}_k)\xleftarrow{\S}\mathbb{B}_N[X]^k s=(s1,⋯,sk)§BN[X]k。
- 明文空间为 Z ^ N [ X ] = ( Z / q Z ) [ X ] / ( X N + 1 ) \hat{\mathbb{Z}}_N[X]=(\mathbb{Z}/q\mathbb{Z})[X]/(X^N+1) Z^N[X]=(Z/qZ)[X]/(XN+1),其中 q = 2 Ω q=2^{\Omega} q=2Ω,原文modulus为 p = 2 w ˉ + w p=2^{\bar{w}+w} p=2wˉ+w,有 Ω ≥ w ˉ + w \Omega\geq \bar{w}+w Ω≥wˉ+w。
- 输出:
- 公共参数为 p p = { k , N , σ , p , q } pp=\{k,N,\sigma,p,q\} pp={k,N,σ,p,q}。
- 私钥为 s k = s sk=\mathfrak{s} sk=s。
-
2) E n c r y p t s k ( μ ˉ ) Encrypt_{sk}(\bar{\mu}) Encryptsk(μˉ):对明文 μ ˉ ∈ Z ^ N [ X ] \bar{\mu}\in\hat{\mathbb{Z}}_N[X] μˉ∈Z^N[X]的加密为:
c ˉ ← G L W E ‾ s ( μ ˉ ) : = ( a ˉ 1 , ⋯ , a ˉ k , v ˉ ) ∈ Z ^ N [ X ] k + 1 \bar{\mathfrak{c}}\leftarrow \overline{GLWE}_{\mathfrak{s}}(\bar{\mu})\\:=(\bar{\mathfrak{a}}_1,\cdots,\bar{\mathfrak{a}}_k,\bar{\mathfrak{v}})\in\hat{\mathbb{Z}}_N[X]^{k+1} cˉ←GLWEs(μˉ):=(aˉ1,⋯,aˉk,vˉ)∈Z^N[X]k+1
其中:- μ ˉ ∗ = μ ˉ + e ˉ ( m o d ( q , X N + 1 ) ) \bar{\mu}^*=\bar{\mu}+\bar{e}(\mod (q,X^N+1)) μˉ∗=μˉ+eˉ(mod(q,XN+1))
- v ˉ = ∑ j = 1 k s j a ˉ j + μ ˉ ∗ ( m o d ( q , X N + 1 ) ) \bar{\mathfrak{v}}=\sum_{j=1}^{k}\mathfrak{s}_j\bar{\mathfrak{a}}_j+\bar{\mu}^*(\mod (q,X^N+1)) vˉ=∑j=1ksjaˉj+μˉ∗(mod(q,XN+1))
- ( a ˉ 1 , ⋯ , a ˉ k ) ← § Z ^ N [ X ] k (\bar{\mathfrak{a}}_1,\cdots,\bar{\mathfrak{a}}_k)\xleftarrow{\S}\hat{\mathbb{Z}}_N[X]^{k} (aˉ1,⋯,aˉk)§Z^N[X]k 为随机多项式向量。
- 离散噪声 e ˉ = ⌈ e q ⌋ ( m o d q ) \bar{e}=\lceil eq\rfloor(\mod q) eˉ=⌈eq⌋(modq),其中 e ← R N [ X ] e\leftarrow\mathbb{R}_N[X] e←RN[X]多项式系数从 N ( 0 , σ 2 ) \mathcal{N}(0,\sigma^2) N(0,σ2)中随机采样。
-
3) D e c r y p t s k ( c ˉ ) Decrypt_{sk}(\bar{\mathfrak{c}}) Decryptsk(cˉ):使用私钥 s = ( s 1 , ⋯ , s k ) \mathfrak{s}=(\mathfrak{s}_1,\cdots,\mathfrak{s}_k) s=(s1,⋯,sk)对 c ˉ = ( a ˉ 1 , ⋯ , a ˉ k , v ˉ ) \bar{\mathfrak{c}}=(\bar{\mathfrak{a}}_1,\cdots,\bar{\mathfrak{a}}_k,\bar{\mathfrak{v}}) cˉ=(aˉ1,⋯,aˉk,vˉ) 进行解码,计算 Z ^ N [ X ] \hat{\mathbb{Z}}_N[X] Z^N[X]:
μ ˉ ∗ = v ˉ − ∑ j = 1 k s j a j ( m o d ( q , X N + 1 ) ) \bar{\mu}^*=\bar{\mathfrak{v}}-\sum_{j=1}^{k}\mathfrak{s}_j\mathfrak{a}_j(\mod (q, X^N+1)) μˉ∗=vˉ−∑j=1ksjaj(mod(q,XN+1))
然后输出 U p p e r q , p ( μ ˉ ∗ ) Upper_{q,p}(\bar{\mu}^*) Upperq,p(μˉ∗)。
正确性:
令 p = 2 w ˉ + w , q = 2 Ω p=2^{\bar{w}+w},q=2^{\Omega} p=2wˉ+w,q=2Ω, μ ˉ = μ ˉ 0 + ⋯ + μ ˉ N − 1 X N − 1 \bar{\mu}=\bar{\mu}_0+\cdots +\bar{\mu}_{N-1}X^{N-1} μˉ=μˉ0+⋯+μˉN−1XN−1,其中 μ ˉ i = q p ( v ˉ i m o d 2 w ) \bar{\mu}_i=\frac{q}{p}(\bar{v}_i\mod 2^w) μˉi=pq(vˉimod2w)。若, c ˉ ← E n c r y p t s ( μ ˉ ) \bar{\mathfrak{c}}\leftarrow Encrypt_{\mathfrak{s}}(\bar{\mu}) cˉ←Encrypts(μˉ),只要 ∣ ∣ e ˉ ∣ ∣ ∞ ≤ q 2 p = 2 Ω − ( w ˉ + w ) − 1 ||\bar{e}||_{\infty}\leq \frac{q}{2p}=2^{\Omega-(\bar{w}+w)-1} ∣∣eˉ∣∣∞≤2pq=2Ω−(wˉ+w)−1。
对应Proof:
有 μ ˉ ∗ = μ ˉ + e ˉ \bar{\mu}^*=\bar{\mu}+\bar{e} μˉ∗=μˉ+eˉ,其中 e ˉ = e ˉ 0 + ⋯ + e ˉ N − 1 X N − 1 \bar{e}=\bar{e}_0+\cdots+\bar{e}_{N-1}X^{N-1} eˉ=eˉ0+⋯+eˉN−1XN−1。因此,将 μ ˉ ∗ \bar{\mu}^* μˉ∗ lift到 Z N [ X ] \mathbb{Z}_N[X] ZN[X],有 ⌈ p q μ ˉ ∗ ⌋ = ⌈ p q ( μ ˉ + e ˉ ) ⌋ = ∑ i = 0 N − 1 ⌈ p q ( μ ˉ i + e ˉ i ( m o d q ) ) ⌋ X i = ∑ i = 0 N − 1 ⌈ p q ( μ ˉ i + e ˉ i + q δ i ) ⌋ X i = ∑ i = 0 N − 1 ( ( v ˉ i m o d 2 w ) + ⌈ p q e ˉ i ⌋ + p δ i ) X i \lceil\frac{p}{q}\bar{\mu}^*\rfloor=\lceil\frac{p}{q}(\bar{\mu}+\bar{e})\rfloor=\sum_{i=0}^{N-1}\lceil\frac{p}{q}(\bar{\mu}_i+\bar{e}_i(\mod q))\rfloor X^i=\sum_{i=0}^{N-1}\lceil\frac{p}{q}(\bar{\mu}_i+\bar{e}_i+q\delta_i)\rfloor X^i=\sum_{i=0}^{N-1}((\bar{v}_i\mod 2^w)+\lceil\frac{p}{q}\bar{e}_i\rfloor+p\delta_i)X^i ⌈qpμˉ∗⌋=⌈qp(μˉ+eˉ)⌋=∑i=0N−1⌈qp(μˉi+eˉi(modq))⌋Xi=∑i=0N−1⌈qp(μˉi+eˉi+qδi)⌋Xi=∑i=0N−1((vˉimod2w)+⌈qpeˉi⌋+pδi)Xi,其中 δ i ∈ Z \delta_i\in\mathbb{Z} δi∈Z。
注意,若 ∣ ∣ e ˉ ∣ ∣ ∞ ≤ q 2 p ||\bar{e}||_{\infty}\leq \frac{q}{2p} ∣∣eˉ∣∣∞≤2pq,则 ⌈ p q e ˉ i ⌋ = 0 \lceil \frac{p}{q}\bar{e}_i\rfloor=0 ⌈qpeˉi⌋=0,从而有 U p p e r q , p ( μ ˉ ∗ ) ≡ q p ⌈ p q μ ˉ ∗ ⌋ ≡ q p ∑ i = 0 N − 1 ( v ˉ i m o d 2 w ) X i ≡ μ ˉ ( m o d q ) Upper_{q,p}(\bar{\mu}^*)\equiv \frac{q}{p}\lceil \frac{p}{q}\bar{\mu}^*\rfloor\equiv \frac{q}{p}\sum_{i=0}^{N-1}(\bar{v}_i\mod 2^w)X^i\equiv \bar{\mu}(\mod q) Upperq,p(μˉ∗)≡pq⌈qpμˉ∗⌋≡pq∑i=0N−1(vˉimod2w)Xi≡μˉ(modq)。
Remark 1:
某些特定应用中,接受解密算法恢复的不是准确的初始明文,而是其近似值。此时,要求变为 D e c r y p t s ( c ˉ ) ≈ μ ˉ Decrypt_{\mathfrak{s}}(\bar{\mathfrak{c}})\approx \bar{\mu} Decrypts(cˉ)≈μˉ,且对 ∣ ∣ e ∣ ∣ ∞ ||e||_{\infty} ∣∣e∣∣∞的限定条件也可放松。
3.3 Leveled operations
FHE支持直接对密文运算。取决于运算类型,最终噪声水平都或多或少将增加。
3.3.1 加法运算
G L W E ‾ \overline{GLWE} GLWE密文是加法同态的。

3.3.2 scalar multiplication运算
G L W E ‾ \overline{GLWE} GLWE密文与常量值(或多项式)的乘法运算是同态的。

3.3.3 external product运算
G L W E ‾ \overline{GLWE} GLWE密文不支持原生内乘运算,实际上,2个 G L W E ‾ \overline{GLWE} GLWE密文无法直接相乘。
一种聪明的做法是使用基于矩阵的方法——GSW构建。 G G S W ‾ \overline{GGSW} GGSW为通用GSW加密算法, G S W ‾ \overline{GSW} GSW为其特例情况,对应有 ( k , N ) = ( n , 1 ) (k,N)=(n,1) (k,N)=(n,1)。
令参数 B = 2 β , ℓ B=2^{\beta},\ell B=2β,ℓ,有 β , ℓ ≥ 1 \beta,\ell\geq 1 β,ℓ≥1,使得 ℓ β ≤ Ω \ell\beta\leq \Omega ℓβ≤Ω。
同时定义向量 g = ( 2 Ω − β , 2 Ω − 2 β , ⋯ , 2 Ω − ℓ β ) \mathbf{g}=(2^{\Omega-\beta},2^{\Omega-2\beta},\cdots,2^{\Omega-\ell\beta}) g=(2Ω−β,2Ω−2β,⋯,2Ω−ℓβ)。以 G L W E ‾ \overline{GLWE} GLWE加密密钥 s ∈ B N [ X ] k \mathfrak{s}\in\mathbb{B}_N[X]^k s∈BN[X]k,对明文 m ∈ Z N [ X ] m\in\mathbb{Z}_N[X] m∈ZN[X]做 G G S W ‾ \overline{GGSW} GGSW加密定义为:

其中:
- I ˉ \bar{\mathcal{I}} Iˉ矩阵中每行为对 0 0 0的fresh G L W E ‾ \overline{GLWE} GLWE加密。
- G T \mathbf{G}^T GT称为gadget矩阵:【其中, I k + 1 \mathbf{I}_{k+1} Ik+1表示size为 k + 1 k+1 k+1的单位矩阵】
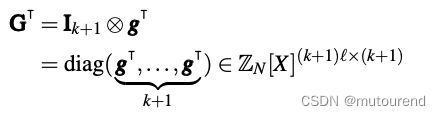
- 对于 Z / q Z \mathbb{Z}/q\mathbb{Z} Z/qZ中的任意元素 d d d,可将其看成是 ⟦ − q 2 , q 2 ⟧ \llbracket -\frac{q}{2}, \frac{q}{2}\rrbracket [[−2q,2q]]范围内的整数,然后近似表示为a signed-digit radix- B B B expansion of size ℓ \ell ℓ:
d ≈ q ∑ i = 1 ℓ d i B − i = ∑ i = 1 ℓ d i 2 Ω − i β = g − 1 ( d ) g T d\approx q\sum_{i=1}^{\ell}d_iB^{-i}=\sum_{i=1}^{\ell}d_i 2^{\Omega-i\beta}=\mathbf{g}^{-1}(d)\mathbf{g}^T d≈q∑i=1ℓdiB−i=∑i=1ℓdi2Ω−iβ=g−1(d)gT
其中:- g − 1 ( d ) : = ( d 1 , ⋯ , d ℓ ) ∈ Z ℓ \mathbf{g}^{-1}(d):=(d_1,\cdots,d_{\ell})\in\mathbb{Z}^{\ell} g−1(d):=(d1,⋯,dℓ)∈Zℓ,其中digit d i ∈ ⟦ − B 2 , B 2 ⟧ d_i\in\llbracket -\frac{B}{2}, \frac{B}{2}\rrbracket di∈[[−2B,2B]]。
- 近似error限定为 ∣ g − 1 ( d ) g T − d ∣ ≤ q / ( 2 B ℓ ) = 2 Ω − β ℓ − 1 |\mathbf{g}^{-1}(d)\mathbf{g}^T-d|\leq q/(2B^{\ell})=2^{\Omega-\beta\ell-1} ∣g−1(d)gT−d∣≤q/(2Bℓ)=2Ω−βℓ−1。
通过扩展,对于多项式 p = p 0 + ⋯ + p N − 1 X N − 1 ∈ Z ^ N [ X ] \mathfrak{p}=p_0+\cdots+p_{N-1}X^{N-1}\in\hat{\mathbb{Z}}_N[X] p=p0+⋯+pN−1XN−1∈Z^N[X],其系数可看成是 ⟦ − q 2 , q 2 ⟧ \llbracket -\frac{q}{2}, \frac{q}{2}\rrbracket [[−2q,2q]]范围内的整数。
decomposition g − 1 ( p ) ∈ Z N [ X ] ℓ \mathbf{g}^{-1}(\mathfrak{p})\in\mathbb{Z}_N[X]^{\ell} g−1(p)∈ZN[X]ℓ,定义为:
g − 1 ( p ) = ∑ j = 1 N − 1 g − 1 ( p j ) X j \mathbf{g}^{-1}(\mathfrak{p})=\sum_{j=1}^{N-1}\mathbf{g}^{-1}(p_j)X^j g−1(p)=∑j=1N−1g−1(pj)Xj。
显然 ∣ g − 1 ( p ) g T − p ∣ ≤ 2 Ω − β ℓ − 1 |\mathbf{g}^{-1}(\mathfrak{p})\mathbf{g}^T-\mathfrak{p}|\leq 2^{\Omega-\beta\ell-1} ∣g−1(p)gT−p∣≤2Ω−βℓ−1 成立。
对于 k + 1 k+1 k+1个多项式组成的向量 p = ( p 1 , ⋯ , p k + 1 ) ∈ Z ^ N [ X ] k + 1 \mathbf{p}=(\mathfrak{p}_1,\cdots,\mathfrak{p}_{k+1})\in\hat{\mathbb{Z}}_N[X]^{k+1} p=(p1,⋯,pk+1)∈Z^N[X]k+1,decomposition G − 1 ( p ) ∈ Z N [ X ] ( k + 1 ) × ℓ \mathbf{G}^{-1}(\mathbf{p})\in\mathbb{Z}_N[X]^{(k+1)\times \ell} G−1(p)∈ZN[X](k+1)×ℓ定义为:
G − 1 ( p ) = ( g − 1 ( p 1 ) , ⋯ , g − 1 ( p k + 1 ) ) \mathbf{G}^{-1}(\mathbf{p})=(\mathbf{g}^{-1}(\mathfrak{p}_1),\cdots,\mathbf{g}^{-1}(\mathfrak{p}_{k+1})) G−1(p)=(g−1(p1),⋯,g−1(pk+1)),且, ∣ ∣ G − 1 ( p ) G T − p ∣ ∣ ∞ ≤ 2 Ω − β ℓ − 1 ||\mathbf{G}^{-1}(\mathbf{p})\mathbf{G}^T-\mathbf{p}||_{\infty}\leq 2^{\Omega-\beta\ell-1} ∣∣G−1(p)GT−p∣∣∞≤2Ω−βℓ−1。
有趣的是, G L W E ‾ \overline{GLWE} GLWE密文的gadget decomposition,可引起与 G G S W ‾ \overline{GGSW} GGSW密文的外乘。
对于明文 m 1 ∈ Z N [ X ] m_1\in\mathbb{Z}_N[X] m1∈ZN[X]和 μ 2 ∈ Z ^ N [ X ] \mu_2\in\hat{\mathbb{Z}}_N[X] μ2∈Z^N[X],若 C ˉ 1 ← G G S W ‾ s ( m 1 ) , c ˉ 2 ← G L W E ‾ s ( μ 2 ) \bar{\mathfrak{C}}_1\leftarrow \overline{GGSW}_{\mathfrak{s}}(m_1),\bar{\mathfrak{c}}_2\leftarrow\overline{GLWE}_{\mathfrak{s}}(\mu_2) Cˉ1←GGSWs(m1),cˉ2←GLWEs(μ2),则二者的外乘 ⊡ \boxdot ⊡表示为:
c ˉ 3 = C ˉ 1 ⊡ c ˉ 2 : = G − 1 ( c ˉ 2 ) C ˉ 1 \bar{\mathfrak{c}}_3=\bar{\mathfrak{C}}_1\boxdot \bar{\mathfrak{c}}_2:=\mathbf{G}^{-1}(\bar{\mathfrak{c}}_2)\bar{\mathfrak{C}}_1 cˉ3=Cˉ1⊡cˉ2:=G−1(cˉ2)Cˉ1
展开有:

从而可知,只要最终噪声(包括近似错误)保持small,则 c ˉ 3 \bar{\mathfrak{c}}_3 cˉ3是对 m 1 μ ∈ Z ^ N [ X ] m_1\mu\in\hat{\mathbb{Z}}_N[X] m1μ∈Z^N[X]的 G L W E ‾ \overline{GLWE} GLWE加密。
3.3.4 Cmux gate运算
以外乘为起点,可定义新的leveled运算:
- ‘controlled’ multiplexer,或CMux
CMux用作根据bit来做选择的selector,但其基于的是已加密数据。
CMux gate:
- 输入有:
- 2个 G L W E ‾ \overline{GLWE} GLWE密文 c ˉ 0 \bar{\mathfrak{c}}_0 cˉ0和 c ˉ 1 \bar{\mathfrak{c}}_1 cˉ1,分别对应明文 μ 0 , μ 1 ∈ Z ^ N [ X ] \mu_0,\mu_1\in\hat{\mathbb{Z}}_N[X] μ0,μ1∈Z^N[X]。
- 1个对bit b b b的 G G S W ‾ \overline{GGSW} GGSW密文 C ˉ \bar{\mathfrak{C}} Cˉ。
- 输出为:
- 对明文 μ b \mu_b μb的 G L W E ‾ \overline{GLWE} GLWE密文 c ˉ ′ \bar{\mathfrak{c}}' cˉ′,只要最终噪声keep small。
即CMux gate定义为:
c ˉ ′ ← C M u x ( C ˉ , c ˉ 0 , c ˉ 1 ) : = C ˉ ⊡ ( c ˉ 1 − c ˉ 0 ) + c ˉ 0 \bar{\mathfrak{c}}'\leftarrow CMux(\bar{\mathfrak{C}},\bar{\mathfrak{c}}_0,\bar{\mathfrak{c}}_1):=\bar{\mathfrak{C}}\boxdot (\bar{\mathfrak{c}}_1-\bar{\mathfrak{c}}_0)+\bar{\mathfrak{c}}_0 cˉ′←CMux(Cˉ,cˉ0,cˉ1):=Cˉ⊡(cˉ1−cˉ0)+cˉ0
CMux gate在同态计算性能中(特别是bootstrapping中)承担核心角色,
FHE系列博客
- 技术探秘:在RISC Zero中验证FHE——由隐藏到证明:FHE验证的ZK路径(1)
- 基于[Discretized] Torus的全同态加密指引(1)
- 基于[Discretized] Torus的全同态加密指引(2)
- TFHE——基于[Discretized] Torus的全同态加密 代码解析
- 技术探秘:在RISC Zero中验证FHE——RISC Zero应用的DevOps(2)
- FHE简介
- Zama TFHE-rs