JavaScript 闭包的全面理解
写文章之前其实我对闭包的概念及原理模糊不清......
理解为一个函数内部返回一个函数,内部函数有权访问外层函数的作用域...来欺骗自己(很多这样的半吊子hhh)
其实这种说法没有绝对的对与错,写这篇文章其实就是为了自己在闭包的理解上能更深入更底层
讲闭包之前先讲下JavaScript的
执行环境(执行上下文),词法作用域,作用域链,垃圾回收机制
①执行环境(全局执行环境和函数执行环境):
执行环境定义了变量或函数有权访问的其他数据,决定了它们各自的行为。每个执行环境都有一个相关联的变量对象(初始化阶段),这个对象里面保存了环境中定义的所有变量和函数。这个变量对象在编写代码是不能访问的,但解析器在处理数据时会在后台使用它。
全局执行环境是最外围的一个执行环境。ECMAScript实现所在的宿主环境不同,表示执行环境的对象也不一样。在web浏览器中,全局执行环境被认为是window对象,因此所有全局变量和函数都是作为window对象的属性和方法创建的。当执行某个函数时,变量对象==》转换成活动对象,并把这个对象作为与该函数的执行环境关联的变量对象,从而创建出该函数的执行环境。执行环境中代码执行完之后,该环境被销毁(执行栈,或环境栈将其环境弹出),保存在其中的所有变量和函数定义也随之销毁,随后控制权返回给之前的执行环境(全局执行环境直到应用程序退出–例如关闭网页或者浏览器时才会一一销毁)
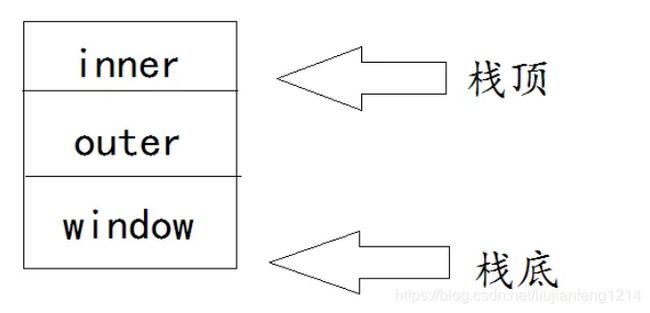
图例1:
var name = 'window';
outer();
function outer(){
var name = 'outer';
inner();
function inner(){
var name = 'inner';
console.log(name);//inner
}
}
②词法作用域:
简单地说,词法作用域就是定义在词法阶段的作用域。换句话说,词法作用域是由你在写代码时将变量和块作用域写在哪里来决定的,因此当词法分析器处理代码时会保持作用域不变(除动态作用域)
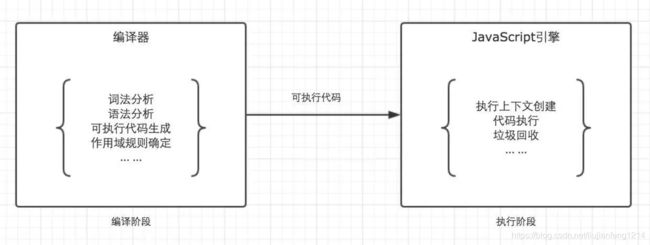
JS中代码整个的执行分两个阶段:代码编译和代码执行
1.代码编译:由编译器完成,将代码翻译成可执行代码。在代码编译阶段,作用域规则就已经被确定了。
2.代码执行:由js引擎完成,主要任务是执行可执行的代码。到代码执行时,执行上下文被创建,同时,作用域链作为作用域规则的具体实现被构建出来。
注:有兴趣了解词法分析器,动态作用域,可以查阅《你不知道的JS》上卷
③作用域链:
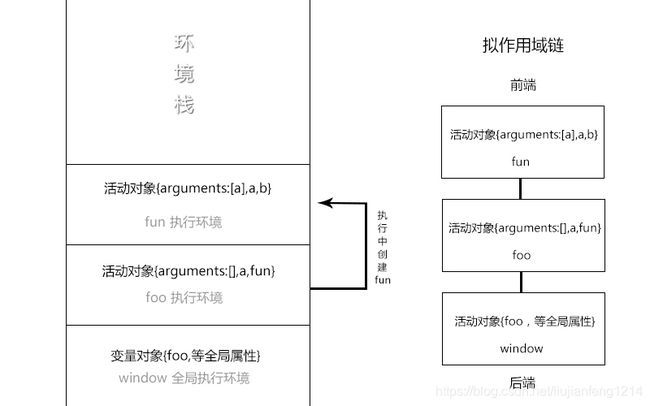
当代码在一个环境中执行时,会创建变量对象的一个作用域链。作用域用途是保证对执行环境有权访问的所有变量和函数的有序访问。作用域链的前端,始终都是当前执行的代码所在环境的变量对象。如果这个环境是函数,则将其活动对象作为变量对象。活动对象在最开始时只包含一个变量(即arguments对象,在全局环境中是不存在的)。作用域链中的下一个变量对象来自包含(外部)环境,而再下一个变量对象则来自下一个包含环境。这样一直延续到全局执行环境。所以全局执行环境的变量对象始终都是作用域链中的最后一个对象
图例2:
function foo(){
var a = 12;
fun(a);
function fun(a){
var b = 8;
console.log(a + b);
}
}
foo();
④垃圾回收机制:
在Javascript中垃圾回收机制的原理很简单,找出那些不再继续使用的变量,释放其占用的内存。垃圾收集器会按照固定的时间间隔周期性的执行这一操作(常用方法就是标记清除,以及不太常见的引用计数)
注:上面的内容可以翻阅《JavaScript高级程序设计第三版》
闭包(closure)
什么是闭包:引用github上一篇文章的话
当一个函数能够记住并访问到其所在的词法作用域及作用域链,特别强调是在其定义的作用域外进行的访问,
此时该函数和其上层执行上下文共同构成闭包。
简单闭包的例子:
function foo() {
let a = 2;
function bar() {
console.log( a );
}
return bar;
}
let baz = foo();
baz();
需要明确的几点:
1.闭包一定是函数对象
2.闭包和词法作用域,作用域链,垃圾回收机制息息相关
3.当函数一定是在其定义的作用域外进行的访问时,才产生闭包
4.闭包是由该函数和其上层执行上下文共同构成
我们从这个例子来理解这几点:
执行到 let baz = foo()时
作用域如图:
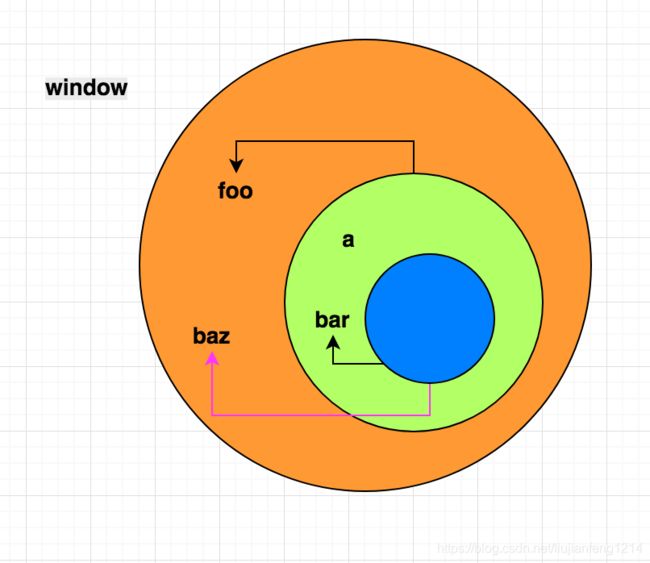
foo函数执行完,JS的垃圾回收机制应该会自动将其标记为"离开环境",等待回收机制下次执行,将其内存进行释放(标记清除)
我们看图中粉色的箭头,我们将bar的引用指向baz,正是这种引用赋值,阻止了垃圾回收机制将foo进行回收,从而导致bar的整条作用域链都被保存下来
接下来,baz()执行,bar进入执行栈,闭包(foo)形成,此时bar中依旧可以访问到其父作用域的变量a
图释:
①执行到let baz = foo()时
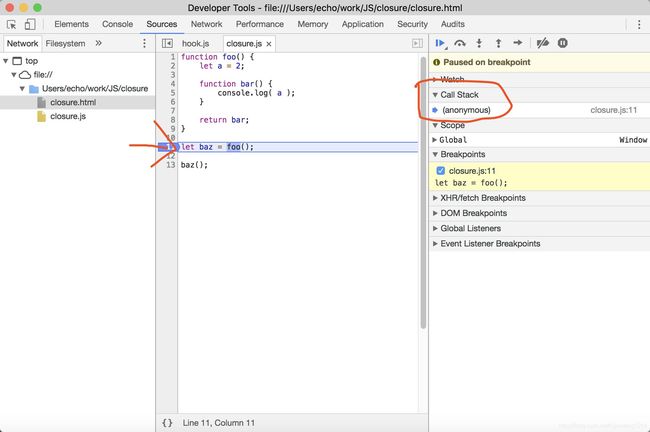
图中所示当let baz = foo()已经执行完,即将执行baz(),此时Call Stack中只有全局上下文
②接下来baz()执行:
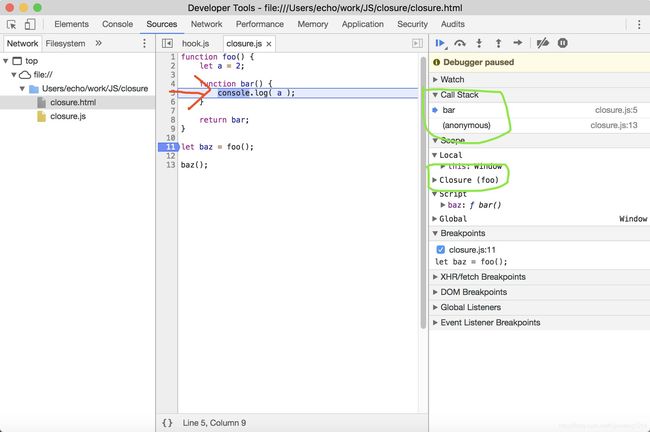
我们可以看到,此时bar进入Call Stack中,并且Closure(foo)形成
为什么要是函数对象呢?
函数可以提供一个执行环境,在这个环境中引用其它环境的变量对象时,后者不会被js内部回收机制清除掉。从而当你在当前执行环境中访问它时,它还是在内存当中的。千万不要把环境栈和垃圾回收这两个很重要的过程搞混了,环境栈调用移入,调用后移出,垃圾回收则是监听引用。
闭包的词法作用域,作用域链,垃圾回收机制等等
我上面也有一定的解释,如果大家想了解的更详细可以去翻阅《你不知道的JS》《JS高级程序设计第三版》
针对第三点,当函数baz执行时,闭包才生成
针对第四点,闭包是foo,并不是bar
很多书都强调保存下来的引用,即上例中的bar是闭包,而chrome认为被保存下来的封闭空间foo是闭包,针对这点我也赞同chrome的判断(仅为自己的理解)
闭包注意事项:内存泄漏(Memory Leak)
JavaScript分配给Web浏览器的可用内存数量通常比分配给桌面应用程序的少,这样做主要是防止JavaScript的网页耗尽全部系统内存而导致系统崩溃。
因此,要想使页面具有更好的性能,就必须确保页面占用最少的内存资源,也就是说,我们应该保证执行代码只保存有用的数据,一旦数据不再有用,我们就应该让垃圾回收机制对其进行回收,释放内存。
我们现在都知道了闭包阻止了垃圾回收机制对变量进行回收,因此变量会永远存在内存中,即使当变量不再被使用时,这样会造成内存泄漏,会严重影响页面的性能。因此当变量对象不再适用时,我们要将其释放。
我们拿上面代码举例:
function foo() {
let a = 2;
function bar() {
console.log( a );
}
return bar;
}
let baz = foo();
baz(); //baz指向的对象会永远存在堆内存中
baz = null; //如果baz不再使用,将其指向的对象释放
闭包的应用
①模块应该具有私有属性、私有方法和公有属性、公有方法。闭包能很好的将模块的公有属性、方法暴露出来
var myModule = (function (window, undefined) {
let name = "echo";
function getName() {
return name;
}
return {
name,
getName
}
})(window);
console.log( myModule.name ); // echo
console.log( myModule.getName() ); // echo
"return"关键字将对象引用导出赋值给myModule,从而应用到闭包
②异步的问题,闭包能能很好解决这种问题(比如经典的setTimeout示例等等),准备在下篇文章详细讲解浏览器的Event Loop机制,到时候会解释清楚