quartz-深度解析
任务调度的原理分析
1.需要用到定时任务时,应该如何选型?
2.为什么需要分布式任务调度系统?
3.quartz核心思想?
4.不改配置,不重启,如何实现定时任务的动态调度?
5.集群部署如何保证不重跑、不漏跑?
1.理论基础-数据结构
1.1 小顶堆
1.1.1 概念
满二叉树:所有层都达到最大节点
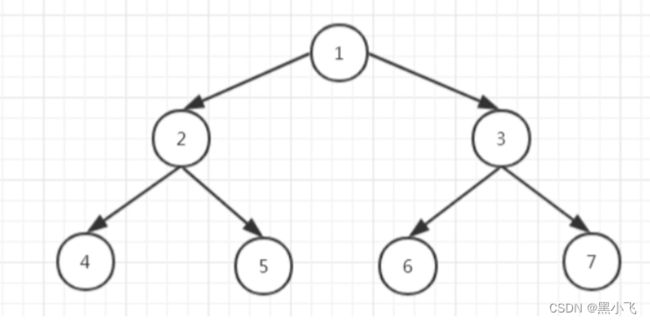
完全二叉树:除了最后一层外其它层都达到最大节点数,且最后一层都靠左排列

堆: (1)完全二叉树 (2)它的元素必须满足每个节点的值都不大于或者不小于其父节点的值。
小顶堆:每个节点都不小于其父节点的值

数组存储结构:

这时候我们要找8的父节点:8的位置下标/2 = 5/2 = 2 也就是5的位置。
大顶堆:每个节点都不大于其父节点的值
定时任务中,每一个节点存储的都是job,越往上走越接近执行时间,最接要执行的job就在根节点的位置,这个是根据delay(延时执行时间)的大小决定的。
1.1.2 插入元素(新增定时任务)
插入元素 然后上浮(fixUp)
需要满足堆的两个特性:
(1)堆是一个完全二叉树
(2)堆中某个节点的值总是不大于或者不小于其父节点的值
堆化:我们需要插入元素2,需要放到9后面,这时不满足条件(2),需要堆化。
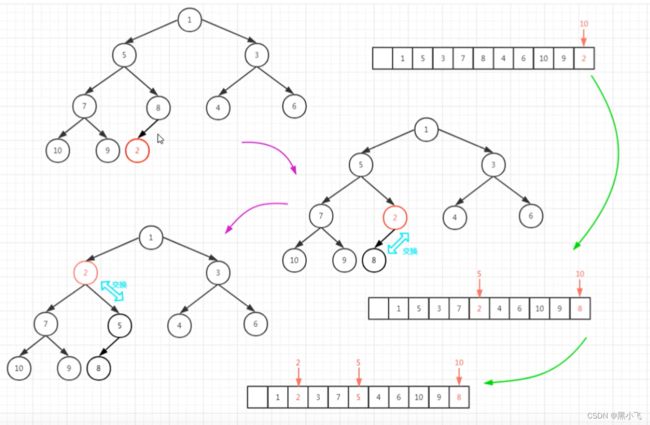
在数组中,插入的节点与n/2位置的节点想比,如果n/2位置节点大就交换他们的位置,
再与n/4位置想比。,如果比n/4位置节点小,继续交换,直到大于父节点为止。
这就是插入元素时堆化,也叫自下而上的堆化,插入元素时间复杂度为O(log n)
1.1.3 删除堆顶元素(定时任务执行后删除)
将尾部元素放到堆顶,然后下沉(fixDown)
删除了堆顶元素后还需要满足堆的两个特性,首先我们把最后一个元素移动到根节点位置,这时候满足条件(1),之后使它满足条件(2),就需要进行堆化。

在数组中,把最后一个元素移到下标为1的位置,然后与下标为 2n 和 2n+1的元素进行比较,取比较小的进行交换下沉,这就是删除堆顶元素时进行的堆化,又叫自上而下的堆化,时间复杂度为O(log n)
1.1.4 小顶堆问题
①删除的时候下沉操作,耗性能。
②只适合小量的定时任务存储
1.2 时间轮算法
1.2.1 概念
时间轮的思想应用范围非常广泛,各种操作系统的定时任务调度,Crontab,还有基于java的通信框架Netty中也有时间轮的实现,几乎所有的时间任务调度系统采用的都是时间轮的思想。
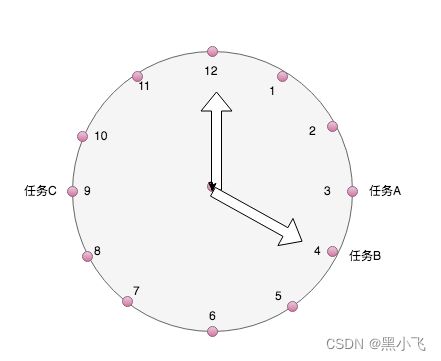
1.2.2 链表或者数组实现时间轮:while-true-sleep
原理:遍历数据,每个下标放置一个链表,链表节点放置任务,遍历到了就取出执行
问题:不同时间维度无法满足比如,年月日时分秒,无法全部在时间轮上体现。
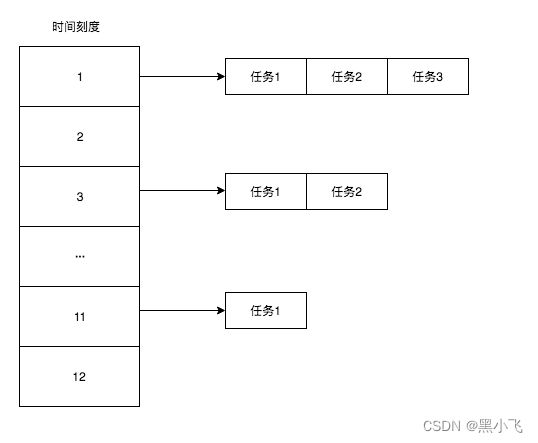
1.2.3 round型时间轮
①任务上记录一个round,遍历到了就将round减1,为0时取出执行。
②需要遍历所有任务,效率较低。

1.2.4 分层时间轮(corn表达式)
①使用多个不同时间维度的轮 天轮:记录几点执行 月轮:记录几号执行
②月轮遍历到了,将任务取出放到天轮里面,即可实现几号几点执行

2.JDK自带的定时任务Timer
2.1 概念
JDK从1.3版本开始,提供了基于Timer的定时调度功能。在Timer中,任务的执行是串行的。这种特性在保证了线程安全的情况下,往往带来了一些严重的副作用,比如任务间相互影响、任务执行效率低下等问题。为了解决Timer的这些问题,JDK从1.5版本开始,提供了基于ScheduledExecutorService的定时调度功能。
2.2 如何使用
Timer需要和TimerTask配合使用,才能完成调度功能。Timer表示调度器,TimerTask表示调度器执行的任务。任务的调度分为两种:一次性调度和循环调度。
1.TaskQueue:小顶堆,存放timeTask
2.TimerThread:任务执行线程
死循环不断检查是否有任务需要开始执行了,有就执行它,本线程执行
2.3 缺点
1.单线程执行任务,任务有可能相互阻塞
• schedule: 任务执行超时,会导致后面的任务往后推移。(丢任务)
• scheduleAtFixedRate:任务超时时可能导致下一个任务就会马上执行。
2.运行时异常会导致timer线程终止
3.任务调度是基于绝对时间,对系统时间敏感
3.线程池实现定时任务
3.1 概念
JDK从1.5版本开始,提供了基于ScheduledExecutorService的定时调度功能,ScheduledExecutorService在设计之初就是为了解决Timer&TimerTask的问题。因为天生就是基于多线程机制,所以任务之间不会相互影响(只要线程数足够。当线程数不足时,有些任务会复用同一个线程)。
3.2 ScheduledThreadPoolExecutor执行机制分析
因为ScheduledExecutorService继承于ExecutorService,所以本身支持线程池的所有功能。额外还提供了4种方法
/** * 带延迟时间的调度,只执行一次 * 调度之后可通过Future.get()阻塞直至任务执行完毕 */ 1. public ScheduledFuture<?> schedule(Runnable command, long delay, TimeUnit unit);
/** * 带延迟时间的调度,只执行一次 * 调度之后可通过Future.get()阻塞直至任务执行完毕,并且可以获取执行结果 */
2. public <V> ScheduledFuture<V> schedule(Callable<V> callable, long delay, TimeUnit unit);
/** * 带延迟时间的调度,循环执行,固定频率 */
3. public ScheduledFuture<?> scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit);
/** * 带延迟时间的调度,循环执行,固定延迟 */
4. public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit);
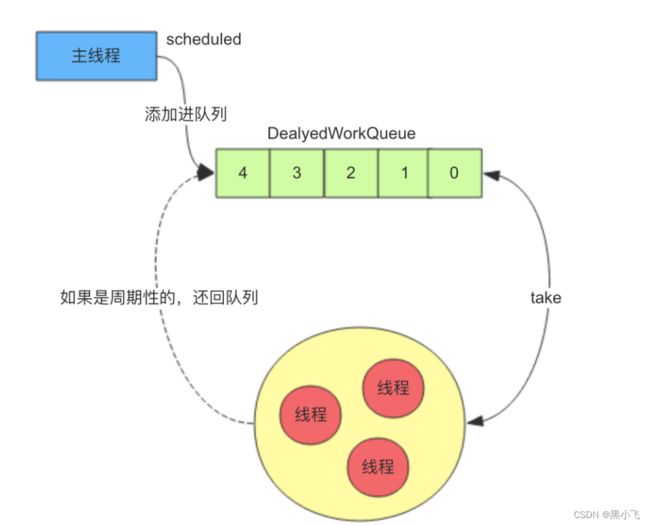
3.3 优缺点
优势:
1.其内部使用的延迟队列,本身就是基于等待/唤醒机制实现的,所以CPU并不会一直繁忙。同时,多线程带来的CPU资源复用也能极大地提升性能。
2.可以保证每个任务并发执行(如果将线程池大小设为1,则相当于是串行),并且其中1个任务抛出异常,不会导致别的任务终止
缺点:
1.1.ScheduledThreadPoolExecutor使用的是DelayedWorkQueue队列,这个队列是无界的,也就是说maximumPoolSize的设置其实是没有什么意义的。 corePoolSize设置的太小,会导致量大时,延迟任务得不到及时处理,造成阻塞。corePoolSize设置的太大,在并发任务少时,又会造成大量的线程浪费
2.任务无法动态启动、停止、修改
3.任务调度是基于绝对时间,对系统时间敏感
4.springBoot自带任务调度
4.1 核心API
在定时任务中使用@Scheduled注解参数来设置任务的执行时间,共有如下三种方式:
1、fixedRate:定义一个按一定频率执行的定时任务
2、fixedDelay:定义一个按一定频率执行的定时任务,与上面不同的是,该属性可以配合initialDelay属性, 定义该任务延迟执行时间
5.3、cron:通过表达式来配置任务执行时间
该参数接收一个cron表达式,cron表达式是一个字符串,字符串以5或6个空格隔开,分开共6或7个域,每一个域代表一个含义。
cron 表达式语法:
格式:[秒][分] [小时][日] [月][周] [年]
| 序号 | 说明 | 是否必填 | 允许填写的值 | 允许的通配符 |
|---|---|---|---|---|
| 1 | 秒 | 是 | 0-59 | , - * / |
| 2 | 分 | 是 | 0-59 | , - * / |
| 3 | 小时 | 是 | 0-23 | , - * / |
| 4 | 日 | 是 | 1-31 | , - * ? / L W |
| 5 | 月 | 是 | 1-12 or JAN-DEC | , - * / |
| 6 | 周 | 是 | 1-7 or SUN-SAT | , - * ? / L # |
| 7 | 年 | 否 | empty 或 1970-2099 | , - * / |
通配符说明:
‘*****’ 表示所有值. 例如:在分的字段上设置 “*”,表示每一分钟都会触发。
‘?’ 表示不指定值。使用的场景为不需要关心当前设置这个字段的值。例如:要在每月的10号触发一个操作,但不关心是周几,所以需要周位置的那个字段设置为"?" 具体设置为 0 0 0 10 * ?
‘-’ 表示区间。例如 在小时上设置 “10-12”,表示 10,11,12点都会触发。
‘,’ 表示指定多个值,例如在周字段上设置 “MON,WED,FRI” 表示周一,周三和周五触发
‘/’ 用于递增触发。如在秒上面设置"5/15" 表示从5秒开始,每增15秒触发(5,20,35,50)。在月字段上设置’1/3’所示每月1号开始,每隔三天触发一次。
‘L’ 表示最后的意思。在日字段设置上,表示当月的最后一天(依据当前月份,如果是二月还会依据是否是润年[leap]), 在周字段上表示星期六,相当于"7"或"SAT"。如果在"L"前加上数字,则表示该数据的最后一个。例如在周字段上设置"6L"这样的格式,则表示“本月最后一个星期五"
‘W’ 表示离指定日期的最近那个工作日(周一至周五). 例如在日字段上设置"15W",表示离每月15号最近的那个工作日触发。如果15号正好是周六,则找最近的周五(14号)触发, 如果15号是周未,则找最近的下周一(16号)触发.如果15号正好在工作日(周一至周五),则就在该天触发。如果指定格式为 “1W”,它则表示每月1号往后最近的工作日触发。如果1号正是周六,则将在3号下周一触发。(注,“W"前只能设置具体的数字,不允许区间”-").
小提示:'L’和 'W’可以一组合使用。如果在日字段上设置"LW",则表示在本月的最后一个工作日触发。
单线程的定时任务: @Scheduled和@EnableScheduling
多线程定时任务:@EnableAsync+@Async+AsyncConfig.java(实现接口AsyncConfigurer)
4.2 原理
spring在初始化bean后,通过“postProcessAfterInitialization”拦截到所有的用到“@Scheduled”注解的方法,并解析相应的的注解参数,放入“定时任务列表”等待后续处理;之后再“定时任务列表”中统一执行相应的定时任务(任务为顺序执行,先执行cron,之后再执行fixedRate)
第一步:依次加载所有的实现Scheduled注解的类方法。
postProcessAfterInitialization()
第二步:将对应类型的定时器放入相应的“定时任务列表”中。
processScheduled()
第三步:执行相应的定时任务。
scheduleTasks()
第四步:定时任务run(extends自Runnable接口)方法。
run()
4.3 缺点
5.Quartz任务调度:
文档
springboot官网quartz相关
5.1 定义
quartz是一个功能丰富的开源的任务调用系统,功能强大,可以让你的程序在指定时间执行,也可以按照某一个频度执行,它可以创建简单或者复杂的job,在添加定时任务时可以携带参数,并且支持定时任务的动态更新。
5.2 需求
1.定时任务创建
2.定时任务动态修改、查询
3.分布式集群支持(高可用)
5.3 体系结构

quartz框架主要核心组件包括调度器、触发器、作业。调度器作为作业的总指挥,触发器作为作业的操作者,作业为应用的功能模块。其关系如下图所示:

Job为作业的接口,为任务调度的对象;
JobDetail用来描述Job的实现类及其它相关的静态信息;Trigger做为作业的定时管理工具,一个Trigger只能对应一个作业实例,而一个作业实例可对应多个触发器;
Scheduler做为定时任务容器,是quartz最上层的东西,它提携了所有触发器和作业,使它们协调工作,每个Scheduler都存有JobDetail和Trigger的注册,一个Scheduler中可以注册多个JobDetail和多个Trigger。
Cron表达式:一种触发策略定义表达式;
5.4 主要线程
在Quartz中,有两类线程,也即执行线程和调度线程,其中执行任务的线程通常用一个线程池维护。线程间关系如图所示。

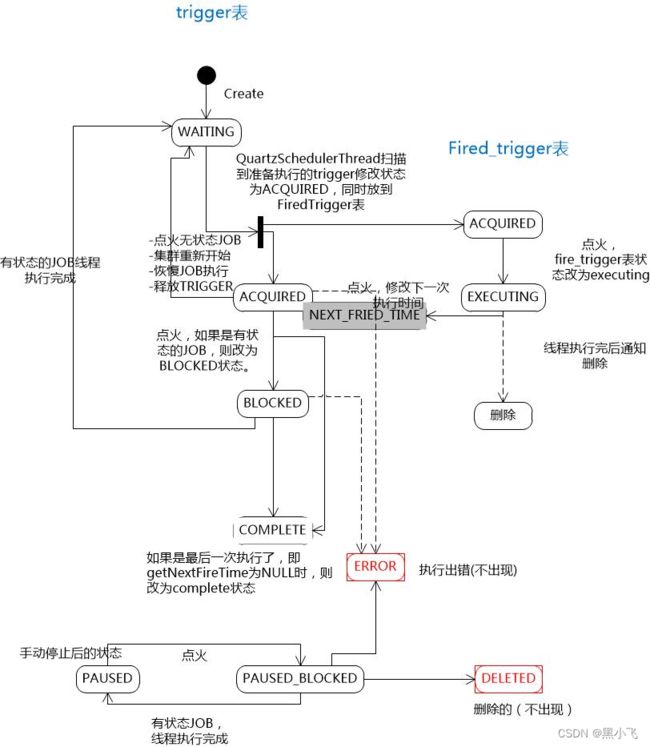
在quartz中,Scheduler调度线程主要有两个:regular Scheduler Thread(执行常规调度)和Misfire Scheduler Thread(执行错失的任务)。其中Regular Thread 轮询Trigger,如果有将要触发的Trigger,则从任务线程池中获取一个空闲线程,然后执行与改Trigger关联的job;Misfire Thraed则是扫描所有的trigger,查看是否有错失的,如果有的话,根据一定的策略进行处理。
5.4.1 regular Scheduler Thread(执行常规调度)
5.4.1.1 原因
QuartzSchedulerThread 线程是实际执行任务调度的线程
5.4.1.2 核心流程:
1、先获取线程池中的可用线程数量(若没有可用的会阻塞,直到有可用的);
2、获取 30ms 内要执行的trigger(即acquireNextTriggers):
获取trigger的锁,通过select …for update方式实现;获取 30ms 内(可配置)要执行的triggers(需要保证集群节点的时间一致),若@ConcurrentExectionDisallowed且列表存在该条trigger则跳过,否则更新trigger状态为ACQUIRED(刚开始为WAITING);
插入firedTrigger表,状态为ACQUIRED;(注意:在RAMJobStore中,有个timeTriggers,排序方式是按触发时间nextFireTime排的;JobStoreSupport从数据库取出triggers时是按照nextFireTime排序);
3、等待直到获取的trigger中最先执行的trigger在2ms内;
4、triggersFired:
更新firedTrigger的status=EXECUTING;
更新trigger下一次触发的时间;
更新trigger的状态:无状态的trigger->WAITING,有状态的trigger->BLOCKED,若nextFireTime==null ->COMPLETE;
commit connection,释放锁;
5、针对每个要执行的trigger,创建JobRunShell,并放入线程池执行:
execute:执行job
获取TRIGGER_ACCESS锁
若是有状态的job:更新trigger状态:BLOCKED->WAITING,PAUSED_BLOCKED->BLOCKED
若@PersistJobDataAfterExecution,则updateJobData
删除firedTrigger
commit connection,释放锁
5.4.1.3 流程图

5.4.1.4 状态流转图
5.4.2 Misfire Scheduler Thread(执行错失的任务)
5.4.2.1 原因
1.系统因为某些原因被重启。在系统关闭到重新启动之间的一段时间里,可能有些任务会被 misfire;
2.Trigger 被暂停(suspend)的一段时间里,有些任务可能会被 misfire;
3.线程池中所有线程都被占用,导致任务无法被触发执行,造成 misfire;
4.有状态任务在下次触发时间到达时,上次执行还没有结束;为了处理 misfired job,Quartz 中为 trigger 定义了处理策略,主要有下面两种:
MISFIRE_INSTRUCTION_FIRE_ONCE_NOW:针对 misfired job 马上执行一次; MISFIRE_INSTRUCTION_DO_NOTHING:忽略 misfired job,等待下次触发;
默认是MISFIRE_INSTRUCTION_SMART_POLICY,该策略在CronTrigger中=MISFIRE_INSTRUCTION_FIRE_ONCE_NOW线程默认1分钟执行一次;在一个事务中,默认一次最多recovery 20个;
5.4.2.2 核心流程
1.若配置(默认为true,可配置)成获取锁前先检查是否有需要recovery的trigger,先获取misfireCount;
2.获取TRIGGER_ACCESS锁;
3.hasMisfiredTriggersInState:获取misfired的trigger,默认一个事务里只能最大20个misfired trigger(可配置),misfired判断依据:status=waiting,next_fire_time < current_time-misfirethreshold(可配置,默认1min)
4.notifyTriggerListenersMisfired
5.updateAfterMisfire:获取misfire策略(默认是MISFIRE_INSTRUCTION_SMART_POLICY,该策略在CronTrigger中=MISFIRE_INSTRUCTION_FIRE_ONCE_NOW),根据策略更新nextFireTime;
6.将nextFireTime等更新到trigger表;
7.commit connection,释放锁
如果还有更多的misfired,sleep短暂时间(为了集群负载均衡),否则sleep misfirethreshold时间,后继续轮询;
5.4.2.3 流程图

5.5 数据存储
Quartz中的trigger和job需要存储下来才能被使用。Quartz中有两种存储方式:RAMJobStore,JobStoreSupport,其中RAMJobStore是将trigger和job存储在内存中,而JobStoreSupport是基于jdbc将trigger和job存储到数据库中。RAMJobStore的存取速度非常快,但是由于其在系统被停止后所有的数据都会丢失,所以在集群应用中,必须使用JobStoreSupport
SQL
DROP TABLE IF EXISTS QRTZ_FIRED_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_PAUSED_TRIGGER_GRPS;
DROP TABLE IF EXISTS QRTZ_SCHEDULER_STATE;
DROP TABLE IF EXISTS QRTZ_LOCKS;
DROP TABLE IF EXISTS QRTZ_SIMPLE_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_SIMPROP_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_CRON_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_BLOB_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_JOB_DETAILS;
DROP TABLE IF EXISTS QRTZ_CALENDARS;
-- Table structure for qrtz_job_details
CREATE TABLE qrtz_job_details(
SCHED_NAME VARCHAR(120) NOT NULL COMMENT '计划名称',
JOB_NAME VARCHAR(200) NOT NULL COMMENT '作业名称',
JOB_GROUP VARCHAR(200) NOT NULL COMMENT '作业组',
DESCRIPTION VARCHAR(250) NULL COMMENT '描述',
JOB_CLASS_NAME VARCHAR(250) NOT NULL COMMENT '作业程序集名称',
IS_DURABLE VARCHAR(1) NOT NULL COMMENT '是否持久',
IS_NONCONCURRENT VARCHAR(1) NOT NULL COMMENT '是否并行',
IS_UPDATE_DATA VARCHAR(1) NOT NULL COMMENT '是否更新',
REQUESTS_RECOVERY VARCHAR(1) NOT NULL COMMENT '是否要求唤醒',
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,JOB_NAME,JOB_GROUP))
ENGINE=InnoDB COMMENT = '自定义触发器';
-- Table structure for qrtz_triggers
CREATE TABLE qrtz_triggers (
SCHED_NAME VARCHAR(120) NOT NULL COMMENT '计划名称',
TRIGGER_NAME VARCHAR(200) NOT NULL COMMENT '触发器名称',
TRIGGER_GROUP VARCHAR(200) NOT NULL COMMENT '触发器组',
JOB_NAME VARCHAR(200) NOT NULL COMMENT '作业名称',
JOB_GROUP VARCHAR(200) NOT NULL COMMENT '作业组',
DESCRIPTION VARCHAR(250) NULL COMMENT '描述',
NEXT_FIRE_TIME BIGINT(13) NULL COMMENT '下次执行时间',
PREV_FIRE_TIME BIGINT(13) NULL COMMENT '前一次执行时间',
PRIORITY INTEGER NULL COMMENT '优先权',
TRIGGER_STATE VARCHAR(16) NOT NULL COMMENT '触发器状态',
TRIGGER_TYPE VARCHAR(8) NOT NULL COMMENT '触发器类型',
START_TIME BIGINT(13) NOT NULL COMMENT '开始时间',
END_TIME BIGINT(13) NULL COMMENT '结束时间',
CALENDAR_NAME VARCHAR(200) NULL COMMENT '日历名称',
MISFIRE_INSTR SMALLINT(2) NULL COMMENT '失败次数',
JOB_DATA BLOB NULL COMMENT '作业数据',
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)
REFERENCES QRTZ_JOB_DETAILS(SCHED_NAME,JOB_NAME,JOB_GROUP))
ENGINE=InnoDB COMMENT = '触发器的基本信息';
-- Table structure for qrtz_simple_triggers
CREATE TABLE qrtz_simple_triggers (
SCHED_NAME VARCHAR(120) NOT NULL COMMENT '计划名称',
TRIGGER_NAME VARCHAR(200) NOT NULL COMMENT '触发器名称',
TRIGGER_GROUP VARCHAR(200) NOT NULL COMMENT '触发器组',
REPEAT_COUNT BIGINT(7) NOT NULL COMMENT '重复次数',
REPEAT_INTERVAL BIGINT(12) NOT NULL COMMENT '触发次数',
TIMES_TRIGGERED BIGINT(10) NOT NULL COMMENT '重复间隔',
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB COMMENT = '存储简单的Trigger,包括重复次数,间隔,以及已触的次数';
-- Table structure for qrtz_cron_triggers
CREATE TABLE qrtz_cron_triggers(
SCHED_NAME VARCHAR(120) NOT NULL COMMENT '计划名称',
TRIGGER_NAME VARCHAR(200) NOT NULL COMMENT '触发器名称',
TRIGGER_GROUP VARCHAR(200) NOT NULL COMMENT '触发器组',
CRON_EXPRESSION VARCHAR(120) NOT NULL COMMENT '时间表达式',
TIME_ZONE_ID VARCHAR(80) COMMENT '时区ID',
PRIMARY KEY (SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP) REFERENCES QRTZ_TRIGGERS(SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP)
) ENGINE = InnoDB COMMENT '存储 Cron Trigger,包括Cron表达式和时区信息';
-- Table structure for qrtz_simprop_triggers
CREATE TABLE qrtz_simprop_triggers (
SCHED_NAME VARCHAR(120) NOT NULL COMMENT '计划名称',
TRIGGER_NAME VARCHAR(200) NOT NULL COMMENT '触发器名称',
TRIGGER_GROUP VARCHAR(200) NOT NULL COMMENT '触发器组',
STR_PROP_1 VARCHAR(512) NULL COMMENT '根据不同的trigger类型存放各自的参数',
STR_PROP_2 VARCHAR(512) NULL COMMENT '根据不同的trigger类型存放各自的参数',
STR_PROP_3 VARCHAR(512) NULL COMMENT '根据不同的trigger类型存放各自的参数',
INT_PROP_1 INT NULL COMMENT '根据不同的trigger类型存放各自的参数',
INT_PROP_2 INT NULL COMMENT '根据不同的trigger类型存放各自的参数',
LONG_PROP_1 BIGINT NULL COMMENT '根据不同的trigger类型存放各自的参数',
LONG_PROP_2 BIGINT NULL COMMENT '根据不同的trigger类型存放各自的参数',
DEC_PROP_1 NUMERIC(13, 4) NULL COMMENT '根据不同的trigger类型存放各自的参数',
DEC_PROP_2 NUMERIC(13, 4) NULL COMMENT '根据不同的trigger类型存放各自的参数',
BOOL_PROP_1 VARCHAR(1) NULL COMMENT '根据不同的trigger类型存放各自的参数',
BOOL_PROP_2 VARCHAR(1) NULL COMMENT '根据不同的trigger类型存放各自的参数',
PRIMARY KEY (SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP) REFERENCES QRTZ_TRIGGERS(SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP)
) ENGINE = InnoDB COMMENT '存储CalendarIntervalTrigger和DailyTimeIntervalTrigger两种类型的触发器';
-- Table structure for qrtz_blob_triggers
CREATE TABLE qrtz_blob_triggers (
SCHED_NAME VARCHAR(120) NOT NULL COMMENT '计划名称',
TRIGGER_NAME VARCHAR(200) NOT NULL COMMENT '触发器名称',
TRIGGER_GROUP VARCHAR(200) NOT NULL COMMENT '触发器组',
BLOB_DATA BLOB NULL COMMENT '保存triggers 一些信息',
PRIMARY KEY (SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP),
INDEX (SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP) REFERENCES QRTZ_TRIGGERS(SCHED_NAME, TRIGGER_NAME, TRIGGER_GROUP)
) ENGINE = InnoDB COMMENT '自定义触发器';
-- Table structure for qrtz_calendars
CREATE TABLE qrtz_calendars (
SCHED_NAME VARCHAR(120) NOT NULL COMMENT '计划名称',
CALENDAR_NAME VARCHAR(200) NOT NULL COMMENT '触发器名称',
CALENDAR BLOB NOT NULL,
PRIMARY KEY (SCHED_NAME, CALENDAR_NAME)
) ENGINE = InnoDB COMMENT '以 Blob 类型存储 Quartz 的 Calendar 信息';
-- Table structure for qrtz_paused_trigger_grps
CREATE TABLE qrtz_paused_trigger_grps (
SCHED_NAME VARCHAR(120) NOT NULL COMMENT '计划名称',
TRIGGER_GROUP VARCHAR(200) NOT NULL COMMENT '触发器组',
PRIMARY KEY (SCHED_NAME, TRIGGER_GROUP)
) ENGINE = InnoDB COMMENT '存储已暂停的 Trigger组的信息';
-- Table structure for qrtz_fired_triggers
CREATE TABLE qrtz_fired_triggers (
SCHED_NAME VARCHAR(120) NOT NULL COMMENT '计划名称',
ENTRY_ID VARCHAR(95) NOT NULL COMMENT '组标识',
TRIGGER_NAME VARCHAR(200) NOT NULL COMMENT '触发器名称',
TRIGGER_GROUP VARCHAR(200) NOT NULL COMMENT '触发器组',
INSTANCE_NAME VARCHAR(200) NOT NULL COMMENT '当前实例的名称',
FIRED_TIME BIGINT(13) NOT NULL COMMENT '当前执行时间',
SCHED_TIME BIGINT(13) NOT NULL COMMENT '计划时间',
PRIORITY INTEGER NOT NULL COMMENT '权重',
STATE VARCHAR(16) NOT NULL COMMENT '状态',
JOB_NAME VARCHAR(200) NULL COMMENT '作业名称',
JOB_GROUP VARCHAR(200) NULL COMMENT '作业组',
IS_NONCONCURRENT VARCHAR(1) NULL COMMENT '是否并行',
REQUESTS_RECOVERY VARCHAR(1) NULL COMMENT '是否要求唤醒',
PRIMARY KEY (SCHED_NAME, ENTRY_ID)
) ENGINE = InnoDB COMMENT '存储与已触发的 Trigger 相关的状态信息,以及相联 Job的执行信息';
-- Table structure for qrtz_scheduler_state
CREATE TABLE qrtz_scheduler_state (
SCHED_NAME VARCHAR(120) NOT NULL COMMENT '计划名称',
INSTANCE_NAME VARCHAR(200) NOT NULL COMMENT '实例名称',
LAST_CHECKIN_TIME BIGINT(13) NOT NULL COMMENT '最后的检查时间',
CHECKIN_INTERVAL BIGINT(13) NOT NULL COMMENT '检查间隔',
PRIMARY KEY (SCHED_NAME,INSTANCE_NAME))
ENGINE=InnoDB COMMENT '存储少量的有关 Scheduler 的状态信息,和别的Scheduler实例(假如是用于一个集群中)';
-- Table structure for qrtz_locks
CREATE TABLE qrtz_locks (
SCHED_NAME VARCHAR(120) NOT NULL COMMENT '计划名称',
LOCK_NAME VARCHAR(40) NOT NULL COMMENT '锁名称',
PRIMARY KEY (SCHED_NAME,LOCK_NAME))
ENGINE=InnoDB COMMENT '存储程序的悲观锁的信息(假如使用了悲观锁)';
CREATE INDEX IDX_QRTZ_T_J ON QRTZ_TRIGGERS(SCHED_NAME,JOB_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_T_JG ON QRTZ_TRIGGERS(SCHED_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_T_C ON QRTZ_TRIGGERS(SCHED_NAME,CALENDAR_NAME);
CREATE INDEX IDX_QRTZ_T_G ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_GROUP);
CREATE INDEX IDX_QRTZ_T_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_N_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_N_G_STATE ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_GROUP,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_NEXT_FIRE_TIME ON QRTZ_TRIGGERS(SCHED_NAME,NEXT_FIRE_TIME);
CREATE INDEX IDX_QRTZ_T_NFT_ST ON QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_STATE,NEXT_FIRE_TIME);
CREATE INDEX IDX_QRTZ_T_NFT_MISFIRE ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME);
CREATE INDEX IDX_QRTZ_T_NFT_ST_MISFIRE ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_T_NFT_ST_MISFIRE_GRP ON QRTZ_TRIGGERS(SCHED_NAME,MISFIRE_INSTR,NEXT_FIRE_TIME,TRIGGER_GROUP,TRIGGER_STATE);
CREATE INDEX IDX_QRTZ_FT_TRIG_INST_NAME ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,INSTANCE_NAME);
CREATE INDEX IDX_QRTZ_FT_INST_JOB_REQ_RCVRY ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,INSTANCE_NAME,REQUESTS_RECOVERY);
CREATE INDEX IDX_QRTZ_FT_J_G ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,JOB_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_FT_JG ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,JOB_GROUP);
CREATE INDEX IDX_QRTZ_FT_T_G ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP);
CREATE INDEX IDX_QRTZ_FT_TG ON QRTZ_FIRED_TRIGGERS(SCHED_NAME,TRIGGER_GROUP);
5.6 quartz集群原理
5.6.1 原理
一个Quartz集群中的每个节点是一个独立的Quartz应用,它又管理着其他的节点。这就意味着你必须对每个节点分别启动或停止。Quartz集群中,独立的Quartz节点并不与另一其的节点或是管理节点通信,而是通过相同的数据库表来感知到另一Quartz应用的。也就是说只有使用持久化JobStore存储Job和Trigger才能完成Quartz集群。

Quartz的集群部署方案是分布式的,没有负责集中管理的节点,而是利用数据库行锁的方式来实现集群环境下的并发控制。
一个scheduler实例在集群模式下首先获取{0}LOCKS表中的行锁;
向Mysql获取行锁的语句:
select * from {0}LOCKS where sched_name = ? and lock_name = ? for update
{0}会替换为配置文件默认配置的QRTZ_。sched_name为应用集群的实例名,lock_name就是行级锁名。Quartz主要由两个行级锁。
| lock_name | desc |
|---|---|
| STATE_ACCESS | 状态访问锁 |
| TRIGGER_ACCESS | 触发器访问锁 |
Quartz集群争用触发器行锁,锁被占用只能等待,获取触发器行锁之后,先获取需要等待触发的其他触发器信息。数据库更新触发器状态信息,及时是否触发器行锁,供其他调度实例获取,然后在进行触发器任务调度操作,对数据库操作就要先获取行锁。
#quartz定时任务
spring.quartz.jdbc.initialize-schema = never
##集群只在存储方式是jobstore才有效
spring.quartz.job-store-type=jdbc
##同样名字的job在插入到表中会报错,设置为true会覆盖之前相同名字的job
spring.quartz.overwrite-existing-jobs=true
spring.quartz.properties.org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX
##配置集群的话,必须实例名一样
spring.quartz.properties.org.quartz.scheduler.instanceName = MyClusteredScheduler
##根据主机以及时间戳生成实例id
spring.quartz.properties.org.quartz.scheduler.instanceId = AUTO
spring.quartz.properties.org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
spring.quartz.properties.org.quartz.threadPool.threadCount = 5
##mysql使用的驱动代理
spring.quartz.properties.org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
spring.quartz.properties.org.quartz.jobStore.tablePrefix=QRTZ_
##开启集群配置
spring.quartz.properties.org.quartz.jobStore.isClustered=true
spring.quartz.properties.org.quartz.plugin.shutdownHook.class=org.quartz.plugins.management.ShutdownHookPlugin
spring.quartz.properties.org.quartz.plugin.shutdownHook.cleanShutdown=TRUE
同一集群下,instanceName必须相同,instanceId可自动生成,isClustered为true,持久化存储,指定数据库类型对应的驱动类和数据源连接。
5.6.2 ClusterManager集群管理线程
5.6.2.1 线程执行:
每个服务器会定时(org.quartz.jobStore.clusterCheckinInterval这个时间)更新SCHEDULER_STATE表的LAST_CHECKIN_TIME,若这个字段远远超出了该更新的时间,则认为该服务器实例挂了;
注意:每个服务器实例有唯一的id,若配置为AUTO,则为hostname+current_time
流程:
1.检查是否有超时的实例failedInstances;
2.更新该服务器实例的LAST_CHECKIN_TIME;若有超时的实例:
3.获取STATE_ACCESS锁;
4.获取超时的实例failedInstances;
5.获取TRIGGER_ACCESS锁;
6.clusterRecover:
•针对每个failedInstances,通过instanceId获取每个实例的firedTriggers;
•针对每个firedTrigger:
•更新trigger状态:
BLOCKED->WAITING
PAUSED_BLOCKED->PAUSED
ACQUIRED->WAITING
•若firedTrigger不是ACQUIRED状态(在执行状态),且jobRequestRecovery=true:
创建一个SimpleTrigger,存储到trigger表,status=waiting,MISFIRE_INSTR=MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY.
•删除firedTrigger
5.6.2.2 流程图

5.7 quartz问题
5.7.1 时间同步问题
•Quartz实际并不关心你是在相同还是不同的机器上运行节点。
•当集群放置在不同的机器上时,称之为水平集群。
•节点跑在同一台机器上时,称之为垂直集群。
•对于垂直集群,存在着单点故障的问题。这对高可用性的应用来说是无法接受的,因为一旦机器崩溃了,所有的节点也就被终止了。
•对于水平集群,存在着时间同步问题。
•节点用时间戳来通知其他实例它自己的最后检入时间。假如节点的时钟被设置为将来的时间,那么运行中的Scheduler将再也意识不到那个结点已经宕掉了。
•另一方面,如果某个节点的时钟被设置为过去的时间,也许另一节点就会认定那个节点已宕掉并试图接过它的Job重运行。
•最简单的同步计算机时钟的方式是使用某一个Internet时间服务器(Internet Time Server ITS)。
5.7.2 节点争抢Job问题
因为Quartz使用了一个随机的负载均衡算法,Job以随机的方式由不同的实例执行。
Quartz官网上提到当前,还不存在一个方法来指派(钉住) 一个 Job 到集群中特定的节点。
5.7.3 从集群获取Job列表问题
当前,如果不直接进到数据库查询的话,还没有一个简单的方式来得到集群中所有正在执行的Job列表。请求一个Scheduler实例,将只能得到在那个实例上正运行Job的列表。Quartz官网建议可以通过写一些访问数据库JDBC代码来从相应的表中获取全部的Job信息。
5.7.4 Quartz集群如何保证高并发下不重复跑
Quartz有多个节点同时在运行,而任务是共享的,这时候肯定存在资源竞争问题,容易造成并发问题
Quartz是通过数据库去作为分布式锁来控制多进程并发问题,Quartz加锁的地方很多
Quartz是使用悲观锁的方式进行加锁,让在各个instance操作Trigger任务期间串行
使用数据库锁需要在.properties中加以下配置,让集群生效Quartz才会对多个instance进行并发控制
有正在执行的Job列表。请求一个Scheduler实例,将只能得到在那个实例上正运行Job的列表。Quartz官网建议可以通过写一些访问数据库JDBC代码来从相应的表中获取全部的Job信息。
5.7.4 Quartz集群如何保证高并发下不重复跑
Quartz有多个节点同时在运行,而任务是共享的,这时候肯定存在资源竞争问题,容易造成并发问题
Quartz是通过数据库去作为分布式锁来控制多进程并发问题,Quartz加锁的地方很多
Quartz是使用悲观锁的方式进行加锁,让在各个instance操作Trigger任务期间串行
使用数据库锁需要在.properties中加以下配置,让集群生效Quartz才会对多个instance进行并发控制
6.xxl-job任务调度
Quartz作为开源作业调度中的佼佼者,是作业调度的首选。但是集群环境中Quartz采用API的方式对任务进行管理,从而可以避免上述问题,但是同样存在以下问题:
•问题一:调用API的的方式操作任务,不人性化;
•问题二:需要持久化业务QuartzJobBean到底层数据表中,系统侵入性相当严重。
•问题三:调度逻辑和QuartzJobBean耦合在同一个项目中,这将导致一个问题,在调度任务数量逐渐增多,同时调度任务逻辑逐渐加重的情况下,此时调度系统的性能将大大受限于业务;
•问题四:quartz底层以“抢占式”获取DB锁并由抢占成功节点负责运行任务,会导致节点负载悬殊非常大;而XXL-JOB通过执行器实现“协同分配式”运行任务,充分发挥集群优势,负载各节点均衡。
XXL-JOB弥补了quartz的上述不足之处。
https://www.xuxueli.com/xxl-job/#%E3%80%8A%E5%88%86%E5%B8%83%E5%BC%8F%E4%BB%BB%E5%8A%A1%E8%B0%83%E5%BA%A6%E5%B9%B3%E5%8F%B0XXL-JOB%E3%80%8B