Kafka会不会重复消费
本文来说下kafka会不会重复消费的问题。在单体架构时代,就存在着接口幂等性的问题,只不过到了分布式、高并发的场景之后,接口幂等性的问题会更加明显。
文章目录
- 概述
- 消息重复消费问题
- 解决方案
-
- 方案一 / 保存并查询
- 方案二 / 利用幂等
- 方案三 / 设置前置条件
- 幂等性的概念
- 保证幂等性的解决方案
-
- 唯一索引
- 悲观锁
- 分布式锁
- 全局唯一 ID
- 数据版本号
- 业务状态
- 去重表
- 本文小结
概述
如何保证消息不被重复消费?或者说,如何保证消息消费的幂等性?
其实这是很常见的一个问题,这俩问题基本可以连起来问。既然是消费消息,那肯定要考虑会不会重复消费?能不能避免重复消费?或者重复消费了也别造成系统异常可以吗?这个是 MQ 领域的基本问题,其实本质上还是问你使用消息队列如何保证幂等性,这个是你架构里要考虑的一个问题。

消息重复消费问题
回答这个问题,首先你别听到重复消息这个事儿,就一无所知吧,你先大概说一说可能会有哪些重复消费的问题。
首先,比如 RabbitMQ、RocketMQ、Kafka,都有可能会出现消息重复消费的问题,正常。因为这问题通常不是 MQ 自己保证的,是由我们开发来保证的。挑一个 Kafka 来举个例子,说说怎么重复消费吧。
Kafka 实际上有个 offset 的概念,就是每个消息写进去,都有一个 offset,代表消息的序号,然后 consumer 消费了数据之后,每隔一段时间(定时定期),会把自己消费过的消息的 offset 提交一下,表示“我已经消费过了,下次我要是重启啥的,你就让我继续从上次消费到的 offset 来继续消费吧”。
但是凡事总有意外,比如我们之前生产经常遇到的,就是你有时候重启系统,看你怎么重启了,如果碰到点着急的,直接 kill 进程了,再重启。这会导致 consumer 有些消息处理了,但是没来得及提交 offset,尴尬了。重启之后,少数消息会再次消费一次。
我们在做开发的时候为了程序的健壮性,在使用 Kafka 的时候一般都会设置重试的次数,但是因为网络的一些原因,设置了重试就有可能导致有些消息重复发送了(当然导致消息重复也有可能是其他原因),那么怎么解决消息重复这个问题呢?关于这个问题,我这儿提供了如下三种解决方案,供大家参考。
解决方案
方案一 / 保存并查询
给每个消息都设置一个独一无二的 key,消费的时候把 key 记录下来,然后每次消费新的消息的时候都查询一下,看当前消息的这个 key 是否消费过,如果没有消费过才进行消费。(这种方式好想,但是其实实现起来一点也不简单)

方案二 / 利用幂等
幂等(Idempotence)在数学上是这样定义的,如果一个函数 f(x) 满足:f(f(x)) = f(x),则函数 f(x) 满足幂等性。这个概念被拓展到计算机领域,被用来描述一个操作、方法或者服务。一个幂等操作的特点是,其任意多次执行所产生的影响均与一次执行的影响相同。一个幂等的方法,使用同样的参数,对它进行多次调用和一次调用,对系统产生的影响是一样的。所以,对于幂等的方法,不用担心重复执行会对系统造成任何改变。
我们举个例子来说明一下。在不考虑并发的情况下,“将 X 老师的账户余额设置为 100 万元”,执行一次后对系统的影响是,X 老师的账户余额变成了 100 万元。只要提供的参数 100万元不变,那即使再执行多少次,X 老师的账户余额始终都是 100万元,不会变化,这个操作就是一个幂等的操作。
再举一个例子,“将 X 老师的余额加 100 万元”,这个操作它就不是幂等的,每执行一次,账户余额就会增加 100 万元,执行多次和执行一次对系统的影响(也就是账户的余额)是不一样的。
所以,通过这两个例子,我们可以想到如果系统消费消息的业务逻辑具备幂等性,那就不用担心消息重复的问题了,因为同一条消息,消费一次和消费多次对系统的影响是完全一样的。也就可以认为,消费多次等于消费一次。
那么,如何实现幂等操作呢?最好的方式就是,从业务逻辑设计上入手,将消费的业务逻辑设计成具备幂等性的操作。但是,不是所有的业务都能设计成天然幂等的,这里就需要一些方法和技巧来实现幂等。
下面我们介绍一种常用的方法:利用数据库的唯一约束实现幂等。
例如,我们刚刚提到的那个不具备幂等特性的转账的例子:将 X 老师的账户余额加 100 万元。在这个例子中,我们可以通过改造业务逻辑,让它具备幂等性。
首先,我们可以限定,对于每个转账单每个账户只可以执行一次变更操作,在分布式系统中,这个限制实现的方法非常多,最简单的是我们在数据库中建一张转账流水表,这个表有三个字段:转账单 ID、账户 ID 和变更金额,然后给转账单 ID 和账户 ID 这两个字段联合起来创建一个唯一约束,这样对于相同的转账单 ID 和账户 ID,表里至多只能存在一条记录。
这样,我们消费消息的逻辑可以变为:“在转账流水表中增加一条转账记录,然后再根据转账记录,异步操作更新用户余额即可。”在转账流水表增加一条转账记录这个操作中,由于我们在这个表中预先定义了“账户 ID 转账单 ID”的唯一约束,对于同一个转账单同一个账户只能插入一条记录,后续重复的插入操作都会失败,这样就实现了一个幂等的操作。

方案三 / 设置前置条件
为更新的数据设置前置条件另外一种实现幂等的思路是,给数据变更设置一个前置条件,如果满足条件就更新数据,否则拒绝更新数据,在更新数据的时候,同时变更前置条件中需要判断的数据。
这样,重复执行这个操作时,由于第一次更新数据的时候已经变更了前置条件中需要判断的数据,不满足前置条件,则不会重复执行更新数据操作。
比如,刚刚我们说过,“将 X 老师的账户的余额增加 100 万元”这个操作并不满足幂等性,我们可以把这个操作加上一个前置条件,变为:“如果X老师的账户当前的余额为 500万元,将余额加 100万元”,这个操作就具备了幂等性。
对应到消息队列中的使用时,可以在发消息时在消息体中带上当前的余额,在消费的时候进行判断数据库中,当前余额是否与消息中的余额相等,只有相等才执行变更操作。
但是,如果我们要更新的数据不是数值,或者我们要做一个比较复杂的更新操作怎么办?用什么作为前置判断条件呢?更加通用的方法是,给你的数据增加一个版本号属性,每次更数据前,比较当前数据的版本号是否和消息中的版本号一致,如果不一致就拒绝更新数据,更新数据的同时将版本号 +1,一样可以实现幂等。

幂等性的概念
那么什么是幂等性呢?
当用户对同一操作请求了一次或者多次,最终的结果是一致的,并不会因为多次请求产生副作用;比如同一个订单支付了两次,最后应该只扣客户一次钱。
查询和删除:查询具有天然的幂等性,在数据不变的前提下,相同查询条件查询一次和查询多次的结果都是一样的;删除也一样,相同的条件删除一次和删除多次,可能删除的数据量不一样,但是数据库中的数据不会因为执行了多次删除而不同。
新增和修改:如果不做幂等性处理,可能就会产生问题;执行多次新增操作,可能会导致一模一样的数据产生了多条(主键自动生成);修改操作,如果只是把某些字段更新成固定的值,不会有幂等性问题,但是如果新值要在旧值上做处理做计算,如增加多少、减少多少,那么多次执行的结果就会有差异。
那么为了保证接口的幂等性,有哪些方法呢?
保证幂等性的解决方案
唯一索引
使用唯一索引,可以有效的防止新增脏数据:当表中存在唯一索引的时候,并发新增相同数据的时候就会报错,不过这在单库单表的时候才有效,如果项目数据量很大,采用了分库分表的策略,就不能再通过数据库的唯一性索引来解决幂等性的问题了。
悲观锁
获取数据的时候加锁获取;
select * from table where col='xxx' for update;
这里要注意, where 条件中的字段必须是主键或者有索引,否则会锁全表。
分布式锁
在业务系统执行插入或更新操作的时候,先要获取分布式锁,然后做操作,之后释放锁;分布式锁保证在一个时间内,只会有一个线程对数据进行操作。
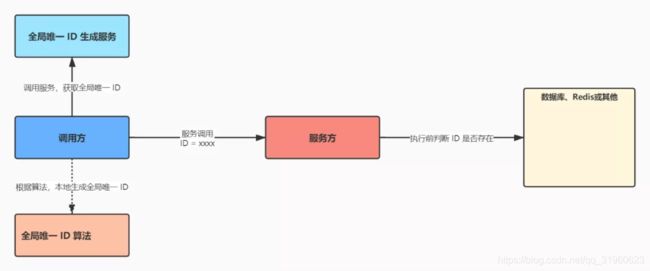
全局唯一 ID
每次请求,都生成一个全局的唯一 ID,接口调用的时候携带者这个 ID,而业务操作方在之执行前判断这个 ID 是否已经在本地存在,如果不存在,则执行交易后记录 ID(存到数据库或Redis中,表示该交易已经执行);如果已经存在,表示交易已经执行过了,不能再次执行。
许多分布式架构中,生成全局唯一 ID 都会被作为一个基础的微服务,当然这个服务的可靠性要求极高,或者可以使用全局唯一 ID 算法,由每个应用自己生成。不过总的来说,引入全局唯一 ID 这个方案,实现起来还是非常繁琐的。
数据版本号
这个方案算是乐观锁的一种;在数据中增加版本号的概念,那么在做数据修改,把当前数据的版本号带上,修改的时候要按照版本号判断数据是否发生过更改。如果没有发生过更改,则执行业务操作,并更新版本号(这种方法适合在更新的场景中)。
下面的代码,意会一下:
updateDate(Object obj , int version);
update set obj , version+1 where ... and version = 入参version;
业务状态
有些业务流程,每一步都是有状态的,比如网上购物可能会有:订单创建、付款、发货,那么付款之前保单状态为“待付款”,付款之后可以将保单的状态修改为“待发货”;那么如果发起重复扣款的话,第二次扣款的时候保单状态已经变化了,就会扣款失败。

去重表
如果业务中有唯一性的标识时,可以使用去重表,把这个唯一性的表示保存到去重表中,如果重复插入,那么会被校验住。
比如上面的场景,一个订单只会付款一次,那么在付款的时候,把订单号作为唯一性的标识,保存到去重表中,可以保证付款操作只会发生一次;这个方法也用到了唯一 ID,不过和全局唯一 ID 不同,这个唯一 ID 是针对具体业务的。

本文小结
本文详细介绍了kafka消息重复消费以及幂等性相关的话题。