GitOps实践指南:GitOps能为我们带来什么?
Git,作为开发过程中的核心工具,提供了强大的版本控制功能。即便在写代码的时候稍微手抖一下,我们也能通过 Git 的差异对比(diff)轻松追踪到庞大工程中的问题,确保代码的准确与可靠。这种无与伦比的自省能力,不仅提高了工作效率,也带来了极大的安全感,让一切都有迹可循。
如果上面的这些能力在运维上也能实现,是不是稳定性会特别好,变更时候想出故障都难?任何非预期的变化都能通过diff对比出来?是的。GitOps就是基于这些触发点而产生的。2017年Weaveworks的CEO Alexis Richardson 提出了这个概念:通过一个模型抽象使得整个系统的操作变得自动化,使用Git来承载这个模型。
不过这么多年过去了,GitOps相关的产品和平台层出不穷,除了WeaveWorks,似乎大家对GitOps各有各的理解和实践:似乎解决了一些问题,但似乎又没完全解决。那么,问题到底出在哪里?GitOps到底能为我们带来些什么?本文尝试展开讲讲这个问题。
首先,我们先从日常的工作开始思考,我们到底希望GitOps帮我们实现哪些目标?我先列了三个目标,大家看看是不是也有类似的想法:
- 变更自动化:只要把代码提交到git中,就进行自动构建、自动测试、自动部署,不要让我到处点按钮。
- 变更代码化:变更到底会变哪些东西,影响哪些基础设施,能否直接在代码中就能看出?不要在一句“风险可控”背后藏着一个没人能理得清的操作流程。
- 变更透明化:变更信息中包含所有的源码变化,不要包含一些无法展开的引用关系:比如容器镜像tag变化需要有对应的构建源码的变化。
带着这三个目标,我们先去找找业界对于GitOps的定义,看看是否能找到一些线索:
一、GitOps是什么
云原生基金会(CNCF)在2021年成立了一个OpenGitOps工作组,旨在推广GitOps的最佳实践。在这个工作组的官网首页放着四条GitOps的原则:
- Declarative:声明式
- Versioned and Immutable:版本化且不可变
- Pulled Automatically:自动拉取
- Continuously Reconciled:持续调和
这四条原则基本是WeaveWorks的GitOps定义的一个深化,而且较多地推荐使用Flux进行GitOps实践,有关这块介绍,我们会在第三章展开。鉴于这个工作组中能得到的有效信息实在太少,我们继续寻找业界有关GitOps的介绍。
GitLab出版过一本电子书叫《A beginners guide to GitOps》(下载地址在参考材料中),在书中提出了一个概念公式:GitOps = IaC + MRs + CI/CD。这个概念就比前面的GitOps四原则更具体一些了:
- IaC (Infrastructure as Code): 指出GitOps管理模型就应该是IaC,这比原则中的Declarative更进了一步:这不仅仅是关于声明性配置,而是关于将整个基础设施的管理嵌入到代码之中,从而实现更精确和可重复的部署过程。
- MRs (Merge Requests):明确指出,在 GitOps 中,管理动作不是通过直接提交代码来完成,而是通过一系列的合并请求(Merge Request)。这种方法允许进行更深入的风险评估和审计,在代码合并到生产环境之前确保质量和安全。
- CI/CD (Continuous Integration/Continuous Delivery):GitOps 的最终目标是实现代码的自动化集成和持续交付:既确保严格的测试验证,又能加速开发周期,保持高质量和稳定性。
在第四章,我们会展开说说如何基于这个公式去进行GitOps实践。
本来我的觉得GitOps差不多概念也就这样了,基本上几大厂商的观点都看过了。没想到又在亚马逊上看到了一本书《Repeatability, Reliability, and Scalability through GitOps》(购买链接在参考材料中),阅读之后对于GitOps的认知又拓宽了不少,作者在书中提出了三种类型的GitOps:
- The Original GitOps: 原始GitOps,即k8s做IaC,然后落地GitOps的方案。
- The Purist GitOps: 纯粹GitOps,不一定基于k8s,但是基于某种IaC+GitOps进行落地的方案,使用终态的方式来进行管理。
- The Verified GitOps: 验证型GitOps,也不一定有终态管理,只要确保整个过程中有git diff能验证即可。
说实话,第三种类型的GitOps让我豁然开朗,这种GitOps确实更贴近实际落地:IaC的改造推广常常会有较大的成本,而在没有改造完之前,就不能享受GitOps带来的好处了吗?作者告诉我们一种选择,这种以验证为目的GitOps就行。
作者为了让我们更能深入地理解这个验证型GitOps,还画了一张流程示意图:红色部分为人工,绿色部分为自动。从图中可以看到,自动的流程在右侧自动流转,左侧分别是development、devops、sre三种角色在根据git diff进行验证审计。
二、Infrastructure as Code要怎么做
通过前面一些概念,我们能看到声明式&IaC在gitops中占据非常重要的部分。可以这样说,如果IaC无法承载所有的运维编排能力,运维编排需求可以会外溢到其他系统或平台上,那么这部分外溢的逻辑就无法使用Git来追踪了:所以这个IaC的声明式的编排能力会变得尤为重要。
在分析IaC方案之前,我们先来看看声明式编程(Declarative)和命令式编程(Imperative)的区别:
- 常见的声明式编程语言有SQL和HTML,我们来写个常见的例子:
# 使用SQL查询数据库中的年龄超过30岁的用户
SELECT name, age FROM users WHERE age > 30;- 常见的命令式编程包括过程式编程(Procedural Programming)和面向对象编程(Object-Oriented Programming),还是上面的这个查询年龄超过30岁的用户的例子,使用Python写则会变成这样
users = [{"name": "Alice", "age": 25}, {"name": "Bob", "age": 35}, {"name": "Carol", "age": 32}]
users_over_30 = []
for user in users:
if user["age"] > 30:
users_over_30.append(user)
通过这两个例子大家可以明显地感觉到声明式编程的可读性更强,描述结果并且只关注结果;与之相对应的是,过程式编程需要理解整个过程,才能知道这段代码在干什么。
我们来列一下市面上比较流行的IaC方案:
- Terraform:HashiCorp公司于2014年创建,提供人们使用HashiCorp Configuration Language(HCL)来声明式编写基础设施的能力。Terraform的社区生态非常活跃,其provider支持几乎所有的云厂商。
- Crossplane:Crossplane 是在 2018 年由 Upbound 公司推出,旨在通过扩展 Kubernetes 的能力,提供统一的多云和混合云环境下的基础设施即服务(IaaS)管理解决方案。
- Pulumi: Pulumi是在2017年由几位前微软员工成立的Pulumi Corp 创立的。与Terraform等工具不同,Pulumi允许使用常用的编程语言(如Python、TypeScript、JavaScript等)来定义和部署基础设施,从而使得基础设施代码更容易理解和维护。
光这样讲会有些抽象,我们围绕着一个例子来比较一下这几种IaC方案,如何来创建一个阿里云ECS:

从上面的例子可以看到,Terraform作为早期的IaC方案,这样声明确实大大简化基础设施的使用成本,只要几行代码就能申请出一台虚拟机。Crossplane是扩展k8s的能力,所以每种基础设施都是一个CRD。但标准的YAML也带来一个问题就是遇到一些复杂的条件渲染,就无能为力了,它不像Terraform的HCL能够在语言中增加一些模板类的控制语句,它需要通过自定义控制器来解决,这无疑增加了IaC交付的难度。
Pulumi明显吸收了Terraform的经验:既然IaC中的模板等控制流无法避免,与其想方设法设计包含过程函数的声明式编程语言,不如我干脆就还是用普通编程语言,只是在SDK中引导用户声明式编程,保留用户使用控制语句的权利。
虽然各种IaC提供了非常方便的基础设施交付方案,但事实上如果真正进行工程化的使用,就会遇到一个状态存储的问题。每个IaC都必须将状态存储下来,才是一份完整的幂等声明,如下图所示:

如果没有这份状态文件,反复执行同一份IaC声明,就会不断地创建资源。对于GitOps而言,所有的变化都必须可以被git commit追踪:这份状态文件同样至关重要,已经创建过的资源不能再创建,否则可能就会产生生产故障。
由于状态文件维护的复杂性,但有些用户又垂涎IaC声明式交付的便利,就会衍生出这样的半吊子的使用场景:只用IaC进行资源创建,后续维护依然使用原有的模式,这样就不用管理创建时产生的状态文件。 事物存在即合理,也不能说这样的方案有什么问题,但确实从另外一个侧面反映出一个问题:IaC的声明代码无法表达全部终态,必须要加上状态文件才构成幂等完整的终态。这个问题也带给我们了一个提醒:GitOps需要将状态也纳入进去,否则无法达成前面提到的“变更透明化”这个目标。
三、GitOps相关产品分析
分析完了IaC方案,我们继续来看GitOps相关产品,我们来分析一下:由于GitOps是在k8s社区中发展起来,所以现在市面上的GitOps基本都是围绕着k8s容器编排展开,如我们第一章所提到 The Original GitOps(原始GitOps)。
我们首先来看看最老牌的CI/CD工具Jenkins在k8s下的演进:Jenkins X。
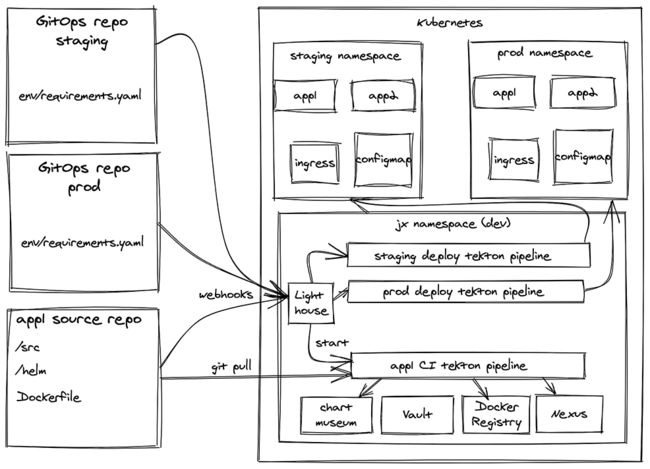
通过这张架构图我们可以看出Jenkins X在k8s场景下,放弃了原有的JenkinsFile的构建编排能力,转而使用Tekton来进行构建流水线的编排。Jenkins整体的侧重CI的,在Jenkins X中依然如此,流水线主要是为CI服务,在流水线的末端会有几个CD节点将实例部署到目标环境。这种CI/CD串联的方案适合小型工程,对于大一些的工程,其CD能力则会有些捉襟见肘,因为毕竟只是几个shell命令的组合。
从整体上看,Jenkins X能够实现“变更自动化”,但其他方面则稍显不足。
然后我们来看一下ArgoCD,这是在GitOps领域的当红炸子鸡,它通过一个Application的CRD实现了k8s的YAML的控制权的转移。需要操作k8s集群的需求,转变成了在git中提交git commit。下面是ArgoCD的GitOps架构图:
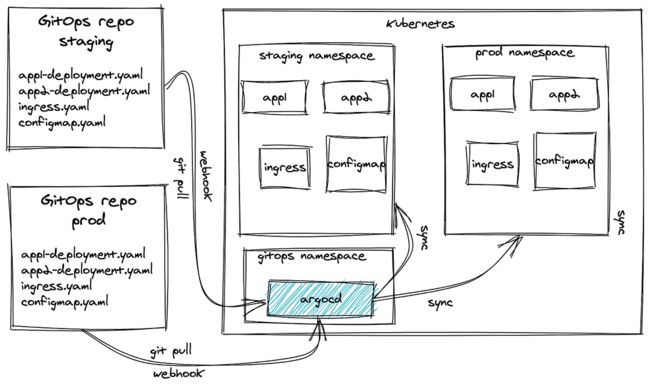
ArgoCD和Jenkins X这类方案比起来少了很多功能,但架不住它简单好用:只需要把Helm包推到git上,他就会被自动部署到k8s环境之上。ArgoCD的这种纯CD的方案有个自动化的短板就是:在CI环节构建完的容器镜像,需要手工把他们拷贝到Helm包中,然后提交git。虽然说这种镜像地址的人肉拷贝也是个常见的行为,但是毕竟我们当前是在调研完整的GitOps方案,如果从源头上就不支持,那只能说他在“变更自动化”这块存在不足。
最后,我们来看一下FluxCD,这是GitOps概念提出者WeaveWorks公司的开源产品。这个FluxCD确实属于对GitOps的践行产物,在ArgoCD中仅用Application盖住的概念,在这里被分成了Source、Helm、Image Automation 等,分别有对应的控制器来负责干活:

不得不说,FluxCD中的概念还是非常完整的,同时它也有ImageUpdateAutomation这样一个对象,专门用来进行镜像的自动更新、如果在镜像仓库中出现新镜像,它就会自动提交一个git commit把对应的镜像字段更新,这个机制完美地解决了ArgoCD中人手工拷贝的问题:不过度介入CI环节,但对于CI环节的制品能自动感知,自动部署。
四、GitOps动手实践
通过前三章节的介绍,我们对GitOps的构成基本清晰了,复用一下GitLab中的那个公式基本就是 GitOps = IaC + MRs + CI/CD,不过从IaC开始做存在较大挑战,毕竟需要从源头改变整个链路,我们可以先从CI/CD开始。
我们先尝试解决第一个问题“变更透明化”:增强对于构建环节的制品采集能力,将每个制品的sha256、git commit以及名称全部采集到数据库。尽量不改变原有的CI流程,在CI最终出制品的节点后将信息采回。
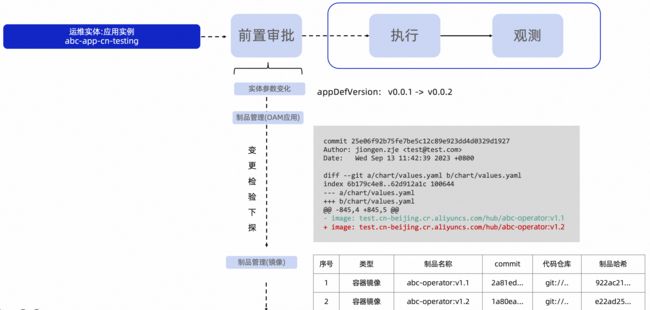
有了制品信息之后,我们就能对每次复杂的变更进行源码下探,遇到镜像变更,就制品仓库中找到对应的源码进一步下探(inspect),使得原本两眼一抹黑的镜像变化,也变得清晰透明。
事实上,从The Verified GitOps(验证型GitOps)的角度看,基于制品做变更透视方案已经将GitOps达成了。不过我们一开始定的目标还有两个没有完全达成:变更自动化、变更代码化。自动化这块其实反倒是简单,在CI的最后一个节点接上变更平台的接口即可。变更代码化这块则需要我们设计一套声明式的方案来编排整个变更链路:这里最大的挑战是对于已有流程和平台的整合。
IaC的语法设计是个苦差事,这么多大牛前仆后继,市面的IaC语言似乎总无法完全用声明的方式,解决基础设施编排的问题。Pulumi这套方案给了我们很大的启发,既然这样,为何不直接用现有的编程语言?
于是我们借鉴Pulumi设计了一套SRE Stack方案:
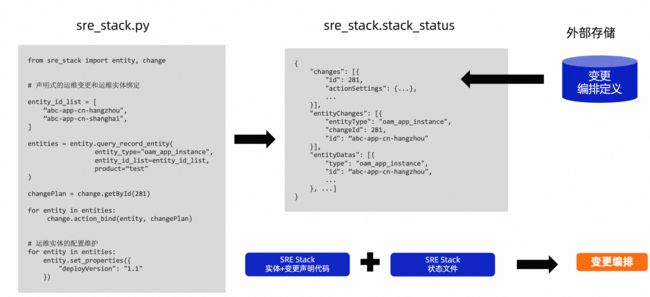
- 我们提供sre_stack供用户在熟悉的编程环境(以Python为例)下编排他的变更过程。
- IaC代码 + 状态文件构成了完整的变更描述,弥补了terraform这类的IaC工具在状态管理中的不足。
- 状态文件本质上也是一张数据快照,对于包含外部系统的数据的一个快照,所以可以友好地实现跨平台的数据整合。
有人可能就会问,如果有人不在sre_stack.py中维护终态,转而在外部系统中维护数据是不是也是可以的。是的,本身这个方案就考虑到了对原有系统的整合,所以这种情况是允许的,但我们能结构化地检查和审计出来:如果sre_stack.py文件没有变化,而status文件变化了,意味着这是一个非IaC驱动的终态变化。如果我们能接受这次变化(毕竟某些低频的复杂操作可能确实没那么适合在IaC中表达),只要审批过了,下次就不会再出现。整个流程如下图所示:
针对开分支,开发者提交了MergeRequest之后,会自动触发SRE Stack的状态渲染,将status文件补全进代码中,因此在审批环节就能完整地看到变化,在本章的开头部分,我们已经对于制品管理以及透视机制有了介绍,因此在通过IaC下的产生的变更透视树就变成了下面的样子:

于是,通过SRE Stack+制品管理,我们基本实现了这三个目标:
- 变更自动化:只要修改stack文件,发起MergeRequest,就进行自动渲染、自动部署,如果将代码构建的最后一个节点变成修改stack文件,就能实现CI到CD的无缝衔接。
- 变更代码化:stack文件中,使用声明的方式描述了变更的目标和行为,使得我们只要查看stack文件和状态文件,就能知道这次变更的内容是什么。
- 变更透明化:通过CI环节的制品信息采集,在最终的变更审批环节,我们能够透视出包含源码的完整的变更栈,不再有无法展开的引用关系。
五、总结
当前GitOps体系已经在内部逐步使用推广,有相应需求的公司可以联系SREWorks进行开源共建,我们可以将其作为一款SREWorks运维应用逐步对外推出。
参考材料
- weaveworks blog: The History of GitOps The History of GitOps
- OpenGitOps工作组官网 Home | OpenGitOps
- 《A beginners guide to GitOps》GitLab
- 《Repeatability, Reliability, and Scalability through GitOps》Amazon.com
- 《Pulumi 到底比 Terraform 强在哪》Pulumi 到底比 Terraform 强在哪
- 《Crossplane 是下一代 IaC 么》Crossplane 是下一代 IaC 么
- 《规模化环境Terraform状态管理技巧》规模化环境Terraform状态管理技巧
- 《FluxCD, ArgoCD or Jenkins X: Which Is the Right GitOps Tool for You?》FluxCD, ArgoCD or Jenkins X: Which Is the Right GitOps Tool for You?
- 《Tekton入门介绍》Tekton入门介绍-腾讯云开发者社区-腾讯云
- 《Automatic image update in Git with FluxCD》Automatic image update in Git with FluxCD