Pandas数据分析02——各类文件的读取和导出
参考书目:《深入浅出Pandas:利用Python进行数据处理与分析》

pandas真的很强大,几乎什么格式的数据 都能读取,什么csv,excel,spss,stata,json,html......连剪贴板的数据都能读.....本章教大家怎么读取数据,虽然简单读取就一句话,但是参数和功能还是很多的,都了解一下。
读取CSV文件
csv文件最基础的数据文件,介绍的最详细,因为别的文件的很多参数和csv读取方法都差不多
import pandas as pd
import numpy as np
# 文件目录
pd.read_csv('data.csv') # 如果文件与代码文件在同目录下
pd.read_csv('D:\AAA最近要用\深度学习\自己的项目\风力发电\少一点.csv') # 指定目录
pd.read_csv('data\my\my.data') # CSV 文件扩展名不一定是 csv
# 使用网址 url
pd.read_csv('https://www.gairuo.com/file/data/dataset/GDP-China.csv')
字符串中读取
# 也可以从 StringIO 中读取
from io import StringIO
data = ('col1,col2,col3\n'
'a,b,1\n'
'a,b,2\n'
'c,d,3')
pd.read_csv(StringIO(data)).to_csv('data.data',index=False) #存一下分隔符
# 数据分隔转化是逗号, 如果是其他可以指定
pd.read_csv('data.data', sep='\t') # 制表符分隔 tab
pd.read_table('data.data') # read_table 默认是制表符分隔 tab
pd.read_csv('data.data', sep='|') # 制表符分隔 tab
指定列名和表头
#指定列名和表头
pd.read_csv(data, header=0) #默认第一行
pd.read_csv(data, header=None) # 没有表头
pd.read_csv(data, names=['列1', '列2']) # 指定列名列表
pd.read_csv(data, names=['列1', '列2'],header=None) # 指定列名列表
# 如没列名,自动指定一个: 前缀加序数
pd.read_csv(data, prefix='c_', header=None) #表头为c_0,c_1...指定索引
#指定索引
pd.read_csv(data,index_col=False) #不使用首列作为索引
pd.read_csv(data,index_col=0) #第几列为索引
pd.read_csv(data,index_col='年份')#指定列名
pd.read_csv(data,index_col=['a','b']) #多个索引
pd.read_csv(data,index_col=[0,3]) #多索引读取部分列
# 读取部分列
pd.read_csv(data, usecols=[0,4,3]) # 按索引只读取指定列,顺序无关
pd.read_csv(data, usecols=['列1', '列5']) # 按索引只读取指定列
# 指定列顺序,其实是 df 的筛选功能
pd.read_csv(data, usecols=['列1', '列5'])[['列5', '列1']]
pd.read_csv(data, index_col=0) # 第几列是索引
# 以下用 callable 方式可以巧妙指定顺序, in 后边的是我们要的顺序
pd.read_csv(data, usecols=lambda x: x.upper() in ['COL3', 'COL1'])处理重复列名
#处理重复列名
data='a,b,a\n0,1,2\n5,6,4'
pd.read_csv(StringIO(data),mangle_dupe_cols=True)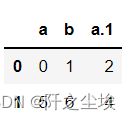
数据类型
#数据类型
data = 'https://www.gairuo.com/file/data/dataset/GDP-China.csv'
# 指定数据类型
pd.read_csv(data, dtype=np.float64) # 所有数据均为此数据类型
pd.read_csv(data, dtype={'c1':np.float64, 'c2': str}).info() # 指定字段的类型
pd.read_csv(data, dtype=[datetime,datetime,str,float]) #依次指定跳过指定行
#跳过指定行
pd.read_csv(data,skiprows=2) #跳过前两行
pd.read_csv(data,skiprows=range(2)) #跳过前两行
pd.read_csv(data,skiprows=[24,235,65]) #跳过指定行
pd.read_csv(data,skiprows=np.array([24,235,65])) #跳过指定行
pd.read_csv(data,skiprows=lambda x:x%2!=0) #隔行跳过
pd.read_csv(data,skipfooter=1) #从尾部跳过
pd.read_csv(data,skip_black_lines=True)#跳过空行读取指定行数
#读取指定行数
pd.read_csv(data,nrows=1000)空值替换
#空值替换
pd.read_csv(data,na_values=[0]) #0会被认为是缺失值
pd.read_csv(data,na_values='?') #?会被认为是缺失值
pd.read_csv(data,na_values='abc') #abc会被认为缺失值 等价['a','b','c']
pd.read_csv(data,na_values={'c':3,1:[2,5]}) #指定列被指定为NaN解析日期时间
# 解析日期时间
data = 'D:/AAA最近要用/数学建模/22美赛/数据/LBMA-GOLD.csv'
pd.read_csv(data, parse_dates=True).info()# 自动解析日期时间格式
pd.read_csv(data, parse_dates=['Date']).info() # 指定日期时间字段进行解析
# 将 0,1,2 列合并解析成名为 时间的 时间类型列
pd.read_csv('D:/AAA最近要用/深度学习/自己的项目/风力发电/少一点.csv', parse_dates={'时间':[0,1,2]}).info()
#保留原来的列
pd.read_csv('D:/AAA最近要用/深度学习/自己的项目/风力发电/少一点.csv', parse_dates={'时间':[0,1,2]},keep_date_col=True).info()
#日期在月份前的数据
pd.read_csv(data,dayfist=True,parse_dates=[0])# 指定时间解析库,默认是 dateutil.parser.parser
date_parser=pd.io.date_converters.parse_date_time
date_parser=lambda x: pd.to_datetime(x, utc=True, format='%D%M%Y')
date_parser=lambda d: pd.datetime.strptime(d,'%d%b%Y')
pd.read_csv(data, date_parser=date_parser)
#尝试转化为日期
pd.read_csv(data, date_parser=date_parser,infer_datetime_format=True)读取压缩包
#读取压缩包
pd.read_csv('sample.tar.gz',compression='gzip')
#指定读取编码
pd.read_csv('gairuo.csv',encoding='utf-8')
pd.read_csv('gairuo.csv',encoding='gk2312')#中文符号
#符号
pd.read_csv('test.csv',thousands=',')#千分位分隔符
pd.read_csv('test.csv',decimal=',,')#小数点,默认'.'
pd.read_csv(StringIO(data),escapechar='\n',encoding='utf-8')#过滤换行符
pd.read_csv(StringIO(s),sep=',',comment='#',skiprows=1) #一行有'#'就将跳过csv文件导出
df.to_csv('done.csv')
df.to_csv('data/done.csv') # 可以指定文件目录路径
df.to_csv('done.csv', index=False) # 不要索引
f.to_csv('done.csv', encoding='utf-8') #指定编码
#还可以用sep指定分隔符
df.Q1.to_csv('Q1_test.txt', index=None) # 指定一列导出 txt 格式文件导出压缩包
df=pd.read_csv('https://www.gairuo.com/file/data/dataset/GDP-China.csv')
#创建一个包含out.csv的压缩文件out.zip
com_opts=dict(method='zip',archive_name='out.csv')
df.to_csv('out.zip',encoding='gbk',index=False,compression=com_opts)
读取 Excel
excel需要这个前置包 openpyxl
pd.read_excel('team.xlsx')
pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')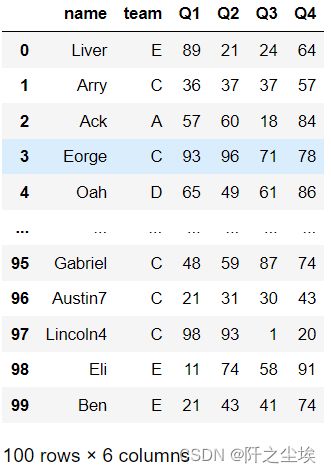
excel表多个sheet
#excel表多个sheet
xlsx = pd.ExcelFile('data.xlsx')
df = pd.read_excel(xlsx, 'Sheet1') # 读取
xlsx.parse('sheet1') # 取指定标签为 DataFrame
# Excel 的所有标签
xlsx.sheet_names # ['sheet1', 'sheet2', 'sheet3', 'sheet4']指定读取sheet
#指定读取sheet
pd.read_excel('team.xlsx', sheet_name=1) #第二个sheet
pd.read_excel('team.xlsx', sheet_name='总结') #名称
#读取多个sheet
pd.read_excel('team.xlsx', sheet_name=[0,1,'Sheet5'])#读取第一个第二个,第五个sheet,组成df字典
dfs=pd.read_excel('team.xlsx', sheet_name=None) #所有sheet
dfs['Sheet5']execl 导出
# 使用 ExcelFile 保存文件对象
df.to_excel('file.xlsx',sheet_name='sheet2',index=False)多个sheet
df1=df.describe()
# 可以把多个 Sheet 存入 ExcelFile
with pd.ExcelWriter('path_to_file.xlsx') as xls:
df1.to_excel(xls, 'Sheet1')
df.to_excel(xls, 'Sheet2',index=False)
网页文件读取
dfs = pd.read_html('https://www.gairuo.com/p/pandas-io')
dfs[0] # 查看第一个 df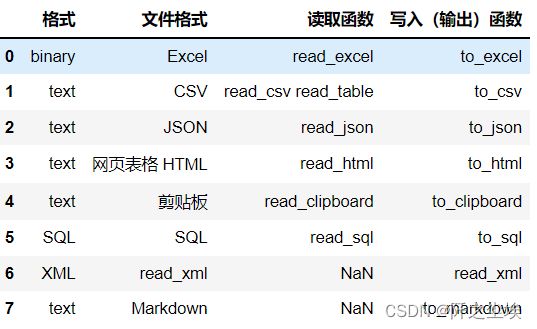
dfs = pd.read_html('data.html', header=0) #读取网页文件,第一行为表头
dfs = pd.read_html(url, index_col=0)# 第一列为索引
#表格很多可以指定元素获取
dfs1 = pd.read_html(url, attrs={'id': 'table'}) # id='table' 的表格,注意这儿仍然可能返回多个
# dfs1[0]
dfs2 = pd.read_html(url, attrs={'class': 'sortable'})# class='sortable'
# !!! 常用的功能与 read_csv 相同,可参考上文网页文件导出
df.to_html('网页文件.html')
df.to_html('网页文件.html',columns=[0])#输出指定列
df.to_html('网页文件.html',classes=['class1','class2'])#输出指定样式json读取
pd.read_json('data.json')
json = '''{"columns":["col 1","col 2"],
"index":["row 1","row 2"],
"data":[["a","b"],["c","d"]]}
'''
pd.read_json(json)
pd.read_json(json, orient='split') # json 格式
''' orient 支持:
- 'split' : dict like {index -> [index], columns -> [columns], data -> [values]}
- 'records' : list like [{column -> value}, ... , {column -> value}]
- 'index' : dict like {index -> {column -> value}}
- 'columns' : dict like {column -> {index -> value}} '''
json输出
df = pd.DataFrame([['a', 'b'], ['c', 'd']],
index=['row 1', 'row 2'],
columns=['col 1', 'col 2'])
# 输出 json 字符串
df.to_json(orient='split')![]()
剪贴板读取
比如我去复制一下东方财富网的一个数据:
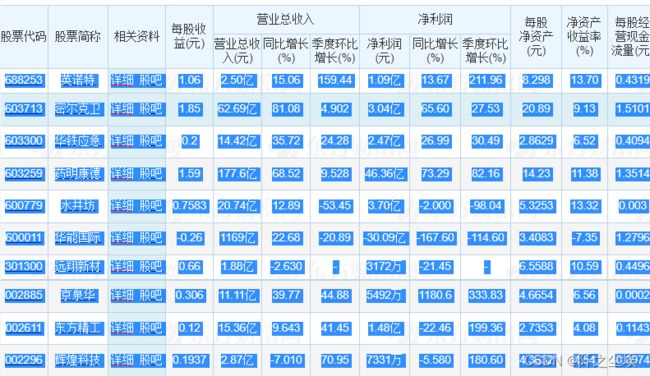
然后在Python输入
pd.read_clipboard(header=None)可以得到
很方便
剪贴板输出
df = pd.DataFrame({'A': [1, 2, 3],
'B': [4, 5, 6],
'C': ['p', 'q', 'r']},
index=['x', 'y', 'z'])
df.to_clipboard()这样就可以把df的东西到处复制去了
markdowm导出
print(df.to_markdown())
其他文件读取
数据分析还有spss文件,sas文件,stata文件等,都可以用pandas读取
pd.read_stata('file.dta')#读取stata文件
pd.read_spss('file.sav')#读取spss文件
pd.read_sas#读取sas
pd.read_sql#读取sql
#读取有固定列宽的数据
colspecs = [(0, 6), (8, 20), (21, 33), (34, 43)]
pd.read_fwf('demo.txt', colspecs=colspecs, header=None, index_col=0)