【Hadoop】RPC在client端的源码解析
最近在看《Hadoop 2.X HDFS源码剖析》这本书(其实看了挺久的,但是进度比较慢),要看懂hadoop源码真的是需要一定的代码和框架的基础,用到的东西还真是蛮多的,真的厉害,哎,我太菜了~
我们会用hadoop的api或者hadoop的命令来执行一些相应的操作,那么当我们执行了一个rename的方法的时候,实际上到底发生了什么呢?
一、我们从一段客户端的代码开始
代码非常的简单
创建了FileSystem,然后通过FileSystem调用rename,重名名hdfs上的文件名
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
fs.rename(new Path("path1"),new Path("path2"));
fs.close();
}
1、创建conf,生成对应FileSystem
通过外层的FileSystem.get方法,一路追踪,发现构造具体的FileSystem代码如下:
(1)、如下图第二个红框,是获得具体FileSystem实现类的Class类
(2)、第三个红框,是通过反射的机制,创建出该Class类的对象,并且初始化

那么如何获得具体的Class类呢?见下面的loadFileSystems方法


hadoop通过java提供的ServiceLoader类,初始化了FileSystem中的SERVICE_FILE_SYSTEMS属性
ServiceLoader详解:https://www.cnblogs.com/aspirant/p/10616704.html
当for循环跑完之后,已经将所有的FlieSystem的实现类加载到了SERVICE_FILE_SYSTEMS这个map中,key是schema,value是具体的class的类名
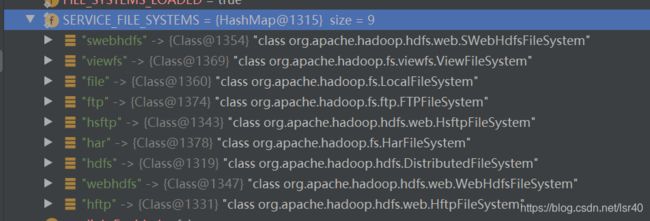
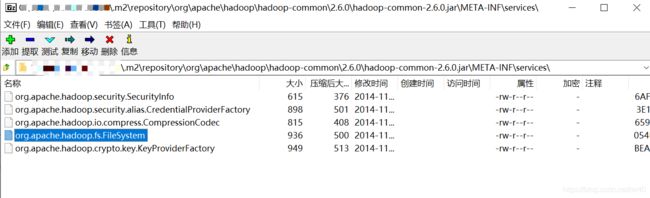
但是这里我有一个疑问,我翻了下源码,META-INF.services这个包下面的FileSystem也才只有4个实现类,不知道hadoop从哪里加载了另外5个,如果有知道的小伙伴烦请指点指点我~
org.apache.hadoop.fs.LocalFileSystem org.apache.hadoop.fs.viewfs.ViewFileSystem org.apache.hadoop.fs.ftp.FTPFileSystem org.apache.hadoop.fs.HarFileSystem
这样,我们就可以根据core-site里面fs.defaultFS得到schema(hdfs),来获得完整的org.apache.hadoop.hdfs.DistributedFileSystem的Class类,进而通过反射,创建出了fs具体的实现类的对象,所以代码中的rename方法,就要跳到DistributedFileSystem里,去看具体的实现了!
2、DistributedFileSystem的rename方法

我们看到这里调用的dfs其实是一个DFSClient,那么这个在哪里初始化的呢?
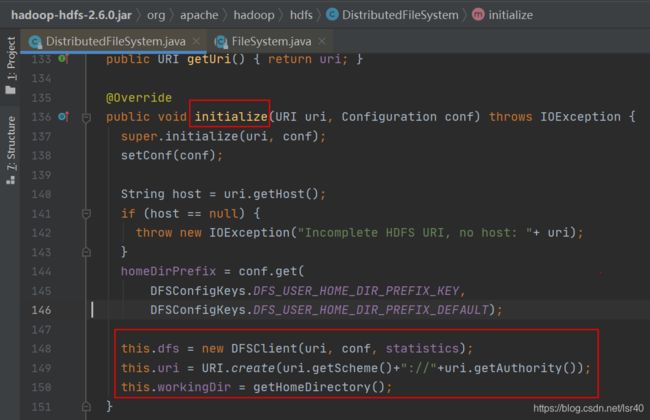
记得吗,这个initialize的方法,是在createFileSystem方法获得具体的FileSystem对象的时候,被调用了(可参见一-1-(2)的第一张图)
3、DFSClient的rename方法

我们发现DFSClient方法的rename方法,实际上是调用了namenode这个对象的方法,这个对象是啥,在哪里创建的呢(从这里开始,说起来就比较复杂了)
4、namenode对象如何生成之一
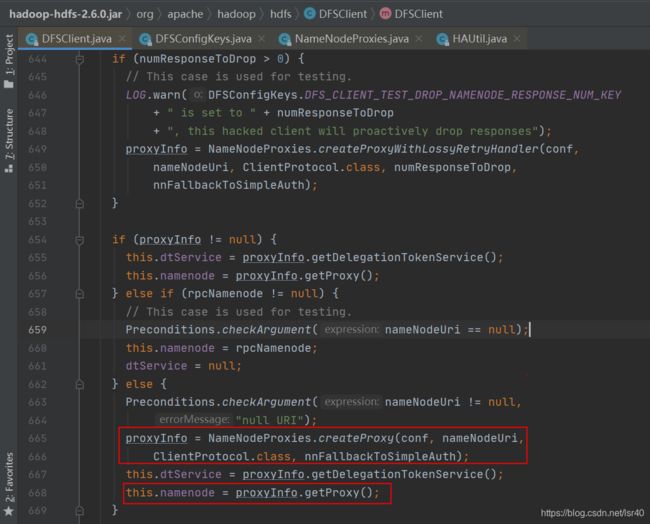
如下图,我们有2个东西要记住,一个是xface传了什么东西过来(ClientProtocol.class),要接着往下传
另一个是这个失败处理的proxy,因为HA的模式,把这个对象传进去了
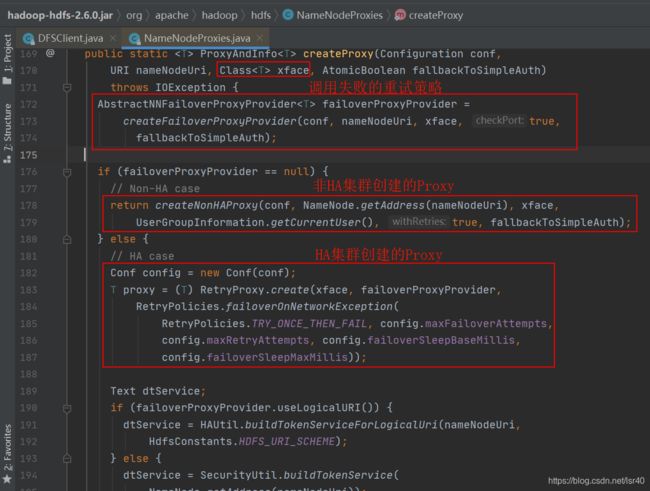
5、namenode对象如何生成之二和三
(1)、先看非HA模式
看到一堆if了吗,这个方法应该是在多个地方会被调用,然后DFSClient传入了ClientProtocol.class,就走了第一个方法

这个方法里的核心,就是设置RPC的引擎(ProtobufRpcEngine.class),然后创建出ClientNamenodeProtocolPB对象
大家有兴趣可以百度下,protobuf,是谷歌的一种高性能的数据序列化方式,Netty里也可以用这个,是业内RPC中比较常见和常用的技术
如下第一个红框的代码,设置了RPC的引擎到conf之中,后面的代码就可以直接通过ClientNamenodeProtocolPB这个,获得ProtobufRpcEngine引擎的完整类名
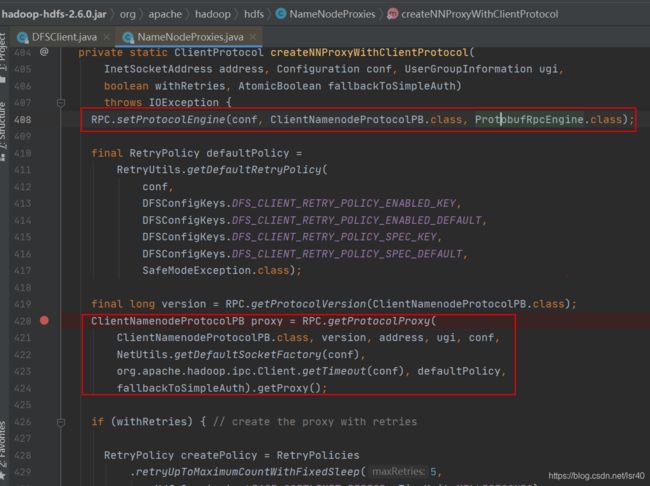
这里的return会创建一个Engine,并且调用该对象的getProxy的方法

如下图,我们先看看如何创建Engine引擎,看到这里你就发现,哦原来ProtobufRpcEngine对象,是反射的机制创建出来的!!

接着我们找到具体ProtobufRpcEngine的getProxy方法,原来是通过java的Proxy类来反射出ClientNamenodeProtocolPB对象
大家可以百度下Proxy.newProxyInstance方法,核心点在于Invoker!
大家可以参考如下文章:
java动态代理Proxy.newProxyInstance:https://blog.csdn.net/u012326462/article/details/81293186(徐海兴)
所以下一步我们要看看Invoker里的invoke方法的代码逻辑!
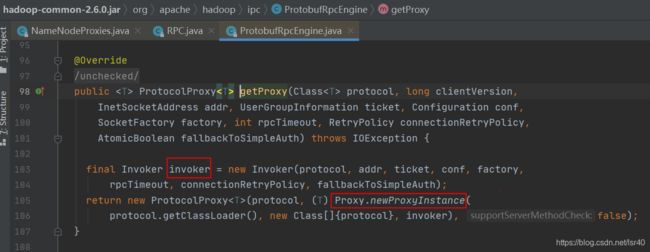
Invoker是ProtobufRpcEngine的私有的内部静态类

invoke方法比较长,我就不截图了,直接把代码贴上来
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws ServiceException {
long startTime = 0;
if (LOG.isDebugEnabled()) {
startTime = Time.now();
}
//判断传入的两个参数,实际上调用的rename是ClientNamenodeProtocolTranslatorPB的rename
//传入两个参数如下一个是null
// 另一个是将请求的参数从字符串转换为Protocolbuf的请求
// RenameRequestProto req = RenameRequestProto.newBuilder().setSrc(src).setDst(dst).build();
// rpcProxy.rename(null, req).getResult();
if (args.length != 2) { // RpcController + Message
throw new ServiceException("Too many parameters for request. Method: ["
+ method.getName() + "]" + ", Expected: 2, Actual: "
+ args.length);
}
if (args[1] == null) {
throw new ServiceException("null param while calling Method: ["
+ method.getName() + "]");
}
TraceScope traceScope = null;
// if Tracing is on then start a new span for this rpc.
// guard it in the if statement to make sure there isn't
// any extra string manipulation.
if (Trace.isTracing()) {
traceScope = Trace.startSpan(
method.getDeclaringClass().getCanonicalName() +
"." + method.getName());
}
//构造请求头域,标明在什么借口上调用什么方法
RequestHeaderProto rpcRequestHeader = constructRpcRequestHeader(method);
if (LOG.isTraceEnabled()) {
LOG.trace(Thread.currentThread().getId() + ": Call -> " +
remoteId + ": " + method.getName() +
" {" + TextFormat.shortDebugString((Message) args[1]) + "}");
}
//获取实际的请求参数,
Message theRequest = (Message) args[1];
final RpcResponseWrapper val;
try {
//真正将数据发送给远端服务!!!
val = (RpcResponseWrapper) client.call(RPC.RpcKind.RPC_PROTOCOL_BUFFER,
new RpcRequestWrapper(rpcRequestHeader, theRequest), remoteId,
fallbackToSimpleAuth);
} catch (Throwable e) {
if (LOG.isTraceEnabled()) {
LOG.trace(Thread.currentThread().getId() + ": Exception <- " +
remoteId + ": " + method.getName() +
" {" + e + "}");
}
if (Trace.isTracing()) {
traceScope.getSpan().addTimelineAnnotation(
"Call got exception: " + e.getMessage());
}
throw new ServiceException(e);
} finally {
if (traceScope != null) traceScope.close();
}
if (LOG.isDebugEnabled()) {
long callTime = Time.now() - startTime;
LOG.debug("Call: " + method.getName() + " took " + callTime + "ms");
}
Message prototype = null;
try {
//获得返回参数
prototype = getReturnProtoType(method);
} catch (Exception e) {
throw new ServiceException(e);
}
Message returnMessage;
try {
//序列化相应信息并返回
returnMessage = prototype.newBuilderForType()
.mergeFrom(val.theResponseRead).build();
if (LOG.isTraceEnabled()) {
LOG.trace(Thread.currentThread().getId() + ": Response <- " +
remoteId + ": " + method.getName() +
" {" + TextFormat.shortDebugString(returnMessage) + "}");
}
} catch (Throwable e) {
throw new ServiceException(e);
}
//返回结果
return returnMessage;
}
(2)、再看HA模式
看到RetryProxy的create方法传入了一个失败重试的适配器
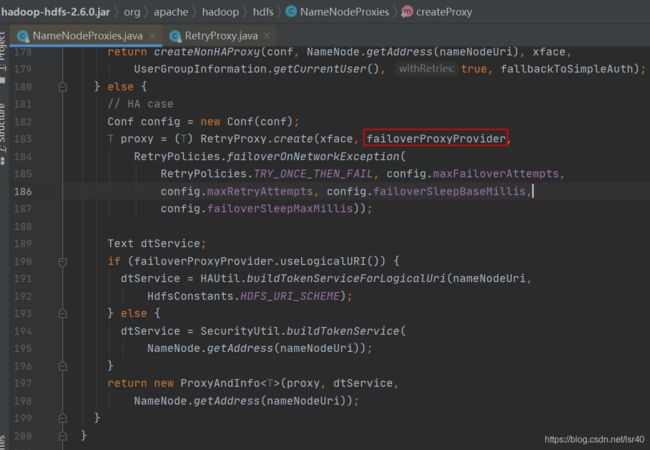
这不就跟刚才的一样吗,Proxy.newProxyInstance,所以我们要看RetryInvocationHandler里的invoke方法的和非HA模式的invoke方法的区别

@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
RetryPolicy policy = methodNameToPolicyMap.get(method.getName());
if (policy == null) {
policy = defaultPolicy;
}
// The number of times this method invocation has been failed over.
int invocationFailoverCount = 0;
final boolean isRpc = isRpcInvocation(currentProxy.proxy);
final int callId = isRpc? Client.nextCallId(): RpcConstants.INVALID_CALL_ID;
int retries = 0;
while (true) {
// The number of times this invocation handler has ever been failed over,
// before this method invocation attempt. Used to prevent concurrent
// failed method invocations from triggering multiple failover attempts.
long invocationAttemptFailoverCount;
synchronized (proxyProvider) {
invocationAttemptFailoverCount = proxyProviderFailoverCount;
}
if (isRpc) {
Client.setCallIdAndRetryCount(callId, retries);
}
try {
//可以拉到下面看下这个方法的实现,也是反射调用方法
//如果调用成功,那么方法就结束了,如果失败,就要走下面的catch来进行重试
Object ret = invokeMethod(method, args);
hasMadeASuccessfulCall = true;
return ret;
} catch (Exception e) {
//通过Idempotent注解判断,该方法是否幂等(多次调用没有影响)
boolean isIdempotentOrAtMostOnce = proxyProvider.getInterface()
.getMethod(method.getName(), method.getParameterTypes())
.isAnnotationPresent(Idempotent.class);
if (!isIdempotentOrAtMostOnce) {
isIdempotentOrAtMostOnce = proxyProvider.getInterface()
.getMethod(method.getName(), method.getParameterTypes())
.isAnnotationPresent(AtMostOnce.class);
}
//通过shouldRetry来分析处理如上的异常,这里的policy,默认是FailoverOnNetworkExceptionRetry
//shouldRetry方法里面的逻辑不复杂大家可以自行看下
//大概就是:
// 1、失败次数超过最大次数,返回FAIL表示失败
// 2、如果是连接,host解析不了等类型的异常,就返回FAILOVER_AND_RETRY,表示要执行performFailover方法,更新active的namenode引用
// 3、如果是端口或者IO异常,判断是否幂等,如果非幂等方法就直接失败FAIL,否则就返回FAILOVER_AND_RETRY
RetryPolicy.RetryAction action = policy.shouldRetry(e, retries++,
invocationFailoverCount, isIdempotentOrAtMostOnce);
//以下的代码就是来处理action返回的具体enum
//第一种情况:返回FAIL直接失败
if (action.action == RetryPolicy.RetryAction.RetryDecision.FAIL) {
if (action.reason != null) {
LOG.warn("Exception while invoking " + currentProxy.proxy.getClass()
+ "." + method.getName() + " over " + currentProxy.proxyInfo
+ ". Not retrying because " + action.reason, e);
}
throw e;
} else { // retry or failover
// avoid logging the failover if this is the first call on this
// proxy object, and we successfully achieve the failover without
// any flip-flopping
//其他两种情况:需要重试或者刷新activenamenode的引用
boolean worthLogging =
!(invocationFailoverCount == 0 && !hasMadeASuccessfulCall);
worthLogging |= LOG.isDebugEnabled();
if (action.action == RetryPolicy.RetryAction.RetryDecision.FAILOVER_AND_RETRY &&
worthLogging) {
String msg = "Exception while invoking " + method.getName()
+ " of class " + currentProxy.proxy.getClass().getSimpleName()
+ " over " + currentProxy.proxyInfo;
if (invocationFailoverCount > 0) {
msg += " after " + invocationFailoverCount + " fail over attempts";
}
msg += ". Trying to fail over " + formatSleepMessage(action.delayMillis);
LOG.info(msg, e);
} else {
if(LOG.isDebugEnabled()) {
LOG.debug("Exception while invoking " + method.getName()
+ " of class " + currentProxy.proxy.getClass().getSimpleName()
+ " over " + currentProxy.proxyInfo + ". Retrying "
+ formatSleepMessage(action.delayMillis), e);
}
}
if (action.delayMillis > 0) {
Thread.sleep(action.delayMillis);
}
if (action.action == RetryPolicy.RetryAction.RetryDecision.FAILOVER_AND_RETRY) {
// Make sure that concurrent failed method invocations only cause a
// single actual fail over.
synchronized (proxyProvider) {
if (invocationAttemptFailoverCount == proxyProviderFailoverCount) {
//这个就是刷新引用的方法
proxyProvider.performFailover(currentProxy.proxy);
proxyProviderFailoverCount++;
} else {
LOG.warn("A failover has occurred since the start of this method"
+ " invocation attempt.");
}
currentProxy = proxyProvider.getProxy();
}
invocationFailoverCount++;
}
}
}
}
}
//通过反射调用method对象的方法
protected Object invokeMethod(Method method, Object[] args) throws Throwable {
try {
if (!method.isAccessible()) {
method.setAccessible(true);
}
//当主备发生切换,currentProxy.proxy这个东西就会变成新的active的namenode地址
return method.invoke(currentProxy.proxy, args);
} catch (InvocationTargetException e) {
throw e.getCause();
}
}@Override
public RetryPolicy.RetryAction shouldRetry(Exception e, int retries,
int failovers, boolean isIdempotentOrAtMostOnce) throws Exception {
if (failovers >= maxFailovers) {
return new RetryPolicy.RetryAction(RetryPolicy.RetryAction.RetryDecision.FAIL, 0,
"failovers (" + failovers + ") exceeded maximum allowed ("
+ maxFailovers + ")");
}
if (retries - failovers > maxRetries) {
return new RetryPolicy.RetryAction(RetryPolicy.RetryAction.RetryDecision.FAIL, 0, "retries ("
+ retries + ") exceeded maximum allowed (" + maxRetries + ")");
}
if (e instanceof ConnectException ||
e instanceof NoRouteToHostException ||
e instanceof UnknownHostException ||
e instanceof StandbyException ||
e instanceof ConnectTimeoutException ||
isWrappedStandbyException(e)) {
return new RetryPolicy.RetryAction(RetryPolicy.RetryAction.RetryDecision.FAILOVER_AND_RETRY,
getFailoverOrRetrySleepTime(failovers));
} else if (e instanceof RetriableException
|| getWrappedRetriableException(e) != null) {
// RetriableException or RetriableException wrapped
return new RetryPolicy.RetryAction(RetryPolicy.RetryAction.RetryDecision.RETRY,
getFailoverOrRetrySleepTime(retries));
} else if (e instanceof SocketException
|| (e instanceof IOException && !(e instanceof RemoteException))) {
if (isIdempotentOrAtMostOnce) {
return RetryPolicy.RetryAction.FAILOVER_AND_RETRY;
} else {
return new RetryPolicy.RetryAction(RetryPolicy.RetryAction.RetryDecision.FAIL, 0,
"the invoked method is not idempotent, and unable to determine "
+ "whether it was invoked");
}
} else {
return fallbackPolicy.shouldRetry(e, retries, failovers,
isIdempotentOrAtMostOnce);
}
}
}
二、总结
所以我们看出了一下几点东西,我来总结下
1、hadoop的这部分代码中,还是比较喜欢用反射的
2、用反射的目的,其实一来是可以直接通过类名加载出对象,二来是可以做invoke,这样就可以在使用者无感知的情况下,将某个方法的参数,通过某个具体的引擎序列化,然后发送出去,接着接受到的数据也是再反序列化成用户能看懂的参数
3、代码中还是用到了不少java提供的一些很方便的类,例如ServiceLoader,因此看hadoop的代码还是能够学到很多东西的,特别是在不使用spring那一套框架的情况下,去完成一些在spring中常见的操作(spring提供了很方便的aop,类的装载,其实也是通过反射实现的)
4、希望大家有空可以自己去跟踪下这部分代码,看完之后相信你对hadoop或者对于rpc,对于protocolbuf,都会有更进一步的了解
哎,又臭又长的文章,但是完整的写出来,真的是很爽,写的很辛苦,也希望大家能够静下心来帮我看看有没有哪里写的有问题的地方,欢迎批评指正
其实很早之前就一直想花时间认真看看hadoop的源码~感谢坚持到现在的自己!!22:40分了,下班回家~
特别感谢:
Hadoop RPC调用实例分析:https://blog.csdn.net/yexiguafu/article/details/107378511(作者:叹了口丶气)
Hadoop 2.X HDFS源码剖析(作者:徐鹏)