HDFS 短路读的实现(全网最全面深入讲解)
文章目录
- 前言
- 1. 知识准备
-
- 1.1 关于域套接字(Domain Socket)
-
- 什么是Domain Socket
- Domain Socket 通信在ShortCircuit Read中做了什么
- DomainSocket 在Hadoop上的基本实现
- 1.2 关于内存映射(MMAP)
-
- 什么是MMAP
- MMAP在ShortCircuit中的作用是什么
- 1.3 关于共享内存(Shared Memory)
-
- 什么是共享内存
- 共享内存在Hadoop短路读中的使用
- 共享内存和mmap的区别和联系
- 2. ShortCircuit Read(短路读)的基本流程
-
- 1.1 客户端的读取策略选择 -- 怎样才会选择短路读
- 1.2 DataNode启动时监听短路读DomainSocket
- 1.3 客户端申请共享内存并在共享内存中分配Slot
-
- 1.3.1 与`DataNode` 建立Socket 通信
- 1.3.2 客户端尝试在Segment中分配Slot,Slot不够用则申请新的segment
- 1.3.3 `DataNode`通过mmap创建共享内存
- 1.3.4 DataNode将共享内存的文件描述符返回给客户端
- 1.3.5 客户端打开文件,写入Slot数据
- 1.4 读取Replica
-
- 1.4.1 向DataNode请求replica的文件描述符
- 1.4.2 打开该replica
- 3. 结束
- 4.参考文章
前言
HDFS短路读是性能优化的一个重要特性,它利用操作系统的内存映射mmap、Domain Socket和共享内存,避开传统的基于TCP的数据通信,极大提升了数据读取效率。
整个短路读的过程完全放弃传统的基于TCP/IP的通信方式,基于Domain Socket进行通信,基于mmap和内存共享进行数据同步和块的高效率读取,整个读取过程涉及到了操作系统(Domain Socket、mmap等)、Java NIO(ByteBuffer, Channel)等知识,同时也和HDFS的缓存系统交叉在一起,因此涉及到的东西很多,本文篇幅较长。
短路读的数据读取方式由于其在本地读取的高效率,很多分布式存储系统都会用到,而且我发现很多面试官也非常喜欢问HDFS短路读的实现原理,因此对短路读的深入理解很有价值。
我看了一些介绍短路读的文章,发现大多数文章都只在上层介绍其基本流程,只要具体到实现和一些概念的深入理解(比如到底mmap是什么?到底Domain Socket通信是什么?Domain Socket跟mmap是一回事吗?)就泛泛而谈。因此,本文以较长篇幅,力求在上层原理和底层实现都能让读者彻底理解短路读。
在第一章,我们先抛开Hadoop的实现本身,介绍短路读中用到的一些操作系统的概念和特性,这是后续理解短路读的基础,包括域套接字读,mmap和共享内存。
在第二章, 我们开始介绍短路读的具体流程,连接的建立,元数据的同步,以及最后对块的读取。
在第三章,列举了一些跟本文相关的有价值的网络文章作为参考。
1. 知识准备
1.1 关于域套接字(Domain Socket)
什么是Domain Socket
首先注意,Domain Socket通信并不是Hadoop中的概念,而是Unix操作系统提供的功能。Hadoop通过自己的libhadoop可以使用Unix Domain Socket接口,从而进行Domain Socket通信。
我们都知道,Socket 原本是为网络通信而设计的,但后来在 Socket 的框架上发展出一种 IPC 机制, 就是 Unix Domain Socket, 它还有另一个名字叫 IPC(inter-process communication, 进程间通信)。
相比于基于TPC/IP协议栈进行的网络通信,使用 Unix Domain Socket 的好处显而易见:不需要经过网络协议栈, 不需要打包拆包、计算校验和、维护序号和应答等,只是将应用层数据从一个进程拷贝到另一个进程。这是因为,进程间通信机制本质上是可靠的通讯,而网络协议是为不可靠的通讯设计的。
但是既然是通信,就涉及到寻址,即我们总得知道对方(Hadoop中将通信双方叫做一个Peer)的URI把?TPC/IP的URI就是URL或者IP地址,而仅限于本机的进程间通信依靠什么去确定一个URI呢?是文件,即,通信双方都绑定到所在机器(别忘了大家在同一台机器上)的某一个文件,实现进程之间的全双工通信。
除了通信方式意外,Domain Socket的一个重要特性是,通信双方可以直接传递文件描述符。比如,服务器端打开了一个replica文件,将打开文件的描述符通过Domain Socket传递给客户端,客户端拿着这个文件描述符就可以读取服务器端打开的这个文件。文件描述符的传递将整个文件的读写权限掌控在DataNode 这里,但是数据的读写又不经过DataNode,这是ShortCircuit读写与普通TCP/IP通信的最重要的不同。
再重复以便在ShortCircuit的场景下,Domain Socket 通信的双方为用户的DFSClient和同处于一台机器上的DataNode。
Domain Socket 通信在ShortCircuit Read中做了什么
答案:进行replica读取前的简单通信和信息同步。
我们知道,ShortCircuit Read的目的就是避免使用TCP/IP,让整个块读取过程不建立TCP/IP,由于不需要网络协议栈、计算校验和、序号维护和应答等,因此减少DataNode的负载、网络开销,提高通信和数据传输效率。要完成整个ShortCircuit Read,在进行块传输以前和过程中,客户端和DataNode前后肯定还需要进行一些必要的信息沟通和同步,这些元信息的沟通和同步使用的是Linux Domain Socket,避免建立TCP/IP连接,这些必要的信息沟通和同步包括但不仅仅包括:
- 客户端告诉
DataNode, 我需要读ID为blk_123123123的文件,我的姓名(client name)是。。。。 DataNode告诉客户端,我刚刚创建好了一块儿内存区域,我们用这一块儿内存区域来放每一个你要读取的replica的一些元数据信息,比如,这个Block需要不需要做crc校验等等,我把这块内存区域的地址给你。DataNode准备好了对应的replica文件信息(就是文件描述符索引fd),通过Domain Socket发送给客户端,客户端根据这个文件描述符,就可以绕过DataNode,直接读取对应的replica文件了。
DomainSocket 在Hadoop上的基本实现
这里,我们先抛开Short Circuit读的实现,先彻底理解Domain Socket在Java这一层的实现。
- 确定
Domain Socket通信的文件路径
Domain Socket通信的双方通过一个本地文件作为地址空间,在通信过程中双方会基于这个文件打开相同的socket进行通信。这HDFS中,通过以下配置项配置这个文件路径:
<property>
<name>dfs.domain.socket.pathname>
<value>/var/lib/hadoop-hdfs/dn._PORTvalue>
property>
- 服务端在
Domain Socket上绑定(bind())和监听(listen())
这个绑定和监听的概念与TCP/IP的通信的服务端操作类似,只不过底层实现是基于Domain Socket。
在Hadoop上,跟Domain Socket通信相关的操作都封装在一个类似工具类的叫做DomainSocket的类中,供DomainSocket的客户端和服务器端共同使用。它是java层对操作系统层的Domain Socket的封装,因此DomainSocket这个工具类会负责帮我们1)类初始化的时候加载libhadoop 2)提供了针对DomainSocket的一些方法,比如服务器端的绑定监听,客户端的连接,3) 根据打开的Domain Socket创建对应的输入输出流,底层就通过调用native方法来调用libhadoop中的library,然后libhadoop会调用操作系统的Domain Socket的相关API实现Domain Socket 通信。
DataNode启动的时候,会创建DataXceiverServer,用来作为服务器,用于接收/发送数据块。 创建它是为了侦听来自客户端或其他 DataNode 的请求。它封装了一个PeerServer的实现。目前,传统的PeerServer的实现是TcpPeerServer,用来接收TCP/IP的通信请求,后来有了ShortCircuit读,就有了基于Domain Socket的实现DomainPeerServer。
DataXceiverServer运行起来以后,会通过封装的PeerServer实现开始监听请求,当监听到请求到来,就通过维护的线程池来运行对应的请求处理。
在DataNode启动的时候,创建DataXceiverServer和DomainPeerServer,就是基于Domain Socket的文件路径,进行绑定(bind())和监听。
// -------------------- DomainPeer.java --------------------
@InterfaceAudience.Private
public class DomainPeerServer implements PeerServer {
static final Logger LOG = LoggerFactory.getLogger(DomainPeerServer.class);
private final DomainSocket sock;
public DomainPeerServer(String path, int port)
throws IOException {
this(DomainSocket.bindAndListen(DomainSocket.getEffectivePath(path, port)));
}
// -------------------- DomainSocket.java --------------------
/**
* Create a new DomainSocket listening on the given path.
*
* @param path The path to bind and listen on.
* @return The new DomainSocket.
*/
public static DomainSocket bindAndListen(String path) throws IOException {
int fd = bind0(path); // 绑定到我们配置的DomainSocket 路径上
return new DomainSocket(path, fd);
}
// 绑定到对应的Socket Path上去
private static native int bind0(String path) throws IOException;
完成了绑定(bind())和被动监听(listen()),会返回一个int类型的文件描述符表的索引值,这个索引值就如同一个Linux操作系统的文件描述符表的索引,代表了打开这个文件的文件描述符。
DataNode启动的时候完成了对指定的Socket Path的绑定和被动监听,那么就开始进入阻塞等待请求的监听(accept())阶段(流程跟TCP/IP的Client-Server连接方式是一样的),一旦有客户端请求过来,就跟客户端建立通信:
// -------------------- DataXceiverServer.java --------------------
@Override
public void run() {
while (datanode.shouldRun && !datanode.shutdownForUpgrade) {
try {
peer = peerServer.accept();// 阻塞等待这个socket上的连接请求,可能来自本机上的一个或者多个客户端
// 阻塞结束,说明接受了连接请求
.......
// 开始使用独立线程处理请求
new Daemon(datanode.threadGroup,
DataXceiver.create(peer, datanode, this))
.start();
// -------------------- DomainSocket.java --------------------
/**
* Accept a new UNIX domain connection.
*
* This method can only be used on sockets that were bound with bind().
*
* @return The new connection.
* @throws IOException If there was an I/O error performing the accept--
* such as the socket being closed from under us.
* Particularly when the accept is timed out, it throws
* SocketTimeoutException.
*/
public DomainSocket accept() throws IOException {
refCount.reference();
boolean exc = true;
try {
// 基于刚刚已经完成绑定和监听的fd,开始进入accept状态,接收客户端的连接请求
DomainSocket ret = new DomainSocket(path, accept0(fd));
exc = false;
return ret;
} finally {
unreference(exc);
}
// 基于刚刚已经完成绑定和监听的fd,开始进入accept状态,接收客户端的连接请求
private static native int accept0(int fd) throws IOException;
当accept()成功,就会基于accept()调用返回的文件描述符(一个整数,这个整数此时代表了和当前客户端的一对一连接),创建跟当前客户端对应的java.io.InputStream(实现类为DomainSocket.DomainInputStream)和java.io.OutputStream(DomainSocket.DomainOutputStream)。有了基于Domain Socket的InputStream和OutputStream的具体实现,那么后续的发送和接收数据就只需要基于构建的InputStream和OutputStream进行了,不需要关心这个InputStream和OutputStream背后是具体实现TCP/IP还是DomainSocket了。
基于Domain Socket创建的InputStream和OutputStream进行数据通信的代码如下:
// -------------------- DomainSocket.DomainInputStream --------------------
/**
* Input stream for UNIX domain sockets.
*/
public class DomainInputStream extends InputStream {
.....
@Override
public int read() throws IOException {
....
try {
byte b[] = new byte[1];
// 调用native方法,基于已经建立的DomainSocket连接,将fd(文件描述符对应的打开的文件)对应的socket中的信息读入到byte数组中,实现通信的接收操作
int ret = DomainSocket.readArray0(DomainSocket.this.fd, b, 0, 1);
......
}
// -------------------- DomainSocket.DomainOutputStream --------------------
/**
* Output stream for UNIX domain sockets.
*/
@InterfaceAudience.LimitedPrivate("HDFS")
public class DomainOutputStream extends OutputStream {
....
@Override
public void write(int val) throws IOException {
......
byte b[] = new byte[1];
b[0] = (byte)val;
// 基于已经建立的DomainSocket连接,将b中的数据写入到fd(文件描述符对应的打开的文件)对应的socket中,实现通信的发送操作
DomainSocket.writeArray0(DomainSocket.this.fd, b, 0, 1);
exc = false;
} ....
}
- 客户端基于DomainSocket连接建立
传统的TCP/IP的连接建立,是通过连接到服务器端的IP地址和端口实现通信。Domain Socket的客户端的连接,是通过连接到上面配置的文件路径来进行通信。
// -------------------- BlockReaderFactory.java --------------------
public DomainSocket createSocket(PathInfo info, int socketTimeout) {
....
try {
// 通过dfs.domain.socket.path来建立连接
sock = DomainSocket.connect(info.getPath());
sock.setAttribute(DomainSocket.RECEIVE_TIMEOUT, socketTimeout);
......
// -------------------- DomainSocket.java --------------------
/**
* Create a new DomainSocket connected to the given path.
*
* @param path The path to connect to.
* @throws IOException If there was an I/O error performing the connect.
*
* @return The new DomainSocket.
*/
public static DomainSocket connect(String path) throws IOException {
int fd = connect0(path);
return new DomainSocket(path, fd);
}
// 建立DomainSocket 连接的native方法,这个native方法的具体调用定义在libhadoop的本地代码库中
private static native int connect0(String path) throws IOException;
可以看到,在客户端, 其实就是通过提供的一个本地文件路径,同Server端建立连接。连接建立以后,会返回一个int类型的文件描述符表的索引值,刚才提到过,这个索引值就如同一个Linux操作系统的文件描述符表的索引,代表了打开这个文件的文件描述符。
为了向DataNode发送数据,Client把刚刚基于DomainSocket构建好的OutputStream进行适当封装,基于这个封装好的OutputStream把数据发送出去。为了读取DataNode返回的数据,Client会基于DomainSocket 构建好的InputStream,读取本地的DataNode从DomainSocket发送过来的数据:
----------------------- DfsClientShmManager.java --------------------------
// 通过OutputStream来接收数据
// peer.getOutputStream()就是我们刚刚基于DomainSocket构建好的一个OutputStream的实现
final DataOutputStream out =
new DataOutputStream(
new BufferedOutputStream(peer.getOutputStream())); // 基于DomainSocket与本地的DataNode进行通信
new Sender(out).requestShortCircuitShm(clientName);
// 通过InputStream来接收数据
ShortCircuitShmResponseProto resp =
ShortCircuitShmResponseProto.parseFrom(
PBHelperClient.vintPrefixed(peer.getInputStream())); // 接收本地DataNode基于DomainSocket发送过来的细腻
1.2 关于内存映射(MMAP)
跟Domain Socket一样,内存映射 (mmap) 并不是Hadoop中的概念,而是Unix操作系统提供的功能。Hadoop通过自己的libhadoop可以使用mmap相关的接口调用,从而使用操作系统的mmap功能。
什么是MMAP
跟Domain Socket一样,内存映射 (mmap()) 也是操作系统提供的一项功能,它将辅助存储上的文件内容映射到程序的内存地址空间。 然后,程序通过指针访问页面,就好像文件完全驻留在内存中一样。 仅当程序引用页面时,操作系统才会透明地加载页面,并在内存填满时自动逐出页面。
这里关键是操作系统提供的 mmap()/munmap()函数,mmap()可以把磁盘文件的一部分直接映射到内存,这样文件中的位置直接就有对应的地址,对文件的读写可以直接用指针来做而不需要read/write函数。 munmap()就是解除映射。示意图如下:
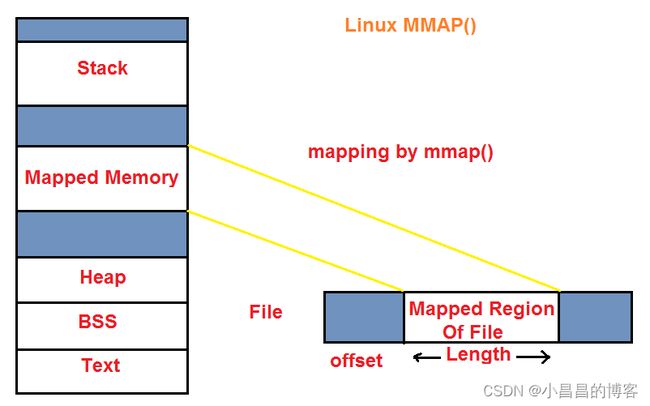 图-1 : mmap示意图
图-1 : mmap示意图
我们先来看操作系统应用程序读取普通常规文件的基本流程: 1、进程发起读文件请求。 2、内核通过查找进程文件符表,定位到内核已打开文件集上的文件信息,从而找到此文件的inode。 3、根据inode查找要请求的文件页是否已经缓存在页缓存中。如果存在,则直接返回这片文件页的内容。 4、如果不存在,则通过inode定位到文件磁盘地址,将数据从磁盘复制到页缓存(内核态)。之后再次发起读页面过程,进而将页缓存中的数据发给用户进程(用户态)。
总结来说,常规文件操作为了提高读写效率和保护磁盘,使用了页缓存机制。这样造成读文件时需要先将文件页从磁盘拷贝到页缓存中,由于页缓存处在内核空间,不能被用户进程直接寻址,所以还需要将页缓存中数据页再次拷贝到内存对应的用户空间中。这样,通过了两次数据拷贝,才能完成文件读取。写操作也是一样,待写入的buffer在内核空间不能直接访问,必须要先拷贝至内核空间,再写回磁盘中(延迟写回),也是需要两次数据拷贝。
相比之下,而使用mmap()操作文件中,创建新的虚拟内存区域,以及建立文件磁盘地址和虚拟内存区域映射这两步,没有任何文件拷贝操作。而之后访问数据时发现内存中并无数据而发起的缺页异常过程,可以通过已经建立好的映射关系,只使用一次数据拷贝,就从磁盘中将数据传入内存的用户空间中,供进程使用。即少了一次数据拷贝,因此效率比常规文件读取要高。因此,mmap()一般具有以下优点:
- 相比于普通文件读写,减少了数据拷贝次数,用一次内存读写取代了平常的I/O读写方式,读写效率更高
- 减少了复杂的用户态和内核台的切换
- 有助于实现高效的数据传输,一定程度上缓解了内存不足的问题
MMAP在ShortCircuit中的作用是什么
基于上文介绍的mmap()的文件读取方式,在短路读的场景中,主要有两个地方用到了短路读:
- 通过短路读直接读取块文件,而不再使用传统读写方式。显然,如上文所述,这种使用短路读方式更高效。
- 通过mmap的方式实现下文要讲的共享内存。即,客户端和NodeNode同时mmap到一个文件,由于mmap会在内存中建立文件映射,因此两个进程操作这个文件,就相当于在同时操作同一内存区域,从而实现内存共享。
1.3 关于共享内存(Shared Memory)
什么是共享内存
共享内存是进程间通信的方法,即在同时运行的程序之间交换数据的方法。一个进程将在RAM中创建一个其他进程可以访问的区域。由于两个进程可以像访问自身内存一样访问共享内存区域,因此是一种非常快速的通信方式。但是它的扩展性较差,例如通信必须在同一台机器上运行。而且必须要避免如果共享内存的进程在不同的CPU上运行,并且底层架构不是缓存一致的。
传统的不共享内存的文件读取方式和共享内存的文件读取如下面两张图所示:
不共享内存的读取方式如下图2-1:
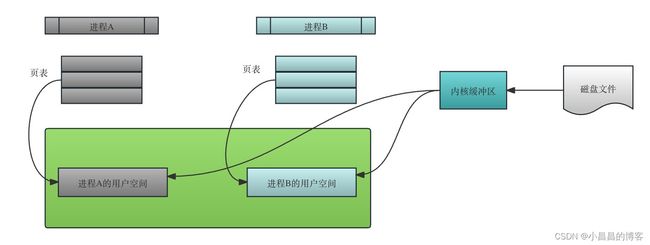
共享内存的读取方式如下图2-2:

共享内存在Hadoop短路读中的使用
在Hadoop中,共享内存主要用在两个地方:
- 存放元数据信息,下文会讲到,主要是客户端和
DataNode进行replica相关的元数据信息的共享。 - 通过共享内存的方式读取replica。下文会详细介绍,通过共享内存的方式,那些已经被
DataNode的缓存系统缓存到内存中的replica,客户端可以直接使用了,无需再从磁盘读取replica。
共享内存和mmap的区别和联系
上面说过,共享内存是进程间通信的一种方式,允许两个或多个进程共享一给定的内存区域,因此数据不需要在内存中或者从内存到磁盘的重复拷贝,所以是很快的一种进程间通信机制。共享内存可以通过systemV共享内存机制实现(本文不做介绍),也可以通过mmap()映射普通文件 (hadoop采用的共享内存方式)机制实现。
但是,Hadoop中的共享内存是基于mmap实现的:
我们在上文中介绍了DataNode在建立共享内存的时候,会先为该客户端创建一个本地磁盘文件,然后通过mmap()的方式打开文件,随后把打开文件的FileInputStream发送给客户端,客户端再以同样的方式通过mmap()打开文件,这样,客户端和DataNode进程都对同一文件以R/W的方式进行mmap(),因此它们其实在操作该文件在内存中的同一块区域,因此实现了共享内存。
2. ShortCircuit Read(短路读)的基本流程
我们都知道,客户端在从一个DataNode读取block的时候,还有一段跟NameNode的沟通过程,实现从文件到replica、以及replca的定位的过程。这个过程不是本文讨论的范围。本文不介绍前期跟NameNode的交互过程,而是直接假设客户端已经从NameNode获取了Block的全部信息(block id, DataNode地址等),开始和DataNode建立连接,读取块数据。
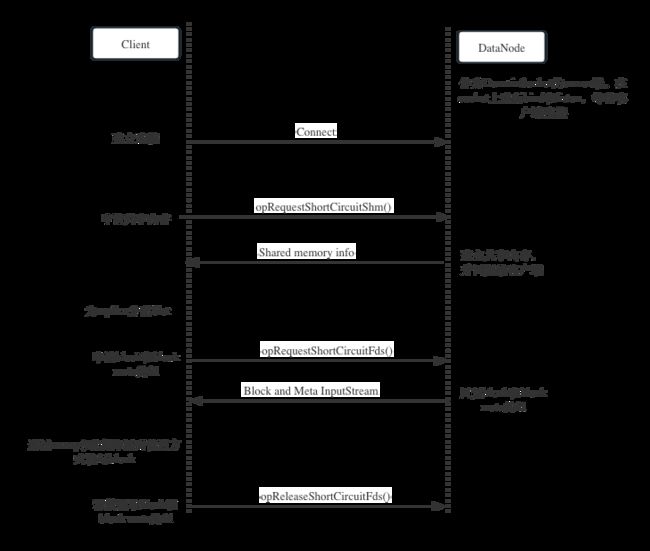
短路读的整个流程简化起来如图-3所示。
- 建立Socket连接:客户端和
DataNode先通过Domain Socket建立通信。但是这种通信仅仅用于少量API的调用,replica的读取流不会使用Domain Socket - 建立和协商共享内存区域:客户端通过Domain Socket向
DataNode申请共享内存,DataNode创建共享内存,Client在共享内存中创建Slot。注意,这段共享内存和其中的Slot是存放replica的元数据信息,不存储replica数据本身。 - 申请块文件描述符: 客户端通过
Domain Socket向DataNode申请replica的输入流,DataNode将replica的输入流 - 读取块文件:客户端将输入流转换为
mmap()的读取方式,或者直接通过传统方式读取replica
在短路读完成以后,整个内存的数据结构如图-4所示。客户端和DataNode的共享内存用来存放Slot,每个 Slot保存了一个replica的元数据信息(元数据信息的具体内容下文介绍)。
这里必须区分JVM中的Slot和共享内存的Slot。客户端和
DataNode的JVM中的Slot是Java对象,对象中放的是共享内存中的Slot的地址,即JVM中的Slot对象是共享内存中的Slot的引用,它指向了共享内存的Slot。共享内存中的Slot的大小为64B,一个Segment大小为8KB,因此一个共享Segment可以存放128个Slot,对应128个replica。

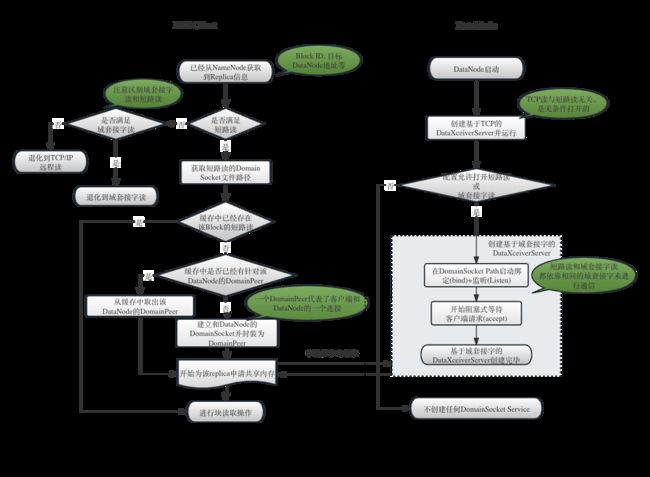
图-5展示了客户端和DataNode在进行块读取之前建立短路读和通过域套接字进行通信的基本过程。主要做了以下几件事:
- 客户端是否选择短路读:对于每一次读取,都会优先考虑短路读,短路读无法实现则进行域套接字读,如果还是无法实现,则进行传统的
TCP/IP读。 - 服务器端启动短路读的监听服务:
DataNode启动的时候,如果配置为需要进行短路读或域套接字读,则会为之启动一个独立的DataXceiverServer,专门负责短路读和域套接字读的连接和通信操作。 - 客户端通过
Domain Socket和服务器端DataNode建立Domain Socket连接 - 基于
Domain Socket连接建立共享内存(Shared Memory),用来存放后来的块的元数据信息
当上图的流程都成功走完,才开始进行块的读取。我们在下文会详细介绍。
1.1 客户端的读取策略选择 – 怎样才会选择短路读
目前,客户端的三种读取策略如下(选取的优先级从高到低):
- 短路读(
Short Circuit Read, 优先级最高)
通过域套接字Domain Socket与DataNode进行前期通信,然后通过Linuxmmap()和共享内存,绕开DataNode进行块的读取。这是本文详细讨论的内容。 - 域套接字读(
Domain Socket Read)
通过域套接字与DataNode通信,包括信息沟通和replica的读取。DataNode全程参与replica读取,replica的读取流会经过DataNode。 - 网络读(
TCP Read,优先级最低)
通过TCP/IP协议与DataNode通信,包括信息沟通和replica的读取。DataNode全程参与replica读取,replica的读取流会经过DataNode。
选取策略为:
- 如果
dfs.client.read.shortcircuit=true,并且当前这个block的条件允许短路读(这个block不是under construction的状态), 那么会尝试建立短路读连接。显然,在建立短路读连接和进行读block以前的准备工作有任何的失败,都不会进行短路读。 - 短路读构建失败,如果客户端配置
dfs.client.domain.socket.data.traffic为true,那么会退化到尝试使用Domain Socket读。显然,在建立域套接字读的前期准备过程中发生任何失败,都不会进行域套接字读。 - 以上尝试都失败,退化到传统
TCP/IP网络读
Domain Socket读(域套接字读)和Short Circuit读(短路读)的区别和联系
域套接字读和短路读,都使用套做系统的域套接字(DomainSocket)和DataNode通信,这意味着两种读方式都只能和同一机器的DataNode进行通信。 但是,从Hadoop分类来讲,域套接字读却和TCP/IP的读划分在了一起,被认为是Remote Read,而只有ShortCircuit Read才被认为是 local read, 这是因为:
域套接字读和TCP/IP的唯一区别只是Socket建立的方式不同,前者和DataNode的连接封装在DomainPeer中,后者和DataNode的通信封装在BasicInetPeer/NioInetPeer中,一旦Socket通信建立,那么域套接字读读和TCP/IP读的逻辑完全一致,都是直接和DataNode进行通信,都不使用mmap、共享内存等特性,因此它们都被hadoop划分为远程读。而短路读的流程则完全不同,虽然也会通过Domain Socket的方式和本地DataNode建立连接,但是后续的读块流程则完全发生了不同,不在经过DataNode,使用了mmap和共享内存等特性,这个我们会在后面的介绍中看到。由于域套接字读和短路读都是基于Unix Domain Socket建立通信,因此域套接字读和短路读在DataNode这一端都被封装在同一个DataXceiverServer中,而TCP/IP读由于使用的是网络通信,因此其单独封装在另外一个DataXceiverServer中。
1.2 DataNode启动时监听短路读DomainSocket
DataNode这一端,通过PeerServer封装了基于Socket的数据读写的基本操作,比如,绑定,监听,关闭等等。目前支持了两种PeerServer的实现,TCPPeerServer 和 DomainPeerServer, 顾名思义,分别用来支持基于TCP/IP的数据通信(TCP/IP网络读)和基于Domain Socket的数据通信(短路读和域套接字读)。负责基于PeerServer的实现来运行的,是DataXceiver,而DataXceiver被DataXCeiverServer调度。类关系如图-5所示:
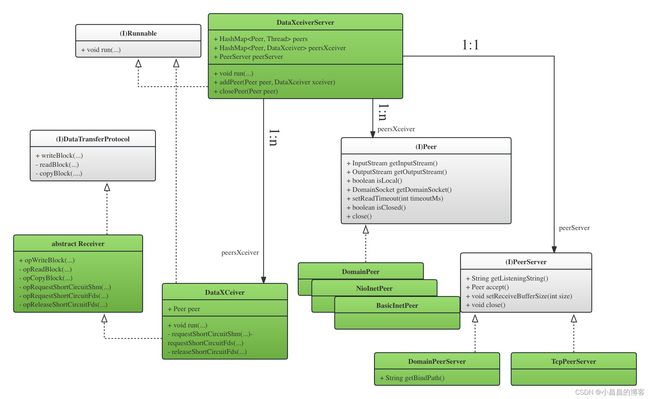
下面的代码显示了DataNode启动的时候为TCP/IP和为短路读以及域套接字读启动启动DataXceiverServer的过程:
------------------------------DataNode.java--------------------------
private void initDataXceiver() throws IOException {
// find free port or use privileged port provided
TcpPeerServer tcpPeerServer;
streamingAddr = tcpPeerServer.getStreamingAddr();
this.threadGroup = new ThreadGroup("dataXceiverServer");
xserver = new DataXceiverServer(tcpPeerServer, getConf(), this); // 创建基于`TCP/IP`的TcpPeerServer的DataXceiverServer
this.dataXceiverServer = new Daemon(threadGroup, xserver);
this.threadGroup.setDaemon(true); // auto destroy when empty
// 如果配置了shortCircuit读,那么会创建一个单独的Daemon, 封装了一个DataXceiver,这个DataXceiver专门
// 处理shortCircuit
if (getConf().getBoolean(
HdfsClientConfigKeys.Read.ShortCircuit.KEY,
HdfsClientConfigKeys.Read.ShortCircuit.DEFAULT) ||
getConf().getBoolean(
HdfsClientConfigKeys.DFS_CLIENT_DOMAIN_SOCKET_DATA_TRAFFIC,
HdfsClientConfigKeys
.DFS_CLIENT_DOMAIN_SOCKET_DATA_TRAFFIC_DEFAULT)) {
DomainPeerServer domainPeerServer = // 基于DomainSocket的PeerServer实现,这个PeerServer既用于ShortCircuit读,也用于DomainSocket读
getDomainPeerServer(getConf(), streamingAddr.getPort());
if (domainPeerServer != null) { // 创建基于DomainSocket的DomainPeerServer的DataXceiverServer
this.localDataXceiverServer = new Daemon(threadGroup,
new DataXceiverServer(domainPeerServer, getConf(), this));
}
可以看到,DataNode启动的时候,会首先无条件启动基于TCP/IP的DataXceiverServer,以接收以TCP/IP为信道的网络请求,这个不可以disable。同时,根据系统配置,选择是否启动基于Domain Socket的DataXceiverServer,启动的条件是:如果用户配置为enable 短路读(dfs.client.read.shortcircuit)或者 enable 了域套接字读(dfs.client.domain.socket.data.traffic),那么就会启动一个使用Linux Domain Socket作为socket实现的DataXceiverServer。
------------------------------DataXceiverServer.java--------------------------
/**
* Server used for receiving/sending a block of data. This is created to listen
* for requests from clients or other DataNodes. This small server does not use
* the Hadoop IPC mechanism.
*/
class DataXceiverServer implements Runnable {
......
@Override
public void run() {
Peer peer = null;
while (datanode.shouldRun && !datanode.shutdownForUpgrade) {
try {
peer = peerServer.accept();// 阻塞等待这个socket上的连接请求,可能来自本机上的一个或者多个客户端
// 阻塞结束,说明接受了连接请求
.....
// 构造一个DataXceiver,使用线程池中的独立线程处理请求
new Daemon(datanode.threadGroup,
DataXceiver.create(peer, datanode, this))
.start();
------------------------------DataXceiver.java--------------------------
/**
* Thread for processing incoming/outgoing data stream.
*/
class DataXceiver extends Receiver implements Runnable {
.......
/**
* Read/write data from/to the DataXceiverServer.
*/
@Override
public void run() {
try {
dataXceiverServer.addPeer(peer, Thread.currentThread(), this);
InputStream input = socketIn;
try {
IOStreamPair saslStreams = datanode.saslServer.receive(peer, socketOut,
socketIn, datanode.getXferAddress().getPort(),
datanode.getDatanodeId());
input = new BufferedInputStream(saslStreams.in,
smallBufferSize);
op = readOp(); // 从InputStream中提取出操作类型
......
processOp(op); // 根据操作类型,交给不同的方法去处理
从上面的实现可以看到,DataXceiverServer启动以后,会通过accept()不断阻塞等待新的请求,一旦监听到了新的请求,就会启动一个DataXceiver来负责处理这个请求,每一个DataXceiver都是一个Runnable,使用线程池对所有的DataXceiver进行处理。
DataXceiver的请求处理逻辑就是首先会从Socket的InputStream中读取操作类型,这些操作类型如下:
------------------------------------Op.java----------------------------------------
public enum Op {
WRITE_BLOCK((byte)80), // 写数据块
READ_BLOCK((byte)81), // 读数据块
READ_METADATA((byte)82), // 读数据块元数据
COPY_BLOCK((byte)84), // 拷贝数据块
BLOCK_CHECKSUM((byte)85), // 计算数据块的crc校验和
TREPLACE_BLOCK((byte)83),RANSFER_BLOCK((byte)86),
REQUEST_SHORT_CIRCUIT_FDS((byte)87), // 申请短路读的块文件描述符
RELEASE_SHORT_CIRCUIT_FDS((byte)88), // 释放短路读的块文件描述符
REQUEST_SHORT_CIRCUIT_SHM((byte)89), // 申请短路读的共享内存块
BLOCK_GROUP_CHECKSUM((byte)90), // 请求BlockGroup的checksum(用在Stripped Block,即纠删码中)
CUSTOM((byte)127);
然后根据op的类型,交给不同的方法去处理:
------------------------------------Receiver.java----------------------------------------
/** Process op by the corresponding method. */
protected final void processOp(Op op) throws IOException {
switch(op) {
case READ_BLOCK:
opReadBlock();
break;
......
case REQUEST_SHORT_CIRCUIT_FDS:
opRequestShortCircuitFds(in);
break;
case RELEASE_SHORT_CIRCUIT_FDS:
opReleaseShortCircuitFds(in);
break;
case REQUEST_SHORT_CIRCUIT_SHM:
opRequestShortCircuitShm(in);
break;
default:
throw new IOException("Unknown op " + op + " in data stream");
}
}
显然,跟短路读相关的就三种操作,REQUEST_SHORT_CIRCUIT_FDS,RELEASE_SHORT_CIRCUIT_FDS和REQUEST_SHORT_CIRCUIT_SHM。后面会详细讲解。
1.3 客户端申请共享内存并在共享内存中分配Slot
上文介绍了,DataNode启动的时候就已经在配置好的在Domain Socket上的监听。客户端构造时,会进行以下工作:
- 与DataNode基于DomainSocket 建立连接
- 申请共享内存
- 在共享内存中分配Slot,并通过Slot与DataNode进行replica相关信息的沟通同步
下文详细解释。
1.3.1 与DataNode 建立Socket 通信
在分配slot之前,dfs客户端会先通过Domain Socket与DataNode建立连接。
客户端和DataNode之间的连接都保存在PeerCache中,包括基于Domain Socket的Peer和基于常规的TCP的Peer。建立连接时,会以DataNodeID和连接类型(Domain Socket还是 TCP?)先从PeerCache获取。如果缓存中没有,则创建Domain Socket客户端并建立连接,并将创建好的Peer放到cache中以便重用(比如该客户端可能会从这个本机的DataNode上读取其他数据块,那么可以不用再建立新的Domain Socket连接)。同时,dfs.client.cached.conn.retry约束了该客户端最多使用缓存中的peer的次数为3次。
--------------------------------------PeerCache.java------------------------------------------
public class PeerCache {
private static class Key {
final DatanodeID dnID; // datanode id
final boolean isDomain; // 是否是 domain socket 的peer,目前有两种peer,基于domain socket的peer和 基于Tcp的peer
------------------------------------DomainSocketFactory.java----------------------------------------
/**
* Get the next DomainPeer-- either from the cache or by creating it.
*
* @return the next DomainPeer, or null if we could not construct one.
*/
private BlockReaderPeer nextDomainPeer() {
if (remainingCacheTries > 0) { // 最多使用3次peer。由于是一个client都会创建一个BlockReaderFactory,因此,一个client只能使用3次cache,超过了3次则必须重新创建socket
// 如果缓存中有,并且缓存次数没有超过限制,那么从缓存中拿对应的Domain Socket Peer
Peer peer = clientContext.getPeerCache().get(datanode, true);
if (peer != null) {
return new BlockReaderPeer(peer, true);// 这个BlockReaderPeer是来自cache
// 否则,创建一个新的Domain Socket Peer
DomainSocket sock = clientContext.getDomainSocketFactory().
createSocket(pathInfo, conf.getSocketTimeout());
return new BlockReaderPeer(new DomainPeer(sock), false); // 这个BlockReaderPeer不是来自cache
}
public DomainSocket createSocket(PathInfo info, int socketTimeout) {
...
// 通过dfs.domain.socket.path来建立连接
sock = DomainSocket.connect(info.getPath());
.....
下面的代码中,客户端通过调用一些native方法,调用到libhadoop中对应方法的library,并最终会调用操作系统的Domain Socket相关api,来建立socket连接:
// -------------------- DomainSocket.java --------------------
/**
* Create a new DomainSocket connected to the given path.
*
* @param path The path to connect to.
* @throws IOException If there was an I/O error performing the connect.
*
* @return The new DomainSocket.
*/
public static DomainSocket connect(String path) throws IOException {
int fd = connect0(path);
return new DomainSocket(path, fd);
}
// 建立DomainSocket 连接的native方法,这个native方法的具体调用定义在libhadoop的本地代码库中
private static native int connect0(String path) throws IOException;
1.3.2 客户端尝试在Segment中分配Slot,Slot不够用则申请新的segment
客户端与DataNode的连接建立完成,开始进入分配共享内存和Slot的阶段,即OP.REQUEST_SHORT_CIRCUIT_SHM的调用阶段。
上文提到过,共享内存中的一个Slot代表了客户端需要读取的一个replica的元数据信息,客户端和服务器端的JVM中都有对应的Slot对象,指向了共享内存中的这一块64B的Slot区域,都对这块区域进行必要的读写。
客户端会为每个DataNode构建一个DfsClientShmManager,专门负责与这个DataNode进行共享内存和分配slot相关的通信,在DataNode这一端的对应类为ShortCircuitRegistry,负责与该客户端进行与共享内存相关的工作。
基本流程如下图-6所示。

从上图可以看到,Segment的创建和Slot的分配流程是:
- 当需要读取一个replica,客户端会查看本地是否还有剩余的分配槽位,有的话直接分配,没有的话则向
DataNode申请新的Segment DataNode收到segment申请以后,会基于mmap()的方式创建一段共享内存,然后把共享内存的文件打开描述符(fd)返回给客户端- 客户端拿到了fd, 就可以同样通过
mmap()的方式打开,相当于和DataNode共享了内存,客户端在共享内存中为replica分配Slot,并通过Slot和DataNode同步信息。
DfsClientShmManager通过allocSlot()方法为replica在共享内存中创建Slot。有剩余Slot那么就直接分配,没有剩余Slot就需要先申请共享内存,申请到了共享内存,再在共享内存中创建Slot。
-------------------------------DfsClientShmManager.java-------------------------------
public class DfsClientShmManager implements Closeable {
.....
class EndpointShmManager {
private final DatanodeInfo datanode;
private final TreeMap<ShmId, DfsClientShm> full = new TreeMap<>();// 已经满了的共享内存段
private final TreeMap<ShmId, DfsClientShm> notFull = new TreeMap<>(); // 还有空闲slot的共享内存段
/**
分配slot,可能从已有的segment中分配,如果segment没有空闲slot,那么先申请新的segment,然后分配slot
*/
Slot allocSlot(DomainPeer peer, MutableBoolean usedPeer,
String clientName, ExtendedBlockId blockId) throws IOException {
while (true) { // 不断循环等待slot的分配,有可能通过已有slot的释放,有可能通过新的共享内存分配slot,成功则退出
// Try to use an existing slot.
Slot slot = allocSlotFromExistingShm(blockId); // 当前的共享内存还有空闲slot可供分配,则直接拿来分配就行了,无需申请新的共享内存
if (slot != null) { //客户端针对这个block的slot已经存在,则直接返回slot
return slot;
}
// 没有空闲slot,需要先申请共享内存,再在共享内存中分配slot
......
try {
// 没有空闲slot,那么需要申请一片新的共享内存,然后再放置这一块slot
shm = requestNewShm(clientName, peer); //申请了一个新的segment成功,剩下的交给下一轮循环,从这个segment中取选择slot
if (shm == null) continue;
// See #{DfsClientShmManager#domainSocketWatcher} for details
// about why we do this before retaking the manager lock.
domainSocketWatcher.add(peer.getDomainSocket(), shm);
// The DomainPeer is now our responsibility, and should not be
// closed by the caller.
usedPeer.setValue(true); // 这个DomainPeer已经使用过了(这个DomainPeer已经用来申请
}
allocSlotFromExistingShm()会尝试从已有的Segment中分配一个可用的Slot:
-------------------------------DfsClientShmManager.java-------------------------------
/**
尝试在当前已有的共享内存段中分配一个slot
*/
private Slot allocSlotFromExistingShm(ExtendedBlockId blockId) {
if (notFull.isEmpty()) { //从当前的DfsClientShmManager中没有找到任何一个还有slot位置的DfsClientShm
return null;
}
//找到一个还有空闲slot的SharedMemory segment
Entry<ShmId, DfsClientShm> entry = notFull.firstEntry();
DfsClientShm shm = entry.getValue();
ShmId shmId = shm.getShmId(); // 这个共享内存块的id,是由DataNode在创建这个共享内存的时候分配的
Slot slot = shm.allocAndRegisterSlot(blockId); // 找到空闲的slot
.....
return slot;
}
/**
找到一个可用的slot,构造成为Slot对象,这个Slot对象专门维护了针对这个Block的短路读的元数据信息
*/
synchronized public final Slot allocAndRegisterSlot(
ExtendedBlockId blockId) {
// allocatedSlots为标记slot可用性的bit数组,从该数组中找到第一个空闲slot的位置
int idx = allocatedSlots.nextClearBit(0);
allocatedSlots.set(idx, true); // 标记这个slot为已占用
// 创建了一个新的slot, 根据这个slot的索引值确定这个slot相对于这个segment的地址偏移
Slot slot = new Slot(calculateSlotAddress(idx), blockId);
slot.clear();
slot.makeValid();
slots[idx] = slot;
return slot;
}
如果无法从当前的segment中获取一个空闲slot(所有的slot都已经被占用),那么就尝试向DataNode申请一个新的共享内存,然后再分配Slot。requestNewShm()就是向DataNode申请共享内存。注意,客户端每次是申请一个 8KB大小的segment,而不是申请一个Slot。Segment的申请是客户端发起,Segment创建是DataNode操作,而在Segment中分配Slot又是客户端做的。
/**
向DataNode申请一段新的共享内存段,因为当前已经分配的共享内存已经没有可用的slot了
*/
private DfsClientShm requestNewShm(String clientName, DomainPeer peer)
throws IOException {
final DataOutputStream out =
new DataOutputStream(
new BufferedOutputStream(peer.getOutputStream())); // 基于DomainSocket与本地的DataNode进行通信
new Sender(out).requestShortCircuitShm(clientName);
ShortCircuitShmResponseProto resp =
ShortCircuitShmResponseProto.parseFrom(
PBHelperClient.vintPrefixed(peer.getInputStream())); // 接收本地DataNode基于DomainSocket发送过来的回复
switch (resp.getStatus()) {
case SUCCESS: // DataNode为该client成功创建了对应的Segment
DomainSocket sock = peer.getDomainSocket();
byte buf[] = new byte[1];
FileInputStream[] fis = new FileInputStream[1];
// 在 DataNode端,DataNode负责创建好对应的SharedMemory,大小为8192B, 此时,
// 客户端和DataNode端共享了相同的fd, 这个fd指向了对应的shared memory segment,同时这个segment是
// DN通过mmap的方式创建的,对应了内存中的一块区域
// shm = new RegisteredShm(clientName, shmId, fis, this);
try {
DfsClientShm shm =
new DfsClientShm(PBHelperClient.convert(resp.getId()),
fis[0], this, peer);
LOG.trace("{}: createNewShm: created {}", this, shm);
return shm;
...
}
下面的代码是在JVM中的Slot的定义。注意,这是在堆内存中的Slot定义,它存放了在共享内存中的Slot的地址,而不是共享内存的Slot本身。
---------------------------------Slot.java----------------------------------
public class Slot {
// slot是否可用的标记位
private static final long VALID_FLAG = 1L<<63;
// slot的锚定位
private static final long ANCHORABLE_FLAG = 1L<<62;
private final long slotAddress;// slot地址,其实就是该slot在共享内存中的地址偏移
private final ExtendedBlockId blockId; //该slot对应的block
参考图-4: 短路读的内存示意图, 可以看到,在共享内存中,一个Slot占用64字节,第一个字节的前32位用来存放跟Slot相关的标记位,目前只有两个标记位,后32位用来存放锚定数量,剩余字节为保留字节。两个标记为是:
-
VALID_FLAG:表示当前Slot是否有效。当
DFSClient在其共享内存区域之一内分配新槽时,它会设置此标志。当与此槽关联的副本不再有效时,DataNode会清除此标志。 当客户端认为DataNode不再使用此槽进行通信时,客户端本身也会清除此标志。 -
ANCHORABLE_FLAG:表示槽位对应的副本可以被锚定。
DataNode的缓存系统在将该replica缓存的时候,会调用操作系统的mlock()接口,将该block在内存中锁定(锚定,anchor),然后将该标识位置位。标志位置位,对于客户端意味着这个block的读取已经不需要再校验checksum了,因为DataNode进行replica的缓存的时候都校验过crc了,这时候客户端可以通过零拷贝和免校验读取(后面会介绍)该副本。客户端读取这样的副本的时候,会将对应的锚定计数器+1,释放的时候减去1。DataNode只有当该副本的锚定数位0的时候才会将该副本从内存缓存中删除,表明没有客户端还在使用这块缓存区域。
注意,共享内存的分配是
DataNode进行的,但是在共享内存区域中分配Slot是客户端进行的,分配完Slot,客户端会把Slot的信息写入共享内存区域,显然,这些信息就对DataNode可见了。
在DataNode端,在收到OP.REQUEST_SHORT_CIRCUIT_SHM请求以后,会开始创建共享内存。下文详细介绍。
1.3.3 DataNode通过mmap创建共享内存
在上一节的图中展示了DataNode处理共享内存的请求和创建共享内存的基本流程。
当DataNode收到了1.3.2中客户端OP.REQUEST_SHORT_CIRCUIT_SHM请求以后,会创建共享内存,大小为8KB。由于一个Slot占用64B,因此一个Segment一共可以分配8192B / 64B = 128个Slot。当客户端用尽了Slot,会再次过来申请Segment。
创建共享内存是基于mmap实现的:
-
先创建一个磁盘文件并打开,拿到文件的文件描述符。这个磁盘文件与当前请求共享内存的客户端一一对应,即DataNode会给每一个客户端创建一个独立的磁盘文件。
-
调用
POXIS.mmap(),即通过mmap()的方式,将该文件映射为内存映射文件,返回值为该内存映射文件的地址(baseAddress)。调用mmap()的时候,使用R&W的方式,因此无论是客户端还是DataNode,都有对该内存区域的读写权限 -
将刚刚打开的文件的描述符(是调用
mmap()以前的那个文件描述符),通过Domain Socket返回给客户端 -
客户端拿到文件描述符以后,通过同样的
mmap()方式,打开文件。由于客户端和DataNode基于同一文件的同一描述符通过mmap()打开文件,内存中只有一份拷贝,因此实现了内存共享。
可以看到,DataNode创建共享内存,是在磁盘上创建一个文件,再把这个文件通过mmap()映射到内存。因此,这段共享内存,是通过mmap的映射实现的共享内存。 -
DataNode服务端收到客户端的创建共享内存请求
--------------------------DataXceiver.java--------------------------
// 服务器端处理客户端的创建共享内存请求
@Override
public void requestShortCircuitShm(String clientName) throws IOException {
try {
shmInfo = datanode.shortCircuitRegistry.
createNewMemorySegment(clientName, sock);共享内存创建完毕,返回共享内存信息
// After calling #{ShortCircuitRegistry#createNewMemorySegment}, the
// socket is managed by the DomainSocketWatcher, not the DataXceiver.
releaseSocket();
}
......
sendShmSuccessResponse(sock, shmInfo); // 把共享内存区域的信息通过Domain Socket发送给客户端
success = true;
下面的代码显示DataNode打开一个大小为8KB的磁盘文件(文件路径通过),获取该文件的InputStream
// 打开文件,用来进行mmap操作。这里的共享文件路径是通过dfs.datanode.shared.file.descriptor.paths配置的,为了提高可用性,我们可以配置多个文件,DataNode会选取其中一个可用的文件,作为基于mmap的共享内存背后的文件
-------------------------- SharedFileDescriptorFactory.java --------------------------
public FileInputStream createDescriptor(String info, int length)
throws IOException {
return new FileInputStream( // 在创建shm的时候,这个info就是clientname, 因此各个client的filename 是不同的
// 这里实际上是创建了一个文件
createDescriptor0(prefix + info, path, length));
}
/**
* Create a file with O_EXCL, and then resize it to the desired size.
*/
private static native FileDescriptor createDescriptor0(String prefix,
String path, int length) throws IOException;
}
下面的代码显示DataNode将刚刚创建和打开的文件的InputStream通过mmap的方式映射到内存,作为共享内存区域:
// DataNode将打开的文件通过POXIS.mmap()的native 调用,在内存中创建对应的映射区
-------------------------- ShortCircuitShm.java --------------------------
public ShortCircuitShm(ShmId shmId, FileInputStream stream)
throws IOException {
// 下面的代码在客户端和服务器端同时执行
this.shmId = shmId;
this.mmappedLength = getUsableLength(stream);
//客户端和服务器端都把这个文件直接映射到自己的进程内存空间中,避免在读写文件过程中还需要通过内核态,避免数据从文件到内核、内核到用户态的多次拷贝
// 可以看到,调用mmap的时候,对应的权限是RW,因为无论是DataNode还是客户端,都将对这段内存进行读和写,实现状态同步
this.baseAddress = POSIX.mmap(stream.getFD(),
POSIX.MMAP_PROT_READ | POSIX.MMAP_PROT_WRITE, true, mmappedLength);
this.slots = new Slot[mmappedLength / BYTES_PER_SLOT]; // 默认情况下,一个segment可以存放8192 / 64 个slot
this.allocatedSlots = new BitSet(slots.length);//默认情况下,所有slot都没有分配
1.3.4 DataNode将共享内存的文件描述符返回给客户端
服务器端把在1.3.3中打开文件的InputStream通过Domain Socket的方式发送给客户端。
这是Domain Socket的一个重要特性,它支持文件描述符的传递: 即进程A 打开一个文件,然后将文件描述符通过Domain Socket发送给同一机器的另外一个进程B,实现文件共享。多个进程基于同一文件的文件打开描述符进行mmap内存映射,内存只会存在一份文件内容拷贝,就是共享内存。
----------------------------NewShmInfo.java --------------------------------------
public static class NewShmInfo implements Closeable {
private final ShmId shmId;
private final FileInputStream stream;
NewShmInfo(ShmId shmId, FileInputStream stream) {
this.shmId = shmId;
this.stream = stream; // 基于文件创建的读数据流
}
------------------------------DataXceiver.java--------------------------------------
/**
DataNode直接将基于mmap创建好的共享内存的FileInputStream的FD发送给客户端,实现内存共享
**/
private void sendShmSuccessResponse(DomainSocket sock, NewShmInfo shmInfo)
throws IOException {
// Send the file descriptor for the shared memory segment.
byte buf[] = new byte[] { (byte)0 };
FileDescriptor shmFdArray[] =
new FileDescriptor[] {shmInfo.getFileStream().getFD()};
sock.sendFileDescriptors(shmFdArray, buf, 0, buf.length);
}
1.3.5 客户端打开文件,写入Slot数据
收到DataNode发送过来的FD以后,客户端通过与DataNode一样的方式,即通过调用POXIS.map(),通过mmap()的方式,将该文件映射为内存映射文件,并获取了该内存映射的地址(baseAddress)。由于DataNode和服务器端使用的是同一个文件的fd进行的POXIS.map(),因此彼此对应了内存中的同一块映射区域,从而实现内存共享。
如下的类图-7所示,在客户端,使用DfsClientShm对象来控制和管理一块共享内存区域,在服务器端,与之对等的对象为ShortCircuitRegistry,它们都是 ShortCircuitShm的子类,一些对共享内存的共同操作封装在ShortCircuitShm中,比如,将文件描述符通过mmap()的方式转换为共享内存等。


至此,客户端和服务器端都有了对同一片内存内存映射的读写权限,从而实现了共享内存。这个共享内存是基于mmap,即DataNode先打开这个文件并获取InputStream, 然后客户端和服务器端都同时基于这个InputStream, 通过mmap()的方式获取到了这片内存区域的操作权限,并且相互的操作对对方可见。
// DataNode将打开的文件通过POXIS.mmap()的native 调用,在内存中创建对应的映射区
-------------------------- ShortCircuitShm.java --------------------------
public ShortCircuitShm(ShmId shmId, FileInputStream stream)
throws IOException {
// 下面的代码在客户端和服务器端同时执行
this.shmId = shmId;
this.mmappedLength = getUsableLength(stream);
//客户端和服务器端都把这个文件直接映射到自己的进程内存空间中,避免在读写文件过程中还需要通过内核态,避免数据从文件到内核、内核到用户态的多次拷贝
// 可以看到,调用mmap的时候,对应的权限是RW,因为无论是DataNode还是客户端,都将对这段内存进行读和写,实现状态同步
this.baseAddress = POSIX.mmap(stream.getFD(),
POSIX.MMAP_PROT_READ | POSIX.MMAP_PROT_WRITE, true, mmappedLength);
this.slots = new Slot[mmappedLength / BYTES_PER_SLOT]; // 默认情况下,一个segment可以存放8192 / 64 个slot
this.allocatedSlots = new BitSet(slots.length);//默认情况下,所有slot都没有分配
1.4 读取Replica
到这里为止,客户端已经为该Replica准备好了Slot。读取replica的准备工作完成,可以进行replica的读取了。
下文将详细讲解,客户端会向DataNode通过Domain Socket的方式获取replica的读取句柄InputStream,然后脱离开DataNode读取replica的全部过程。
1.4.1 向DataNode请求replica的文件描述符
下图-8展示了在共享内存和Slot构建结束以后,客户端向DataNode申请对应的replica的InputStream的过程。

- 客户端通过
Linux Domain Socket向远程的DataNode申请读取某个replica。上文提到过,这个操作的名称是OP.REQUEST_SHORT_CIRCUIT_FDS,即申请短路读的文件描述符(FD)。 收到请求以后,DataNode会把这个replica文件和这个replica的meta文件打开(meta中主要存放了replica的checksum,如果需要对replica计算校验和,就将收到的replica的校验和跟meta文件记录的校验和进行比对),将这两个文件的InputStream的FileDescription通过Domain Socket返回给客户端。 上文讲过,Domain Socket的一个巨大优势是直接支持进程间进行文件描述符的传递。
下面的代码显示了DataNode打开自己管理的replica文件,然后获取文件的InputStream:
----------------------------------LocalReplica.java-----------------------------------
/**
* 打开Block文件,获取文件的InputStream
*/
private FileInputStream getDataInputStream(File f, long seekOffset)
throws IOException {
FileInputStream fis;
.....
else {
try {
// 通过普通的方式(RandomAccessFile + seek)打开Block文件
fis = fileIoProvider.openAndSeek(getVolume(), f, seekOffset);
} }
return fis;
}
------------------------------ ShortCircuitReplica.java ------------------------------------
/**
DataNode打开本地的replica文件
*/
public static FileDescriptor openAndSeek(File file, long offset)
throws IOException {
RandomAccessFile raf = null;
try {
// 以只读的方式打开Block文件
raf = new RandomAccessFile(file, "r");
if (offset > 0) {
raf.seek(offset);
}
return raf.getFD();
} ......
}
DataXceiver处理客户端的REQUEST_SHORT_CIRCUIT_FDS请求,然后把replica和replica meta的FD返回给客户端:
-------------------------------------------DataXceiver.java---------------------------------------------
public void requestShortCircuitFds(final ExtendedBlock blk,
final Token<BlockTokenIdentifier> token,
SlotId slotId, int maxVersion, boolean supportsReceiptVerification)
throws IOException {
....
if (slotId != null) {
// class FsDatasetImpl implements FsDatasetSpi由于这个文件是
DataNode打开而不是客户端打开的,所以DataNode完全自行控制打开文件以后的权限。在这里,客户端只需要读replica,因此DataNode只需要以Readonly的方式打开就行。可以看到,直到这一步,整个文件打开都与mmap()无关,后文会讲,是否通过mmap()的方式通过零拷贝读取replica,是客户端自行决定,最坏情况是直接使用这个InputStream进行传统的replica读取。
1.4.2 打开该replica
下图显示了客户端拿到了DataNode打开的副本文件的描述符以后的基本处理流程,主要是:
- 客户端拿到副本文件的文件描述符以后,不是直接进行读取,而是尝试进行最高效的零拷贝读取(下面会详细介绍)。在零拷贝读取中,如果我们确认数据已经被
DataNode缓存在内存中,那么这些数据不仅零拷贝,而且无需计算checksum。 - 如果零拷贝读取无法实现,就基于这个文件描述符进行直接的、常规的块文件读取。
可以看到,无论是否成功进行零拷贝读取,副本块的读取都不再经过DataNode了,这就是零拷贝读取和基于TCP网络通信以及Domain Socket通信的最重大不同:块文件的真正读取不经过DataNode的进程。

Client端拿到InputStream以后,实际上已经完全可以直接读取到该replica了。但是,为了提高读取效率,客户端会首先尝试进行高效的零拷贝读取(zero copy read),如果零拷贝读取失败,才会回退到基于常规的InputStream的读写,即从文件读取到操作系统内核,然后从操作系统内核缓存拷贝到用户进程空间 。
---------------------------------------DFSInputStream.java------------------------------------------
@Override
public synchronized ByteBuffer read(ByteBufferPool bufferPool,
int maxLength, EnumSet<ReadOption> opts)
throws IOException, UnsupportedOperationException {
...
// 如果dfs.client.mmap.enabled=true,那么会先尝试进行零拷贝读取
if (dfsClient.getConf().getShortCircuitConf().isShortCircuitMmapEnabled()) {
buffer = tryReadZeroCopy(maxLength, opts);
}
if (buffer != null) {
return buffer;
}
// 无法进行zerocopy的copy, 回退到基于常规读写的模式,但是同样不用再经过DataNode了
buffer = ByteBufferUtil.fallbackRead(this, bufferPool, maxLength);
....
return buffer;
}
这里的零拷贝读取对理解短路读的高效非常重要,因此着重解释:
什么是零拷贝:
零拷贝读取,使用了内存映射文件mmap的读取方式。在本文开头讲mmap的时候就讲过,内存映射文件和标准IO操作最大的不同是并不需要将数据读取到操作系统的内核缓冲区,而是直接将进程私有地址空间中的一部分区域与文件对象建立起映射关系,就好像直接从内存中读写文件一样,减少了IO的拷贝次数,提高了文件的读写速度。
java提供了三种内存映射模式,即:只读(readonly)、读写(read_write)、专用(private)。
- 对于只读模式来说,如果程序试图进行写操作,则会抛出
ReadOnlyBufferException异常; - 对于读写模式来说,如果程序通过内存映射文件的方式写或者修改文件内容,则修改内容会立刻反映到磁盘文件中,如果另一个进程共享了同一个映射文件,也会立即看到变化;
- 专用模式采用的是操作系统的"写时拷贝"原则,即在没有发生写操作的情况下,多个进程之间都是共享文件的同一块物理内存的(进程各自的虚拟地址指向同一片物理地址),一旦某个进程进行写操作,就会把受影响的文件数据单独拷贝一份到进程的私有缓冲区中,不会反映到物理文件中。
在tryReadZeroCopy()方法中,使用的是只读模式,多个进程通过共享同一块内存映射区域,来实现零拷贝读取,文件只需要往内存中load一次。
tryReadZeroCopy()会通过mmap()的方式,打开DataNode传过来的replica文件的描述符。那么问题来了,为什么通过mmap()的方式打开描述符,就成了零拷贝呢?不也需要把磁盘文件读取到内存吗?
其实,问题的关键在于HDFS的缓存。即,客户端读取的这个replica可能已经在DataNode端被缓存起来了。了解DataNode缓存的就知道,DataNode缓存数据的时候,就是通过mmap()和mlock()的方式将replica映射到内存。因此,当客户端通过该文件的FileDescriptor通过mmap()的方式打开文件,已经不需要再从磁盘读取文件,而是直接映射到了DataNode的缓存中,因此是零拷贝。
零拷贝带来的好处:
- 数据读取效率和节省内存空间 如果数据已经在
DataNode端缓存起来,那么通过零拷贝方式,用户的客户端进程无需再次读取数据到内存,而是直接引用这块缓存数据,既提高了数据读取效率,也节省了内存(同一块数据无需重复存取) - 在特定情况下不用再进行checksum校验,因为零拷贝成功,说明数据已经被
DataNode通过mmap()的方式缓存到内存了,DataNode在缓存时肯定已经做过checksum了。checksum是cpu密集型操作。
HDFS的缓存的调用发生在CachingTask的Runnable中,我们以内存缓存为例(HDFS还支持持久内存缓存Pmem, 本文不讨论):
----------------------------------------CachingTask.java----------------------------------------------
private class CachingTask implements Runnable {
/**
DataNode的CachingTask会通过mmap()的方式将replica加载到缓存中,同时通过mlock()将这段内存锁定在缓存中。
*/
@Override
public void run() {
...
blockIn = (FileInputStream)dataset.getBlockInputStream(extBlk, 0);
metaIn = DatanodeUtil.getMetaDataInputStream(extBlk, dataset);
.....
// 通过cacheLoader,将块load到缓存。对于基于内存的缓存,cacheLoader的实现是MemoryMappableBlockLoader
mappableBlock = cacheLoader.load(length, blockIn, metaIn,
blockFileName, key);
----------------------------------------MemoryMappableBlockLoader.java----------------------------------------------
/**
* Load the block.
* mmap and mlock the block, and then verify its checksum.
*/
@Override
MappableBlock load(long length, FileInputStream blockIn,
FileInputStream metaIn, String blockFileName, ExtendedBlockId key)
throws IOException {
// 通过mmap的方式将文件映射到内存
mmap = blockChannel.map(FileChannel.MapMode.READ_ONLY, 0, length);
NativeIO.POSIX.getCacheManipulator().mlock(blockFileName, mmap, length);//调用操作系统mlock接口,将
verifyChecksum(length, metaIn, blockChannel, blockFileName);// 计算checksum
mappableBlock = new MemoryMappedBlock(mmap, length)
我们看到,DataNode在进行缓存操作的时候,除了mmap(),还调用mlock()的系统调用。mlock()的作用是将指定地址范围内的页被锁定在物理内存中。 在此进程或其他进程中引用锁定页不会导致需要 I/O 操作的页错误。
在客户端,在尝试进行零拷贝读取的时候,会尝试调用createNoChecksumContext()来创建无需进行checksum的上下文。createNoChecksumContext()只有在下面的情况会返回true,即无需进行checksum的前提是,这段数据已经被DataNode缓存到了内存,因为,根据DataNode的缓存机制,缓存到内存的数据都必须进行了checksum都校验 ,因此,客户端使用这段内存无需再进行checksum了,况且checksum是cpu密集型的操作。
下面的代码可以看到createNoChecksumContext()的判断标准和创建客户端的mmap的过程:
-------------------------------------------BlockReaderLocal.java-------------------------------------------------
public ClientMmap getClientMmap(EnumSet<ReadOption> opts) {
boolean anchor = verifyChecksum &&
!opts.contains(ReadOption.SKIP_CHECKSUMS);
if (anchor) { // 需要进行数据校验
if (!createNoChecksumContext()) { // 创建nochecksum context失败
return null;
}
}
clientMmap = replica.getOrCreateClientMmap(anchor);
}
// 创建Nochecksum 的上下文,如果成功,那么说明正在读取DataNode缓存中的数据,因此无需再进行checksum,因为DN在进行缓存的时候已经做了
private boolean createNoChecksumContext() {
// 客户端通过配置的方式配置为跳过checksum, 或者是临时存储, 或者,如果verifyChecksum为true,同时storagetype不是临时存储,
// 那么添加checksum anchor计数。如果计数成功,就返回true,计数失败返回false。
// 能否anchor,是在DataNode端通过ShortCircuitRegistry.registerSlot() -》 slot.makeAnchorable()来判断的
return !verifyChecksum ||
// Checksums are not stored for replicas on transient storage. We do
// not anchor, because we do not intend for client activity to block
// eviction from transient storage on the DataNode side.
(storageType != null && storageType.isTransient()) ||
replica.addNoChecksumAnchor();
}
----------------------------------------------ShortCircuitReplica.java-----------------------------------------------
/**
客户端尝试通过mmap的方式实现零拷贝
*/
MappedByteBuffer loadMmapInternal() {
try {
// 将DataNode返回的读取block的dataStream转换成内存的mmap
FileChannel channel = dataStream.getChannel();
MappedByteBuffer mmap = channel.map(MapMode.READ_ONLY, 0,
Math.min(Integer.MAX_VALUE, channel.size()));
return mmap;
}
NoChecksumAnchor的作用:
NoChecksumAnchor是这个replica对应的slot中的一个计数器,通过Unsafe去增加或者减少以进行计数。它主要是统计当前有多少客户端正在通过无需校验的方式读取缓存中的replica。
刚刚说到,对于已经被DataNode缓存的数据,客户端通过mmap 的方式读取,无需再进行checksum。replica在DataNode上既然的缓存,那肯定有缓存的淘汰策略。如果一个缓存的replica正在被客户端通过mmap nochecksum 的方式读取,我们肯定不希望这个replica在缓存中被淘汰,否则会使得客户端的读操作失败。那么,如果知道当前缓存的replica是否有客户端正在通过mmap的方式读取呢?这是通过Slot中的noCheckSumAnchor来完成的:每当客户端通过mmap的方式读取一个block,如果创建nonchecksum context成功,那么就将noChecksumAnchor的计数器加1,读完以后减去1。这样,DataNode只会在这段缓存的nochecksumAnchor的计数为0的时候,才会从物理内存中解锁这段缓存,即进行munlock()操作,代表缓存可以被swap out 了。
可以看到,将普通文件读写的InputStream转换成MappedByteBuffer的过程都被Java NIO进行了很好的封装,使用很简单:
- 从文件的
InputStream中获取文件读写的Channel - 通过
map()将InputStream 映射到MappedByteBuffer(注意,mmap调用完成以后,并没有真正将文件数据拷贝到MappedByteBuffer中,真生的数据拷贝发生在客户端真的开始从MappedByteBuffer读取数据的时候) - 通过
mlock()的方式将这段内存区域锁定
这里涉及到对
ByteBuffer的理解、对Channel的理解,但是不在本文介绍的范围内。我们只需要知道,MappedByteBuffer是一种·ByteBuffer·的实现,因此ByteBuffer的整个操作逻辑对MappedByteBuffer也适用。但是,MappedByteBuffer是一种特殊的ByteBuffer, 它的内容是某个文件的一部分(Segment), 并且文件的内容是存放在Direct Memory中的(不在jvm heap中)。
3. 结束
可以看到,整个短路读的方式涉及到了很多特殊的操作系统层面的知识,因此传统的做Java开发的,如果仅仅从Hadoop代码层面无法对短路读有准确的理解,所以本文开始的时候介绍了短路读所涉及到的一些操作系统知识。
短路读的整个流程讲清楚也非常不容易,因为流程多,通信方式多,又是Domain Socket通信,又是共享内存通信,又是文件描述符传递。
本文力求详尽,但是如果想要彻底理解,还需要读者顺着本文的思路真实地去看代码。
4.参考文章
- 认真分析mmap:是什么 为什么 怎么用
- HDFS短路读详解
- 文件操作之FileChannel和mmap
- Java NIO 中的 Channel 详解
- 详解Java NIO之Channel(通道)
- 读HDFS书笔记—5.2 文件读操作与输入流(5.2.2)—下
- mmap和共享内存
- 关于共享内存shm和内存映射mmap的区别是什么?
- 共享内存之——mmap内存映射