DataFrame增删改
01.DataFrame行操作
1.添加行
基本格式:
方法:df.append(other) 说明:向 DataFrame 末尾添加 other 新行数据,返回新的 DataFrame
示例:
(1)加载 scientists.csv 数据集
import pandas as pd
scientists = pd.read_csv('./data/scientists.csv')
scientists 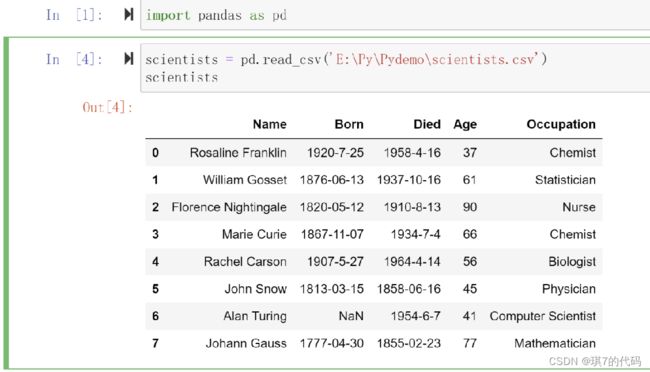
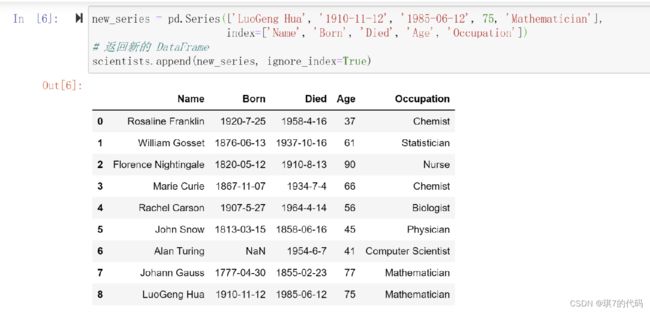
(2)在 scientists 数据末尾添加一行新数据
# 准备新行数据
new_series = pd.Series(['LuoGeng Hua', '1910-11-12', '1985-06-12', 75, 'Mathematician'], index=['Name', 'Born', 'Died', 'Age', 'Occupation'])
new_series
(3)在 scientists 数据末尾添加一行新数据
# 返回新的 DataFrame
scientists.append(new_series, ignore_index=True)
2.修改行
基本格式:
方法1:df.loc[['行标签', ...],['列标签', ...]] 说明:修改行标签对应行的对应列的数据
方法2:df.iloc[['行位置', ...],['列位置', ...]] 说明:修改行位置对应行的对应列的数据
示例1:修改行标签为 4 的行的所有数据 修改之后:
scientists.loc[4] = ['Rachel Carson', '1907-5-27', '1965-4-14', 57, 'Biologist']
scientists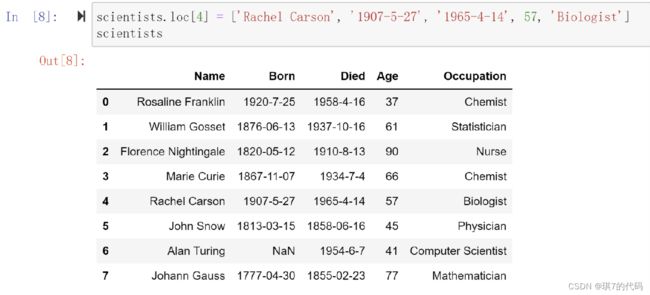
示例2:修改行标签为 4 的行的 Born 和 Age 列的数据
scientists.loc[4, ['Born', 'Age']] = ['1906-5-27', 58]
scientists
示例3:修改行标签为 6 的行的 Born 列的数据为 1912-06-23
scientists.loc[6, 'Born'] = '1912-06-23'
scientists
3.删除行
基本格式:
方法:df.drop(['行标签', ...]) 说明:删除行标签对应行的数据,返回新的 DataFrame
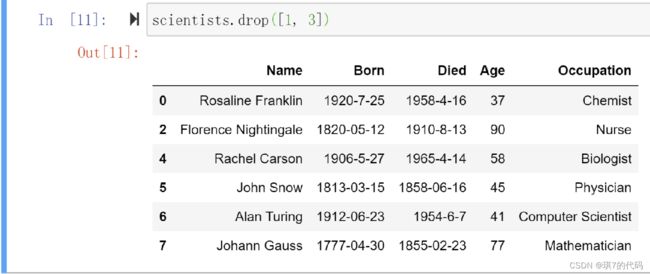
示例:删除行标签为 1 和 3 的行
scientists.drop([1, 3])
02 DataFrame列操作
1.新增列/修改列
基本格式:
方式1:df['列标签']=新列 说明:1)如果 DataFrame 中不存在对应的列,则在 DataFrame 最右侧增加新列2)如果 DataFrame 中存在对应的列,则修改 DataFrame 中该列的数据
方式2:df.loc[:, 列标签]=新列 说明:1)如果 DataFrame 中不存在对应的列,则在 DataFrame 最右侧增加新列2)如果 DataFrame 中存在对应的列,则修改 DataFrame 中该列的数据
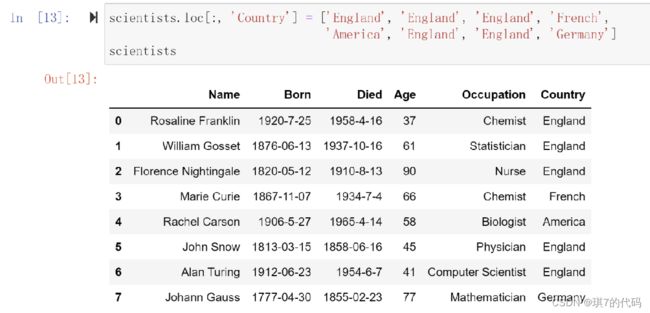
示例1:给 scientists 数据增加一个 Country 列
scientists
scientists['Country'] = ['England', 'England', 'England', 'French',
'America', 'England', 'England', 'Germany']
或
scientists.loc[:, 'Country'] = ['England', 'England', 'England', 'French',
'America', 'England', 'England', 'Germany']
scientists
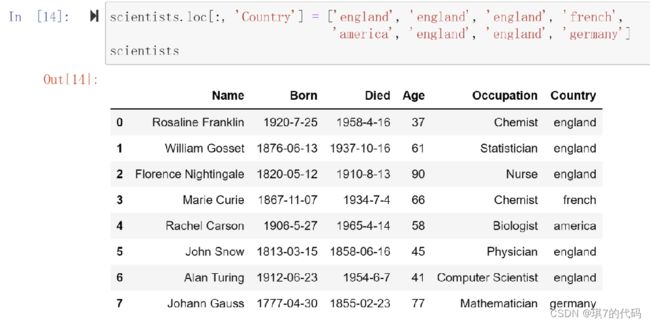
示例2:修改 scientists 数据中 Country 列的数据
#国家首字母变成小写
scientists['Country'] = ['england', 'england', 'england', 'french',
'america', 'england', 'england', 'germany']
或scientists.loc[:, 'Country'] = ['england', 'england', 'england', 'french',
'america', 'england', 'england', 'germany']
scientists
2.删除列
基本格式:
方式:df.drop(['列标签', ...], axis=1) 说明: 删除列标签对应的列数据,返回新的 DataFrame
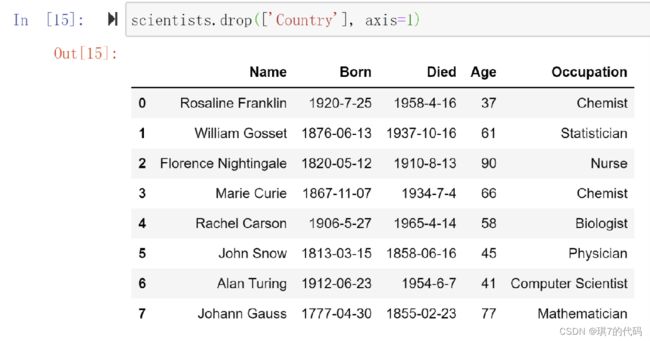
示例:删除 scientists 数据中 Country 列的数据
scientists.drop(['Country'], axis=1)