【数据结构】双向链表(思路解释,插入,删除,打印. c++代码)
到双向链表咯,链表的知识终于走到最终章了hhh(视频教程只到这些知识
视频课程地址:
https://www.bilibili.com/video/BV1Fv4y1f7T1?p=11&vd_source=02dfd57080e8f31bc9c4a323c13dd49c

目录
双向链表的思想
双向链表的操作
新节点的初始化
从链表头部插入节点
正向打印链表
反向打印链表
从链表中删除数据
从链表末尾插入节点
主函数测试
双向链表的思想
就我粗浅的描述,双向链表就是可以从前后两个方向遍历链表(简称双链表),相比单链表节点:包含两个元素,一个元素用来存储数据,一个元素用来存储下一个数据的地址,双向链表只是在这两个元素的基础上,增加了一个存储上一个数据的地址。
其实很好理解,当一个节点包含本身的数据,又含有其上一个元素和下一个元素的地址,那么不就可以从前或者从后索引到其他元素么?可以理解撒。
不过它比单链表多开辟了一份地址的空间,但在复杂情况下,使用双链表应该会方便。
双向链表的操作
明白双向链表的思想之后,我们会想到它肯定是方便执行那些单链表可以实现的操作咯。这里一些部分会与单链表进行对比理解。
新节点的初始化
在执行插入节点的操作时,会面临需要创建一个新的节点的问题,由于双向链表每个节点包含三个元素,相比单链表要多写一步,为了使代码更简洁清晰,把创建新节点单独封装函数,直接调用即可。注意其返回值应该是指向新创建节点的指针。
// 创建一个新的节点
struct Node *GetNew(int x)
{
struct Node *temp = new Node();
temp->data = x;
temp->next = NULL;
temp->prev = NULL;
return temp;
}从链表头部插入节点
我们思考一下,在单链表中,从头部插入节点,思路如下
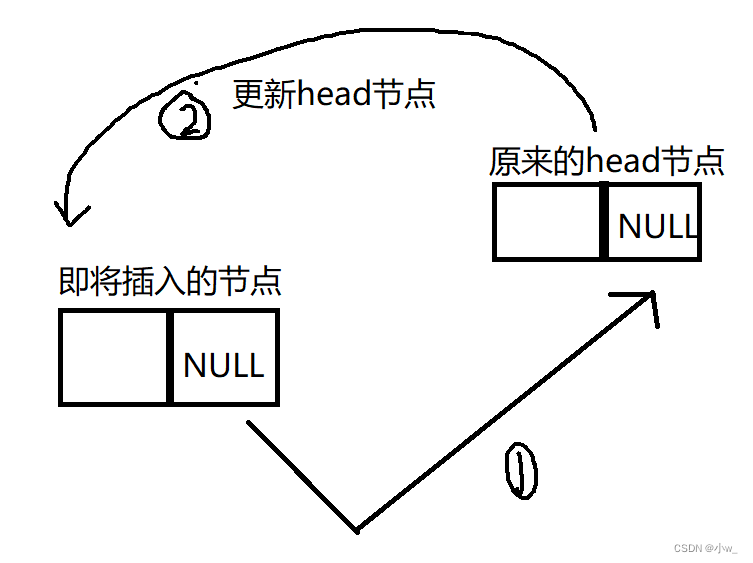
而且这两步的顺序是不可以改的,防止地址丢失。
而双向链表因为多存储了一个地址 ,在思想上更容易理解一些。思路如下

这两步是没有先后顺序的,因为前后地址都是单独存储的,不存在丢失。
两者在书写上的区别就是:单链表并没有单独将head=NULL的情况进行判断。因为不论链表是否为空,所执行的操作都是一样的:更改新节点的地址位为head即可。
单链表:
void Insert(int x)
{
struct Node* temp=(struct Node*)malloc(sizeof(struct Node));//malloc 的返回值为 void*,接收时必须强制类型转换
(*temp).data = x;
temp->next=head;//当链表为空的时候 head 自然是NULL 该语句仍然成立 所以可以部分情况 写一个语句即可
head = temp;
}这是因为,单链表只需要存储后一个数据的地址。但是双向链表还存储了其前一个数据的地址,为了确保正确更新,需要对head==NULL单独判断。当head==NULL时,直接更新head即可,但是当链表不为空的时候,需要对节点中的两个地址进行不同的更新。
// 从链表头部插入节点
void InsertAtHead(int x)
{
struct Node *newnode = GetNew(x);
if (head == NULL)
{
head = newnode;
return;
}
// 更新地址指向来建立联系
head->prev = newnode;
newnode->next = head;
head = newnode;
}正向打印链表
这个就比较简单了,直接参考代码。
// 正向打印链表
void Print()
{
struct Node *temp = head;
printf("Forward:");
if (temp == NULL)
return;
while (temp != NULL)
{
printf("%d ", temp->data);
temp = temp->next;
}
printf("\n");
}反向打印链表
这里就有一些注意点了。
想想我们单链表反向打印是怎么实现的?通过递归找到了链表的最后一个节点,实现反向打印。
而双链表由于存储了前一个数据的地址,所以可以不使用递归,通过while循环先把temp更新到指向链表中的最后一个节点,然后直接将数据的更新方式 从temp->next,变化为temp->prev.
head==NULL的情况就不再解释了,写过很多次了。
// 反向打印
void ReversePrint()
{
struct Node *temp = head;
printf("Reverse:");
if (temp == NULL)
return;
// 遍历链表到达最后一个节点
while (temp->next != NULL) // 注意这里应该是判断temp->next不等于NULL,这样循环终止的时候,temp是指向最后一个节点的
{
temp = temp->next;
}
while (temp != NULL)
{
printf("%d ", temp->data);
temp = temp->prev;
}
printf("\n");
}从链表中删除数据
想一下单链表中我们是如何实现的?直接通过地址的更改。

只不过地址的存储和更新需要注意。
for (int i = 0; i < x - 2; i++)
{
temp1 = temp1->next;
} // 现在找到的时目标位置的前一个位置 即此时temp1表示的是要删除元素的前一个元素
struct Node *temp2 = temp1->next; // 现在temp2表示的是要删除的这个元素
temp1->next = temp2->next; // 让n-1的地址指向n+1的位置
free(temp2);在双向链表中,删除节点的思路应该是这样的

在双向链表中删除一个节点,需要先找到要删除的节点,然后将该节点的前驱节点的 next 指针指向该节点的后继节点,将该节点的后继节点的 prev 指针指向该节点的前驱节点。同样没有先后顺序
void Delete(int x)
{
struct Node *temp = head;
if (x == 1)
{
head = temp->next;
free(temp);
}
// 在 for 循环中,temp 被移动到了要删除的节点
// 但是在循环结束后,temp 没有进行任何检查,所以如果 x 大于链表的长度
// 那么 temp 将会是一个空指针,这将导致程序崩溃
// 由于我们传入的是 第 x 个节点,是个数字,所以for循环的主体要定义一个整型i来进行遍历
for (int i = 0; i < x - 1; i++)
{
temp = temp->next;
} // 找到了要删除的节点
/*最开始自己写写错了...我把它想成交换数据了,看错了
struct Node* temp1;
temp1=temp->prev;
temp->prev=temp->next;
temp->next=temp1;
free(temp1);
*/
//重点!!
temp->prev->next = temp->next;
temp->next->prev = temp->prev;
free(temp);
// 释放要删除节点所占用的内存空间
}从链表末尾插入节点
单链表中的实现
//创建一个新的节点,遍历链表中的节点直到找到下一个地址为空的节点为止
Node *temp2 = head;
while (temp2->next != NULL)
temp2 = temp2->next;
//更新 插入的节点
temp2->next = temp1;双链表中唯一不同的就是最后更新地址的时候,注意更新两个地址。
void InsertAtTail(int x)
{
struct Node *temp1 = GetNew(x);
if (head == NULL)
{
head = temp1;
return;
}
else
{
Node *temp2 = head;
while (temp2->next != NULL)
{
temp2 = temp2->next;
} // 找到最后一个节点
temp2->next = temp1;
temp1->prev = temp2; // 记住我们这里双向链表节点有三个参数,注意赋值
}
}主函数测试
将上面的函数都写上,我用了下面的代码来检验,当然检验的代码是随意的,想怎么写怎么写。
int main()
{
// 起始链表为空
head = NULL;
InsertAtHead(1);
Print();
ReversePrint();
InsertAtHead(5);
Print();
ReversePrint();
InsertAtHead(9);
InsertAtHead(4);
Print();
ReversePrint();
// 删除节点函数 传入的数据应该是 第 几 个节点
Delete(2);
InsertAtTail(9);
InsertAtTail(9);
Print();
}ok啦,链表的知识到这里就结束啦。
有问题欢迎指出,非常感谢!!!
也欢迎交流建议哦!