Scrapy入门到放弃07:scrapyd、gerapy,界面化启停爬虫
前言
上一篇的枯燥无味,就用这一篇来填补一下。写到插件篇了,终于能写点有意思的东西了,接下来就Scrapy基本概念和插件篇来穿插着写一写。
在我们以往开发的爬虫中,不论是Java的Jsoup,还是Python的requests,启动方式和普通的应用程序没什么两样,都是通过命令来本机运行。
但Scrapy提供了远程启停爬虫的服务Scrapyd。Scrapyd基于http协议开放了API,以此来远程启停爬虫。
而第三方插件Gerapy作为一个分布式爬虫管理框架,基于Scrapyd又封装了一个web应用,在网页上就可以启停爬虫程序,监控程序日志。
Scrapyd
1.安装
命令两行,快速安装。
python install scrapyd
python install scrapyd-client
2. scrapyd配置
在python的site-packages/scrapyd安装目录下,有一个default-scrapyd.conf配置文件,里面是scrapyd的默认配置,我们可以修改一些默认配置。

这里主要还是修改IP和端口。
bind_address:默认是本地127.0.0.1,修改为0.0.0.0,可以让外网访问
http_port:服务端口,默认是6800
3.项目配置
在每个Scrapy项目下,都有一个scrapy.cfg,添加以下配置。
[deploy:video]
url = http://localhost:6800/
# 这个project名称你随便起
project = VideoSpider
其中要注意以下两点:
-
video为deploy的别名,冒号之间千万不要有空格,别问,问就是加空格是我的编码风格
-
url端口要与scprayd.conf中一致
4. 启动服务
在主机上新建一个目录,执行scrapyd,这里注意,一定要新建目录,因为目录中会生成一些数据文件。
如果是linux环境,记得要创建软链接。
ln -s /usr/local/python3.9/bin/scrapyd /usr/local/bin/scrapyd
ln -s /usr/local/python3.9/bin/scrapyd-client /usr/local/bin/scrapyd-client
ln -s /usr/local/python3.9/bin/scrapyd-deploy /usr/local/bin/scrapyd-deploy
操作如下图:

5.部署服务
我们需要进入到scrapy项目的目录下,执行deploy命令。将项目中的爬虫部署到scrapyd服务上去。
scrapyd-deploy video -p VideoSpider
响应结果为200时,表示部署成功。

同时,scrapyd-deploy -l 命令可以查看部署了哪些项目。
6.API
前面也说了,scrapyd是一个通过API来操作爬虫的服务框架。这里先列举一比较常用的API。
1. http://localhost:6800/daemonstatus.json:查看集群负载,返回{ status, running, pending,finished, node_name }的json
2. http://localhost:6800/schedule.json -d project=myproject -d spider=SpiderName [ -d setting = DOWNLOAD_DELAY = 2 -d arg1 = val1]:运行爬虫,
3. http://localhost:6800/cancel.json -d project=myproject -d job=jobid:停止爬虫
4. http://localhost:6800/listjobs.json | listspiders.json?project=myproject:查看项目的任务|爬虫列表
5. curl http://localhost:6800/delproject.json -d project=myproject:删除项目
操作截图如下:

这里要注意的是,里面的myproject要换成自己的项目名称,这里我需要换成VideoSpider。
这样的API的操作方式,对于很多人来说太不友好了,所以为了解决这个问题,Gerapy基于scrapyd服务,提供了界面化的操作方式。
Gerapy
前提:scrapyd服务启动,项目已经部署到scrapyd中
1. 安装
命令一行,极速安装。
pip install gerapy
2. 服务初始化
执行以下命令完成安装、初始化、用户创建。
安装
pip install gerapy
初始化
新建一个目录,执行以下命令,此目录会作为gerapy的工作目录。
gerapy init
在当前目录下会生成一个gerapy文件夹。
创建数据库
进入gerapy文件夹,执行以下命令,在gerapy目录下生成一个sqlite数据库,同时创建数据表。
gerapy migrate
这里的sqlite是一个嵌入式数据库,在后面也会用到另一个嵌入式数据库BerkeleyDB。在linux环境下,如果sqlite版本过低,执行此操作会报错,这时候需要安装高版本的sqlite。
sqlite版本升级的详细步骤就不写了,留给大家一点发挥空间。
用户创建
执行以下命令,来创建管理用户。
gerapy createsuperuser
执行此命令后,会提示我们输入用户名、邮箱、密码等。以上操作如下图:
3.启动gerapy
在gerapy工作目录下,执行以下命令启动服务:
前台方式运行
gerapy runserver 0.0.0.0:8888
后台方式运行
gerapy runserver 0.0.0.0:8888 > /dev/null 2>&1 &
这里强调两点:
- 如果想被外网访问,启动的时候就要加0.0.0.0
- 默认端口是8000,我这里修改为了8888
- 测试采用前台方式运行,生产采用后台方式运行
访问8888端口,进入登录页面。

输入用户名、密码登录进入到主机管理菜单下。
4.菜单介绍
主机管理
主机管理主要是对部署在scrapyd服务上的scrapy爬虫进行界面化管理操作。

点击右上角的创建按钮,添加scrapyd服务的IP和端口,点击保存,结果如下图。

状态正常之后,点击调度按钮,进入scrapy项目爬虫列表。

点击爬虫程序后面的运行按钮,即可运行爬虫。
项目管理
Gerapy的工作目录下有一个空的projects文件夹,也就是存放Scrapy目录的文件夹。要部署一个 Scrapy 项目,也可以不提前部署到scrapyd上,只要项目文件放在projects文件夹中即可。
方式主要有以下三种:
- 将本地 Scrapy 项目直接移动或复制到项目文件夹。
- 克隆或下载远程项目,例如 Git Clone,并将项目下载到项目文件夹。
- 通过软连接将项目链接到项目文件夹(Linux、Mac下使用ln命令,使用mklink命令)
这里我将本地的scrapy项目压缩成zip格式,进行上传。

上传完成后,点击部署按钮,进入部署页面。然后打包项目,最后部署到远程主机上。

部署完成后,可以看到远程主机上已经有了新的scrapy项目。

点击编辑按钮,也可以对项目进行在线编辑。
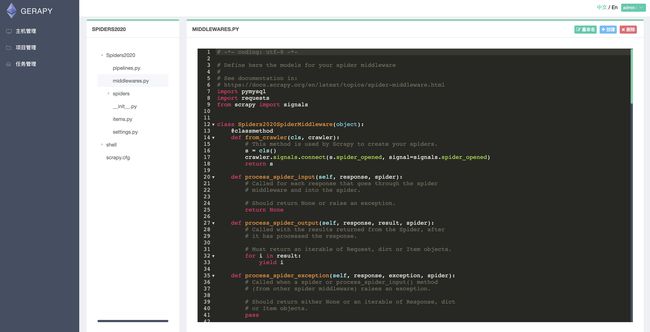
部署完成后看一下gerapy工作目录,则发现projects下多了新部署的项目。

任务管理
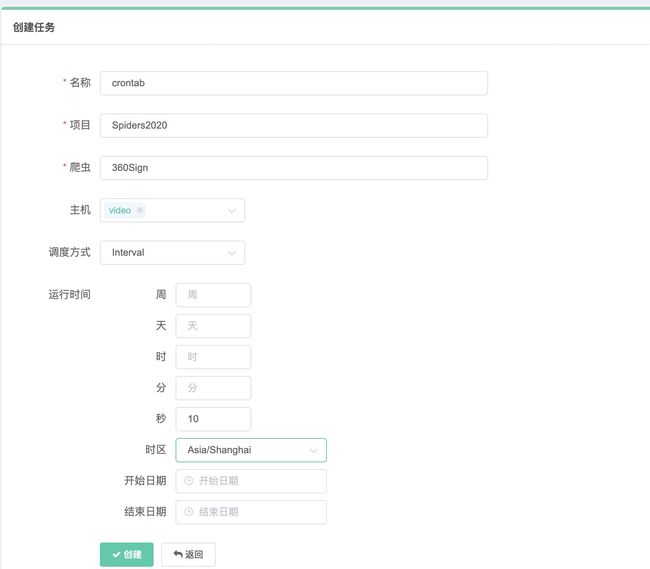
支持设置定时任务,进入任务管理菜单,新建定时任务,比如新建一个crontab模式,实现每分钟运行一次等场景。

点击编辑可以修改定时任务。
结语
本篇文章主要讲述了scrapy项目,在scrapyd和genrapy的加持下,最终实现界面化操作。这也是我觉得scrapy生态要优于原生爬虫的原因之一。
所以,爬虫并不是单纯的爬取数据,当你觉得太无聊、很没有技术含量的时候,不如在所处领域内深耕一下,寻找一些让自己感兴趣的东西。
95后小程序员,写的都是日常工作中的亲身实践,置身于初学者的角度从0写到1,详细且认真。文章会在公众号 [入门到放弃之路] 首发,期待你的关注。
