HTTP请求走私 | PortSwigger(burpsuite官方靶场)| part 1
写在前面
在开始之前,非常容易弄混的一点是,HTTP请求走私究竟发生在哪里?
答案是发生在负载均衡。开始之前,首先需要区别,负载均衡和cdn:
简单来说,负载均衡是一个反向代理,使用它的目的是能够对请求进行有效的分发。因为当前服务器都是分布式的,对于请求也必须做出区分,在负载均衡的两侧分别是请求池和服务器池,它就是通过各种简易或复杂的算法进行分发请求至最优策略的服务器。对于用户来说,仅仅是将请求发往这个代理,无需管后面的,而对于后端数据库,也不管是哪一个用户来进行调度数据,服务器自己来调就行,有着明显的分隔。
负载均衡的判定条件是依赖于ip和http头,但在现在,为了更好的分发,对于http头使用非常多,只有将分发条件给的更多,才能够提高分发的准确度。例如一个用户需要查看她的购买记录,有一个服务器带有她的缓存,此时,可以采用cookie来作为一个判断依据,让判断更加有效。
CDN内容分发网络工作的关键是DNS,它是在本身服务不变的基础上提供的额外服务,它主要用来存储许多笨重的资源,当一个请求发生时,例如:http://example.com/index.php 首先DNS会解析主站,然后去索引资源。关键就在这里,这里的dns服务器会同时作为cdn服务器使用,它并不会返回一定的ip地址,会返回最优的CDN的ip。不过通常情况下,会正常解析主站的ip(这样主站ip就不会变来变去),但是剩下的静态资源请求或者点击任意超链接产生的请求就会对cdn请求。像这样,面对请求来区分cdn请求还可以进行有效的隔离,将笨重的静态资源给cdn处理,但是敏感的管理权限,其他小型请求仍然给主站。这样,cdn的服务提供就单独分层了,从供应者和用户视角体验都变好了。
同时cdn可以迅速扩大网站的服务能力,当请求较少时,使用的cdn也会减少,当流量激增时,可以瞬间使用所有cdn,快速缓解流量。
负载均衡和cdn可以同时使用,目的都是减少流量压力。区别也非常明显,前者不那么独立,通常要使用http中的信息来作为下一步的判断,而cdn是技术较为成熟的独立服务,通常由一些公司来专门提供该服务。
如果你想更详细的了解,补充资料链接:
补充资料
回到请求走私上,问题究竟出在哪呢?
一系列的请求传到前端服务器后,负载均衡会区别一个一个的请求,HTTP规范使用了两种方法来说明请求结束的点,Content-Length标头和Transfer-Encoding标头。
由于 HTTP 规范提供了两种不同的方法来指定 HTTP 消息的长度,因此单个消息可能同时使用这两种方法,从而使它们相互冲突。HTTP 规范试图通过声明如果Content-Length和Transfer-Encoding标头都存在,Content-Length则应忽略标头来防止此问题。当只有一个服务器在运行时,这可能足以避免歧义,但当两个或多个服务器链接在一起时就不行了。在这种情况下,出现问题的原因有两个:
某些服务器不支持Transfer-Encoding请求中的标头。
Transfer-Encoding如果标头以某种方式被混淆,则可以诱导某些支持标头的服务器不处理它。
如果前端和后端服务器在(可能被混淆的)Transfer-Encoding 标头方面表现不同,那么它们可能会在连续请求之间的边界上存在分歧,从而导致请求走私漏洞。
cl即content-lenth;te即transfer-encoding
解析方式不同对应出来也就是 cl-cl;cl-te;te-cl;te-te
对于cl-cl,情况比较特殊,就像这样
POST / HTTP/1.1
Host: example.com
Content-Length: 8
Content-Length: 7
12345\r\n
a
如果前端服务器,解析前一个cl,那么请求体正常传输,如果后端服务器识别的第二个,就会忽略掉a,a只能在原地等待继续传输,当下一个请求来临时,就会附在下一个请求之前,比如变成这样:
aGET /index.html HTTP/1.1
Host: example.com
下一个传输就失败了,但是它无法达到入侵,攻击的目的,只能对请求进行干扰。这种情况在这里不做讨论
在现实生活中,双重内容长度技术很少起作用,因为许多系统明智地拒绝具有多个内容长度标头的请求。相反,我们将使用分块编码来攻击系统——这次我们有规范RFC 2616:
如果接收到的消息同时带有 Transfer-Encoding 头字段和 Content-Length 头字段,则必须忽略后者。
由于规范隐式允许使用Transfer-Encoding: chunked和Content-Length处理请求,因此很少有服务器拒绝此类请求。每当我们找到一种方法来隐藏链中的一个服务器的 Transfer-Encoding 标头时,它将回退到使用 Content-Length,我们可以使整个系统不同步。
最后,还需要了解content-lenth和transfer-encoding的一些东西。首先需要说明长连接。长连接是使用http头中的connection: keep-alive。对于非持久连接,浏览器可以通过连接是否关闭来界定请求或响应实体的边界;而对于持久连接,这种方法显然不奏效。尽管我已经发送完所有数据,但浏览器并不知道这一点,它无法得知这个打开的连接上是否还会有新数据进来,只能傻傻地等了。
要解决这个问题,最容易想到的办法就是计算实体长度,并通过头部告诉对方。这就要用到 Content-Length 了。通常如果 Content-Length 比实际长度短,会造成内容被截断;如果比实体内容长,会造成 pending。
但是有的时候实体长度并没有那么好得到,比如一个网络文件,或者动态语言生成,就必须开出足够的buffer来计算,所以我们还需要不依赖头部的长度信息,也能知道实体边界的方法。
这就是,Transfer-Encoding: chunked
到现在,这个http头就只有这一种对应值,工作方式非常简单,就是每个分块包含十六进制的长度值和数据,长度值独占一行,长度不包括它结尾的 CRLF(\r\n),也不包括分块数据结尾的 CRLF。最后一个分块长度值必须为 0,对应的分块数据没有内容,表示实体结束。
就像这样:
sock.write('HTTP/1.1 200 OK\r\n');
sock.write('Transfer-Encoding: chunked\r\n');
sock.write('\r\n');
sock.write('b\r\n');
sock.write('01234567890\r\n');
sock.write('5\r\n');
sock.write('12345\r\n');
sock.write('0\r\n');
sock.write('\r\n');
这个时候它就可以压缩后再分块传输,非常方便
如果你想更详细的了解这方面的内容,可以查看:
补充资料
HTTP request smuggling, basic CL.TE vulnerability
第一题是cl-te,前端服务器识别cl,后端识别te。
答案就是将下图的包发送两次,即可完成攻击。(这里操作和攻击思路都会详细讲解,后续不会再仔细说明)
(bp使用小技巧:首先你可以打开一开始的\n按钮,这可以帮助你看清cl的构成,除了手动的写包,首先你可以右键直接更改请求方式。不需要你自己数cl,当你发包时会自动进行计数)

如果你想使用官方建议的插件 HTTP Request Smuggler,安装后按以下操作
1.首先切换请求方式
2.convert to chunked 出现头部,准备使用http smuggling攻击
3.选择攻击模式,就会打poc,在成功的poc中替换一下就可以了
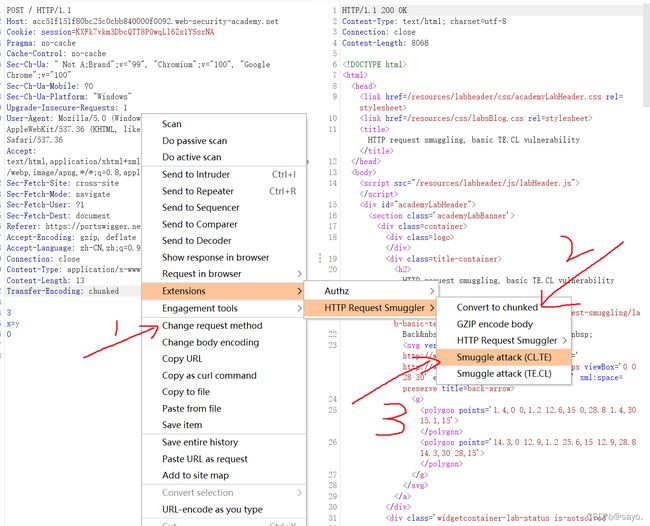

详细说明:
这个漏洞的关键就在于识别标准的不统一。第一次识别是cl,第二次识别是te,由于这种差异,就会有数据未被识别到,从而导致偷渡到后端。
在cl-te中,cl是第一道门槛,就必须保证cl能够正常工作,但是在body中先带入了0,在第二道门槛te中就被识别为传输截止了,此时G就在缓冲区继续等待,在下一个请求到来时被附在了下一个请求前,对下一个请求造成了污染,G这个数据就偷渡到了下一个请求,攻击就完成了。
操作的关键就是对包的修改,自然,用工具来完成是非常好的,同时还可以进行一定的fuzz,自动化发包比我们一个一个包发出去效率高得多。操作思路无论手动或自动,大体都是差不多的。
1.首先切换请求方式,因为你要传输数据
2.加入cl/te,你需要的http头
3.更改payload,达到你想要的效果
自动化工具,可以直接打poc,查看包的状态可以识别是否出现这个漏洞,但也需要仔细观察。除了被动扫描,还可以辅助改包,针对你已经知道漏洞的情况下进行定向攻击。
HTTP request smuggling, basic TE.CL vulnerability
拦截操作,重复上述操作,选择te.cl攻击,开始打poc

poc验证成功
更换payload,就可以达成实验室的结果

GPOST如下:

这里是让下一个请求成为body,不是直接附在前面,这是因为前端验证时靠的te,te结尾必是一个0,无法达到要求,就让0变成body,取消对请求方式的篡改。
HTTP request smuggling, obfuscating the TE header


发送两次
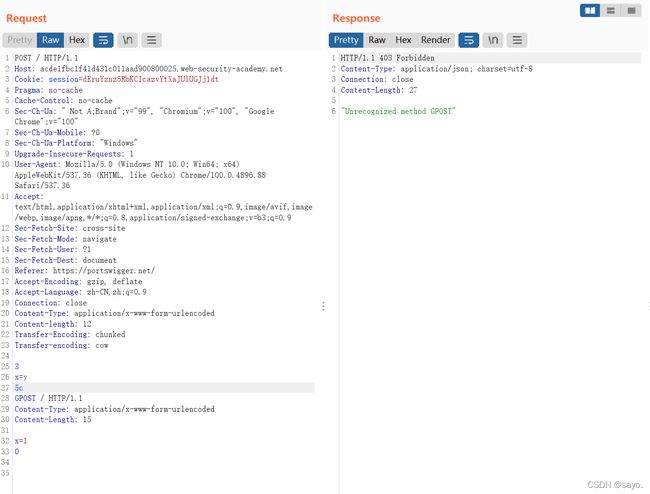
在这里,前端和后端服务器都支持Transfer-Encoding标头,但是可以通过以某种方式混淆标头来诱导其中一个服务器不处理它,也就是从te-te转化为了te-cl,就能够完成和上一次一样的攻击方式,混淆的方式很多,比如换行,不同的单词,大小写等等。最好的方式就是进行fuzz。
寻找http请求走私漏洞
前面都是在告诉你漏洞出现的方式的情况下进行攻击,这里来告诉你如何寻找这样的漏洞。一开始只给出了攻击方式,探测也是非常重要的
Finding HTTP request smuggling vulnerabilities using timing techniques
检测 HTTP 请求走私漏洞最有效的方法是发送请求,如果存在漏洞,将导致应用程序响应的时间延迟。Burp Scanner使用此技术来自动检测请求走私漏洞
如果应用程序容易受到请求走私的 CL.TE 变体的攻击,那么发送如下请求通常会导致时间延迟:
POST / HTTP/1.1
Host: vulnerable-website.com
Transfer-Encoding: chunked
Content-Length: 4
1
A
X
由于前端服务器使用Content-Length标头,因此它将仅转发此请求的一部分,省略X. 后端服务器使用Transfer-Encoding标头,处理第一个块,然后等待下一个块到达。这将导致可观察到的时间延迟。
如果应用程序容易受到请求走私的 TE.CL 变体的攻击,那么发送如下请求通常会导致时间延迟。
POST / HTTP/1.1
Host: vulnerable-website.com
Transfer-Encoding: chunked
Content-Length: 6
0
X
由于前端服务器使用Transfer-Encoding标头,因此它将仅转发此请求的一部分,省略X. 后端服务器使用Content-Length标头,期望消息正文中有更多内容,并等待剩余内容到达。这将导致可观察到的时间延迟。
这样的时间探测原理都是让后端服务器认为还有数据等待传输,等待时便会产生时间延迟
但是,这样并不能准确的判断此时就发生了走私请求,需要结合下面的响应差异判断
HTTP request smuggling, confirming a CL.TE vulnerability via differential responses
这里就是第一个时间探测的拓展,将无效信息替换为一个新的请求,这个请求将请求一个不存在的资源。如果此时响应了走私请求,就会产生这个请求,导致出现响应差异,第一次为200,第二次为404

非常典型,直接poc吧,用于确认cl-te
这里必须要提到那个插件,使用插件打poc真的非常方便,选择探测cl-te即可
HTTP request smuggling, confirming a TE.CL vulnerability via differential responses

以下为官方提示:
“攻击”请求和“正常”请求应该使用不同的网络连接发送到服务器。通过同一连接发送两个请求并不能证明漏洞存在。
“攻击”请求和“正常”请求应尽可能使用相同的 URL 和参数名称。这是因为许多现代应用程序根据 URL 和参数将前端请求路由到不同的后端服务器。使用相同的 URL 和参数会增加请求由相同的后端服务器处理的机会,这对于攻击起作用至关重要。
在测试“正常”请求以检测来自“攻击”请求的任何干扰时,您正在与应用程序同时接收的任何其他请求竞争,包括来自其他用户的请求。您应该在“攻击”请求之后立即发送“正常”请求。如果应用程序很忙,您可能需要执行多次尝试来确认漏洞。
在一些应用中,前端服务器充当负载均衡器,根据某种负载均衡算法将请求转发到不同的后端系统。如果你的“攻击”和“正常”请求被转发到不同的后端系统,那么攻击就会失败。这是您可能需要多次尝试才能确认漏洞的另一个原因。
如果您的攻击成功干扰了后续请求,但这不是您为检测干扰而发送的“正常”请求,那么这意味着另一个应用程序用户受到了您的攻击的影响。如果您继续执行测试,这可能会对其他用户产生破坏性影响,您应该谨慎行事。