python 常用知识点
文章目录
- Python 概述
- 内置对象、运算符、表达式、关键字
- Python 序列结构
- 选择结构与循环结构
- 函数
- 面向对象程序设计
- 字符串
- 正则表达式
Python 概述
- 标准库与拓展库中对象的导入与使用
(1)import 模块名 [ as 别名 ]
//使用时用’模块名.对象名’的形式访问
(2)from 模块名 import 对象名 [ as 别名 ]
//从模块中仅仅导入你想要的对象,可以直接使用对象
(3)from 模块名 import *
//一次导入模块中全部的对象- _ _ name _ _ 属性: (识别程序的使用方式)
(1)如果程序被作为模块被导入,其_ _ name _ _ 属性的值被自动设置成模块名
(2)如果作为程序直接运行,其_ _ name _ _ 的属性的值就被自动设置成 “_ _ main _ _”
内置对象、运算符、表达式、关键字
- python 中一切都是对象,例如整数,实数,列表,元组等,zip ,map 等函数也是对象,函数和类也是对象
- 对象类型:
(1)数字:大小没有限制,支持复数运算 (3+2j)
(2)字符串:使用单引号,双引号,三引号作为定界符,可以嵌套,使用r或R 表示引导原始字符串
(3)字节串: 用 字母b 引导 (b’hello’)
(4)列表:list ,元素在方括号中,元素用逗号隔开,元素可以为任意类型
(5)元组:tuple ,元素在圆括号中,元素用逗号隔开,只有一个元素时,逗号不能省略(3,)
(6)字典:dict ,元素在大括号中,按照"键:值"形式,其中键不可以重复,键必须不可变
(7)集合:set ,所有的元素在大括号中,元素之间用逗号隔开,元素不可以重复且必须为不可变类型
(8)布尔类型:bool ,True 或者False- 在python 中,变量的值和类型都可以变,不需要事先声明变量名以及类型,赋值语句可以直接创建任意类型的变量(python 中变量并不直接存储值,而是存储值得内存地址或者引用)
- 变量名得命名:
(1)以字母和下划线开头
(2)变量名中不能有空格或者标点符号
(3)不能使用关键字作为变量名,不建议用系统内置得模块名等命名
(4)大小写敏感
- 对于数字类型:尽量避免实数直接比较大小,而是以绝对值来比较。为了提高可读性,可以在数字中中增加下划线,下划线可以出现在数字中间得任意位置,不能在开头和结尾,不能连续出现
- python 没有字符变量以及字符常量,就是单个字符也是字符串
- 运算符:优先级:
算术运算符>位运算符>成员测试运算符>关系运算符>逻辑运算符
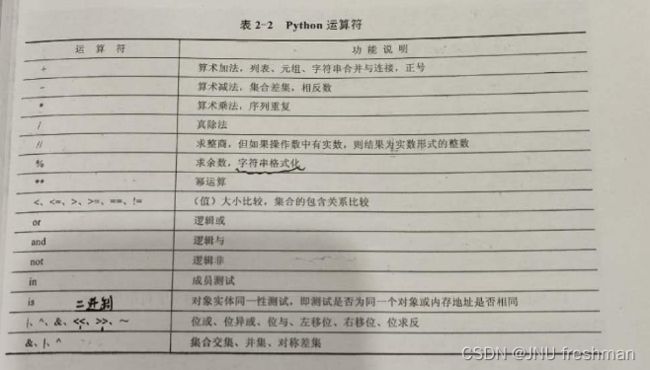
print([1,2,3] + [ 4,5])
print((1,) + (2,3))
print([1,2,3]*3)
print(15/4)
print(15.0/4)
print(15//4)
print(15//4.0)
print(-15//4)

- 取余数是向下取整
- 关系运算符:可以连用,但是操作数必须能够可以比较大小
'hello' > 3 //错误,字符串和数字不能比较大小
[1,2,3] < [1 ,2,4] //True ,列表比较大小
{1,2} < { 1,2,3} //True ,集合用来查看是否为子集,相等关系
- 成员测试符: in ,用于测试一个对象是否包含另一个对象
3 in [1,2,3] //True
5 in range(1,10,1) // True
for i in(3,5,7): //成员遍历
print(i)
- 集合运算符:交集,并集,对称差集,集合差集:&, | ,^ , -
- 逻辑运算符: and,or,not ,(其中 and 与 or 有惰性求值和逻辑短路的特点)
and 和 or 的值不一定是 True 或者False ,会把最后一个计算的表达式作为自己的值
3>5 and a>3 与 3>5 or a > 3 //前者为False ,后者会报错,a 没有被定义
3 and 5 //值为 5
3 and 5>3 //值为 True ,
- 常用内置函数:
(1)char(x) //返回Unicode 编码的为 x 的字符
(2)enumerate ( iterable[ , start])
(3)input([提示]) //显示提示,接收键盘输入的内容,返回字符串
(4)isinstance(obj,type) //检查测试对象obj 是否属于指定的类型
isinstance(3,int) //True
(5)len(obj) ,求对象obj 的元素的个数
(6)list(x) ,set(x),tuple(x),dict(x) ,将x 转化为 列表,集合,元组,字典,并返回
(7)map(func,*iterables),将迭代器对象都运用func 函数,并返回,map 函数不对原来的序列做更改
def dou ( b ):
return b*2
a = [2,5,9,7,4]
c = map(dou,a)
print(list(c))
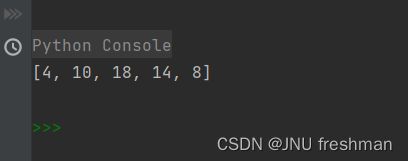
//双参数
def add(x,y):
return x+y
result = map(add,range(5),range(10,15))
print(list(result))

(8)max( ),min ( ) ,sum()返回最大值,最小值,求和
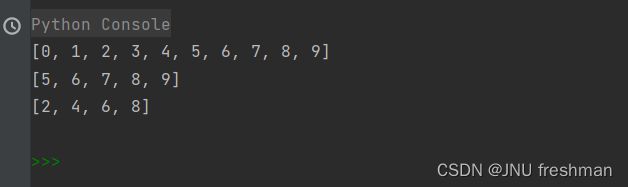
(9)range(start,end,step) //返回range 对象,其中包含[start,end) ,步长为step 的整数,range 默认从 0 开始,step 默认为1,list(range(5)) 为[0,1,2,3,4]
# 默认有range(stop),range(start,stop),range(start,stop,step)
print(list(range(10)))
print(list(range(5,10)))
print(list(range(2,10,2)))
(10)reversed(seq) //返回seq 中全部元素逆序的迭代器对象
(11)sorted(iterable,key=None,reverse = False) //返回排序后的列表,iterable 是相应的对象,key 为排序规则, reverse 用来指定升序还是降序)(False 是升序排序,True 是降序排序)
(12)str(obj) //将obj 对象直接转换成字符串
(13)type(obj) //返回类型
(14)zip(seq1,seq2 ···) //返回zip 对象,其中的元素为每一个对象的交替出现(相应位置的元素压缩在一起),结果是一个相对应元素的元组,长度取决于最短的那个对象
a = ['a','b','c','d']
b = [1,2,3,4,5]
c = zip(a,b)
print(list(c))
print(list(c)) //得到的迭代器对象只能使用一次,
//迭代器 c 的内部状态已经到达了末尾

a = [0,1,2,3,4,5,6]
print(list(zip(a)))
//每一个元素得元组 [(0, ) ,(1,),(2,),(3,)(4,),(5,),(6,)]
(15)
filter(func,seq)//返回filter 对象,其中包含序列seq 中使得 func 函数为True 的那些元素,如果func 为none ,则返回seq 中等价于True 的元素
def cpy (a):
return a>5
//筛选数字
num = [1,5,9,7,3,6]
result = filter(cpy,num)
print(list(result))

(16)eval(s) //计算字符串s 的表达式的值,并返回结果
- 基本的输入输出:input / print ,不论输入什么,input() 一律作为字符串,必要时可以使用 内置函数 int(),float()或者eval()对输入进行转换
- print(value1,value2,····valuen,sep=" ",end = ‘\n’)
sep指定每个元素的分隔符,默认为空格,end 为最后的操作,默认情况下为换行)
- 排序和逆序:sorted 的key 值可以用lambda 表达式 ,reversed()翻转
- 枚举和迭代:enumerate()函数可以用来
枚举可迭代的对象中的元素,返回可迭代的enumerate对象,其中每一个元素都是包含索引和值的元组,可以将enumerate 对象直接转换成 列表、元组、集合,也可以使用for 循环直接遍历其中元素
print(list(enumerate('abcd')))
print(list(enumerate(["abc","bcd"])))
for index,value in enumerate(range(10,15)):
print((index,value),end=" ")

- reduce() 函数将一个接收两个参数的函数以迭代累计的方式从左到右依次作用到一个序列的全部元素上,并且允许指定一个初始值
from functools import reduce
//计算阶乘 (((((1*2)*3)*4)*5)
result = reduce(lambda x,y:x*y ,range(1,6));
print(result)
注意,enumerate ,map,filter ,zip 函数返回的迭代器对象只能使用一次,访问过后就不存在了
Python 序列结构

- 列表:数据收纳盒。列表里面的元素可以互不相同,可以同时包含整数、实数、字符串等,也可以包含列表、元组等
# 字符串改成列表
print(list('anbcdj'))
# 元组变成列表
print(list((1,2,3,4)))
# 字典的键变成列表
print(list({'a':11,'nihao':12,'asd':13}))
# 字典的元素变成列表
print(list({'a':11,'nihao':12,'asd':13}.items()))

- 列表的删除 用
del- 列表元素的访问:
正向索引,0表示最后一个元素,反向索引,-1表示最后一个元素
a = [0,1,2,3,4,5,6]
print(a[6])
print(a[-1])
# 都是输出6
- 列表常用方法:
(1)append(x) //将x 追加至列表的尾部
(2)extend(L) //将列表L 中的全部的元素追加至 列表的尾部
(3)insert(index,x) //在列表的 index 处插入 x
(4)remove(x) //删除列表的第一个元素,当第一个元素不存在就抛出异常
(5)pop(index) //删除并返回列表中下标为index 的元素
(6)index(x) //返回列表第一个元素的索引
(7)count(x) //返回 元素x 在列表中出现的次数
(8)reverse() //对列表的全部元素进行原地逆序
(9)sort(key = None, reverse=False) //对列表的元素进行原地排序,key 用来指定排序规则, reverse = False 表示升序,True 表示降序)
区别于内置函数sorted(iterable,key,reverse)
a = [0,1,2,3,4,5,6]
b = sorted(a,reverse=True)
print(b)
a.sort(key=None,reverse=True)
print(a)
# sorted 是返回一个排序的对象,但是sort 是在自身的基础上排序
- 列表的内存有自动收缩和扩张的功能,在列表中插入和删除元素,会导致下标的对应得变化
- 列表推导式:可以快速使用简洁的方法对列表以及其他可以迭代的对象的元素进行遍历,过滤,或者再次计算,快速生成满足需求的新的列表(
在逻辑上相当于一个循环语句)[expression for expr1 in sequence1 if condition 1 for expr2 in sequence2 if condition 2 ····· for exprN in sequenceN if condition N ]
a = [x+x for x in range(20) if x % 2 ==0]
print(a)
# [0, 4, 8, 12, 16, 20, 24, 28, 32, 36]
a = [[1,2,3],[4,5,6]]
b = [num for elem in a for num in elem] //如何理解? 从正常的两重循环的角度去看即可
print(b)
# [1, 2, 3, 4, 5, 6]
a = [1,2,3,4]
b = [4,5,6]
c= [(x,y) for x in a for y in b]
print(c)
c= [(x,y) for x in a if x ==2 for y in b]
print(c)
#[(1, 4), (1, 5), (1, 6), (2, 4), (2, 5), (2, 6), (3, 4), (3, 5), (3, 6), (4, 4), (4, 5), (4, 6)]
#[(2, 4), (2, 5), (2, 6)]
- 切片:
[start : end : step]
start 是切片开始的位置 , end 是切片结束的位置,step 是切片的步长 , 其中 [ start ,end )不包含 end ,start 默认值为 0 ,end 默认值为列表的长度,step 的默认值为1 ,与 range 的用法极为相似
切片不会因为超出列表的边界而抛出异常,而是简单的在末尾截断- [ : : ] 返回原来的列表,[ : : -1] 返回逆序列表
- 使用切片为列表增加元素
a = [1,2,3]
a[len(a):] = [9] # 表尾插入
print(a)
a[:0] = [0] # 表头插入
print(a)
a[2:2] = [88] # 中间插入
print(a)

# 列表的插入也同理
a = [1,2,3]
a[:1] = [4,5,6]
//a 变成 [4,5,6,2,3]
//要是想删除的话,就赋值为[ ]
- 元组:元组可以看成列表的简化版,元组也支持双向索引,支持通过下标来访问特定的元素
tuple- 元组与列表的异同点:都是有序序列,但是元组属于不可变序列,无法修改元组的内容,只能通过切片来访问元素,列表可以修改,元组可以作为字典的键,也可以作为集合的元素(不可变),但是列表不行
- 生成器表达式:与列表推导式类似,但是生成器对象的结果是一个生成器对象,具有惰性求值的特点。形式上,是列表推导式的中括号换成圆括号
- 生成器对象的遍历:可以用生成器对象的 _ _ next _ _ 或者 next() 遍历以及for 循环直接遍历,只能从前往后遍历,没有办法再次访问访问过的元素,不支持下标来访问(童enumerate 、 filter 、 map 、 zip 等迭代器的对象)
- 字典:一种无序可变序列。键为不可变元素,键不可以重复,值可以重复
x = dict(zip('abc',[1,2,3,4]))
print(x)
# {'a': 1, 'b': 2, 'c': 3}
- 字典的访问:
x = dict(zip('abc',[1,2,3,4]))
print(x['a'])
print(x.get('d','not find')) //允许在找不到键时,按照设定的默认值返回
- 对字典进行遍历和迭代的时候,默认情况下是遍历字典的键,{ }.values() 是对字典的值进行遍历,
{ }.items() 是对整个字典元素进行遍历
x = dict(zip('abc',[1,2,3,4]))
for item in x:
print(item,end = ' ')
print()
for item in x.items():
print(item,end = ' ')
print()
for item in x.values():
print(item,end = ' ')
#a b c
#('a', 1) ('b', 2) ('c', 3)
#1 2 3
- 字典的添加与修改:以指定的键为下标 ,并赋值,要是该键不存在,就增加该键值对,要是存在,就修改值
- 集合:无序可变序列,元素唯一。可以使用set() 将其他对象转化为集合,当有元素重复的时候只保留一个
- 集合的增加:
(1)add(x) 增加元素(若元素以及存在,怎会忽略,不会报错),update( s),将另一个集合合并到当前集合,自动删除重复元素
import random
# 获取一定数量的在一定范围内的整数
start = int(input("请输入下边界"))
end = int(input("请输入上边界"))
sum = int(input("请输入你想要的数据的个数"))
def getnumber (start,end,sum):
currentnum = set()
while len(currentnum) <= sum:
elem = random.randint(start,end)
currentnum.add(elem)
return currentnum
data = getnumber(start,end,sum)
print(data)
- 集合删除:
pop() 用于随机删除一个元素并返回 remove(x) 用于删除集合中的x- 集合也可以运用len,max,min,sorted,map等函数
- <,>,=,<=,>= 用于表示集合的包含关系
- 序列解包:对多个变量进行同时赋值,要求等号左边的变量的数量和等号右边的变量的数量必须一致
x,y,z = 1,2,3
print(x,y,z)
x,y =y,x # 两个变量即可完成交换
print(x,y,z)
x,y,z = 'ABC'
print(x,y,z)
#1 2 3
#2 1 3
#A B C
选择结构与循环结构
- 条件表达式:条件表达式的值只要不是False ,0,None ,空列表,空集合,空字典等,都会被解释器认为与True 等价
- 条件表达式运行连续比较:1<2<3 ,条件表达式中不允许有赋值语句
=- and 要求两侧的值都要为True,or 要求一个为True,not 而言,后面为False
- 单分支选择: if 表达式: 语句块
- 双分支选择: if 表达式: 语句块 else :语句块
- 三元运算符: value1 if condition else value2 (if 成立时为value1,否则为 value2)
- 多分支同理, else if 可以简写 为 elif
- 循环结构:for 循环 和while 循环,循环结构可以带else ,当循环因为条件表达式不成立或者序列遍历结束而自然结束时,才会执行else 结构的语句,如何是因为break 而结束的,那么就不会执行 else 语句
for i in range(1,101):
if i%7==0 and i%5!=0:
print(i,end=' ')
# 输出被7整除,不能被5整除
- break 和 continue 语句:break 语句是终止所在层的循环,continue 只是终止本次循环,提前进入下次循环
# 找100以内的素数
for i in range(2,101):
flag = 0
for j in range(2,i):
if(i%j==0):
flag = 1
break
if(flag==0):
print(i)
函数
- 函数语法:
def 函数名 ([参数列表]):
函数体注意:
(1)形参不用指定类型,系统会更具实参来确定
(2)不需要指定函数的返回类型,这由return 语句来决定
(3)及即使不接收任何参数,括号都不能省略,头部的冒号不可以省略
(4)函数体相对于def 关键字要有缩进
# 输出小于n 的斐波那契数列
def fibonacci (n):
a,b = 1,1
while(a<n):
print(a,end=' ')
a,b = b,a+b
num = int(input("请输入一个整数"))
fibonacci(num)
- 递归调用:自己调用自己
- 函数参数:位置参数:调用参数时,实参与形参的顺序一致,数量相同;默认值参数:可以在函数的形参中定义参数的值,如果实参没有覆盖,则可以使用设定的值
- 关键参数:通过关键参数可以按照参数的名字来传递值,明确哪一个值传递给哪一个参数,实参顺序和形参的顺序不一致也不会影响最后的传递结果
def demo (a,b,c=5):
print(a,b,c)
demo(3,4)
demo(3,4,8)
demo(a=7,b= 6,c=5)
demo(b=2,a=3,c=7)

- 可变长度参数: 分为 *parameter 和 **parameter
前者接收任意多个位置参数并放入一个元组中,后者接收多个关键参数并将其放入字典中
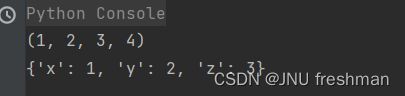
def demo (*p):
print(p)
demo(1,2,3,4)
def demo2 (**p):
print(p)
demo2(x=1,y=2,z=3)
- 传递参数时的序列解包:实参加上* 或者 **
前者给列表,元组,集合,字典都可以解包,后者可以对字典进行解包,形成关键参数那样
- 变量的作用域:如果想要在函数内部修改一个定义在函数外的变量值,必须使用global明确声明,不然就是创建一个新的变量,如果局部变量与全局变量有相同的名字,那么在局部变量的作用域中会暂时隐藏同名的全局变量
- lambda 表达式:声明匿名函数,也就是没有函数名字,临时使用的小函数。lambda 表达式只可以包含一个表达式,不允许包含复杂的语句和结构,但是在表达式中可以调用其他函数,该表达式的计算的结果相当于函数的返回值。
import random
a = list(range(20))
random.shuffle(a)
print(a)
a.sort(key = lambda x:len(str(x)))
# 按照所有的元素转化为字符串的长度进行升序排序
print(a)
- 生成器函数:包含yield 的语句可以用来创建生成器对象,这样的函数被称为生成器函数。yield 与return 一样都会返回一个值,不过return 在返回一个值的同时,函数也会立即结束运行,yield 不同,每次执行到yield 语句的时候会在返回一个值之后会暂停或者挂起后面的代码的运行,下次通过生成器对象的
_ _ next _ _()方法,内置函数 next() ,for 循环遍历生成器对象元素或者其他显示所要数据时恢复执行
def f():
a,b=1,1
while True:
yield a
a,b = b,a+b
# 创建生成器对象
m = f()
# 生成10个斐波那契数
for i in range(10):
print(m.__next__() ,end=' ')
print()
# 输出第一个大于100 斐波那契数
for i in f():
if i > 100:
print(i)
break

面向对象程序设计
- 类的定义与使用:
(1)类的成员包括数据成员和成员方法。
(2)以设计好的类为基类,可以继承得到派生类
(3)三个要素:封装,继承,多态
(4)定义类用class,类内部的成员方法的第一个参数必须是self
(5)定义好类之后,就可以对类进行实例化,然后通过对象名.成员来访问类中的数据成员或者成员方法- 私有成员与公有成员:
(1)私有成员:以两个下划线开头但是不以两个下划线结束的就是私有成员。私有成员在类的外部不能直接访问,一般在类的内部进行相关的操作,或者在类的外部调用成员方法来操作,但是可以通过特殊的方法直接访问私有成员对象名._类名_ _私有成员来访问
(2)公有成员可以公开使用 ,既可以在类的内部使用,又可以在外部使用
- 相关下划线:
(1)_xxx以一个下划线开头,保护成员。一般建议的类对象和子对象访问这些成员
(2)_ _ xxx使用两个下划线开头但是不以两个下划线结束,私有成员
(3)_ _ xxx _ _前后各两个下划线,系统定义的特殊成员
注意,在模块中使用一个或者多个下划线开头的成员不能用‘from modul import *’ 导入,除非在模块中使用_ _ all _ _变量明确这样的成员可以被导入
- 数据成员:可以分为属于对象的数据成员和属于类的对象数据成员
(1)属于对象的数据成员主要是在构造方法 _ _ init _ _ () 中定义,而且在定义和在实例方法中访问数据成员的时候常常以self 作为前缀,同一个类中的不同的数据成员之间相互不影响
(2)属于类的数据成员的定义不在任何的成员方法之内,是类的所有的对象共享的不属于某一个对象(类似于java 中的静态变量)
- 成员方法:分为公有方法,私有方法,静态方法,类方法。
(1)公有方法和私有方法一般指属于对象的实例方法
(2)私有方法的名字以两个下划线开始。
(3)公有方法可以通过对象名来直接调用,但是私有方法不能通过对象名来直接调用,只能在其他实例方法中通过前缀self 进行调用或者在外部通过特殊的形式调用
(4)所有的实例方法都必须有一个self 的参数,并且必须是方法的第一个形参,self 参数表示当前对象,在实例方法中访问实例成员要加上 self 为前缀,但是在外部通过对象名调用对象方法的时候不用传递这个参数(通过对象调用公有方法时,会把对象隐式绑定到self)
(5)静态方法和类方法都可以通过类名和对象名来调用,但是这两个方法并不能直接访问属于对象的成员,只能访问属于类的成员。一般以cls 作为类方法的第一个参数,表示该类的自身,在调用类方法时不需要为cls 传递参数,静态方法可以不接收任何参数。
class Root:
#私有变量,属于类
__total = 0
#属于对象的数据在init 里面定义
def __init__(self,v):
self.__value = v
Root.__total += 1
#公有方法
def show(self):
print('self.__value:',self.__value)
print('Root.__total:',Root.__total)
@classmethod # 修饰器,声明类方法
def classShowTotal(cls):
print(cls.__total)
@staticmethod # 修饰器,声明静态方法
def staticShowTotal():
print(Root.__total)
r = Root(3)
r.classShowTotal() # 通过对象来访问类方法
r.staticShowTotal() # 通过对象来访问静态方法
Root.classShowTotal() # 通过类名来访问类方法
Root.staticShowTotal() # 通过类名来访问静态方法
# Root.show() 不可以用类名来访问实例方法
r.show()
- 属性:是一种特殊形式的成员方法,综合了公开数据成员与成员方法二者的优点,既可以像成员方法那样对值进行必要的检查,又可以像数据成员那样灵活访问
- 继承:派生类可以继承父类的公有成员,不能继承父类的私有成员,如果需要在派生类中调用基类的方法,可以使用内置函数super() 或者通过
父类名.方法名()来访问
class Person(object):
def __init__(self,name,age):
self.name = name
self.age = age
def showname(self):
print(self.name )
def showage(self):
print(self.age )
def setName(self,name):
self.name = name
def setAge(self,age):
self.age = age
class Employee(Person):
def __init__(self,name,age):
self.name = name
self.age = age
if __name__ =='__main__':
ee = Employee('mike',20)
ee.showname()
ee.showage()
ee.setName('lily')
ee.showname()
ee.setAge(25)
ee.showage()
不论类名是什么,构造方法都是_ _ init _ _,析构方法都是 _ _ del _ _,分别用来创建对象时进行必要的初始化和在释放对象时必要的清理工作- 特殊方法:

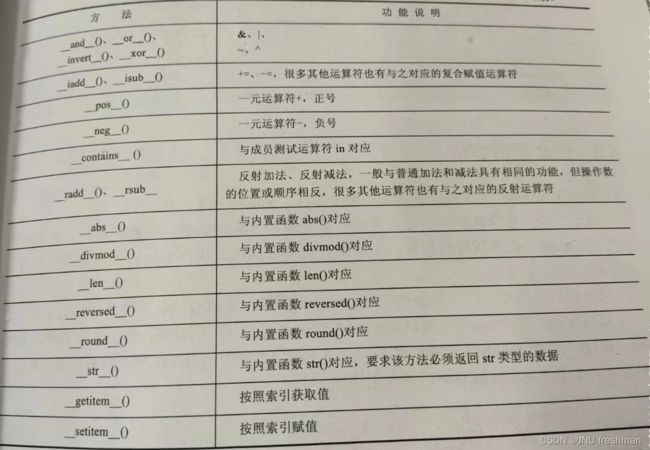
- 要想实现相关的特殊方法,(让类的对象能够运算,就必须在类的定义中实现相对应的特殊方法
class Demo:
def __init__(self,num):
self.__num = num
def __add__(self, othornum):
return self.__num + othornum
if __name__ == '__main__':
dd = Demo(2)
a = dd + 5
print(a)
# 输出7
字符串
- 属于不可变的有序序列,采用单引号,双引号,三引号的形式作为定界符,不同的定界符之间可以进行嵌套。除了支持常见的序列的通用的方法(双向索引,比较大小,计算长度,元素访问,切片,成员测试等),还支持特殊方法。不过由于字符串属于不可变序列,不能直接对字符串进行增加,删除,修改等操作,切片操作也只能进行访问,而不能进行修改。
- 字符串的对象提供的 replace() 和 translate() 方法以及大量的排版方法也不是对原有的字符串进行修改替换,而是返回一个新的字符串作为结果。
- 字符串的编码:ASCII 码采用一个字节对应一个字符进行编码,最多表示256 个符号
- UTF-8 对全世界的所有国家用到的字符都进行了编码,以一个字节表示英文的字母(兼容ASCII),以3个字节表示中文
- GB2312 是我国制定的。一个字节表示英文,2个字节表示中文
- GB2312,GBK,CP936 都是使用2 个字节表示中文
- 统计字符串的长度的时候,无论是数字,英文,汉字 都被按照一个字符来对待
# 注意转义字符的影响
a = '\'nihao'
print(len(a)) # 输出6
a = r'\'nihao'
print(len(a)) # 输出 7
- 字符串格式化:使用% 符号进行格式化

print('%o ' %10) # 转化为8进制
print('%s' % set(range(10))) # 转化为字符串
print('%d,%c' % (1,68)) # 对元组进行格式化
#12
#{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
#1,D
- 使用foemat() 方法进行字符串的格式化 ,就是在原来的基础上应该替换的内容是增加{ } ,然后在整体的后面加上
.format(),format() 括号里面的值就是要进行格式化的值
print("{1} ,hello ,I am your {0}".format('friend','Mike'))# 可以指定得到哪一个值,其中序号从0开始
#输出Mike ,hello ,I am your friend
#print('5 的八进制是{1:%o},10 的16 进制是{0:%x}'.format(10,5)) 错误写法,没有%
print('5 的八进制是{1:o},10 的16 进制是{0:x}'.format(10,5))
# 输出5 的八进制是5,10 的16 进制是a
- 格式化字符串常量:大括号表示占位符,会将前面的定义的同名的变量的值对格式化字符串的占位符进行替换
有f
name = 'Mike'
age = 10
print(f'{name} is {age} years old')
# 输出Mike is 10 years old
- 字符串常用的方法与操作:
(1)find()查找一个字符串在另一个字符串中第一次出现的位置,不存在则返回-1
(2)rfind() 查找一个字符串在另一个字符串最后一次出现的位置,不存在则返回-1
(3)index() 和 rindex() 分别返回一个字符串在另一个字符串中首次出现和最后一个出现的位置,如果不存在则抛出异常
(4)count() 返回一个字符串在另一个字符串中出现的次数,不存在则返回0
fruits = "banana,apple,peach,banana,pear"
print(fruits.find('apple'))
print(fruits.rfind('banana'))
print(fruits.count('banana'))
print(fruits[7:12])
#7
#19
#2
#apple
- (5)split() 和 rsplit() 方法分别从字符串的左端和右端开始,以指定的字符作为分隔符,将原来的字符分隔成多个字符,并返回包含分隔结果的列表
如果不指定分隔符,那么字符串中任何空白符号(包含空格,换行符,制表符等)的连续出现都被认为是分隔符
fruits = " ba nana, apple,p each,ban ana,pear"
print(fruits.split()) # 默认情况
print(fruits.split(' ')) # 以空格为分隔符
print(fruits.split('a')) # 以字符a 为分隔符
print(fruits.rsplit(' ')) # 以空格为分隔符
#['ba', 'nana,', 'apple,p', 'each,ban', 'ana,pear']
#['', 'ba', 'nana,', 'apple,p', 'each,ban', 'ana,pear']
#[' b', ' n', 'n', ', ', 'pple,p e', 'ch,b', 'n ', 'n', ',pe', 'r']
#['', 'ba', 'nana,', 'apple,p', 'each,ban', 'ana,pear']
- (6)partition() 和rpartition() 方法用于以指定的字符串作为分隔符将原来的字符串分成三部分,即 分隔符之前的字符串,分隔符字符串,分隔符之后的字符串,如果指定的字符串不存在,则返回原来的字符串和两个空字符串,如果有多个字符串与分隔符相同,那么partition()在从左边到右边的第一个,rpartition() 则是右边第一个
s = "banana,apple,pear,apple"
print(s.partition('apple'))
print(s.rpartition('apple'))
#('banana,', 'apple', ',pear,apple')
#('banana,apple,pear,', 'apple', '')
- join()用来将列表中多个字符串进行连接,并在相邻的两个字符串之间插入指定的字符,返回新的字符串
# 结合split 和 join 将字符串中多余的空白字符删除
x = "aaa bb c d e fff"
x1 = x.split()
print(x1)
x2 =' '.join(x1)
print(x2)
#['aaa', 'bb', 'c', 'd', 'e', 'fff']
#aaa bb c d e fff
- lower() ,upper() ,capitalize() ,title() ,swapcase() 分别将全部字符变为小写,全部字符变成大写,将字符串的首字符变成大写,将每个单词的首字母变成大写,大小写互换
s = "Hello world"
s1 = s.lower()
s2 = s.upper()
s3 = s.capitalize()
s4 = s.title()
s5 = s.swapcase()
print(s1)
print(s2)
print(s3)
print(s4)
print(s5)
#hello world
#HELLO WORLD
#Hello world
#Hello World
#hELLO WORLD
- replace() 用来替换字符串中指定字符或字符串的全部出现,每次只能替换一个字符或字符串,把指定的字符串参数当成一个整体,类似于记事本的查找替换功能,结果会返回一个新的字符串
words = " 我喜欢编程设计"
newwoeds = words.replace('喜欢','love')
print(newwoeds)
#我love编程设计
- maketrans() 方法用于生成字符映射表,而translate() 可以根据映射表定义的对应的关系转换字符串并替换其中的字符,使用两个方法结合可以同时处理多个不同的字符
类似于编码
words = " 我喜欢编程设计,设计我哇"
table = ''.maketrans('我喜欢编程设计','你把电脑带上去')
newwords = words.translate(table)
print(newwords)
# 你把电脑带上去,上去你哇
- strip() ,rstrip(),lstrip() 分别用于删除两端,右端,左端连续的空白字符或者指定字符
words = "aaaaahjdjkhkjaaaa"
print(words.strip('a'))
print(words.lstrip('a'))
print(words.rstrip('a'))
#hjdjkhkj
#hjdjkhkjaaaa
#aaaaahjdjkhkj
- startwith() ,endwith() 分别用来判断字符串是否以指定的字符串开头或者结束,可以接受两个整数参数来指定字符串的检测范围
words = 'Hello world every day!'
print(words.startswith('He'))
print(words.startswith('He',5))# 指定开始检测的位置
print(words.startswith('He',0,5)) # 指定检测的范围
#True
#False
#True
- isalnum(), isalpha() ,isdigit() ,isspace(), isupper() ,islower()检测字符串是否为 字母或者数字 ,是否为字母 ,是否为整数字符 ,是否为空白字符 ,是否为大写字母 ,是否为小写字母
- center() ,ljust () ,rjust() 排版,原来的字符串居中对齐,左对齐,右对齐,如果指定的长度大于字符串长度,就用默认字符填充,默认字符是空格
正则表达式


- 可以通过巧妙地构造正则表达式来匹配任何字符串,并完成查找,替换,分隔等复杂的任务
- 重要的正则表达式:
(1)区别 * 与 + ,前者表示之前的字符出现0次或者多次,后者表示前面的字符出现 1次或者多次
(2)? 可以将字符由贪心变成非贪心的,原本 o+ 是可以匹配尽可能多的o ,如果变成o+? 那么就只会匹配一个o (尽可能少)
(3)\b ,\d,\s ,\w 分别表示匹配单词头或者单词尾,匹配任何数字相当于[0-9], 匹配任何的空白字符,匹配任何的字母、数字、下划线,相当于[a-zA-Z0-9],它们对应的大写的正则表达式的表示的意思与它们各自的意思相反,相当于它们自己的补集
(4)[abc] 是匹配 abc 其中一个的意思,[ ] 就是在括号里面选择一个
(5){m,n} 表示按照前面的字符至少出现m 次,最多出现 n次,注意逗号后面不要有空格
- 例子:
- ‘[pjc]ython’ 或者 ‘(p|j|c)ython’ 都可以匹配’python’ ‘jython’ ‘cython’
- ‘python|perl’ 或者 ‘p(ython|erl)’ 都可以匹配 ‘python’ 或者 ‘perl’
- r’(http://)?(www.)?python.org’ 只能匹配’http://www.python.org’ 或者 ‘www.python.org’ ,‘http://oython.org’ ,‘python.org’
- ‘(a|b)*c’ 表示匹配多个a或者b (可以为0 个) ,后面跟着 c
- ‘ab{1,}’ 相当于 'ab+ ’ 表示字母a 开头,后面跟着至少一个b
- ‘^ [a-zA-Z]{1}[a-zA-Z0-9._]{4,19}$’ 表示匹配长度为5-20的字符串,字符串以字母开头,后面可以为数字,字母,下划线,点号
- ^ [a-zA-Z]+$’ 检测字符串是否只包含英文
- ’\d{4}-\d{1,2}-\d{1,2}‘ 检查是否指定格式的日期,例如2023-12-31
- 正则表达式的拓展语法:可以加上括号表示一个模式 像’(ab)+'就可以匹配多个ab
- 正则表达式模块re:
(1)findall(pattern,string[,flags]) 表示列出字符串中模式的所有的匹配项
(2)match(pattern,string[,flags]) 从字符串的开始的位置开始匹配,返回match 对象或者none
(3)search(pattern,string[,flags]) 从整个字符串开始查找,返回match 对象或者none
(4)split(pattern,string[,maxsplit=0]) 根据模式匹配项来分隔字符串
(5)sub(pat,repl,string[,count=0]) 将字符串中的pat匹配项用repl 项替换,返回新的字符串,repl 可以是字符串或者返回字符串的可调用对象,该可调用对象作用于每一个匹配的match 对象
- match对象:主要方法
(1)group() 返回匹配模式的一个或者多个子模式的内容
(2)groups() 返回一个包含匹配的所有子模式的元组
(3)groupdict() 返回包含匹配所有命名子模式的内容的字典
(4)start() 返回匹配子模式的起始位置
(5)end() 返回匹配子模式的结束位置的前一个位置
(6)span() 返回(start(),end()) 的一个元组