Oracle 学习(3)
分组函数
多行函数也叫组函数,本章学习目标:
- 了解组函数。
- 描述组函数的用途。
- 使用GROUP BY 子句数据分组。
- 使用HAVING 子句过滤分组结果集。
分组函数作用于一组数据,并对一组数据返回一个值。如:AVG、COUNT、MAX、MIN、SUM操作的是一组数据,返回一个结果。
求员工的工资总额:
SQL> select sum(sal) from emp; sum() 对指定列的各行求和。
员工人数:
SQL> select count(*) from emp; count() 统计指定列的非空行数。
平均工资:
SQL> select sum(sal)/count(*) 方式一, avg(sal) 方式二 from emp;
方式一和方式二结果一样,当有空值得时候结果有可能不一样。如:奖金。
求员工的平均奖金:
SQL> select sum(comm)/count(*) 方式一, sum(comm)/count(comm) 方式二, avg(comm) 方式三 from emp;
结果:方式一结果不同,方式二 和 方式三结果一样。
☆NULL空值:组函数都有自动滤空功能(忽略空值),所以:
SQL> select count(*), count(comm) from emp; 执行结果不相同。
如何屏蔽 组函数 的滤空功能:
SQL> select count(*), count(nvl(comm,0)) from emp;
但是实际应用中,结果为14和结果为4都有可能对,看问题本身是否要求统计空值。
count函数:求个数,如果要求不重复的个数,使用distinct。
求emp表中的工种:
SQL> select count(distinct job) from emp;
分组数据
group by
按照group by 后给定的表达式,将from后面的table进行分组。针对每一组,使用组函数。
查询“部门”的平均工资:
分析:结合select * from emp order by deptno 结果分析分组
SQL> select deptno, avg(sal) from emp group by deptno;
上SQL语句可以抽象成:select a, 组函数(x) from 表 group by a; 这样的格式。
如果select a, b 组函数(x) …… group by 应该怎么写?
注意: 在SELECT 列表中所有没有包含在组函数中的列,都必须在group by的后面出现。所以上问应该写成group by a, b;没有b语法就会出错,不会执行SQL语句。但,反之可以。Group by a,b,c; c可以不出现在select语句中。
group by后面有多列的情况:
SQL> select deptno, job, avg(sal) from emp group by deptno, job order by 1;
分析该SQL的作用:
因为deptno, job 两列没有在组函数里面,所以必须同时在group by后面。
该SQL的语义:按部门,不同的职位统计平均工资。先按第一列分组,如果第一列相同,再按第二列分组。
所以查询结果中,同一部门中没有重复的职位。
常见的非法使用组函数的情况,主要出现在缺少group by 子句。如hr用户下执行查询语句:
SELECT department_id, COUNT(last_name)
FROM employees;
会显示如下错误:
SELECT department_id, COUNT(last_name)
*
ERROR at line 1:
ORA-00937: not a single-group group function
意为:GROUP BY 子句中缺少列
Having
使用 HAVING 过滤分组:
1. 行已经被分组。
2. 使用了组函数。
3. 满足HAVING 子句中条件的分组将被显示。
其语法:
SELECT column, group_function
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[HAVING group_condition]
[ORDER BY column];
查询平均薪水大于2000的部门 :
分析:该问题实际上是在分组的基础上过滤分组。
SQL> select deptno, avg(sal) from emp group by deptno having avg(sal)>2000; ------注意:having后面不能使用别名
- 不能在 WHERE 子句中使用组函数(注意)。
- 可以在 HAVING 子句中使用组函数。
从功能上讲,where和having都是将满足条件的结果进行过滤。但是差别是where子句中不能使用 组函数!所以上句中的having不可以使用where代替。
求10号 部门的平均工资:
分析:在上一条的基础上,having deptno=10; 此时 where也可以做这件事。
SQL> select deptno, avg(sal) from emp where deptno=10 group by deptno; 因为没有组函数。
在子句中没有使用组函数的情况下,where、having都可以,应该怎么选择?
※SQL优化: 尽量采用where。
如果有分组的话,where是先过滤再分组,而having是先分组再过滤。当数据量庞大如1亿条,where优势明显。
多表查询
理论基础:——笛卡尔集
笛卡尔集的行数 = table1的行数 x table2的行数
笛卡尔集的列数 = table1的列数 + table2的列数

在操作笛卡尔集的时候,应该避免使用“笛卡尔全集”,因为里面含有大量错误信息。
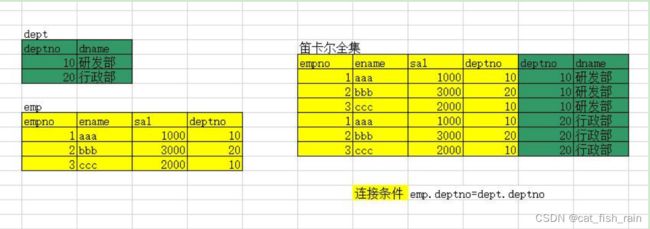
多表查询就是按照给定条件(连接条件),从笛卡尔全集中选出正确的结果。
根据连接条件的不同可以划分为:等值链接、不等值链接、外链接、自连接
- Oracle 连接:
- Equijoin:等值连接
- Non-equijoin:不等值连接
- Outer join:外连接
- Self join:自连接
- SQL: 1999
- Cross joins
- Natural joins
- Using clause
- Full or two sided outer joins
等值连接:
从概念上,区分等值连接和不等值连接非常简单,只需要辨别where子句后面的条件,是“=”为等值连接。不是“=”为不等值连接。
查询员工信息:员工号 姓名 月薪和部门名称
分析:这个问题涉及emp(员工号,姓名,月薪) 和dept(部门名称)两张表 ——即为多表查询。
通常在进行多表查询的时,会给表起一个别名,使用“别名.列名”的方式来获取数据,直接使用“表名.列名”语法上是允许的,但是实际很少这样用。
如果:select e.empno, e.ename, e.sal, e.deptno, d.dname, d.deptno from emp e, dept d;
直接得到的是笛卡尔全集。其中有错误结果。所以应该加 where 条件进行过滤。
SQL> select e.empno, e.ename, e.sal, d.dname from emp e, dept d where e.deptno=d.deptno;
如果有N个表,where后面的条件至少应该有N-1个。
不等值连接:
将上面的问题稍微调整下,查询员工信息:员工号 姓名 月薪 和 薪水级别(salgrade表)
分析:SQL> select * from salgrade; 看到员工总的薪水级别,共有5级,员工的薪水级别应该满足 >=当前级别的下限,<=该级别的上限:
过滤子句应该: where e.sal >= s.losal and e.sal <= s.hisal
所以: SQL> select e.empno, e.ename, e.sal, s.grade from emp e, salgrade s where e.sal >= s.losal and e.sal <= s.hisal;
更好的写法应该使用between…and:
SQL> select s.grade, e.empno, e.ename, e.sal, e.job from emp e, salgrade s
where e.sal between s.losal and s.hisal
order by 1
外链接:
按部门统计员工人数,显示如下信息: 部门号 部门名称 人数
分析:
人数:一定是在emp表中,使用count()函数统计emp表中任一非空列均可。
部门名称:在dept表dname中,直接读取即可。
部门号:任意,两张表都有。
SQL> select d.deptno 部门号, d.dname 部门名称, count(e.empno) 人数 from emp e, dept d
where e.deptno=d.deptno group by d.deptno, d.dname
注意:由于使用了组函数count(),所以组函数外的d.deptno和d.dname必须放到group by后。
得到查询结果,但是select * from dept发现40号部门没有显示出来,原因是40号部门没有员工,where没满足。结果不对,40号部门没有员工,应该在40号部门位置显示0。
我们希望: 在最后的结果中,包含某些对于where条件来说不成立的记录 (外链接的作用)
左外链接:当 where e.deptno=d.deptno 不成立的时候,=左边所表示的信息,仍然被包含。
写法:与叫法相反:where e.deptno=d.deptno(+)
右外链接:当 where e.deptno=d.deptno 不成立的时候,=右边所表示的信息,仍然被包含。
写法:依然与叫法相反:where e.deptno(+)=d.deptno
以上我们希望将没有员工的部门仍然包含到查询的结果当中。因此应该使用外链接的语法。
SQL> select d.deptno 部门号, d.dname 部门名称, count(e.empno) 人数 from emp e, dept d
where e.deptno(+)=d.deptno group by d.deptno, d.dname; 右外链接写法
SQL> select d.deptno 部门号, d.dname 部门名称, count(e.empno) 人数 from emp e, dept d
where d.deptno = e.deptno(+) group by d.deptno, d.dname; 左外链接写法
这样就可以将40号部门包含到整个查询结果中。人数是0
注意:不能使用count(e.*)
自连接:
核心,通过表的别名,将同一张表视为多张表。
查询员工信息:xxx的老板是 yyy
分析:执行select * from emp; 发现,员工的老板也在员工表之中,是一张表。要完成多表查询我们可以假设,有两张表,一张表e(emp)只存员工、另一张表b(boss)只存员工的老板。—— from e, b;
老板和员工之间的关系应该是:where e.mgr=b.empno (即:员工表的老板 = 老板表的员工)
SQL> select e.ename || ' 的老板是 ' || b.ename from emp e, emp b where e.mgr=b.empno
执行,发现结果正确了,但是KING没有显示出来。KING的老板是他自己。应该怎么显示呢?
SQL> select e.ename || ' 的老板是 ' || nvl(b.ename, '他自己' )
from emp e, emp b
where e.mgr=b.empno(+)
使用concat函数应该怎么做呢???
SQL> select concat( e.ename, concat(' 的老板是 ', nvl(b.ename, '他自己' )) )
from emp e, emp b
where e.mgr = b.empno(+)