【读书笔记-MIT决策算法】1.简介
目录
1.1 决策(Decision Making)
1.2 应用
1.2.1 飞行器防撞
1.2.2 自动驾驶
1.2.3 乳腺癌筛查
1.2.4 金融消费与投资组合配置
1.2.5 分布式野火监测
1.2.6 火星科学探索
1.3 方法
1.3.1 显式编程
1.3.2 监督学习
1.3.3 优化理论
1.3.4 规划
1.3.5 强化学习
1.4 历史发展
1.4.1 经济学
1.4.2 心理学
1.4.3 神经学
1.4.4 计算科学
1.4.5 工程学
1.4.6 数学
1.4.7 运筹学
1.5 社会影响
1.6 综述
1.6.1 概率推理
1.6.2 序列问题
1.6.3 模型不稳定性
1.6.4 状态不稳定性
1.6.5 多智能体系统
自动决策系统必须考虑不确定性并平衡多个目标。本章提供了有关决策模型和方法的计算视角,重点介绍了来自不同学科的贡献和潜在的社会影响。
1.1 决策(Decision Making)
什么是智能体(或代理,agent)?智能体可以是物理实体(如人类或机器人)或非物理实体(如完全由软件实现的决策支持系统)。智能体通过观察环境来采取行动,这种交互遵循一个观察-行动循环。智能体在时间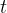 接收到环境的观察结果
接收到环境的观察结果 ,这些观察结果可能通过生物感知过程(如人类)或传感器系统(如空中交通管制雷达)来进行。观察结果通常是不完整或有噪声的,智能体通过一些决策过程来选择行动。
,这些观察结果可能通过生物感知过程(如人类)或传感器系统(如空中交通管制雷达)来进行。观察结果通常是不完整或有噪声的,智能体通过一些决策过程来选择行动。

四种不确定性来源:结果不确定性、模型不确定性、状态不确定性和交互不确定性,这些不确定性是人工智能等领域中需要解决的核心问题。后续将围绕这四种不确定性展开,介绍如何在不确定性条件下做出决策,并探讨一系列相应的算法。
1.2 应用
1.2.1 飞行器防撞
防止飞机之间空中碰撞的系统的设计。此系统与其他飞机通信,以确定其位置,并提醒飞行员注意潜在威胁,同时提供如何避开这些威胁的指导。然而有几个不确定性来源,包括飞行员的反应速度和其他飞机的行为。该系统必须在早期警报需求与避免不必要的机动之间取得平衡,同时提供特殊的安全水平。
1.2.2 自动驾驶
汽车依靠一套传感器来感知环境。激光雷达是一类传感器,它包括测量环境中的激光反射,以确定与障碍物的距离。另一类型的传感器是摄像头,它可以通过计算机视觉算法检测行人和其他车辆。这两种类型的传感器都是不完美的,并且容易受到噪声和遮挡的影响。例如,一辆停着的卡车可能会挡住试图在人行横道上穿过的行人。系统必须根据其他车辆、行人和其他道路使用者的可观察行为来预测他们的意图和未来路径,以便安全地导航到目的地。
1.2.3 乳腺癌筛查
乳房X光检查是最有效的筛查工具,但它具有潜在的风险,例如误报。研究已经根据年龄制定了基于人群的筛查时间表,但需要开发一种能够根据个人风险提出建议的系统。将这种方法与全人群的筛查计划进行比较,这些因素包括质量调整后的寿命年限、乳房X光检查次数、误报率和未被发现的癌症风险。
1.2.4 金融消费与投资组合配置
建立一个建议个人财富中应消费和投资多少的体系的问题,同时考虑了财富的随机演变以及在个人一生中实现消费平滑的愿望。
1.2.5 分布式野火监测
在扑灭野火时,由于火势的性质不断变化且地理跨度很大,因此在扑灭野火时很难进行态势感知。一组配备传感器的无人机可以提供统一的情况快照,以推动资源分配决策,但是有效的监测需要自主协作和推理火势的随机演变。
1.2.6 火星科学探索
通信延迟和有限的上传/下载窗口一直是火星科学探索的瓶颈,但是引入更高的自主权可以将任务效率提高五倍。拥有更大自主权的漫游者可以选择自己的科学目标,无需人为干预即可应对危险和系统故障。
1.3 方法
设计决策代理的方法多种多样,这些决策代理对设计人员和自动化负有不同的责任,包括规划、强化学习、监督学习和优化。
1.3.1 显式编程
用于设计决策代理的显式编程方法可能适用于简单的问题,但会给设计人员带来提供完整策略的负担。不过现有研究已经提出了各种代理编程语言和框架,以简化编程代理。
1.3.2 监督学习
监督学习,也称行为克隆,涉及为自动学习算法提供一组训练示例,以便从中进行概括,当专家设计师知道一组具有代表性的情境的最佳行动方针时,监督学习效果很好,但通常在新情境中表现不可能比人类设计师好。
1.3.3 优化理论
另外一种方法,指定可能的决策策略的空间和要最大化的绩效衡量标准,然后运行模拟来评估决策策略的绩效。然后,优化算法在此空间中搜索最优策略,如果空间相对较小,并且性能度量没有许多局部最优,那么各种局部或全局搜索方法可能是合适的。尽管通常假设动态模型的知识用于运行模拟,但它不会用于指导搜索,这对复杂问题可能很重要
1.3.4 规划
规划是一种优化形式,它使用问题动力学模型来帮助指导搜索。大量文献探讨了各种规划问题,其中大部分集中在确定性问题上。对于某些问题,用确定性模型近似动力学可能是可以接受的。假设确定性模型允许我们使用更容易扩展到高维问题的方法。对于其他问题,考虑未来的不确定性至关重要。后续将完全聚焦于不确定性会计核算的重要问题。
1.3.5 强化学习
强化学习放松了任务中提前知道模型的假设。相反,决策策略是在智能体与环境交互时学习的。设计者只需要提供一个性能度量;优化代理的行为取决于学习算法。强化学习中出现的一个有趣的复杂性是,行动的选择不仅影响主体在实现其目标方面的直接成功,还影响主体了解环境和确定其可以利用的问题特征的能力。
1.4 历史发展
自动决策的概念可以追溯到古希腊的神话和故事,其中包括提及机械三脚架等自动机器。17世纪的哲学家提议使用逻辑规则进行机械化推理,为自动决策奠定了基础。
发明家在18世纪末开始创造用于劳动的自动机器,促成了自动织机和第一批工厂机器人的开发,而使用智能机器实现劳动自动化则开始进入科幻小说。
在自动化决策的实际实现中,主要的挑战是考虑不确定性。即使在20世纪末,以开发单纯形算法而闻名的乔治·丹齐格也在1991年表示:发起研究的最初问题是随着时间的推移动态规划或日程安排的问题,尤其是在不确定性的情况下,这个问题如果得到解决,可以促进世界的福祉和稳定。
研究人员通过汇聚来自多个学科(包括经济学、心理学、神经科学、计算机科学、工程、数学和运筹学)的概念,在不确定性下的决策方面取得了进展,从而带来了最新的进展和未来的发展。
1.4.1 经济学
18世纪末引入的效用理论提供了一种对各种结果的可取性(例如货币数量的可取性)进行建模和比较的方法,并且可以用来比较不同财富水平的人的幸福感。
20世纪中叶的经济学家通过将效用概念与理性决策相结合建立了最大预期效用原则,这是创建自主决策机构背后的关键概念,并促成了博弈论的发展。
1.4.2 心理学
心理学家研究人类决策和试错学习,基于满意度和不适感来强化(reinforcement)学习。对人类儿童的训练在很大程度上取决于一个奖惩系统,这表明应该可以在只有两个干扰输入的情况下进行组织,一个输入用于“学习”或“后退”(R),另一个输入为“惩罚”或“惩罚”(P)。
图灵认为:机器只需使用两个干扰输入即可以同样的方式学习。
1.4.3 神经学
神经科学家研究了人类行为背后的生物学过程,特别是大脑中相互关联的神经元网络,这些网络可以应用于决策。
20世纪40年代,首次提出,神经元可以被视为单独的“逻辑单元”,当被拼凑成网络时,能够执行计算操作。这项工作为神经网络奠定了基础。
1.4.4 计算科学
20世纪中叶,计算机科学家通过形式逻辑使用符号操作来解决智能决策问题,证明了数学定理的计算机程序逻辑理论就是例证。
在连接主义中使用人工神经网络可以从数据或经验中学习智能行为,而不是依赖专家的硬编码知识,并促成了AlphaGo和自动驾驶汽车等项目的成功。
1.4.5 工程学
工程领域的重点是让机器人等物理系统做出智能决策。
设计物理系统的工程师必须解决感知、计划和行为问题,这包括建立对世界状况的信念、推理任务执行以及通过反馈控制控制控制执行器。
这些任务得益于半导体行业的进步,并广泛应用于工业中,从调节烤箱温度到导航航空航天系统。
1.4.6 数学
代理必须能够量化其不确定性,以便在不确定的环境中做出明智的决策。决策领域在很大程度上依赖于概率论来完成这项任务。决策领域在很大程度上依赖于概率论来完成这项任务。
基于采用的方法,蒙特卡洛。。
1.4.7 运筹学
运筹学使用数学和科学分析来寻找决策问题的最佳解决方案,例如资源分配和维护计划。它在工业革命期间加速发展,并在第二次世界大战期间应用于资源分配。战后,企业意识到相同的概念可以帮助他们优化决策,从而促进管理科学的发展。
1.5 社会影响
医学、城市公共设施、政治等,
挑战:数据偏见、算法鲁棒性、道德体系建设。
1.6 综述
本书分为五个部分:
第一部分解决了在单个时间点上对简单决策中的不确定性和目标进行推理的问题。
第二种方法将决策扩展到顺序问题,在顺序问题中,我们必须在进行过程中根据有关行动结果的信息做出一系列决策。
第三个解决了模型的不确定性,即我们不能从已知的模型开始,必须学会如何通过与环境的互动来采取行动。
第四个解决了状态不确定性,即不完美的感知信息使我们无法了解完整的环境状态。
最后一部分讨论了涉及多个代理的决策协调。
1.6.1 概率推理
理性决策的过程包括考虑不确定性和目标,这些不确定性和目标可以用概率分布和效用论来表示。决策网络可用于将这些概念整合到概率图形模型中。
1.6.2 序列问题
序列背景下的最佳决策需要对随机环境中未来的动作和观测顺序进行推理,书中将使用马尔可夫决策过程(MDP)作为标准数学模型来讨论这一点。
1.6.3 模型不稳定性
强化学习涉及在动态和回报不确定时学会通过经验采取行动,需要平衡探索和利用,为延迟奖励分配积分,并从有限的经验中进行概括。本书将回顾解决这些挑战的理论和一些关键算法。
1.6.4 状态不稳定性
将不确定性扩展到包括状态并将其建模为部分可观察的马尔可夫决策过程(POMDP),采用一种常见的方法是推断基础状态的信念分布,并应用将信念映射到行动的政策。讨论了求解 pomDP 的各种精确和近似方法。
1.6.5 多智能体系统
本节讨论了多个代理在环境中做出决策所面临的挑战,包括简单的博弈和马尔可夫博弈。 2。由于其他代理的政策存在不确定性,马尔可夫博弈的算法依赖于强化学习。
-----------------------------------------------------------------------------------------------------------------------
站在巨人的肩膀上。致敬原著:Kochenderfer M J, Wheeler T A, Wray K H. Algorithms for decision making[M]. MIT press, 2022.