k8s 网络

还没有部署网络。
k8s的网络类型:
k8s中的通信模式:
1,pod内部之间容器和容器之间的通信。
在同一个pod中的容器共享资源和网络,使用同一个网络命名空间。可以直接通信的。
2,同一个node节点之内不同pod之间的通信。
每一个pod都有一个全局的真实的IP地址,同一个node之间的不同的pod可以直接使用对方的IP地址进行通信。
pod1和pod2是通过docker0的网桥来进行通信。
3,不同node节点上的pod之间如何进行通信?
cni的插件:
cni是一个标准接口,用于容器运行时调用网络插件,配置容器网络,负责设置容器的网络命名空间,IP地址,路由等等参数。
flannel组件:功能就是让集群之中不同节点的docker容器具有全集群唯一的虚拟IP地址。
overlay网络,在底层物理网络的基础之上,创建一个逻辑的网络层。二层+三层的集合 二层是物理网络,三层的逻辑上的网络层。
overlay网络也是一种网络虚拟化的技术。
flannel支持的数据转发方式:
1,UDP模式,默认模式,应用转发,配置简单,但是性能最差
2,vxlan,基于内核转发,也最采用的网络类型(小集群都资源这个)
3,host-gw,(性能最好,但是配置麻烦。)
UDP模式:基于应用转发,flannel提供路由表,flannel封装数据包,解封装。
node都会有一个flannel的虚拟网卡。

flannel的作用:
1.封装数据包
2.转发通过flannel插件的路由表
要多层转发,所以性能比较差
vxlan:使用的就是overlay的虚拟隧道通信技术。二层+三层的模式。
udp基于应用层,用户。
vxlan:flannel提供路由表,内核封装接封装。
flannel1.1 接口
flannel作用:识别对应的vni的IP地址,

实验:
---------- 部署 flannel ----------
在 node01 02 节点上操作
#上传 cni-plugins-linux-amd64-v0.8.6.tgz 和 flannel.tar 到 /opt 目录中
cd /opt/

docker load -i flannel.tar
导入镜像包
mkdir -p /opt/cni/bin
tar zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni/bin
在 master01 节点上操作
#上传 kube-flannel.yml 文件到 /opt/k8s 目录中,部署 CNI 网络
cd /opt/k8s
kubectl apply -f kube-flannel.yml
kubectl get pods -n kube-system

配置网络之后。
kubectl get nodes

fannel:每个发向容器的数据包进行封装,vxlan通过vtep打包数据,有内核封装数据包---转发到目标node节点。到了目标节点,还有一个解封装的过程,在发生目标pod。性能是由移动影响。
---------- 部署 Calico ----------
Calico插件:采用直接路由 的方式。BGP路由。不需要修改报文,统一直接通过路由表转发,路由表会很复杂,运行维护的要求比较高。
BGP模式的特点:交换路由信息的外部网关协议,可以连接不同的节点,node可能不是一个网段。BGP会自动寻址,自动选择可靠的。最佳的,而且是动态的路由选择。自动识别相邻的路由设备。
calico不使用overlay,也不需要交换,直接通过虚拟路由实现,每一台虚拟路由都通过BGP转发。
核心组件:
felix:也是运行在主机的一个个pod,一个进程,k8s,daemonset的方式部署的pod。
daemont set 会在每个node节点部署相同的pod,后台运行的方式。
负责在宿主机上插入路由规则,维护calico需要的网络设备。网络接口的管理,监听,路由等等。
BGP Client:bird BGP的客户端,专门负责在集群中分发路由规则的信息。每一个节点都会有一个BGP Client。
BGP协议广播的方式通知其他节点,分发路由的规则。执行网络互通。
etcd:保存路由信息,负责整个网络元数据的一致性。保证网络状态的一致和准确。
BGP:通过为ip路由表的签字来实现目标主机的可打性,
对比ipip模式,BGP没有隧道,BGP模式下,pod的数据包之间通过网卡发送到目的地。
ipip的隧道:隧道进行数据包的封装ipv4 --- ipv4.
calico的工作原理:
路由表来维护每个pod之间的通信。
创建好pod之后,添加一个设备cali veth pair设备。
虚拟网卡:veth pair是一对设备,虚拟的以太网设备。
一头连接在容器的网络命名空间
另一头连接宿主机的网络命名空间 cali
ip地址分配:veth pair连接容器的部分给容器分配一个ip地址,这个ip地址是唯一标识,宿主机也会被veth pair分配一个calico网络的镍币IP地址。和其他节点上的容器进行通信。
veth设备,容器发出的ip地址通过veth pair设备到宿主机,宿主机根据路由规则的下一跳地址,发送到网关(目标宿主机,)
数据包到达目标宿主机,veth pari设备,目标宿主机也是根据路由规则,下一跳地址,转发到目标容器。
面试问calico就是根据路由规则来转发。通过veth设备来

ipip模式当中会生成一个tunnel。数据包在tunnel内部打包。封装:宿主机ip 容器内部的IP地址。
实验:
在 master01 节点上操作
#上传 calico.yaml 文件到 /opt/k8s 目录中,部署 CNI 网络
cd /opt/k8s
vim calico.yaml
修改:

安装:
kubectl apply -f calico.yaml
kubectl get pods -n kube-system

kubectl get nodes

总的管理器
![]()
创建了之后就有了一个隧道
ifconfig

总结:
面试题:
k8s当中常用的网络类型:flannel解饿calico
flannel:配置简单,功能简单,基于overlay叠加网络实现,在物理层的网络封装在一个虚拟的网络
vxlan是虚拟三层网络。
udp是默认模式
vxlan 最大的模式 vni+ip 进行转发,flannel通过路由表,内核封装和解封装
host-gw
由于封装和解封装的过程,对应数据传输的性能会有影响,没有网络策略配置的能力 UDP(协议)
默认网段:10.244.0.0/16
calico:功能强大,基于路由表进行转发,没有封装和接封装的过程。剧本网络策略的配置能力。但是路由表维护起来复杂。
模式:ipip BGP
BGP:通过为ip路由表的签字来实现目标主机的可打性,
对比ipip模式,BGP没有隧道,BGP模式下,pod的数据包之间通过网卡发送到目的地。
ipip的隧道:隧道进行数据包的封装ipv4 --- ipv4.
如果是简单的小集群:flannel
如果以后要扩容,配置网络策略:calico
我们公司比较小,用的是flannel,但是calico我也知道,
让我来部署,一般的用flannel就够了,有其他要求的话,来部署calico
coredns:
可以为集群当中的service资源创建一个域名和ip进行对应解析的关系。
service是对外提供访问的地址,现在我们加入DNS机制之后,可以之间访问服务名,
![]()
实验继续部署二进制
创建pod
kubectl create deployment nginx1 --image=nginx:1.22 --replicas=3

每创建一个pod就会创建两个个虚拟网卡:
一边连容器,一边连宿主机。
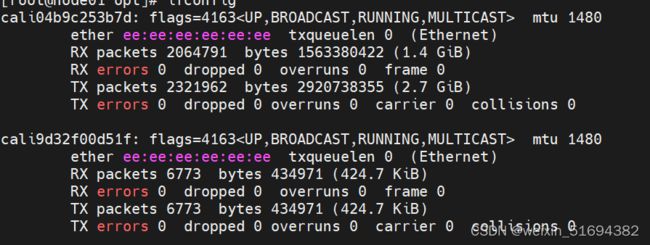
kubectl get pod -o wide查看详细信息。

---------- master02 节点部署 ----------
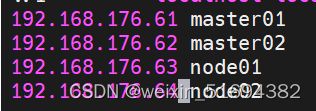
先每个节点做映射:
vim /etc/hosts
从 master01 节点上拷贝证书文件、各master组件的配置文件和服务管理文件到 master02 节点
scp -r /opt/etcd/ [email protected]:/opt/
scp -r /opt/kubernetes/ [email protected]:/opt
scp -r /root/.kube [email protected]:/root
scp /usr/lib/systemd/system/{kube-apiserver,kube-controller-manager,kube-scheduler}.service [email protected]:/usr/lib/systemd/system/
修改配置文件kube-apiserver中的IP
vim /opt/kubernetes/cfg/kube-apiserver

//在 master02 节点上启动各服务并设置开机自启
systemctl start kube-apiserver.service
systemctl enable kube-apiserver.service
systemctl start kube-controller-manager.service
systemctl enable kube-controller-manager.service
systemctl start kube-scheduler.service
systemctl enable kube-scheduler.service
//查看node节点状态
ln -s /opt/kubernetes/bin/* /usr/local/bin/
kubectl get nodes
kubectl get nodes -o wide
------------------------------ 负载均衡部署 ------------------------------
//配置load balancer集群双机热备负载均衡(nginx实现负载均衡,keepalived实现双机热备)
在lb01、lb02节点上操作
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
//配置nginx的官方在线yum源,配置本地nginx的yum源
cat > /etc/yum.repos.d/nginx.repo
[nginx]
name=nginx repo
baseurl=Index of /packages/centos/7/$basearch/
gpgcheck=0
EOF
yum install nginx -y
修改nginx配置文件,配置四层反向代理负载均衡,指定k8s群集2台master的节点ip和6443端口
vim /etc/nginx/nginx.conf
添加:

nginx -t
启动nginx服务,查看已监听6443端口
systemctl start nginx
systemctl enable nginx
netstat -natp | grep nginx

部署keepalived服务
yum install keepalived -y
//修改keepalived配置文件
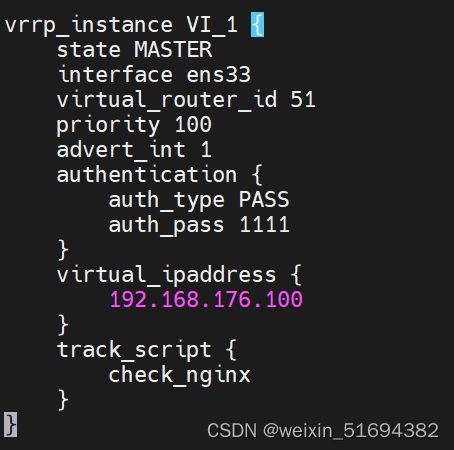
vim /etc/keepalived/keepalived.conf
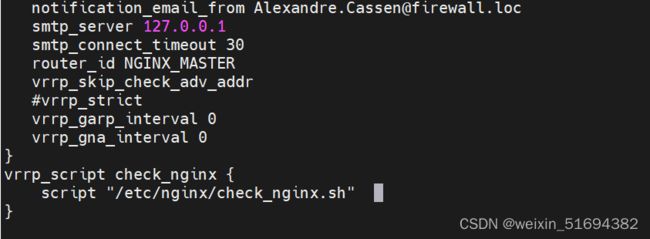
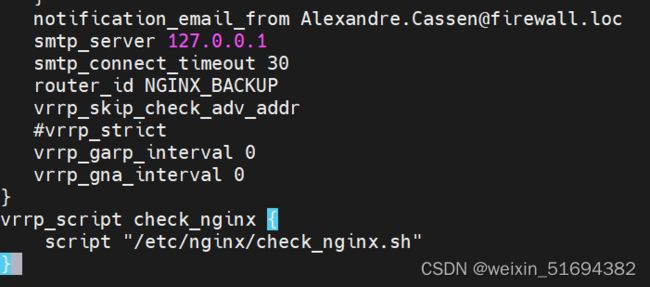

创建nginx状态检查脚本
vim /etc/nginx/check_nginx.sh
#!/bin/bash
/usr/bin/curl -I http://localhost &>/dev/null
if [ $? -ne 0 ];then
# /etc/init.d/keepalived stop
systemctl stop keepalived
fi
chmod +x /etc/nginx/check_nginx.sh
启动keepalived服务(一定要先启动了nginx服务,再启动keepalived服务)
systemctl start keepalived
systemctl enable keepalived
ip a #查看VIP是否生成

修改node节点上的bootstrap.kubeconfig,kubelet.kubeconfig配置文件为VIP
cd /opt/kubernetes/cfg/
vim bootstrap.kubeconfig
server: https://192.168.176.100:6443
vim kubelet.kubeconfig
server: https://192.168.176.100:6443
vim kube-proxy.kubeconfig
server: https://192.168.176.100:6443
//重启kubelet和kube-proxy服务
systemctl restart kubelet.service
systemctl restart kube-proxy.service
------------------------------ 部署 Dashboard ------------------------------
Dashboard:
仪表盘, kubenetes的可视化界面。在这个可视化界面上,可以对k8s集群进行管理。
在 master01 节点上操作
#上传 recommended.yaml 文件到 /opt/k8s 目录中
cd /opt/k8s
直接运行
kubectl apply -f recommended.yaml
创建service account并绑定默认cluster-admin管理员集群角色
kubectl create serviceaccount dashboard-admin -n kube-system
kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
获取token值
kubectl describe secrets -n kube-system $(kubectl -n kube-system get secret | awk '/dashboard-admin/{print $1}')
使用输出的token登录Dashboard
https://192.168.176.63:30001
