MySQL的索引(一)
目录
- 索引是什么
- `MySQL` 为何使用 `B+ Tree` 作为索引的数据结构
-
- 二叉树为什么不可行
- 平衡二叉树为什么不可行
- `B Tree`
- 为什么说 `B Tree` 能够解决平衡二叉树存在的问题呢
- `B+ Tree`
- `B Tree` 和 `B+ Tree` 区别
- `MySQL` 为什么最终要去选择 `B+ Tree`
- `Innodb` 引擎的索引实现
-
- 聚集索引(主键索引)
- 普通索引(非主键索引)
- 聚集索引与普通索引示例
-
- 建表
- 索引 `B+ Tree` 的存储结构
- 普通索引(非主键索引)的 `B+ Tree` 的存储结构
- 聚集索引查找过程
- 普通索引查找过程
-
- 普通索引查找过程第一步
- 普通索引查找过程第二步
- 回表查询
- 普通索引存在的意义
索引是什么
索引是为了加速对表中数据的检索的一种数据结构,是 B+ Tree的一种数据结构
索引保存数据的方式一般有两种:
- 数据区保存主键
id对应行数据的所有数据具体内容 - 数据区保存的是真正保存数据的磁盘地址
其工作机制如下图:
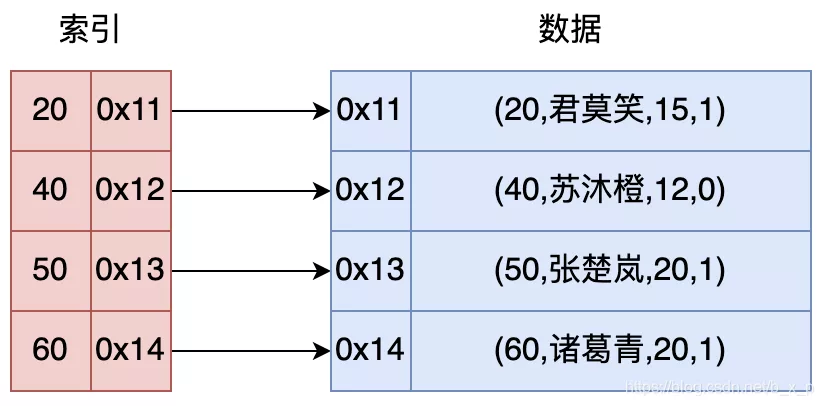
上图中,如果现在有一条 sql 语句
select * from user where id = 40
- 如果没有索引的条件下,我们要找到这条记录,我们就需要在数据中进行全表扫描,匹配
id = 40的数据 - 如果有了索引,我们就可以通过索引进行快速查找,如上图中,可以先在索引中通过
id = 40进行二分查找,再根据定位到的地址取出对应的行数据
MySQL 为何使用 B+ Tree 作为索引的数据结构
关于数据结构之树详情查看:https://blog.csdn.net/weixin_38192427/article/details/112973493
二叉树为什么不可行
对数据的加速检索,首先想到的就是二叉树,二叉树的查找时间复杂度可以达到 O(log2(n))
下面看一下二叉树的存储结构:
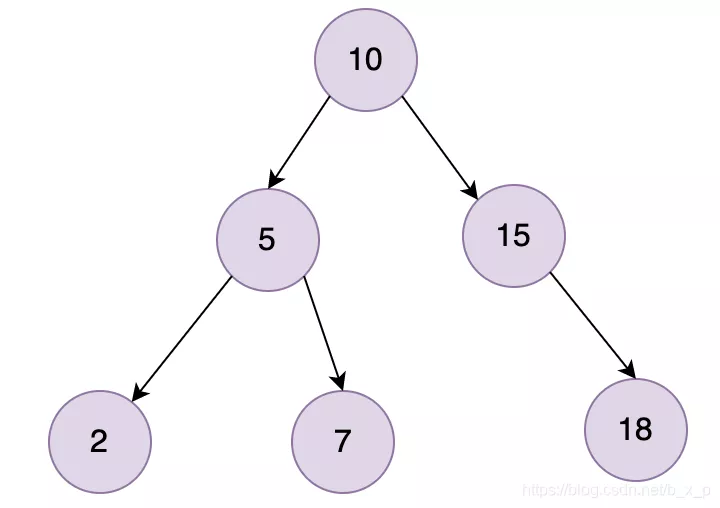
二叉树搜索相当于一个二分查找。二叉查找能大大提升查询的效率,但是它有一个问题:二叉树以第一个插入的数据作为根节点,如上图中,如果只看右侧,就会发现,就是一个线性链表结构。如果我们现在的数据只包含1, 2, 3, 4,就会出现
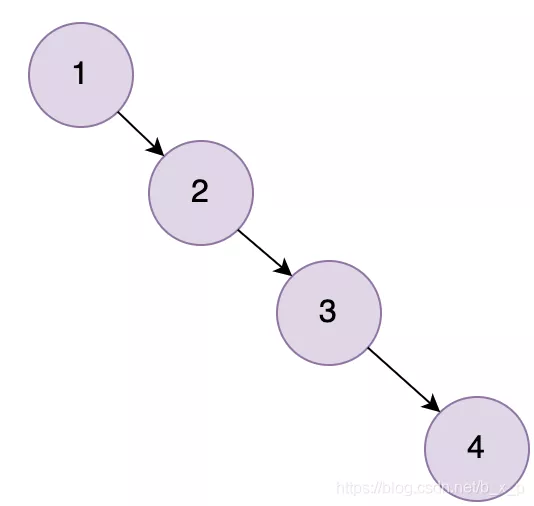
如果我们要查询的数据为 4,则需要遍历所有的节点才能找到 4,即相当于全表扫描,就是由于存在这种问题,所以二叉查找树不适合用于作为索引的数据结构
平衡二叉树为什么不可行
为了解决二叉树存在线性链表的问题,会想到用平衡二叉查找树来解决
下面看看平衡二叉树是怎样的:
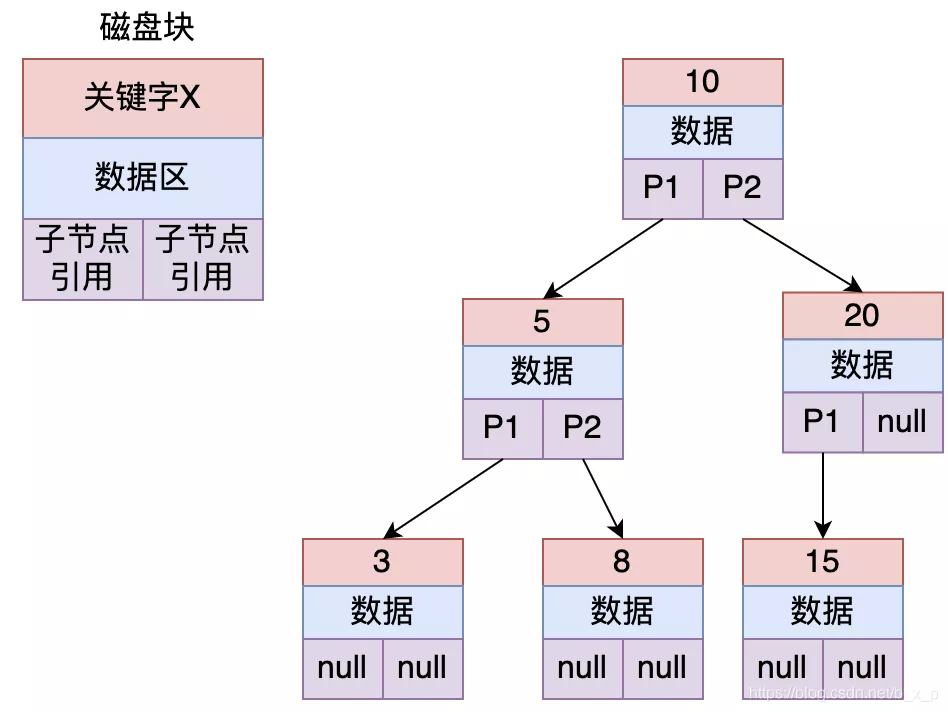
平衡二叉查找树定义为:节点的子节点高度差不能超过 1,如上图中的节点 20,左节点高度为 1,右节点高度 0,差为 1,所以上图没有违反定义,它就是一个平衡二叉树。保证二叉树平衡的方式为左旋,右旋等操作
如果上图中平衡二叉树保存的是 id 索引,现在要查找 id = 8 的数据,过程如下:
- 把根节点加载进内存,用
8和10进行比较,发现8比10小,继续加载10的左子树 - 把
5加载进内存,用8和5比较,同理,加载5节点的右子树 - 此时发现命中,则读取
id为8的索引对应的数据
到这里,平衡二叉树解决了存在线性链表的问题,数据查询的效率好像也还可以,基本能达到 O(log2(n)), 那为什么 mysql 不选择平衡二叉树作为索引存储结构,他又存在什么样的问题呢
- 搜索效率不足:一般来说,在树结构中,数据所处的深度,决定了搜索时的
IO次数(MySQL中将每个节点大小设置为一页大小,一次IO读取一页或一个节点)。如上图中搜索id = 8的数据,需要进行3次IO。当数据量到达几百万的时候,树的高度就会很恐怖 - 查询不稳定。如果查询的数据落在根节点,只需要一次
IO,如果是叶子节点或者是支节点,会需要多次IO才可以 - 存储的数据内容太少。没有很好利用操作系统和磁盘数据交换特性,也没有利用好磁盘
IO的预读能力。因为操作系统和磁盘之间一次数据交换是以页为单位的,一页大小为4K,即每次IO操作系统会将4K数据加载进内存。但是,在二叉树每个节点的结构只保存一个关键字,一个数据区,两个子节点的引用,并不能够填满4K的内容。幸幸苦苦做了一次的IO操作,却只加载了一个关键字。在树的高度很高,恰好又搜索的关键字位于叶子节点或者支节点的时候,取一个关键字要做很多次的IO
那有没有一种结构能够解决二叉树的这种问题呢?有,那就是多路平衡查找树
B Tree
B Tree 是一个绝对平衡树,所有的叶子节点在同一高度
如下图所示:
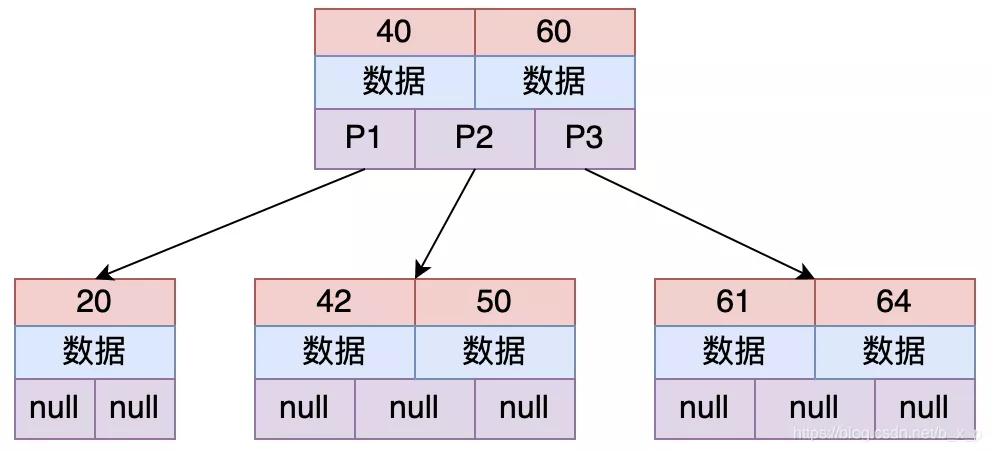
上图为一个 2-3 树(每个节点存储 2 个关键字,有 3 路),多路平衡查找树也就是多叉的意思,从上图中可以看出,每个节点保存的关键字的个数和路数关系为:关键字个数 = 路数 – 1
假设要从上图中查找 id = X 的数据,B TREE 搜索过程如下:
- 取出根磁盘块,加载
40和60两个关键字 - 如果
X等于40,则命中;如果X小于40走P1;如果40 < X < 60走P2;如果X = 60,则命中;如果X > 60走P3 - 根据以上规则命中后,接下来加载对应的数据,数据区中存储的是具体的数据或者是指向数据的指针
为什么说 B Tree 能够解决平衡二叉树存在的问题呢
B Tree能够很好的利用操作系统和磁盘的交互特性:mysql为了很好的利用磁盘的预读能力,将页大小设置为16K,即将一个节点(磁盘块)的大小设置为16K,一次IO将一个节点(16K)内容加载进内存。这里,假设关键字类型为int,即4字节,若每个关键字对应的数据区也为4字节,不考虑子节点引用的情况下,则上图中的每个节点大约能够存储(16 * 1000)/ 8 = 2000个关键字,共2001个路数。对于二叉树,三层高度,最多可以保存7个关键字,而对于这种有2001路的B 树,三层高度能够搜索的关键字个数远远的大于二叉树
这里顺便说一下:在 B Tree 保证树的平衡的过程中,每次关键字的变化,都会导致结构发生很大的变化,这个过程是特别浪费时间的,所以创建索引一定要创建合适的索引,而不是把所有的字段都创建索引,创建冗余索引只会在对数据进行新增,删除,修改时增加性能消耗
B Tree 确实已经很好的解决了问题,我先这里先继续看一下 B+Tree 结构,再来讨论 B Tree 和 B+ Tree 的区别
B+ Tree
B+ Tree 是 B Tree 的一个变种,在 B+ Tree 中,B Tree 的路数和关键字的个数的关系不再成立了,数据检索规则采用的是左闭合区间,路数和关键个数关系为 1:1
具体如下图所示:
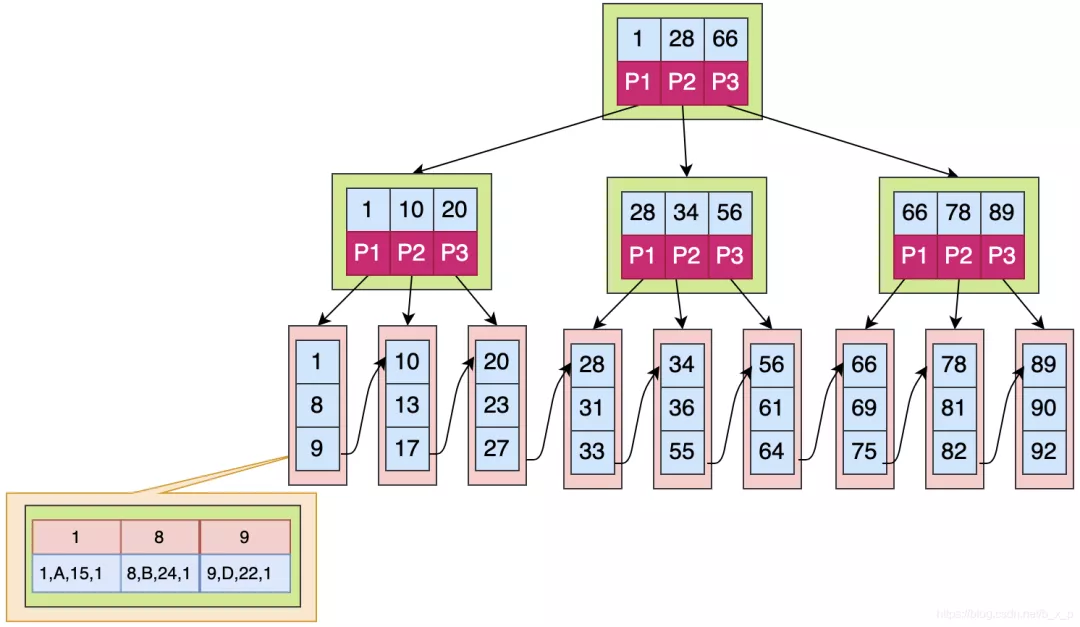
如果上图中是用 id 做的索引,如果是搜索 X = 1 的数据,搜索规则如下
- 取出根磁盘块,加载
1,28,66三个关键字 X <= 1走P1,取出磁盘块,加载1,10,20三个关键字X <= 1走P1,取出磁盘块,加载1,8,9三个关键字- 已经到达叶子节点,命中
1,接下来加载对应的数据,图中数据区中存储的是具体的数据
B Tree 和 B+ Tree 区别
B Tree每一个节点里存的是数据,而B+ Tree存储的是索引(地址),所以B Tree里一个节点存不了多少个数据,但是B+ Tree一个节点能存很多索引,B+ Tree叶子节点存所有的数据B+ Tree的叶子节点数据用了一个链表串联起来,便于范围查找,通过B Tree和B+ Tree的对比我们看出,B+ Tree节点存储的是索引,在单个节点存储容量有限的情况下,单节点也能存储大量索引,使得整个B+ Tree高度降低,减少了磁盘IOB+ Tree的叶子节点是真正数据存储的地方,叶子节点用了链表连接起来,这个链表本身就是有序的,在数据范围查找时,更具备效率。因此mysql的索引用的就是B+ Tree,B+ Tree在查找效率、范围查找中都有着非常不错的性能
MySQL 为什么最终要去选择 B+ Tree
B+Tree是B TREE的变种,B TREE能解决的问题,B+TREE也能够解决(降低树的高度,增大节点存储数据量)B+Tree扫库和扫表能力更强。如果我们要根据索引去进行数据表的扫描,对B TREE进行扫描,需要把整棵树遍历一遍,而B+TREE只需要遍历他的所有叶子节点即可(叶子节点之间有引用)B+TREE磁盘读写能力更强。他的根节点和支节点不保存数据区,所以根节点和支节点同样大小的情况下,保存的关键字要比B TREE要多。而叶子节点不保存子节点引用,能用于保存更多的关键字和数据。所以B+TREE读写一次磁盘加载的关键字比B TREE更多B+Tree排序能力更强。上面的图中可以看出,B+Tree天然具有排序功能B+Tree查询性能稳定。B+Tree数据只保存在叶子节点,每次查询数据,查询IO次数一定是稳定的。当然这个每个人的理解都不同,因为在B TREE如果根节点命中直接返回,确实效率更高
Innodb 引擎的索引实现
聚集索引(主键索引)
聚集索引: InnoDB 会使用主键 ID 建立索引 B+ Tree,而其 B+ Tree 的叶子节点存储的是主键 ID 对应的数据,聚集索引的叶子节点称为数据页,聚集索引的这个特性决定了索引树中的数据也是索引的一部分
由此可见,使用聚集索引查询会很快,因为可以直接定位到行记录
- 如果表设置了主键,则主键就是聚集索引(主键索引)
- 如果表没有主键,则会默认第一个
NOT NULL,且唯一(UNIQUE)的列作为聚集索引(主键索引) - 以上都没有,则会默认创建一个隐藏的
row_id作为聚集索引(主键索引)
普通索引(非主键索引)
普通索引:当表中创建了普通索引(非主键索引)时,InnoDB 就会建立普通索引 B+ Tree,这个普通索引 B+ Tree 的叶子节点存储的是数据记录的主键 ID,而与这个数据记录的主键 ID 所对应的就是普通索引(非主键索引)
聚集索引与普通索引示例
建表
mysql> create table user(
-> id int(10) auto_increment,
-> name varchar(30),
-> age tinyint(4),
-> primary key (id),
-> index idx_age (age)
-> )engine=innodb charset=utf8mb4;
insert into user(name,age) values('张三',30);
insert into user(name,age) values('李四',20);
insert into user(name,age) values('王五',40);
insert into user(name,age) values('刘八',10);
mysql> select * from user;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | 张三 | 30 |
| 2 | 李四 | 20 |
| 3 | 王五 | 40 |
| 4 | 刘八 | 10 |
+----+--------+------+
id 字段是聚集索引,age 字段是辅助索引(普通索引)
索引 B+ Tree 的存储结构
id 是主键,所以是聚集索引,其叶子节点存储的是 id 主键对应的行记录的数据。聚集索引的这个特性决定了索引树中的数据也是索引的一部分

普通索引(非主键索引)的 B+ Tree 的存储结构
age 是普通索引(辅助索引),其叶子节点存储的是数据记录的主键 ID,而与这个数据记录的主键 ID 所对应的就是普通索引(非主键索引)
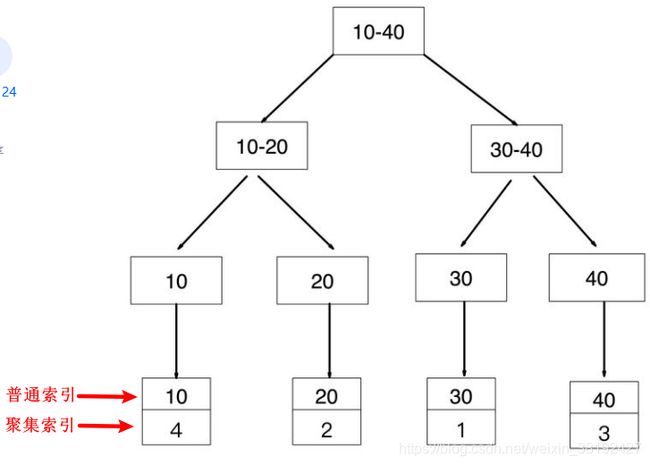
聚集索引查找过程
如果查询条件为主键(聚集索引),则只需扫描一次 B+ Tree 即可通过聚集索引定位到要查找的行记录数据
select * from user where id = 1
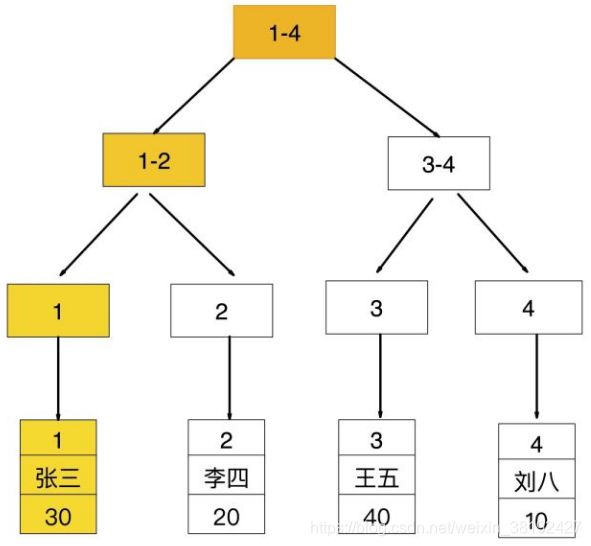
普通索引查找过程
如果查询条件为普通索引(非聚集索引),需要扫描两次 B+ Tree,第一次扫描通过普通索引定位到聚集索引的值,然后第二次扫描通过聚集索引的值定位到要查找的行记录数据
select * from user where age = 30;
- 先通过普通索引
age = 30定位到主键值id = 1 - 再通过聚集索引
id = 1定位到行记录数据
普通索引查找过程第一步
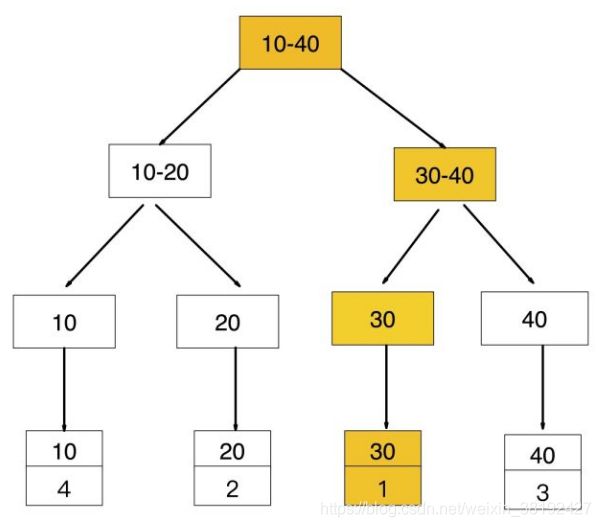
普通索引查找过程第二步
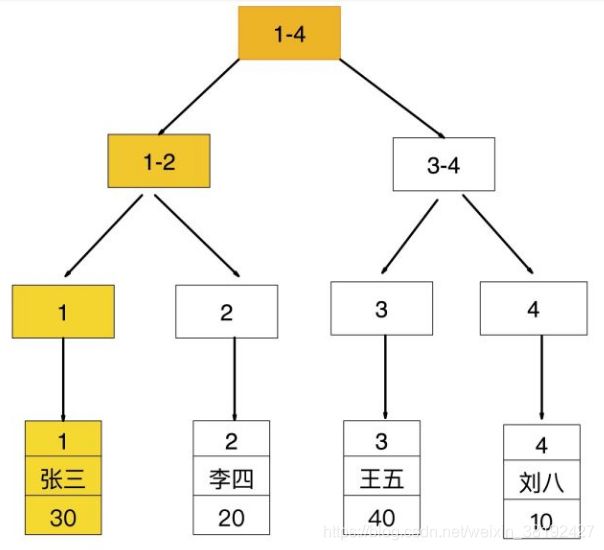
回表查询
先通过普通索引的值定位聚集索引值,再通过聚集索引的值定位行记录数据,需要扫描两次索引 B+ Tree,它的性能较扫一遍索引树更低
普通索引存在的意义
- 聚集索引:
InnoDB会使用主键ID建立索引B+ 树,而其B+ 树的叶子节点存储的是主键ID对应的数据 - 普通索引:普通索引
B+ 树的叶子节点存储的是数据记录的主键ID,而与这个数据记录的主键ID所对应的就是聚集索引(主键索引)
因为 InnoDB 需要节省存储空间。一个表里可能有很多个索引,InnoDB 都会给每个加了索引的字段生成索引树,如果每个字段的索引树都存储了具体数据,那么这个表的索引数据文件就变得非常巨大(数据极度冗余了)。从节约磁盘空间的角度来说,真的没有必要为每个字段索引树都存具体数据,通过这种看似“多此一举”的步骤,在牺牲较少查询的性能下节省了巨大的磁盘空间,这是非常有值得的