基于centos7.6搭建hadoop-3.1.2集群
基于centos7.6搭建hadoop-3.1.2集群
- hadoop单节点安装。
Hadoop单节点的安装不需要守护进程,所以不需要安装zookeeper。
准备环境centos7.6、java1.8、hadoop-3.1.2。
首先安装虚拟机。我选择的是最小安装,这样会更节省资源,更快一些,但是有些东西会缺少,需要自己手动安装。在创建虚拟机之前点击左上角的虚拟网络编辑器。

之后安装虚拟机的时候网卡会设置成NAT所以这里吧NAT的网段改为192.168.10.0。
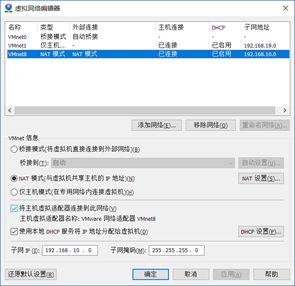
设置完成后就可以安装虚拟机了。下面是我的虚拟机配置。

安装完成后先配置网卡信息。
![]()
不需要连接外网的话这样就可以了。多余行可以删掉。

主要是标注的这3行进行修改。第一行的dhcp改为static,第二行的no改为yes,第三行是添加上去的,添加的就是这台虚拟机的IP。
然后重启网卡服务。
![]()
重启成功。
ip a s 查看网卡信息

可以看到ens33网卡IP修改成功。
关闭防火墙,然后永久关闭防火墙。
![]()
然后就可以使用ssh工具连接使用了。这里推荐mobaxterm工具。有安装版和便携版。功能比较全,便携版无需安装使用方便。这软件功能比较多,本人由于英语不好所以正在摸索使用中,有什么好玩功能的东西望大家告知。
点击左上角的session即可开始连接。然后输入自己的虚拟机IP和用户进入连接。

然后输入自己root账户的密码。
连接成功。

修改主机名hostname。
![]()
最小安装是没有vim的,我这里是手动装的。
将配置文件中原有的内容删除掉改为hadoop01。这里可以根据自己的选择改,比较随意。
![]()
配置完成后reboot重启生效。
然后配置hosts文件,这里因为我后面要装4节点的集群,所以提前把后面的也写好了。
![]()

向里面写入对应的IP和主机名。
Ping通说明配置生效。

接下来创建一个新的用户hadoop这个用户将来用来管理hadoop所有的组件。
创建hadoop用户并且设置密码。
![]()
![]()
然后在/etc/sudoers配置文件里修改hadoop用户的权限。
![]()
第一行是本来就有的,添加第二行。
![]()
重启生效。
cd到/opt文件夹下新建两个文件夹software和module。software将用来存放传到节点上的安装包,module将成为hadoop组件的安装路径。
![]()
![]()
然后修改文件夹属主和读写权限。
修改属主。
![]()
![]()
修改读写权限。
![]()
![]()
修改后的文件夹属性如下。

接下来就可以安装java了,因为我的节点是最小安装所以不需要查看是否有旧版本,直接安装即可。
首先在oracle官网下载linux的jdk安装包。
https://www.oracle.com/technetwork/java/javase/downloads/index.html
然后在mobaxterm自带的sftp上将安装包上传至/opt/software路径下。
(mobaxterm连接成功后可以看到左下角有一个跟随文件夹,把这里勾选上然后cd到/opt/software路径下,可以看到左边竖框也转到了该路径下。)

在本地电脑上将文件拖拽至左边框内即可上传至对应路径。这里我将后面要用到的一些包也上传了进去。
将jdk的压缩包解压至/opt/module路径下。

将解压好的文件夹更名。然后配置环境变量。
![]()
向文件末尾追加两行。
![]()
执行source是变量生效。
![]()
查看版本确定安装成功。

到这里准备环境算是配置完成了,接下来就可以配置hadoop组件了。
首先将hadoop的安装包上传至/opt/software路径下。我之前上传过了就不再上传了。
cd到/opt/software路径下将hadoop安装包解压至/opt/module路径下。

使用hadoop账户配置免密登录。

然后修改hadoop的配置文件,这些文件的路径为/opt/module/hadoop-3.1.2/etc/Hadoop。
然后修改hdfs-site.xml、core-site.xml、hdfs-env.sh、
hdfs-site.xml配置副本数。

hdfs-site.xml配置web页面。

core-sit.xml配置节点端口。

hdfs-site.xml配置指定hadoop运行时产生文件的存储目录
配置hadoop-env.sh中的JAVA_HOME。
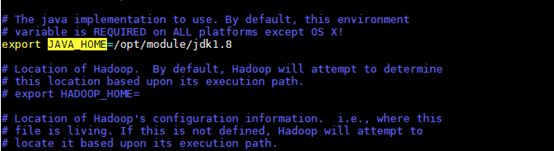
接下来修改yarn的相关配置文件。
修改mapred-site.xml、yarn-site.xml、mapred-env.sh。
配置MapReduce程序运行在yarn上。

配置resourcemanager的地址和reduce的数据获取方式。

向mapred-env.sh中添加JAVA_HOME。

切换root用户修改/etc/profile文件,向里面添加HADOOP_HOME。
![]()
![]()
Source使配置文件生效。
格式化namenode看到successfully格式化成功。


启动服务。

使用jps查看启动成功的服务。

Web访问192.168.10.101:50070访问成功。

刚格式化好的hdfs是完全空的,可以执行命令创建文件夹并上传文件。

这里我将jdk包作为测试上传到hdfs。
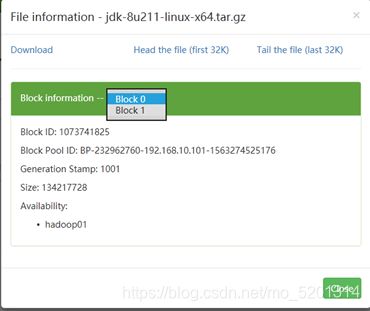
可以在web管理页面中看到上传的文件有两个块有两个副本。(hadoop2.x以上默认副本大小为128MB,副本数是在hdfs配置文件里面配置的)
到这里单节点安装就完成了。
- 完全分布式安装。
完全分布式安装hadoop组件运行在多个物理节点上,这里对应多台虚拟机。这里我的计划是装一个四节点的集群,各组件分布如下。

因为需要四台虚拟机所以还需要在创建三台。这里可以直接克隆hadoop01,这样可以省去很多基础环境配置。只需要配置hostname、IP等属性即可。接下来以hadoop02作为示例演示。hadoop03和hadoop04和hadoop02相同就不再演示。

可以看到这台克隆来的虚拟机的属性还是hadoop01的,目前和hadoop01是一样的。然后使用root账户登录进行配置修改。
修改/etc/hostname和/etc/sysconfig/network-scripts/ifcfg-ens33 配置文件然后重启生效,接下来就可以用ssh工具进行连接了。
通过克隆虚拟机然后修改配置现在得到了基本配置完成的四个节点,但是还需要重新配置免密登录,因为之前配置的只有hadoop01的免密登录,想要四节点之间互相免密登录还需要重新配置。命令如下。(配置免密登录的时候注意用户切换,要使用hadoop用户配置免密登录)
[hadoop@hadoop02 ~]# ssh-keygen -t rsa
[hadoop@hadoop02 ~]# ssh-copy-id hadoop01
[hadoop@hadoop02 ~]# ssh-copy-id hadoop02
[hadoop@hadoop02 ~]# ssh-copy-id hadoop03
[hadoop@hadoop02 ~]# ssh-copy-id hadoop04
这样四个节点的基础环境就配置成功了。
由于HA需要zookeeper,所以需要先安装zookeeper。下载地址如下。
https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
我之前已经下载好并上传至/opt/software路径下,所以这里直接解压。
解压zookeeper到/etc/module路径下。然后进入解压的文件夹进行配置。
![]()
在zookeeper安装文件夹下创建Data目录。

然后cd到conf文件夹下
将zoo_sample.cfg更名为zoo.cfg。然后进入该文件进行配置。
![]()
![]()
配置dataDir添加dataLogDir,并在末尾添加zookeeper所有节点信息,然后保存退出。

接下来进入之前创建的Data目录下创建一个名为myid的文件,里面添加上zookeeper节点号数字。比如一号节点里面就是一个1。
![]()

这样一个zookeeper就配置完成了。然后切换root用户配置环境变量。

![]()
然后切换至hadoop用户用scp将配置好的zookeeper文件夹发送至其他需要安装的节点。这里需要发送至hadoop02和hadoop03。
![]()
![]()
然后到对应节点去修改之前创建的myid文件,将里面的数字改为节点号。Hadoop02里面改为2.
hadoop03里面改为3.
并修改这两个节点的环境变量。
然后就可以启动zookeeper了。

使用命令分别在三台安装了zookeeper的节点上启动zookeeper。
使用命令查看三个节点上zookeeper的状态。



可以看到一个leader其他的都是follower,说明安装正确没有问题。
接下来就可以进行hadoop的完全分布式配置了。
因为其他三个节点都是由hadoop01克隆过来的所以其他节点修改配置文件即可完成配置安装。
接下来配置hadoop分布式安装的配置文件。需要配置以下文件。
core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
core-site.xml
fs.defaultFS
hdfs://mycluster
hadoop.tmp.dir
/opt/module/hadoop-2.7.6/data/ha/tmp
ha.zookeeper.quorum
hadoop01:2181,hadoop02:2181,hadoop03:2181
hdfs-site.xml
dfs.replication
2
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
hadoop01:9000
dfs.namenode.rpc-address.mycluster.nn2
hadoop02:9000
dfs.namenode.http-address.mycluster.nn1
hadoop01:50070
dfs.namenode.http-address.mycluster.nn2
hadoop02:50070
dfs.namenode.shared.edits.dir
qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/mycluster
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/home/hadoop/.ssh/id_rsa
dfs.journalnode.edits.dir
/opt/module/hadoop-3.1.2/data/ha/jn
dfs.permissions.enable
false
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.automatic-failover.enabled
true
mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop03:10020
mapreduce.jobhistory.webapp.address
hadoop03:19888
mapreduce.jobhistory.joblist.cache.size
20000
mapreduce.jobhistory.done-dir
${yarn.app.mapreduce.am.staging-dir}/history/done
mapreduce.jobhistory.intermediate-done-dir
${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate
yarn.app.mapreduce.am.staging-dir
/tmp/hadoop-yarn/staging
yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
rmCluster
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
hadoop01
yarn.resourcemanager.hostname.rm2
hadoop02
yarn.resourcemanager.zk-address
hadoop01:2181,hadoop02:2181,hadoop03:2181
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
然后修改/opt/module/hadoop-3.1.2/etc/hadoop/路径下的workers文件。(在hadoop1.x和hadoop2.x中是slaves文件,但是hadoop3.x中是workers文件)
workers文件指定的是datanode的地址和journalnode的地址。
配置完成后用scp将配置好的文件整个目录发往其他节点。

03节点和04节点也要发送。
然后先启动zookeeper服务,再启动journalnode。(一定要先启动zookeeper)
可以看到在启动了journalnode之后hadoop目录中data路径下多了一个ha文件夹。

然后在namenode1上格式化namenode。

看到successfully说明格式化成功。然后在hadoop01上启动namenode。
可以看到namenode已经启动成功。然后在hadoop02上同步namenode。
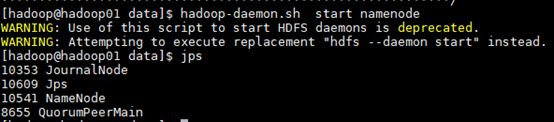
同步成功。

启动hadoop02上的namenode。
![]()
在hadoop01上启动所有的datanode再去Hadoop可以看到datanode启动成功。

此时可以进入web页面查看状态,端口50070.


看到hadoop01和hadoop02的状态都是standby。在hadoop01上格式化ZKFC,然后其中一台变成active。
Hadoop集群分布式安装完成。