CentOS系统部署Hadoop完全分布式集群
查看当前使用的CentOS版本及JDK、Hadoop版本,结果如下截图:

Hadoop全分布部署与伪分布的单机部分完全相同,唯有hadoop的文件配置略有不同,本文建立在伪分布部署的基础上重新修改配置文件,伪分布部署可见文档博文CentOS系统部署 Hadoop 伪分布模
一、配置主节点 master
前提:有已建好的单机环境,或伪分布环境也可
1、修改主机名
[root@cMaster hadoop]# vim /etc/hostname
//将主节点机器名修改为master
[root@master ~]# cat /etc/hostname
master
[root@master ~]#
2、修改配置文件 core-site.xml
[root@master ~]# cd /usr/local/hadoop //进入hadoop目录
[root@master hadoop]# vim etc/hadoop/core-site.xml //进入配置文件
//在标签
fs.defaultFS
hdfs://master:8020
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
io.file.buffer.size
2048
/*代码解析
defaultFS用于配置hdfs地址;tmp配置保存临时文件的目录;buffer 配置操作hdfs缓冲区大小
*/
3、修改配置文件 yarn-site.xml
[root@master hadoop]# vim etc/hadoop/yarn-site.xml
//在标签
yarn.resourcemanager.hostname
master
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8031
yarn.resourcemanger.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
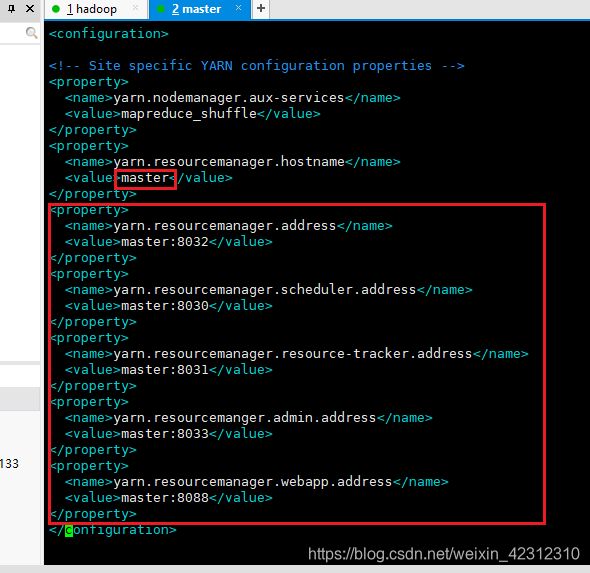
配置参数解析:上面yarn配置文件中的第一个标签内容用于指定yarn的ResourceManager管理界面的地址,不配的话,Active Node始终为0;最后一个标签内容用于配置连接外网的IP地址。
4、修改配置文件 hdfs-site.xml
[root@master hadoop]# vim etc/hadoop/hdfs-site.xml
//在标签
dfs.http.address
master:50700

5、修改配置文件 mapred-site.xml.template
[root@master hadoop]# vim etc/hadoop/mapred-site.xml.template
//在标签
mapreduce.jobhistory.address
master:10020
mapreducce.jobhistory.webapp.address
master:19888
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=$HADOOP_HOME

6、配置 workers文件
[root@master hadoop]# vim etc/hadoop/workers
//删除localhost,写入DataNode节点主机名slave0 slave1
slave0
slave1注意:若是hadoop2.0版本的此处配置slaves文件
二、配置从节点 slave
1、虚拟机克隆
通过虚拟机克隆技术,从主节点机器master克隆出两台从节点机器 slave0 与 slave1 。选择克隆机器单击鼠标右键,选择管理中的克隆,其中克隆方法选择完整克隆,虚拟机名称和安装位置可自定义设置,其他默认下一步即可。

2、修改机器名
[root@master ~]# vim /etc/hostname
[root@slave0 hadoop]# cat /etc/hostname
slave0
[root@slave0 hadoop]#
[root@slave1 ~]# cat /etc/hostname
slave1
[root@slave1 ~]# 3、重新配置三台机器的 hdfs-site.xml 文件
机器master中只需配置NameNode节点,所以删去DataNode的配置内容,机器slave0 与slave1不需要配置NameNode节点内容,所以删其配置内容。


三、格式化 重启 hadoop
1、分别重建HDFS目录
1)重建 master 的 namenode文件夹
[root@master ~]# rm -rf /usr/local/hadoop/hdfs
[root@master ~]# mkdir -p /usr/local/hadoop/hdfs/namenode
[root@master ~]# chown -R root:root /usr/local/hadoop
2)重建 slave0 的 datanode文件夹
[root@slave0 ~]# rm -rf /usr/local/hadoop/hdfs
[root@slave0 ~]# mkdir -p /usr/local/hadoop/hdfs/datanode
[root@slave0 ~]# chown -R root:root /usr/local/hadoop3)重建 slave1 的 datanode 文件夹
[root@slave1 ~]# rm -rf /usr/local/hadoop/hdfs
[root@slave1 ~]# mkdir -p /usr/local/hadoop/hdfs/datanode
[root@slave1 ~]# chown -R root:root /usr/local/hadoop2、主节点 master 下格式化并重启
[root@master ~]# hadoop namenode -format
[root@master ~]# start-dfs.sh
[root@master ~]# start-yarn.sh
3、启动成功后 jps 命令查看 master 的四个进程

4、查看slave 的三个进程

