oracle数据库用法
oracle数据库常用函数的用法
1:oracle 中的 row_number() over() 分析函数的用法
row_number() over(partition by col1 order by col2) 表示根据col1分组,在分组内部根据col2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内是连续且唯一的)。
注意:在使用over等开窗函数时,over里头的分组及排序的执行晚于“where,group by,order by”的执行。
select * from T1;
| ID | NAME | DATE1 |
|---|---|---|
| 101 | aaa | 09-SEP-13 |
| 101 | bbb | 10-SEP-13 |
| 101 | ccc | 11-SEP-13 |
| 102 | ddd | 08-SEP-13 |
| 102 | eee | 11-SEP-13 |
SELECT ID,NAME,DATE1,ROW_NUMBER() OVER(partition by ID order by DATE1 desc) as RN FROM T1;
| ID | NAME | DATE1 |
|---|---|---|
| 101 | ccc | 11-SEP-13 |
| 101 | bbb | 10-SEP-13 |
| 101 | aaa | 09-SEP-13 |
| 102 | eee | 11-SEP-13 |
| 102 | ddd | 08-SEP-13 |
2:oracle 中的 row_number() over() 与rank(),dense_rank()函数的区别
row_number的用途非常广泛,排序最好用它,它会为查询出来的每一行记录生成一个序号,依次排序且不会重复,注意使用row_number函数时必须要用over子句选择对某一列进行排序才能生成序号。
rank函数用于返回结果集的分区内每行的排名,行的排名是相关行之前的排名数加一。简单来说rank函数就是对查询出来的记录进行排名,与row_number函数不同的是,rank函数考虑到了over子句中排序字段值相同的情况,如果使用rank函数来生成序号,over子句中排序字段值相同的序号是一样的,后面字段值不相同的序号将跳过相同的排名号排下一个,也就是相关行之前的排名数加一,可以理解为根据当前的记录数生成序号,后面的记录依此类推。
dense_rank函数的功能与rank函数类似,dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续。dense_rank函数出现相同排名时,将不跳过相同排名号,rank值紧接上一次的rank值。在各个分组内,rank()是跳跃排序,有两个第一名时接下来就是第三名,dense_rank()是连续排序,有两个第一名时仍然跟着第二名。
select * from student;
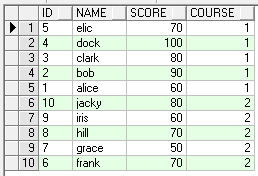
--row_number() 顺序排序 此处任务:现在需要按照课程对学生的成绩进行排序
select name,course,row_number() over(partition by course order by score desc) rank from student;

--rank() 跳跃排序,如果有两个第一级别时,接下来是第三级别
select name,course,rank() over(partition by course order by score desc) rank from student;
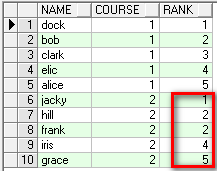
--dense_rank() 连续排序,如果有两个第一级别时,接下来是第二级别
select name,course,dense_rank() over(partition by course order by score desc) rank from student;
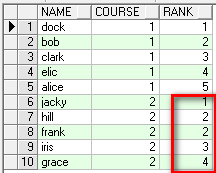
取得每门课程的第一名:
--每门课程第一名只取一个:
select * from (select name,course,row_number() over(partition by course order by score desc) rank from student) where rank=1;
--每门课程第一名取所有:
select * from (select name,course,dense_rank() over(partition by course order by score desc) rank from student) where rank=1;
--每门课程第一名取所有:
select * from (select name,course,rank() over(partition by course order by score desc) rank from student) where rank=1;
关于Parttion by:
Parttion by关键字是Oracle中分析性函数的一部分,用于给结果集进行分区。它和聚合函数Group by不同的地方在于它只是将原始数据进行名次排列,能够返回一个分组中的多条记录(记录数不变),而Group by是对原始数据进行聚合统计,一般只有一条反映统计值的结果(每组返回一条)。
总结:
在使用排名函数的时候需要注意以下三点:
1、排名函数必须有 OVER 子句。
2、排名函数必须有包含 ORDER BY 的 OVER 子句。
3、分组内从1开始排序。
3:oracle 中to_char函数的用法
Oracle to_char函数的功能是将数值型或者日期型转化为字符型,下面就为您详细介绍Oracle to_char函数的使用
Postgres 格式化函数提供一套有效的工具用于把各种数据类型(日期/时间,int,float,numeric)转换成格式化的字符串以及反过来从格式化的字符串转换成原始的数据类型。
注意:所有格式化函数的第二个参数是用于转换的模板。
| 函数 | 返回 | 描述 | 例子 |
|---|---|---|---|
| to_char(timestamp, text) | text | 把 timestamp 转换成 string | to_char(timestamp ‘now’,‘HH12:MI:SS’) |
| to_char(int, text) | text | 把 int4/int8 转换成 string | to_char(125, ‘999’) |
| to_char(float, text) | text | 把 float4/float8 转换成 string | to_char(125.8, ‘999D9’) |
| to_char(numeric, text) | text | 把 numeric 转换成 string | to_char(numeric ‘-125.8’, ‘999D99S’) |
| to_date(text, text) | date | 把 string 转换成 date | to_date(‘05 Dec 2000’, ‘DD Mon YYYY’) |
| to_timestamp(text, text) | date | 把 string 转换成 timestamp | to_timestamp(‘05 Dec 2000’, ‘DD Mon YYYY’) |
| to_number(text, text) | numeric | 把 string 转换成 numeric | to_number(‘12,454.8-’, ‘99G999D9S’) |
select to_date('2005-01-01 ','yyyy-MM-dd') from dual;
select to_char(sysdate,'yyyy-MM-dd HH24:mi:ss') from dual;
如上,是将时间类型转换为逗号后的字符串类型。
4:Oracle中的NVL函数
Oracle中函数除了字符串处理函数,日期函数,数学函数,以及转换函数等等之外,还有一类函数是通用函数。主要有:NVL,NVL2,NULLIF,COALESCE,这几个函数用在各个类型上都可以。
1:NVL函数的格式如下:NVL(expr1,expr2)
含义是:如果oracle第一个参数为空那么显示第二个参数的值,如果第一个参数的值不为空,则显示第一个参数本来的值。
2:NVL2函数的格式如下:NVL2(expr1,expr2, expr3)
含义是:如果该函数的第一个参数为空那么显示第二个参数的值,如果第一个参数的值不为空,则显示第三个参数的值。
3:NULLIF函数的格式如下:NULLIF(exp1,expr2)
含义是:函数的作用是如果exp1和exp2相等则返回空(NULL),否则返回第一个值。
4:Coalese函数格式如下:Coalesce(expr1, expr2, expr3…… exprn)
含义是:函数的作用是和NVL的函数有点相似,其优势是有更多的选项。
可以指定多个表达式的占位符。所有表达式必须是相同类型,或者可以隐性转换为相同的类型。
返回表达式中第一个非空表达式。
SELECT COALESCE(NULL,NULL,3,4,5) FROM dual 其返回结果为:3
如果所有自变量均为 NULL,则 COALESCE 返回 NULL 值。
COALESCE(expression1,…n) 与此 CASE 函数等价:这个函数实际上是NVL的循环使用,在此就不举例子了。
SELECT ROW_NUMBER() OVER(ORDER BY SUM(A.VISIT_COUNT) DESC) NO, TO_CHAR(A.DATE_YEAR, 'yyyymmdd') 日期,
A.DEPT_CODE 科室代码,
NVL(B.DEPT_NAME, A.DEPT_NAME) 科室名称,
SUM(A.VISIT_COUNT) 就诊人次
FROM T_F_OUT_COUNT_D_MRCB A left join t_d_Dept B on A.DEPT_CODE=b.DEPT_CODE<br> WHERE TO_CHAR(A.DATE_YEAR, 'yyyymmdd') = to_char(日期: ,'yyyymmdd')
and A.VISIT_COUNT<>0
and A.COUNT_TYPE='院本部'
and NVL(B.DEPT_NAME, A.DEPT_NAME) NOT IN ('医务科','病理科','质控科','戒毒所','拘留所','超声介入科','影像科','收检中心','ICU门诊','公安三所','体检科')
GROUP BY TO_CHAR(DATE_YEAR, 'yyyymmdd'),
A.DEPT_CODE,
NVL(B.DEPT_NAME, A.DEPT_NAME)
ORDER BY SUM(A.VISIT_COUNT) DESC

5:Oracle中的LAG和LEAD分析函数
lag与lead函数是跟偏移量相关的两个分析函数,通过这两个函数可以在一次查询中取出同一字段的前N行的数据(lag)和后N行的数据(lead)作为独立的列,从而更方便地进行进行数据过滤。这种操作可以代替表的自联接,并且LAG和LEAD有更高的效率。
over()表示 lag()与lead()操作的数据都在over()的范围内,他里面可以使用partition by 语句(用于分组) order by 语句(用于排序)。partition by a order by b表示以a字段进行分组,再 以b字段进行排序,对数据进行查询。
例如:lead(field, num, defaultvalue) field需要查找的字段,num往后查找的num行的数据,defaultvalue没有符合条件的默认值。
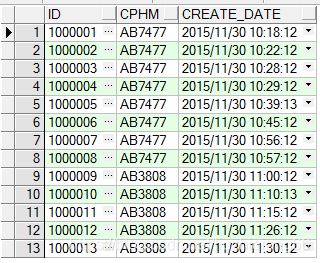
a、获取当前记录的id,以及下一条记录的id
select t.id id ,
lead(t.id, 1, null) over (order by t.id) next_record_id, t.cphm
from tb_test t
order by t.id asc
运行结果如下:

b、获取当前记录的id,以及上一条记录的id
select t.id id ,
lag(t.id, 1, null) over (order by t.id) next_record_id, t.cphm
from tb_test t
order by t.id asc
运行结果如下:
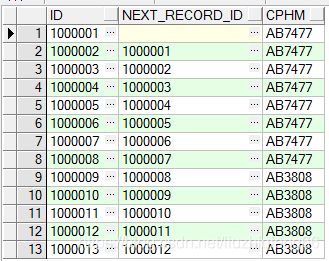
c、获取号牌号码相同的,当前记录的id与,下一条记录的id(使用partition by)
select t.id id,
lead(t.id, 1, null) over(partition by cphm order by t.id) next_same_cphm_id, t.cphm
from tb_test t
order by t.id asc
运行结果如下:

d、查询 cphm的总数,当create_date与下一条记录的create_date时间间隔不超过10分钟则忽略。
select cphm, count(1) total from
(
select t.id,
t.create_date t1,
lead(t.create_date,1, null) over( partition by cphm order by create_date asc ) t2,
( lead(t.create_date,1, null) over( partition by cphm order by create_date asc ) - t.create_date ) * 86400 as itvtime,
t.cphm
from tb_test t
order by t.cphm, t.create_date asc
) tt
where tt.itvtime >= 600 or tt.itvtime is null
group by tt.cphm
结果如下:

6:Oracle中的DECODE函数
DECODE 的原理:if-then-else逻辑
在逻辑编程中,经常用到If – Then –Else 进行逻辑判断。在DECODE的语法中,实际上就是这样的逻辑处理过程。它的语法如下:
DECODE(value, if1, then1, if2,then2, if3,then3, . . . else )
Value 代表某个表的任何类型的任意列或一个通过计算所得的任何结果。当每个value值被测试,如果value的值为if1,Decode 函数的结果是then1;如果value等于if2,Decode函数结果是then2;等等。事实上,可以给出多个if/then 配对。如果value结果不等于给出的任何配对时,Decode 结果就返回else 。
需要注意的是,这里的if、then及else 都可以是函数或计算表达式。
含义解释:
DECODE(条件,值1,翻译值1,值2,翻译值2,…值n,翻译值n,缺省值)
该函数的含义如下:
IF 条件=值1 THEN
RETURN(翻译值1)
ELSIF 条件=值2 THEN
RETURN(翻译值2)
…
ELSIF 条件=值n THEN
RETURN(翻译值n)
ELSE
RETURN(缺省值)
END IF
1: 使用decode判断字符串是否一样
在逻辑编程中,经常用到If – Then –Else 进行逻辑判断。在DECODE的语法中,实际上就是这样的逻辑处理过程。它的语法如下:
sql测试
select empno,decode(empno,7369,'smith',7499,'allen',7521,'ward',7566,'jones','unknow') as name from emp where rownum<=10
输出结果
7369 smith,7499 allen,7521 ward,7566 jones,7654 unknow,7698 unknow,7782 unknow
sql测试
select *from users;

select id, username, age, decode(sex,0,'男',1,'女') from users;

2: 使用decode比较大小
select decode(sign(var1-var2),-1,var 1,var2) from dual
sign()函数根据某个值是0、正数还是负数,分别返回0、1、-1
sql测试
select decode(sign(100-90),-1,100,90) from dual
输出结果

100-90=10>0 则会返回1,所以decode函数最终取值为90
反正
select decode(sign(100-90),1,100,90) from dual
输出结果

100-90=10>0返回1,判断结果为1,返回第一个变量100,最终输出结果为100
3: 使用decode函数分段
工资大于5000为高薪,工资介于3000到5000为中等,工资小于3000为低薪
sql测试
SELECT
ename,sal,DECODE(SIGN(sal - 5000),1, 'high sal', 0, 'high sal', \- 1,
DECODE(SIGN(sal - 3000),1, 'mid sal',0, 'mid sal',- 1,
DECODE(SIGN(sal - 1000), 1, 'low sal',0, 'low sal', \- 1, 'low sal')))
FROM emp
输出结果
SMITH 800 low sal,ALLEN 1600 low sal,WARD 1250 low sal,JONES 2975 low sal
MARTIN 1250 low sal,BLAKE 2850 low sal,CLARK 2450 low sal,SCOTT 3000 mid sal
KING 5000 high sal,TURNER 1500 low sal,ADAMS 1100 low sal,JAMES 950 low sal
FORD 3000 mid sal,MILLER 1300 low sal
4: 使用decode函数来使用表达式来搜索字符串
decode (expression, search_1, result_1, search_2, result_2, ...., search_n, result_n, default)
decode函数比较表达式和搜索字,如果匹配,返回结果;如果不匹配,返回default值;如果未定义default值,则返回空值。
sql测试
SELECT ENAME,SAL,DECODE(INSTR(ENAME, 'S'),0,'不含有s','含有s') AS INFO FROM EMP
输出结果
SMITH 800 含有s,ALLEN 1600 不含有s,WARD 1250 不含有s,JONES 2975 含有s
MARTIN 1250 不含有s,BLAKE 2850 不含有s,CLARK 2450 不含有s,SCOTT 3000 含有s
KING 5000 不含有s,TURNER 1500 不含有s,ADAMS 1100 含有s,JAMES 950 含有s
FORD 3000 不含有s,MILLER 1300 不含有s
sql测试
SELECT *
FROM (SELECT TO_CHAR(DATE_YEAR, 'yyyymmdd') 日期,
'门急诊' 就诊类型,
SUM(VISIT_COUNT) 门急诊就诊人次,
LAG(SUM(VISIT_COUNT), 1) OVER(ORDER BY TO_CHAR(DATE_YEAR, 'yyyymmdd')) 门急诊人次环期,
DECODE(LAG(SUM(VISIT_COUNT), 1)
OVER(ORDER BY TO_CHAR(DATE_YEAR, 'yyyymmdd')),
0,
0,
SUM(VISIT_COUNT) / LAG(SUM(VISIT_COUNT), 1)
OVER(ORDER BY TO_CHAR(DATE_YEAR, 'yyyymmdd'))) - 1 环比增长率
FROM T_F_OUT_COUNT_D_MRCB
WHERE T_F_OUT_COUNT_D_MRCB.COUNT_TYPE='院本部'
GROUP BY TO_CHAR(DATE_YEAR, 'yyyymmdd'))
WHERE 日期 = TO_CHAR( to_date('2020-08-19', 'yyyy-MM-dd') , 'yyyymmdd')
ORDER BY 日期
输出结果

7:Oracle中的case when函数用法
case when 的原理:类似于DECODE,if-then-else逻辑,是一个通用条件的表达式
在逻辑编程中,经常用到If – Then –Else 进行逻辑判断。在case when的语法中,实际上就是这样的逻辑处理过程。它的语法如下:
case
when 条件1 then action1
when 条件2 then action2
when 条件3 then action3
when 条件N then actionN
else action
end
语法含义解释:
条件condition:返回一个布尔结果的表达式。如果结果为false,则以相同的方式评估后续when子句。
action行动结果result :当关联条件为真时要返回的值。
ELSE action:如果没有条件,则CASE表达式的值是ELSE子句中的结果。 如果省略ELSE子句且没有条件匹配,则结果为null。
CASE WHEN 表达式有两种形式
--简单Case函数
CASE sex
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他' END
--Case搜索函数
CASE
WHEN sex = '1' THEN '男'
WHEN sex = '2' THEN '女'
ELSE '其他' END
SELECT a, CASE
WHEN a=1 THEN 'one'
WHEN a=2 THEN 'two'
ELSE 'other' END
FROM test;
结果如下:
a | case
—+——-
1 | one
2 | two
3 | other
举例如:判断现在是几月
select case substr('20181118',5,2)
when '08' then '8yue'
when '09' then '9yue'
when '10' then '10yue'
when '11' then '11yue'
when '12' then '12yue'
else 'other'
end
from dual;
结果如下:11yue
实验表如下:sno:学号,km:科目,score:成绩,grade:等级
create table score(sno number,km varchar2(8),score int,grade varchar2(4) default null);
insert into score(sno,km,score) values(1,'yw',65);
insert into score(sno,km,score) values(2,'sx',76);
insert into score(sno,km,score) values(3,'yw',86);
insert into score(sno,km,score) values(4,'yw',94);
select * from score;
SNO KM SCORE GRADE
---------- ------------------------ ---------- ------------
1 yw 65
2 sx 76
3 yw 86
4 yw 94
问题:给学生成绩分等级,优秀、良好、中等、合格
update score set grade =
(select grade from
(select sno,case
when score >=90 then 'A'
when score >=80 then 'B'
when score >=70 then 'C'
when score >=60 then 'D'
else 'F'
end as grade
from score) a
where a.sno=score.sno
);
select * from score;
SNO KM SCORE GRADE
---------- ------------------------ ---------- ----------
1 yw 65 D
2 sx 76 C
3 yw 86 B
4 yw 94 A
8:Oracle中的substr()(字符截取函数)与instr()(字符查找函数)用法
substr() 的原理:
格式1: substr(string string, int a, int b);
格式2:substr(string string, int a) ;
解释:
格式1:
1、string 需要截取的字符串
2、a 截取字符串的开始位置(注:当a等于0或1时,都是从第一位开始截取)
3、b 要截取的字符串的长度
格式2:
1、string 需要截取的字符串
2、a 可以理解为从第a个字符开始截取后面所有的字符串。
0、select substr('123456',3,2) from dual; //返回结果:34
1、select substr('HelloWorld',0,3) value from dual; //返回结果:Hel,截取从“H”开始3个字符
2、select substr('HelloWorld',1,3) value from dual; //返回结果:Hel,截取从“H”开始3个字符
3、select substr('HelloWorld',2,3) value from dual; //返回结果:ell,截取从“e”开始3个字符
4、select substr('HelloWorld',0,100) value from dual; //返回结果:HelloWorld,100虽然超出预处理的字符串最长度,但不会影响返回结果,系统按预处理字符串最大数量返回。
5、select substr('HelloWorld',5,3) value from dual; //返回结果:oWo
6、select substr('Hello World',5,3) value from dual; //返回结果:o W (中间的空格也算一个字符串,结果是:o空格W)
7、select substr('HelloWorld',-1,3) value from dual; //返回结果:d (从后面倒数第一位开始往后取1个字符,而不是3个。原因:下面红色 第三个注解)
8、select substr('HelloWorld',-2,3) value from dual; //返回结果:ld (从后面倒数第二位开始往后取2个字符,而不是3个。原因:下面红色 第三个注解)
9、select substr('HelloWorld',-3,3) value from dual; //返回结果:rld (从后面倒数第三位开始往后取3个字符)
10、select substr('HelloWorld',-4,3) value from dual; //返回结果:orl (从后面倒数第四位开始往后取3个字符)
11、select substr('HelloWorld',0) value from dual; //返回结果:HelloWorld,截取所有字符
12、select substr('HelloWorld',1) value from dual; //返回结果:HelloWorld,截取所有字符
13、select substr('HelloWorld',2) value from dual; //返回结果:elloWorld,截取从“e”开始之后所有字符
14、select substr('HelloWorld',3) value from dual; //返回结果:lloWorld,截取从“l”开始之后所有字符
15、select substr('HelloWorld',-1) value from dual; //返回结果:d,从最后一个“d”开始 往回截取1个字符
16、select substr('HelloWorld',-2) value from dual; //返回结果:ld,从最后一个“d”开始 往回截取2个字符
17、select substr('HelloWorld',-3) value from dual; //返回结果:rld,从最后一个“d”开始 往回截取3个字符
(注:当a等于0或1时,都是从第一位开始截取(如:1和2))
(注:假如HelloWorld之间有空格,那么空格也将算在里面(如:5和6))
(注:虽然7、8、9、10截取的都是3个字符,结果却不是3 个字符; 只要 |a| ≤ b,取a的个数(如:7、8、9);当
|a| ≥ b时,才取b的个数,由a决定截取位置(如:9和10))
(注:当只有两个参数时;不管是负几,都是从最后一个开始 往回截取(如:15、16、17))
instr() 的原理:
格式一:instr( string1, string2 ) / instr(源字符串, 目标字符串)
格式二:instr( string1, string2 [, start_position [, nth_appearance ] ] ) / instr(源字符串, 目标字符串, 起始位置, 匹配序号)
解释:
string2 的值要在string1中查找,是从start_position给出的数值(即:位置)开始在string1检索,检索第nth_appearance(几)次出现string2。
注:在Oracle/PLSQL中,instr函数返回要截取的字符串在源字符串中的位置。只检索一次,也就是说从字符的开始到字符的结尾就结束。
1 select instr('helloworld','l') from dual; --返回结果:3 默认第一次出现“l”的位置
2 select instr('helloworld','lo') from dual; --返回结果:4 即:在“lo”中,“l”开始出现的位置
3 select instr('helloworld','wo') from dual; --返回结果:6 即“w”开始出现的位置
4 select instr('helloworld','l',2,2) from dual; --返回结果:4 也就是说:在"helloworld"的第2(e)号位置开始,查找第二次出现的“l”的位置
5 select instr('helloworld','l',3,2) from dual; --返回结果:4 也就是说:在"helloworld"的第3(l)号位置开始,查找第二次出现的“l”的位置
6 select instr('helloworld','l',4,2) from dual; --返回结果:9 也就是说:在"helloworld"的第4(l)号位置开始,查找第二次出现的“l”的位置
7 select instr('helloworld','l',-1,1) from dual; --返回结果:9 也就是说:在"helloworld"的倒数第1(d)号位置开始,往回查找第一次出现的“l”的位置
8 select instr('helloworld','l',-2,2) from dual; --返回结果:4 也就是说:在"helloworld"的倒数第1(d)号位置开始,往回查找第二次出现的“l”的位置
9 select instr('helloworld','l',2,3) from dual; --返回结果:9 也就是说:在"helloworld"的第2(e)号位置开始,查找第三次出现的“l”的位置
10 select instr('helloworld','l',-2,3) from dual; --返回结果:3 也就是说:在"helloworld"的倒数第2(l)号位置开始,往回查找第三次出现的“l”的位置
注:MySQL中的模糊查询 like 和 Oracle中的 instr() 函数有同样的查询效果; 如下所示:
MySQL: select * from tableName where name like '%helloworld%';
Oracle:select * from tableName where instr(name,'helloworld')>0; --这两条语句的效果是一样的

9:Oracle中的TRUNC()(类似截取函数)用法
TRUNC()的原理:
语法格式:TRUNC(date[,fmt])
解释:
其中:date 一个日期值;fmt 日期格式。
该日期将按指定的日期格式截取;忽略它则由最近的日期截取。
select trunc(sysdate) from dual;--2017/2/13,返回当前时间
select trunc(sysdate,'yy') from dual;--2017/1/1,返回当年第一天
select trunc(sysdate,'mm') from dual;--2017/2/1,返回当月的第一天
select trunc(sysdate,'d') from dual;--2017/2/12,返回当前星期的第一天,即星期天
select trunc(sysdate,'dd') from dual;--2017/2/13,返回当前日期,今天是2017/2/13
select trunc(sysdate ,'HH24') from dual;--2017/2/13 15:00:00,返回本小时的开始时间
select trunc(sysdate ,'MI') from dual;--2017/2/13 15:13:00,返回本分钟的开始时间
TRUNC()函数处理number型数字
语法格式:TRUNC(number[,decimals])
解释:
其中: number 待做截取处理的数值;decimals 指明需保留小数点后面的位数,默认值为 0。可选项,忽略它则截去所有的小数部分。
注意:截取时并不对数据进行四舍五入。
select trunc(123.458) from dual --123
select trunc(123.458,0) from dual --123
select trunc(123.458,1) from dual --123.4
select trunc(123.458,-1) from dual --120
select trunc(123.458,-4) from dual --0
select trunc(123.458,4) from dual --123.458
select trunc(123) from dual --123
select trunc(123,1) from dual --123
select trunc(123,-1) from dual --120
10:Oracle中的MOD函数的使用用法
mod(m,n)的原理:
格式: mod(m,n)
解释:
格式:
(1):MOD返回m除以n的余数,如果n是0,返回m。
(2):这个函数以任何数字数据类型或任何非数值型数据类型为参数,可以隐式地转换为数字数据类型。
SELECT MOD(1200, 500) FROM dual;
//因为1200/500结果为2余200,所以输出结果:200
SELECT MOD(1200, 0) FROM dual;
//因为后面参数为0,所以输出结果前面的参数:1200
SELECT MOD(12, 5) FROM dual;//返回结果:2
SELECT MOD(12, -5) FROM dual;//返回结果:2
SELECT MOD(-12, 5) FROM dual;//返回结果:-2
SELECT MOD(2, 1) FROM dual;//返回结果:0
11:Oracle中的rollup()(分组函数)用法
rollup()的原理:
rollup()是group by的一个扩展函数,初步的感觉是,可以多个列进行group by,然后分别进行统计求总和。rollup()在数据统计和报表生成过程中带来极大的便利,而且效率比起来Group By + Union组合方法效率高得多。这也体现了Oracle在SQL统计分析上人性化、自动化、高效率的特点。
语法格式:group by rollup(a,b)
解释:
这条语句相当于分组三次
第一次,a,b两个约束条件,即a相同,b也相同的分为同一组
第二次,只是用a一个条件进行分组,把上一次形成的结果在进行分组,把a相同的分为一组
第三次,没有约束条件,将整个表数据分为一组
这样三次之后,我们就有了三个分组条件,那么sum函数,就会给每一个分组都执行一次计算总和
select * from group_test;
GROUP_ID JOB NAME SALARY
---------- ---------- ---------- ----------
10 Coding Bruce 1000
10 Programmer Clair 1000
10 Architect Gideon 1000
10 Director Hill 1000
20 Coding Jason 2000
20 Programmer Joey 2000
20 Architect Martin 2000
20 Director Michael 2000
30 Coding Rebecca 3000
30 Programmer Rex 3000
30 Architect Richard 3000
30 Director Sabrina 3000
40 Coding Samuel 4000
40 Programmer Susy 4000
40 Architect Tina 4000
40 Director Wendy 4000
1、先看一下普通分组的效果:对group_id进行普通的group by操作—按照小组进行分组
select group_id,sum(salary) from group_test group by group_id;
GROUP_ID SUM(SALARY)
---------- -----------
30 12000
20 8000
40 16000
10 4000
2、对group_id进行普通的roolup操作—按照小组进行分组,同时求总计
select group_id,sum(salary) from group_test group by rollup(group_id);
GROUP_ID SUM(SALARY)
---------- -----------
10 4000
20 8000
30 12000
40 16000
40000
3、使用Group By语句翻译一下上面的SQL语句如下(union all一个统计所有数据的行):
select group_id,sum(salary) from group_test group by group_id
union all
select null, sum(salary) from group_test
order by 1;
GROUP_ID SUM(SALARY)
---------- -----------
10 4000
20 8000
30 12000
40 16000
40000
4、再看一个rollup两列的情况
select group_id,job,sum(salary) from group_test group by rollup(group_id, job);
GROUP_ID JOB SUM(SALARY)
---------- ---------- -----------
10 Coding 1000 第一次分组的sum总和计算
10 Director 1000
10 Architect 1000
10 Programmer 1000
10 4000 第二次分组添加的计算
20 Coding 2000
20 Director 2000
20 Architect 2000
20 Programmer 2000
20 8000
30 Coding 3000
30 Director 3000
30 Architect 3000
30 Programmer 3000
30 12000
40 Coding 4000
40 Director 4000
40 Architect 4000
40 Programmer 4000
40 16000
40000 第三次分组添加的计算
5、上面的SQL语句使用下面的Group By进行翻译
select group_id,job,sum(salary) from group_test group by group_id, job
union all
select group_id,null,sum(salary) from group_test group by group_id
union all
select null,null,sum(salary) from group_test
order by 1,2;
GROUP_ID JOB SUM(SALARY)
---------- ---------- -----------
10 Architect 1000
10 Coding 1000
10 Director 1000
10 Programmer 1000
10 4000
20 Architect 2000
20 Coding 2000
20 Director 2000
20 Programmer 2000
20 8000
30 Architect 3000
30 Coding 3000
30 Director 3000
30 Programmer 3000
30 12000
40 Architect 4000
40 Coding 4000
40 Director 4000
40 Programmer 4000
40 16000
40000
6、体验一下grouping函数的效果
select group_id,job,grouping(GROUP_ID),grouping(JOB),sum(salary) from group_test group by rollup(group_id, job);
GROUP_ID JOB GROUPING(GROUP_ID) GROUPING(JOB) SUM(SALARY)
---------- ---------- ------------------ ------------- -----------
10 Coding 0 0 1000
10 Director 0 0 1000
10 Architect 0 0 1000
10 Programmer 0 0 1000
10 0 1 4000
20 Coding 0 0 2000
20 Director 0 0 2000
20 Architect 0 0 2000
20 Programmer 0 0 2000
20 0 1 8000
30 Coding 0 0 3000
30 Director 0 0 3000
30 Architect 0 0 3000
30 Programmer 0 0 3000
30 0 1 12000
40 Coding 0 0 4000
40 Director 0 0 4000
40 Architect 0 0 4000
40 Programmer 0 0 4000
40 0 1 16000
1 1 40000
解释:如果显示“1”表示GROUPING函数对应的列(例如JOB字段)是由于ROLLUP函数所产生的空值对应的信息,即对此列进行汇总计算后的结果。如果显示“0”表示此行对应的这列参未与ROLLUP函数分组汇总活动。
Coding 0 0 3000
30 Director 0 0 3000
30 Architect 0 0 3000
30 Programmer 0 0 3000
30 0 1 12000
40 Coding 0 0 4000
40 Director 0 0 4000
40 Architect 0 0 4000
40 Programmer 0 0 4000
40 0 1 16000
1 1 40000
解释:如果显示“1”表示GROUPING函数对应的列(例如JOB字段)是由于ROLLUP函数所产生的空值对应的信息,即对此列进行汇总计算后的结果。如果显示“0”表示此行对应的这列参未与ROLLUP函数分组汇总活动。