redis SDS介绍
Redis面试中经常被问到,Redis效率为什么这么快,很多同学往往回答:
① Redis基于内存操作
② Redis是单线程的,采用了IO多路复用技术
③ Redis未使用C语言字符串,使用了SDS字符串
然而,很少有人能说清楚SDS字符串到底是什么,为什么使用SDS字符串比使用C语言字符串效率要高。
redis字符串(String)内存结构
字符串对象底层数据结构实现为简单动态字符串(SDS)和直接存储,但其编码方式可以是int、raw或者embstr,区别在于内存结构的不同。
1. int编码
字符串保存的是整数值,并且这个正式可以用long类型来表示,那么其就会直接保存在redisObject的ptr属性里,并将编码设置为int,如图:

2. raw编码
字符串保存的大于32字节的字符串值,则使用简单动态字符串(SDS)结构,并将编码设置为raw,此时内存结构与SDS结构一致,内存分配次数为两次,创建redisObject对象和sdshdr结构,如图:

3. embstr编码
字符串保存的小于等于32字节的字符串值,使用的也是简单的动态字符串(SDS结构),但是内存结构做了优化,用于保存顿消的字符串;内存分配也只需要一次就可完成,分配一块连续的空间即可,如图:

总结
- 在Redis中,存储long、double类型的浮点数是先转换为字符串再进行存储的
- raw与embstr编码效果是相同的,不同在于内存分配与释放,raw两次,embstr一次
- embstr 编码的字符串对象的所有数据都保存在一块连续的内存里面, 所以这种编码的字符串对象比起 raw 编码的字符串对象能够更好地利用缓存带来的优势
- int编码和embstr编码如果做追加字符串等操作,满足条件下会被转换为raw编码;embstr编码的对象是只读的,一旦修改会先转码到raw
什么是SDS
SDS全拼为:simple dynamic string,解释为:简单动态字符串。
C语言字符串使用长度为n+1的字符数组来表示长度为n的字符串,并且字符数组的最后一个元素总是空字符’\0’,因为这种字符串表示方式不能满足Redis对字符串在安全性、效率以及功能方面的要求,所以Redis自己构建了SDS,用于满足其需求。在Redis里,C语言字符串只用于一些无须对字符串值进行修改的地方,比如:日志。在Redis中,包含字符串值的键值对都是使用SDS实现的,除此之外,SDS还被用于AOF缓冲区、客户端状态的输入缓冲区。
SDS定义
struct sdshdr{
//字节数组
char buf[];
//buf数组中已使用字节数量
int len;
//buf数组中未使用字节数量
int free;
}
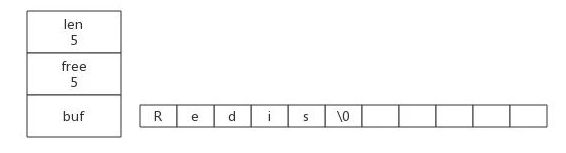
上图展示了一个SDS实例,len表示该SDS保存了一个5字节长度(不包含结束符)的字符串,free表示该SDS还有5个字节的未使用空间,buf是一个char类型的数组,保存了该SDS所存储的字符串值
为什么使用SDS
1. 相比C语言字符串,使获取字符串长度时间复杂度降为O(1)
C语言字符串不记录自身长度,如果想获取自身长度必须遍历整个字符串,对每个字符进行计数,这个操作时间复杂度是O(n)。相比较而言,Redis程序只要访问SDS的len属性就可以直接获取到字符串长度,时间复杂度为O(1),确保获取字符串长度不会成为Redis性能瓶颈,比如对字符串键反复执行strlen命令。如:获取“Redis”字符串长度时程序会直接访问len属性即可,该字符串长度为5。

2. 杜绝缓冲区溢出
假设程序里有两个在内存中紧邻的字符串s1和s2,s1的值为Redis,底层数组的值为[‘R’,‘e’,‘d’,‘i’,‘s’,’\0’],s2的值为Memcache,底层数组的值为[‘M’,‘e’,‘m’,‘c’,‘a’,‘c’,‘h’,‘e’,’\0’],在C语言中如果要执行strcat(s1, " cluster")把s1修改为Redis cluster,如果忘记在执行strcat命令之前为s1重新分配空间,那么在执行完strcat命令之后,s1底层数组的值变为[‘R’,‘e’,‘d’,‘i’,‘s’,’ ‘,‘c’,‘l’,‘u’,‘s’,‘t’,‘e’,‘r’,’\0’],s2底层数组的值变为[‘c’,‘l’,‘u’,‘s’,‘t’,‘e’,‘r’,’\0’,’\0’],s1的数据溢出到s2所在的内存空间,s2的值被意外修改。与C语言不同,当SDS API需要对SDS进行修改时,API会先检查SDS当前剩余空间是否满足修改之后所需的空间,如果不满足的话API会自动将SDS的空间扩展至修改之后所需空间大小,然后再执行实际的修改操作,所以SDS不会出现缓冲区溢出问题。(缓冲区扩充并非是直接扩充到所需要的空间大小,它和SDS空间分配策略有关,参见下一小节)

3. 减少修改字符串时带来的内存重分配次数
C语言字符串底层是使用一个n+1个字符长度的char类型数据实现的,所以每次增长或缩短一个C语言字符串,程序都要对这个字符串数组进行一次内存重分配操作:
- ① 如果程序执行的是增长字符串操作,比如strcat操作,在执行这个操作之前需要通过内存重分配扩展底层数组,如果忘记了则会造成缓冲区溢出。
- ② 如果程序执行的是缩短字符串操作,比如trim操作,在执行这个操作之前需要通过内存重分配释放字符串不再使用的内存空间,如果忘记了则会造成内存泄漏。
因为内存重分配涉及复杂的算法,并且可能需要执行系统调用,所以它通常是一个比较耗时的操作。Redis经常被用于速度要求严苛、数据被频繁修改的场合,如果每次修改字符串都需要执行一次内存重分配的话,那么对于性能会造成很大影响。
在SDS中通过未使用空间解除了字符串长度和底层数组长度之间的关联,在SDS中,buf数组长度不一定是字符串长度加1,数组中可能包含未使用的字节,这些字节的数量就是由SDS的free属性记录。通过未使用空间,SDS实现了空间预分配和惰性空间释放两种优化策略。
3.1 空间预分配
用于字符串增长操作,当字符串增长时,程序会先检查需不需要对SDS空间进行扩展,如果需要扩展,程序不仅会为SDS分配修改所必要的空间,还会为SDS分配额外的未使用空间,额外分配的未使用空间公式如下:
- ① 如果对SDS修改之后,SDS的长度(修改之后len属性的值)小于1MB,那么则分配和len属性同样大小的未使用空间,这时SDS的len属性和free属性的值相同。如:如果修改之后SDS的len将变为10字节,那么程序也会分配10字节的未使用空间,SDS的buf数组实际长度变为10 + 10 + 1 = 21(额外一个字节用于保存结束符\n)
- ② 如果对SDS修改之后,SDS的长度大于等于1MB,那么程序会分配1MB的未使用空间。如:修改之后的len将变为10MB,那么程序会分配1MB的未使用空间,SDS的bug数组长度为10MB + 1MB + 1byte
3.2 惰性空间释放
用于优化SDS的字符串收缩操作,当字符串收缩时,程序不会立即执行内存重分配来回收收缩后内存多出来的空间,而是使用free属性记录下来,以备将来使用。
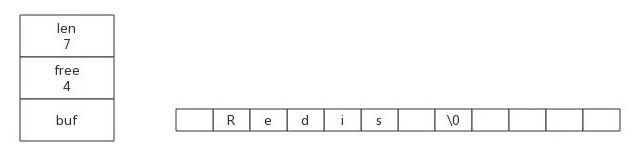

通过空间预分配,Redis可以减少连续执行字符串增长操作所需的内存重分配次数,通过惰性空间释放,SDS避免了缩短字符串时所需的内存重分配操作,并为将来由可能的增长操作提供了优化。