Python爬取东方财富网任意股票任意时间段的Ajax动态加载股票数据
导言
最近由于需求想爬取以下东方财富网的股票数据,但是发现没有想象那么简单,接下来我会讲述一下我遇到的问题以及是如何解决,最后成功的爬出了想要的数据。
查看网页源码
首先我们F12打开东方财富网网页源码,以指南针(300803)为例:
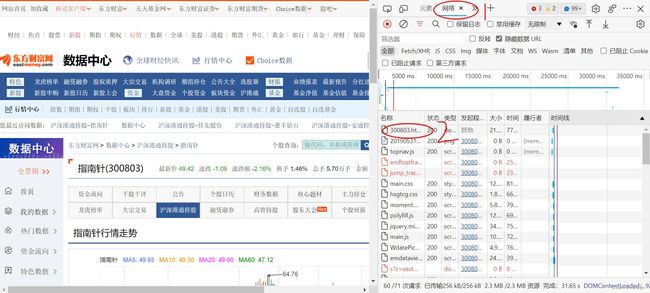
我们先点击网络,再点击300803.html,再选择右边弹出来的预览或响应,可以发现,源码中并没有我们想要的股票数据,但是再网页中又有我们想要的收盘价等数据,说明这很可能数据是Ajax动态加载出来的,一般而言数据会存储再一个json文件之中。
找出储存数据的json文件
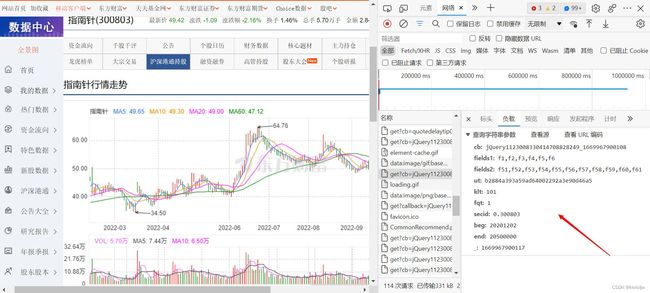
我们很容易找到当前网页中该股票的当日收盘价,所以我们可以以此为关键词进行搜索,搜索步骤为:在页面右边的网页信息页面,ctrl+F,即可打开搜索框,结果如下图所示,发现有三个url文件包含该数值:

点击进去可以发现里面都有大量的数据,这些数据也是网页所显示的数据来源,根据不同的数据需求,选择某一个url进行数据提取,接下来的数据提取以第二个URL为例,即K线图的原始数据。
解析URL地址
该URL地址为:
https://push2his.eastmoney.com/api/qt/stock/kline/get?cb=jQuery1123008330414708828249_1669967900108&fields1=f1%2Cf2%2Cf3%2Cf4%2Cf5%2Cf6&fields2=f51%2Cf52%2Cf53%2Cf54%2Cf55%2Cf56%2Cf57%2Cf58%2Cf59%2Cf60%2Cf61&ut=b2884a393a59ad64002292a3e90d46a5&klt=101&fqt=1&secid=0.300803&beg=20201202&end=20500000&_=1669967900117
可以发现里面有许多查询参数,我们需要一个一个进行分析。
cb
该参数值为:
jQuery1123008330414708828249_1669967900108
通过查看其他股票代码的网页可以发现,前缀jQuery是不变的,后面的一串数字有变化。点击上一张图负载旁边的发起程序,可以发现发送操作和异步加载操作的来源是
jquery.min.js
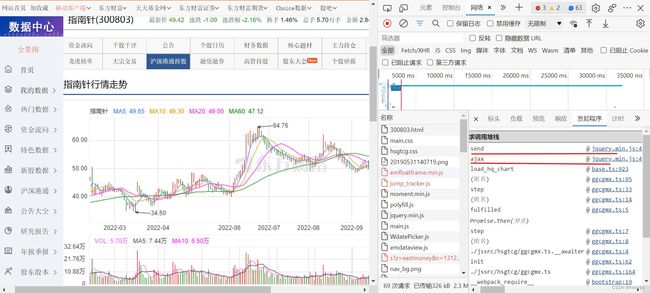
因此,打开该js文件,ctr+F搜索jQuery可以发现cb参数的来源,如下图所示。结果表明该参数值是通过JS代码赋值的。往前搜索m可以发现m为一个固定的字符串值1.12.3,这应该是版本号;后面再添加一个0到1随机数组合为一个字符串;最后的replace操作则是对该字符串所有非数字字符替换为空。因此下划线前面的数字已经被解读出来了。
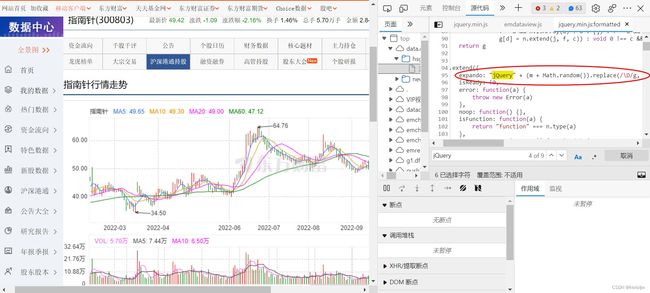
通过上图可以发现,该参数首先被赋值给变量expando,通过搜索我们很快的可以找到下划线后面的数字来源,如下图所示:
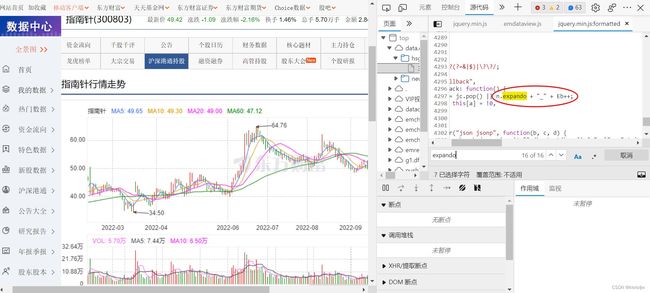
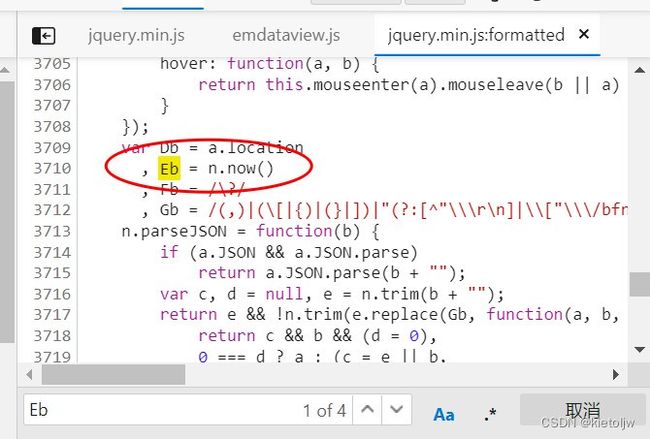
因此,这个变量Eb是关键。同理我们搜索变量Eb,可以发现该变量是一个时间戳,考虑其位数,可以联想到对当前书简戳乘以1000再取整,经过检验是正确的。
因而我们解读出了该参数的构成,python代码实现如下:
jq = re.sub('\D','','1.12.3'+str(random.random()))
tm = int(time.time()*1000)
'jQuery{}_{}'.format(jq,tm)
fields1,fields2,ut,klt1,fqt
经过对多个不同股票数据查询的参数对比,容易发现,这些参数都是一个固定值,只需要赋值即可
secid
显而易见,该参数值小数点后是股票代码。经过对上交所,深交所,北交所的股票数据查询发现,若为上交所股票,小数点前为1,否则为0,所以python代码构建该参数如下:
c = 1 if code[0]=='6' else 0
{}.{}'.format(c,code)
beg,end,_
很显然,这两个参数就是股票数据查询的起始日期和终止日期;可以发现,下划线参数与前面的cb参数的时间戳是一致的。
完整代码
最后,完整爬取代码如下,该代码只是简单的进行了函数包装,有精力的小伙伴可以将其包装为一个类,本人水平有限,代码仅供参考:
#爬虫程序
import requests
from lxml import etree
#from fake_useragent import UserAgent
import random
import time
import urllib
import json
#ua = UserAgent()
def Spider_stock(code_list,begin,end='20500000'):
url = 'https://push2his.eastmoney.com/api/qt/stock/kline/get?'
header ={'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36 Edg/107.0.1418.62",
'Cookie':'qgqp_b_id=e66305de7e730aa89f1c877cc0849ad1; qRecords=%5B%7B%22name%22%3A%22%u6D77%u9E25%u4F4F%u5DE5%22%2C%22code%22%3A%22SZ002084%22%7D%5D; st_pvi=80622161013438; st_sp=2022-09-29%2022%3A47%3A13; st_inirUrl=https%3A%2F%2Fcn.bing.com%2F; HAList=ty-1-000300-%u6CAA%u6DF1300%2Cty-0-002108-%u6CA7%u5DDE%u660E%u73E0%2Cty-1-600455-%u535A%u901A%u80A1%u4EFD%2Cty-0-002246-%u5317%u5316%u80A1%u4EFD',
'Referer':'https://data.eastmoney.com/',
'Host':'push2his.eastmoney.com'}
stock_df = pd.DataFrame(columns=['股票代码','股票名称',"时间",'开盘价','收盘价','最高价','最低价',"涨跌幅",'涨跌额',
"成交量","成交额","振幅","换手率"])
for code in code_list:
#构建url参数
jq = re.sub('\D','','1.12.3'+str(random.random()))
tm = int(time.time()*1000)
c = 1 if code[0]=='6' else 0
params={'cb':'jQuery{}_{}'.format(jq,tm),
'fields1':urllib.request.unquote('f1%2Cf2%2Cf3%2Cf4%2Cf5%2Cf6',encoding='utf-8'),
'fields2':urllib.request.unquote('f51%2Cf52%2Cf53%2Cf54%2Cf55%2Cf56%2Cf57%2Cf58%2Cf59%2Cf60%2Cf61',encoding='utf-8'),
'ut':'b2884a393a59ad64002292a3e90d46a5',
'klt':'101',
'fqt':'1',
'secid':'{}.{}'.format(c,code),
'beg':begin,
'end':end,
'_':'{}'.format(tm)
}
#发送请求
res = requests.get(url.format(code),headers=header,params=params)
res.encoding="utf-8"
#去除js数据中的无关字符,以便符合json数据格式
html = res.text.lstrip('jQuery{}_{}'.format(jq,tm)+'(')
html = html.rstrip(');')
#转换为json数据
js_html = json.loads(html)
js_data = js_html['data']
js_klines = js_data['klines']
day_num = len(js_klines)
for num in range(day_num):
stock_df.loc[len(stock_df)]=[str(js_data['code']),js_data['name'],js_klines[num].split(",")[0],js_klines[num].split(",")[1],
js_klines[num].split(",")[2],js_klines[num].split(",")[3],js_klines[num].split(",")[4],
js_klines[num].split(",")[8],js_klines[num].split(",")[9],js_klines[num].split(",")[5],
js_klines[num].split(",")[6],js_klines[num].split(",")[7],js_klines[num].split(",")[10]
]
time.sleep(0.1)
return stock_df
if __name__ == '__main__':
stock_df = Spider_stock(code_list,begin='20220915')