复旦发布 FoodLMM,食材辨别/菜谱生成/营养分析样样行!
想要准确分辨出泰餐里的玉米笋?想吃美食但又怕一不小心无法控制卡路里而吃胖?食材在手但不知道该怎么搭配能炒出一道营养又美味的菜?养生吃货的最爱的大模型来咯!
近期,来自复旦的最新研究成果——FoodLMM(有种谐音“复的”的感觉),打遍吃货届无敌手,能够快速准确进行食物和成分识别,能基于图像和文字输入生成食谱,还能够估算食物的营养价值,比如计算卡路里、蛋白质和脂肪含量都不在话下。此外,它不但可以识别食物的种类,还能够标明图像中不同成分的位置,并且能与用户通过自然语言交流,不再只像某些 APP 中的关键词搜索方式来提供营养建议。
论文题目:
FoodLMM: A Versatile Food Assistant using Large Multi-modal Model
论文链接:
https://arxiv.org/abs/2312.14991
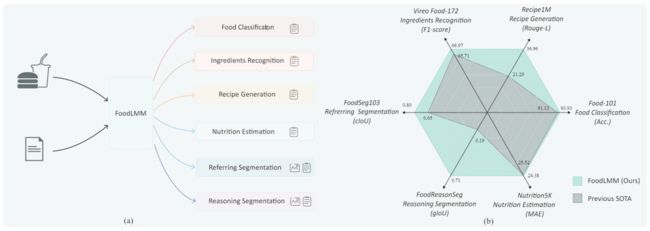
▲图1 FoodLMM 功能及其性能比较
为了应对食物领域中的多样性和复杂性,满足人们对于食物相关问题的多样性提问和对话需求,作者提出了多功能食物助手 FoodLMM,如图 1 所示,其提出背景与原因主要可以概括为:
-
多模态问题: 食物领域包含了丰富的图像(食物图片)和文本(提问和回答)等多模态数据。需要处理这些多模态数据的模型,传统的单模态模型可能无法充分挖掘和整合这些信息。FoodLMM 作为大型多模态模型(MLLM),能够同时处理和理解食物领域的图像和文本信息。
-
复杂的推理需求: 食物相关问题通常需要进行推理,涉及到对食材的识别、食谱生成、营养估算等任务。FoodLMM 通过两个训练阶段,分别注入基本食物知识和提高多轮对话及推理分割能力,以满足这些复杂的推理需求。
-
缺乏专业性对话模型: 食物领域相对缺乏专门用于对话和推理的大模型。传统的模型可能无法胜任食物领域的多样性和复杂性问题,FoodLMM 的提出填补了这一空白,使得模型能够处理关于食物的多轮对话,并提供详细的解释和分割信息。
-
任务多样性: 食物领域涉及到多个任务,如食物分类、成分识别、食谱生成、营养估算和分割等。FoodLMM 通过多任务学习,使得模型在不同的食物任务上都能够表现出色,提供全面的食物问题解决方案。
食物数据训练过程
数据来源
论文基于 LLaVA 方法,通过视觉指令微调 FoodLMM 模型。并对训练数据进行了定义,其中 代表食物图像, 和 分别代表第 轮对话的文本查询和回答,仅用绿色的序列计算自回归损失。

训练阶段
FoodLMM 的训练过程分为两个阶段:第一阶段旨在通过使用各种公开食物数据集向 LMM 注入足够的基本食物知识,第二阶段则通过作者生成的 GPT-4 数据集增强了 FoodLMM 的对话能力。

▲表1 阶段 1 构建视觉指令跟踪数据的公开食物数据集统计
-
阶段 1:公开食物数据集:作者用了食物领域中 5 个最关键任务的指令模板构建了指令跟随数据,包括食物分类、成分识别、食谱生成、营养估算和食物分割。详细介绍了每个任务使用的公开数据集(如 Food VQA、Nutrition Estimation 和 Food Segmentation)。
-
阶段 2:GPT-4 生成的对话数据集:第二阶段的目标是赋予 FoodLMM 在基于食物图像的各种主题上进行多轮对话的能力,并为需要复杂推理的查询提供分割掩码。为填补数据空白,作者构建了 FoodDialogues 和 FoodReasonSeg 两个数据集,分别应用于多轮对话和推理分割任务。
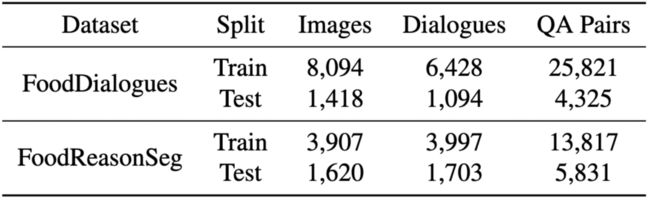
▲表2 阶段 2 的数据集统计
FoodLMM
如图 2 所示,本文提出的 FoodLMM 建立在多模态大模型 LISA 的基础上,基于 LLaVA 方法,将图像和文本提示作为输入。除了两阶段的训练策略使其专注于食物领域之外,还采用了多任务学习、多轮对话和推理分割方法。
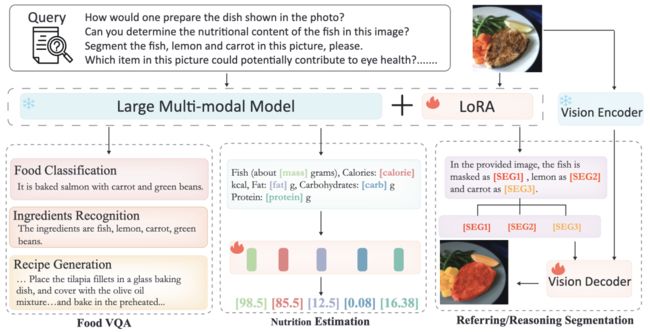
▲图2 FoodLMM 架构概览
第一阶段:多任务学习
该阶段中的多任务学习主要是为了使 FoodLMM 能够处理不同的基础食物任务。这些任务包括食物 VQA(Food VQA),营养估算(Nutrition Estimation)和指令分割(Referring Segmentation)。
食物 VQA
模型需要通过分析图像和问题,理解问题的含义,并生成准确的回答。作者针对食物分类、成分识别和食谱生成,设计了不同的问答模板。与 LLaVA 类似,FoodLMM 通过纯语言自回归进行训练。
营养估算
模型对食品图像进行分析,估算图像中食物的营养价值含量。在 FoodLMM 中,为了更好地完成营养估算的任务,引入了特定十个不同类型的营养 token,这些 token 被设计成代表食物的不同营养元素,添加到模型的词汇表中,作用是为模型提供关于图像中食物营养价值的线索。在模型进行训练和推断时,这些 token 作为输入以指导模型对每个营养元素进行预测。
通过采用多层感知机(MLP)将这些营养 token 的隐状态处理成嵌入,然后将这些嵌入馈送到相应的回归头,以获取对各个营养元素的预测值。最终,预测值被用来替换原始文本输出中的任务特定 token,从而生成模型对食物图像营养价值的答案。
引用分割
该任务的目标是使模型能够理解自然语言中关于图像中成分的引用,并以可解释的方式执行图像分割。这里引入了分割 token,将其隐状态通过 MLP 转换为嵌入,并与 SAM 编码器生成的图像视觉表示结合在一起,由 SAM 解码器生成分割掩码。作者描述了三种不同的情景:
-
One-to-One(一对一): 用户通过自然语言描述查询图像中的一个特定成分,而模型需要生成相应的分割掩码。
-
One-to-Many(一对多): 查询可能涉及引用图像中的多个成分,模型需要生成相应数量的不同分割掩码。
-
One-to-Zero(一对零): 查询引用图像中不存在的对象,这时模型不应生成任何分割掩码,而是引用查询中的成分在图像中不存在。
第二阶段:对多功能对话食物助手进行微调
这是 FoodLMM 的第二阶段,即“精调阶段”,是为了培养 FoodLMM 的多轮对话和推理分割能力,使其成为一个灵活的、多功能的食物对话助手。
多轮对话
通过使用生成的 FoodDialogues 和 FoodReasonSeg 数据集,训练 FoodLMM 具备多轮对话的能力。对话的格式被调整为指令遵循数据的格式,其中在第一轮提问之前仅输入图像,而在随后的每一轮中,将新的问题追加到现有的历史上下文中,引导 LMM 生成后续的回答。其自回归损失函数用于衡量模型生成的回答与实际对话历史的一致性。
推理分割
与多轮对话相一致,推理分割的数据格式也是多轮对话的,每个答案都包含分割 token ,并使用第一阶段的分割损失来增强分割能力。这是为了通过使用特定任务的推理指令,使 FoodLMM 具备进行多轮、高度专业对话的能力,并为需要复杂推理的提问提供详细解释。
实验结果

▲图3 FoodLMM 各种能力的示例
FoodVQA 结果
如表 3 所示,FoodLMM 在食品分类、成分识别和食谱生成等三个任务上的性能均优于先前的 SOTA 方法。
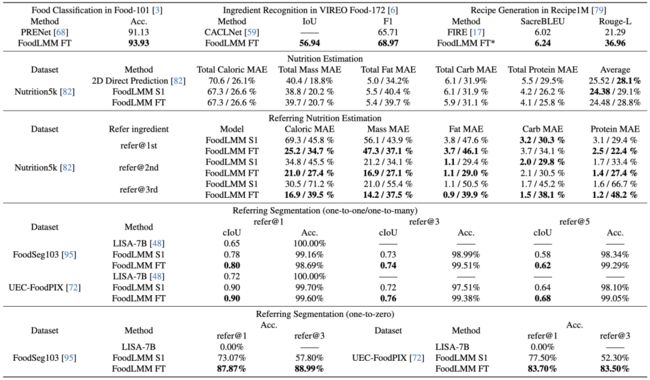
▲表3 不同食物基准上的性能比较
营养估算结果
FoodLMM 在营养估算方面表现出色,降低了平均预测误差(MAE),相较于之前的 SOTA 方法,平均降低了4.5%。此外,FoodLMM 还展示了对特定成分的营养估算的能力(引用营养估算),该能力是先前方法所缺乏的。精细微调阶段虽然未能提高整体营养估算性能,但显著提高了对特定成分的估算准确性。
引用分割结果
-
在一对一引用分割(one-to-one)任务中,FoodLMM 的 cIoU 分数显著超过了 LISA 方法,分别在 FoodSeg103 和 UECFoodPIX 数据集上提高了20%和25%。
-
在一对多引用分割(one-to-many)任务中,模型在 ref er@3 任务上取得了高 cIoU 分数,尽管在引用更多成分时分割变得更具挑战性。然而,经过精细微调后,FoodLMM 在所有场景中均取得更高的 cIoU 分数,并在复杂的分割任务中保持了高准确性。
-
在一对零引用分割(one-to-zero)任务中,作者通过引入具有挑战性的场景来进一步评估 FoodLMM 的推理性能。这个场景要求模型分割图像中不存在的成分,即模型需要拒绝返回分割掩码。
多轮对话结果
FoodLMM 在多轮对话方面通过用户研究获得了良好的满意度评分。如表 4 所示,大多数对话(173/200)获得了高分,其中 4 分是最高频的评分。这表明 FoodLMM 能够与用户偏好密切对齐,生成准确且具有解释性的高质量答案。

▲表4 FoodLMM Chat的人工评估结果
推理分割结果
在推理分割任务中,与 LISA 方法相比,FoodLMM 表现更好,特别是在 FoodReasonSeg 基准上,如表 5 所示,其 gIoU 和 cIoU 得分显著提高,表明 FoodLMM 在食物推理分割方面获得了更多的专业知识和更强的推理能力。
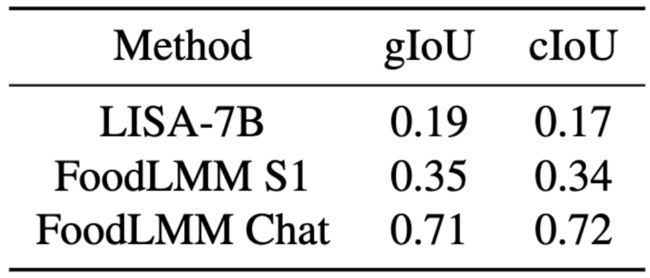
▲表5 推理分割性能比较
总结
来自复旦的研究团队提出了 FoodLMM,这是一个多功能的大型多模态语言模型,专注于解决各种食物相关任务。通过引入食物视觉指令跟踪数据,训练 FoodLMM 在食物领域执行多个任务。通过两个专门针对食物领域的基准,作者评估了 FoodLMM 的推理和对话能力,展示了其在复杂推理任务和多轮关于食物主题的对话中的卓越性能。
最终,作者通过用户研究和两个新颖的食物领域基准测试验证了 FoodLMM 的多轮对话和推理分割能力。用户研究结果表明,FoodLMM 能够根据用户的需求生成准确而详细的回答,证明了其在实际应用中的实用性。食物相关 MLLM 框架的出现,让本资深吃货眼前一亮,相较于简单输入关键词和类似搜索引擎一样的应用,FoodLMM 能够进行更加智能、有深度的对话,可以满足用户在食品领域的多元化需求。
“民以食为天”,FoodLMM 淋漓尽致展现了大模型贴近普通人生活的能力。未来,我们期待这位“美食向导”能够持续引领我们体验更为丰富的美食和健康的饮食习惯,也希望有更多贴近我们生活衣食住行的大模型应用落地生根。