多任务学习综述之模型介绍和训练方法

paper, code
论文详细说明了常用的多任务网络结构和训练方法。
2.1.2 soft and hard parameter sharing in deep learning

在Hard parameter sharing中,参数被分为共享参数和task-specific参数。执行流程如下:一张图片,经过一个主干网络(共享参数),再将主干网络的输出作为不同任务的输入。各个任务的head有各自的参数,即task-specific参数。
在soft parameter sharing中,每个任务都有其各自的参数,在不同任务的特征图之间,会加入一些交互(cross-task talk)。
2.1.4 A New Taxonomy of MTL Approaches
多任务网络一般被分为hard或者soft parameter sharing,在这里,根据task interactions(即不同任务的信息或者特征发生交换或者共享)发生的位置,提出了一种新的分类方式。

若task interactions发展的encoder部分,则叫Encoder-focused model。若发生在decoder部分,则叫Decoder-fcoused model。
2.2 Encoder-focused Architectures

cross-stitch networks,将不同任务前一层的特征,经过线性组合后,作为下一层网络的输入。公式如下:

其中,为前一层的输出,为后一层的输入。
NDDR-Layer,将前一层的输出按通道数叠加,再经过一个1*1的卷积降维,作为后一层的输入。
Multi-Task Attention Networks(MTAN),各个人物共享backbone,然后不同的任务利用attention网络,从对应特征中提取有用信息。
cross-stitch networks和NDDR-Layer都会有一个scalability concern,但是MTAN可以规避这个问题。不过,这三个网络在做信息交互时,都只能使用有限的局部信息。
3 Optimization in MTL
在实际训练中,需要平衡各个任务对网络参数的影响,防止某一个任务占主导地位。
3.1.1 Uncertainty Weighting 【paper】【code】

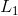 和
和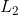 为两个任务的损失,
为两个任务的损失,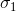 、
、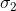 为其对噪声参数,将其作为模型参数,训练学习。
为其对噪声参数,将其作为模型参数,训练学习。
# 定义各个任务的方差log,作为训练参数
log_var_a = torch.zeros((1,), requires_grad=True)
log_var_b = torch.zeros((1,), requires_grad=True)
# get all parameters (model parameters + task dependent log variances)
params = ([p for p in model.parameters()] + [log_var_a] + [log_var_b])
#optimizer = optim.SGD(params, lr=0.001, momentum=0.9)
optimizer = optim.Adam(params)
# define loss criterion
def criterion(y_pred, y_true, log_vars):
loss = 0
for i in range(len(y_pred)):
precision = torch.exp(-log_vars[i])
diff = (y_pred[i]-y_true[i])**2.
loss += torch.sum(precision * diff + log_vars[i], -1)
return torch.mean(loss)3.1.2 Gradient Normalization



根据不同step计算的loss值,计算loss变化率(inverse training rate),在计算相对变化率(relative inverse training rate)。(有些地方不是特别明白,贴上原文,留待有缘人)
与Uncertainty weighting不同之处在于,它不考虑任务的不确定性,而是平衡任务训练的pace。
3.1.3 Dynamic Weight Averaging
根据各个任务的loss值,重新计算各个任务的权重 .
.

n为任务数量,为任务的loss值。T控制softmax操作的softness,t为训练步数
3.1.4 Dynamic Task Prioritization(DTP)
3.1.1——3.1.3都属于uncertainty weighting的范畴,倾向于调节各个任务的权重,以此平衡各个任务的pace。与之不同的是,Dynamic Task Priorization对困难任务分配较高的权重。出发点在于,网络需要花费更大的资源去训练困难任务,而不确定性权重则是对简单任务分配更高的权重。
作者认为,在两个任务没有明确冲突的情况下,当有噪声标注数据时,uncertainty weighting更为合适。当标注数据比较干净时,DTP更为合适。
为评价任务的难易程度,DTP提出了一种KPIs方法,

类似于focal loss,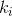 为任务i的KPI值,至于计算KPI值的方法,看DTP原文。
为任务i的KPI值,至于计算KPI值的方法,看DTP原文。
 欢迎关注微信公众号“计算机视觉那些事儿”,了解最新前沿技术。
欢迎关注微信公众号“计算机视觉那些事儿”,了解最新前沿技术。
未完待续......