MR实战:实现数据去重
文章目录
- 一、实战概述
- 二、提出任务
- 三、完成任务
-
- (一)准备数据文件
-
- 1、在虚拟机上创建文本文件
- 2、上传文件到HDFS指定目录
- (二)实现步骤
-
- 1、Map阶段实现
-
- (1)创建Maven项目
- (2)添加相关依赖
- (3)创建日志属性文件
- (4)创建去重映射器类
- 2、Reduce阶段实现
-
- 创建去重归并器类
- 3、Driver程序主类实现
-
- 创建去重驱动器类
- 4、运行去重驱动器类,查看结果
- 四、拓展练习
-
- (一)原始问题
- (二)简单化处理
一、实战概述
-
本次实战任务目标是使用Hadoop MapReduce技术对两个包含重复数据的文本文件
file1.txt和file2.txt进行去重操作,并将结果汇总到一个文件。首先启动Hadoop服务,然后在虚拟机上创建这两个文本文件并上传到HDFS的/dedup/input目录。 -
在Map阶段,我们创建自定义Mapper类
DeduplicateMapper,将TextInputFormat默认组件解析的键值对修改为需要去重的数据作为key,value设为空。在Reduce阶段,我们创建自定义Reducer类DeduplicateReducer,直接复制输入的key作为输出的key,利用MapReduce默认机制对key(即文件中的每行内容)进行自动去重。 -
我们还编写MapReduce程序运行主类
DeduplicateDriver,设置工作任务的相关参数,对HDFS上/dedup/input目录下的源文件进行去重处理,并将结果输出到HDFS的/dedup/output目录。最后,运行DeduplicateDriver类,查看并下载结果文件,确认去重操作成功完成。此实战任务展示如何运用Hadoop MapReduce进行大数据处理和去重操作,提升我们对分布式计算的理解和应用能力。
二、提出任务
-
文件file1.txt本身包含重复数据,并且与file2.txt同样出现重复数据,现要求使用Hadoop大数据相关技术对以上两个文件进行去重操作,并最终将结果汇总到一个文件中。


-
编写MapReduce程序,在Map阶段采用Hadoop默认作业输入方式后,将key设置为需要去重的数据,而输出的value可以任意设置为空。
-
在Reduce阶段,不需要考虑每一个key有多少个value,可以直接将输入的key复制为输出的key,而输出的value可以任意设置为空,这样就会使用MapReduce默认机制对key(也就是文件中的每行内容)自动去重。
三、完成任务
(一)准备数据文件
- 启动hadoop服务

1、在虚拟机上创建文本文件
- 创建两个文本文件 -
file1.txt、file2.txt

2、上传文件到HDFS指定目录
-
创建
/dedup/input目录,执行命令:hdfs dfs -mkdir -p /dedup/input
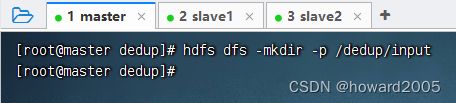
-
将两个文本文件
file1.txt与file2.txt,上传到HDFS的/dedup/input目录

(二)实现步骤
1、Map阶段实现
- 使用IntelliJ开发工具创建Maven项目
Deduplicate,并且新创建net.hw.mr包,在该路径下编写自定义Mapper类DeduplicateMapper,主要用于读取数据集文件将TextInputFormat默认组件解析的类似<0,2022-11-1 a >键值对修改为<2022-11-1 a,null>。
(1)创建Maven项目
- Maven项目 -
Deduplicate
- 单击【Finish】按钮

(2)添加相关依赖
- 在
pom.xml文件里添加hadoop和junit依赖

<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.3.4version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.13.2version>
dependency>
dependencies>
(3)创建日志属性文件
- 在
resources目录里创建log4j.properties文件

log4j.rootLogger=INFO, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/deduplicate.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
(4)创建去重映射器类
- 创建
net.hw.mr包,在包里创建DeduplicateMapper类

package net.hw.mr;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 功能:去重映射器类
* 作者:华卫
* 日期:2022年11月30日
*/
public class DeduplicateMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
private static Text field = new Text();
// <0,2022-11-3 c> --> <2022-11-3 c,null>
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
field = value;
context.write(field, NullWritable.get());
}
}
2、Reduce阶段实现
- 根据Map阶段的输出结果形式,同样在
net.hw.mr包下,自定义Reducer类DeduplicateReducer,主要用于接受Map阶段传递来的数据,根据Shuffle工作原理,键值key相同的数据就会被合并,因此输出数据就不会出现重复数据了。
创建去重归并器类
- 在
net.hw.mr包里创建DeduplicateReducer类

package net.hw.mr;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* 功能:去重归并器类
* 作者:华卫
* 日期:2022年11月30日
*/
public class DeduplicateReducer extends Reducer<Text, NullWritable, Text, NullWritable> {
// <2022-11-3 c,null> <2022-11-4 d,null><2022-11-4 d,null>
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
3、Driver程序主类实现
- 编写MapReduce程序运行主类
DeduplicateDriver,主要用于设置MapReduce工作任务的相关参数,对HDFS上/dedup/input目录下的源文件实现去重,并将结果输入到HDFS的/dedup/output目录下。
创建去重驱动器类
- 在
net.hw.mr包里创建DeduplicateDriver类

package net.hw.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.net.URI;
/**
* 功能:去重驱动器类
* 作者:华卫
* 日期:2022年11月30日
*/
public class DeduplicateDriver {
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 获取作业实例
Job job = Job.getInstance(conf);
// 设置作业启动类
job.setJarByClass(DeduplicateDriver.class);
// 设置Mapper类
job.setMapperClass(DeduplicateMapper.class);
// 设置map任务输出键类型
job.setMapOutputKeyClass(Text.class);
// 设置map任务输出值类型
job.setMapOutputValueClass(NullWritable.class);
// 设置Reducer类
job.setReducerClass(DeduplicateReducer.class);
// 设置reduce任务输出键类型
job.setOutputKeyClass(Text.class);
// 设置reduce任务输出值类型
job.setOutputValueClass(NullWritable.class);
// 定义uri字符串
String uri = "hdfs://master:9000";
// 创建输入目录
Path inputPath = new Path(uri + "/dedup/input");
// 创建输出目录
Path outputPath = new Path(uri + "/dedup/output");
// 获取文件系统
FileSystem fs = FileSystem.get(new URI(uri), conf);
// 删除输出目录
fs.delete(outputPath, true);
// 给作业添加输入目录
FileInputFormat.addInputPath(job, inputPath);
// 给作业设置输出目录
FileOutputFormat.setOutputPath(job, outputPath);
// 等待作业完成
job.waitForCompletion(true);
// 输出统计结果
System.out.println("======统计结果======");
FileStatus[] fileStatuses = fs.listStatus(outputPath);
for (int i = 1; i < fileStatuses.length; i++) {
// 输出结果文件路径
System.out.println(fileStatuses[i].getPath());
// 获取文件输入流
FSDataInputStream in = fs.open(fileStatuses[i].getPath());
// 将结果文件显示在控制台
IOUtils.copyBytes(in, System.out, 4096, false);
}
}
}
4、运行去重驱动器类,查看结果
- 运行
DeduplicateDriver类

- 下载结果文件 -
part-r-00000

- 查看结果文件 -
part-r-00000

四、拓展练习
- 形式:单独完成
- 题目:实现数据去重
- 要求:让学生自己按照步骤实现数据去重的功能,以此来巩固本节的学习内容。写一篇CSDN博客,记录操作过程。
(一)原始问题
- 某人今天访问很多不同的网站,移动或电信日志都会记录在案,有些网站访问次数多,有些网站访问次数少,此人,今天访问了多少个不同的网站?
(二)简单化处理
- 假如有如下一些IP地址,分别保存在三个文件里,如何去掉重复地址?
- ips01.txt
192.168.234.21
192.168.234.22
192.168.234.21
192.168.234.21
192.168.234.23
192.168.234.21
192.168.234.21
192.168.234.21
- ips02.txt
192.168.234.25
192.168.234.21
192.168.234.21
192.168.234.26
192.168.234.21
192.168.234.27
192.168.234.21
192.168.234.27
192.168.234.21
- ips03.txt
192.168.234.29
192.168.234.21
192.168.234.26
192.168.234.21
192.168.234.25
192.168.234.25
192.168.234.21
192.168.234.22
192.168.234.21