大数据毕业设计:天气气象数据采集分析可视化大屏 爬虫+大数据+源码+论文✅
毕业设计:2023-2024年计算机专业毕业设计选题汇总(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕设选题推荐汇总
感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。
1、项目介绍
Python语言、MySQL数据库、Flask框架、Echarts可视化、中国天气网数据、requests爬虫技术、LayUI框架、HTML
关键词:数据可视化;Python;Echart;Flask;爬虫;气象
2、项目界面
(1)数据可视化大屏

(2)后台数据管理页面

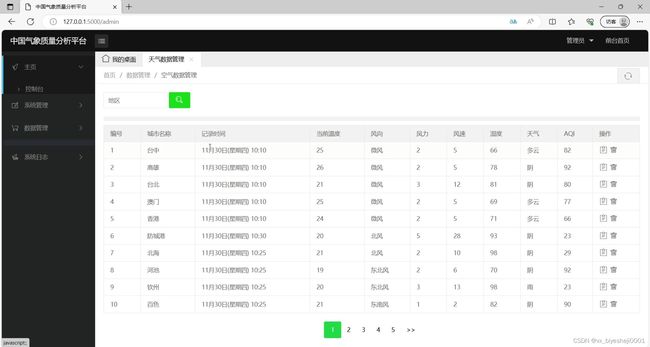
(3)天气数据管理
(4)天气数据修改编辑

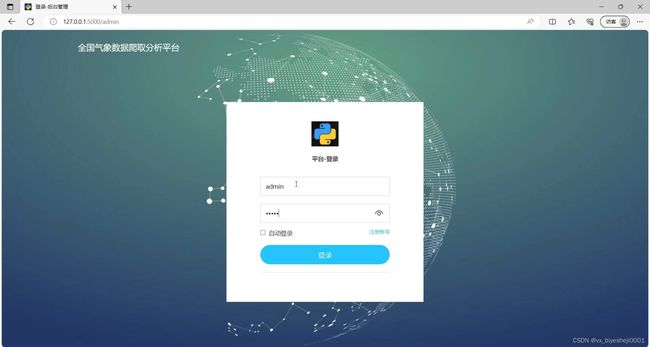
(5)系统注册登录界面
(6)数据采集页面
3、项目说明
随着科技技术的不断发展,人民物质生活质量不断提高,我们越来越关注身边的气象、空气等地理环境。对于普通居民我们会选择合适的气象进行出游,提高精神层面的生活质量;对于企业会关注气象变换状况,来定制相关的生产计划,来提高企业生产效率并降低生成过程中由气象造成的风险损失。从社会角度我们不难看出,气象时时刻刻影响我们的规划和生活,因此我们开发一套中国气象数据可视化系统,更加直观的呈现气象状况,是有必要的。
中国气象质量大数据展示与分析系统,通过使用python爬虫技术对中国气象数据进行实时获取,然后利用相关数据清洗以及数据库处理技术存入数据库,再通过Python Web框架也就是Flask框架进线系统后台数据接口开发,通过Echarts技术进行数据分析可视化展示以及通过LayUI前端技术开发后台数据管理页面从而来完成我们最终的中国气象数据可视化系统。
本文主要通过研究背景,对项目意义进线分析讨论;通过技术分析对项目技术架构选型进行敲定,根据系统需求分析和可行性分析来确定系统的主要功能结构。最后通过系统概要设计、数据库设计将设计的功能进行初步的建模。通过系统设计与实现以及测试阐述系统开发内容以及测试系统功能的正确性。从而最终完成系统的设计与实现。
关键词:数据可视化;Python;Echart;Flask;爬虫;气象
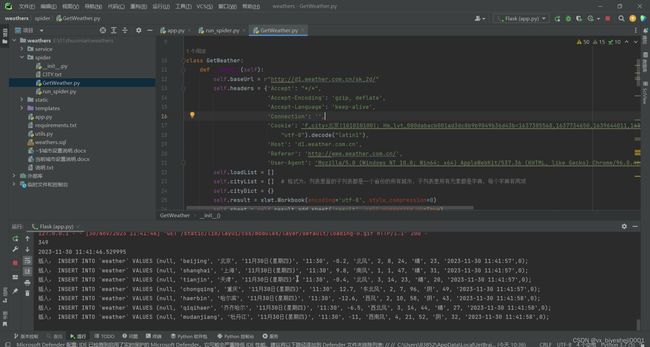
4、核心代码
from flask import Flask as _Flask, flash
from flask import request, session
from flask import render_template
from flask.json import JSONEncoder as _JSONEncoder, jsonify
import decimal
from flask_apscheduler import APScheduler
import service.users_data as user_service
import service.weathers_data as weathers_data
import service.view_data as view_data
import service.version_data as version_data
import service.slog_data as slog_data
from service import data_service
from spider.GetWeather import online
class JSONEncoder(_JSONEncoder):
def default(self, o):
if isinstance(o, decimal.Decimal):
return float(o)
super(_JSONEncoder, self).default(o)
class Flask(_Flask):
json_encoder = JSONEncoder
import os
app = Flask(__name__)
app.config['SESSION_TYPE'] = 'filesystem'
app.config['SECRET_KEY'] = os.urandom(24)
# -------------前台可视化大数据分析相关服务接口start-----------------
# 系统默认路径前台跳转
@app.route('/')
def main_page():
count_data = data_service.count_data()
detail_data = data_service.detail_data()
weather_data = data_service.weather_category_data()
table_data = data_service.table_data()
wd_data = data_service.wd_category_data()
ws_data = data_service.ws_category_data()
aqi_data = data_service.aqi_category_data()
map_data = data_service.china_map_data()
return render_template("main.html", count_data=count_data, detail_data=detail_data, weather_data=weather_data,
table_data=table_data, wd_data=wd_data, ws_data=ws_data, aqi_data=aqi_data,
map_data=map_data)
# -------------前台可视化大数据分析相关服务接口end-----------------
# -------------后台管理模块相关服务接口start-----------------
# 登录
@app.route('/login', methods=['POST'])
def login():
if request.method == 'POST':
account = request.form.get('account')
password = request.form.get('password')
if not all([account, password]):
flash('参数不完整')
return "300"
res = user_service.get_user(account, password)
if res and res[0][0] > 0:
session['is_login'] = True
session['role'] = res[0][1]
return "200"
else:
return "300"
# 登录页面跳转
@app.route('/admin')
def admin():
if session.get("is_login"):
if session.get('role') == 0:
return render_template('index.html')
else:
return render_template('index1.html')
else:
return render_template('login.html')
@app.route('/logout')
def logout():
try:
session.pop("is_login")
return render_template('login.html')
except Exception:
return render_template('login.html')
# 后台首页面跳转
@app.route('/html/welcome')
def welcome():
return render_template('html/welcome.html')
# 后台注册跳转
@app.route('/html/reg')
def html_reg():
return render_template('reg.html')
# -----------------用户管理模块START-----------------
# 用户管理页面
@app.route('/html/user')
def user_manager():
return render_template('html/user.html')
# 获取用户数据分页
@app.route('/user/list', methods=["POST"])
def user_list():
get_data = request.form.to_dict()
page_size = get_data.get('page_size')
page_no = get_data.get('page_no')
param = get_data.get('param')
data, count, page_list, max_page = user_service.get_user_list(int(page_size), int(page_no), param)
return jsonify({"data": data, "count": count, "page_no": page_no, "page_list": page_list, "max_page": max_page})
# 注册用户数据
@app.route('/user/reg', methods=["POST"])
def user_reg():
get_data = request.form.to_dict()
name = str(get_data.get('username'))
account = str(get_data.get('account'))
password = str(get_data.get('password'))
company = "平台注册"
phone = " "
mail = " "
type = 1
return user_service.add_user(name, account, password, company, phone, mail, type)
# 添加用户数据
@app.route('/user/add', methods=["POST"])
def user_add():
get_data = request.form.to_dict()
name = get_data.get('name')
account = get_data.get('account')
password = get_data.get('password')
company = get_data.get('company')
phone = get_data.get('phone')
mail = get_data.get('mail')
type = get_data.get('type')
return user_service.add_user(name, account, password, company, phone, mail, type)
---
from concurrent.futures import ThreadPoolExecutor
# 爬虫日志页面
@app.route('/html/slog')
def slog_manager():
return render_template('html/slog.html')
# 获取爬虫日志数据分页
@app.route('/slog/list', methods=["POST"])
def slog_list():
get_data = request.form.to_dict()
page_size = get_data.get('page_size')
page_no = get_data.get('page_no')
param = get_data.get('param')
data, count, page_list, max_page = slog_data.get_slog_list(int(page_size), int(page_no), param)
return jsonify({"data": data, "count": count, "page_no": page_no, "page_list": page_list, "max_page": max_page})
# 修改爬虫日志数据
@app.route('/slog/edit', methods=["PUT"])
def slog_edit():
get_data = request.form.to_dict()
id = get_data.get('id')
log = get_data.get('log')
slog_data.edit_slog(id, log)
return '200'
# 删除爬虫日志数据
@app.route('/slog/delete', methods=["DELETE"])
def slog_delete():
get_data = request.form.to_dict()
id = get_data.get('id')
slog_data.del_slog(id)
return '200'
# 后台调用爬虫
@app.route('/spider/start', methods=["POST"])
def run_spider():
executor = ThreadPoolExecutor(2)
executor.submit(online())
return '200'
# 爬虫自动运行
def job_function():
print("爬虫任务执行开始!")
executor = ThreadPoolExecutor(2)
executor.submit(online())
# return # 新增的
def task():
scheduler = APScheduler()
scheduler.init_app(app)
# 定时任务,每隔10s执行1次
scheduler.add_job(func=job_function, trigger='interval', seconds=1800, id='my_cloud_spider_id')
scheduler.start()
# return # 新增的
# 写在main里面,IIS不会运行
task()
# ----------------------爬虫/爬虫日志模块-结束----------------------
if __name__ == '__main__':
# 端口号设置
app.run(host="127.0.0.1", port=5000)
源码获取:
由于篇幅限制,获取完整文章或源码、代做项目的,查看我的【用户名】、【专栏名称】、【顶部选题链接】就可以找到我啦
感兴趣的可以先收藏起来,点赞、关注不迷路,下方查看获取联系方式