【Transformer】深入理解Transformer模型2——深入认识理解(下)
前言
Transformer模型出自论文:《Attention is All You Need》 2017年
近年来,在自然语言处理领域和图像处理领域,Transformer模型都受到了极为广泛的关注,很多模型中都用到了Transformer或者是Transformer模型的变体,而且对于很多任务,使用加了Transformer的模型可以获得更好的效果,这也证明了Transformer模型的有效性。
由于Transformer模型内容较多,想要深入理解该模型并不容易,所以我分了大概3~4篇博客来介绍Transformer模型,第一篇(也就是本篇博客)主要介绍Transformer模型的整体架构,对模型有一个初步的认识和了解;第二篇是看了b站李宏毅老师的Transformer模型讲解之后,做的知识总结(内容比较多,可能会分成两篇博客);第三篇从代码的角度来理解Transformer模型。
目前我只完成了前两篇论文,地址如下,之后完成第三篇会进行更新。
第一篇:【Transformer】深入理解Transformer模型1——初步认识了解-CSDN博客
第二篇:【Transformer】深入理解Transformer模型2——深入认识理解(上)-CSDN博客
第三篇:【Transformer】深入理解Transformer模型2——深入认识理解(下)-CSDN博客
第四篇:
深入认识理解(下)
Transformer 就是Sequence-to-Sequence(Seq2Seq):输入一个sequence,输出也是一个sequence(输出sequence的长度由机器自己决定)

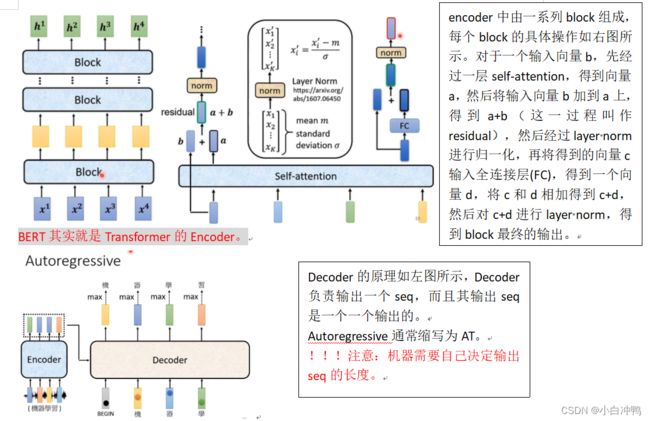

AT和NAT的比较:(AT和NAT都是Decoder的一种,其中NAT表示Non-Autoregressive)
Decoder和Encoder是怎么互动的?


seq2seq训练的一些tips:
1、copy机制:
即:有些东西不需要模型生成,模型可以直接复制。例如聊天机器人、摘要生成等任务。
2、Beam Search
对于答案唯一的任务(如语音识别任务),Beam Search就比较有效果,而对于答案不唯一,需要机器有一点创造力的任务,Beam Search的效果就不是很好。
3、Scheduled Sampling
原本训练时Decoder看到的输入都是正确的,现在要加入一些错误的案例,即在训练时使Decoder看到的输入中有一部分是错误的。但这种方法会导致模型性能有所下降。
评价指标:
1、PPL(Perplexity)
PPL是nlp领域衡量语言模型好坏的指标,它主要是根据每个词来估计一句话出现的概率,并用句子长度作normalize。公式:

其中,S表示sentence,N表示句子长度,P(wi)是第i个词的概率。第一个词就是p(w1|w0),而w0是BEGIN,表示句子的起始,是个占位符。这个式子可以这样理解:PPL越小,p(wi)越大,我们期望的sentence出现的概率就越高。(PPL越小,模型越好)
PPL的影响因素:
(1)训练数据集越大,PPL会下降得更低,1百万数据集和10万数据集训练效果是很不一样的。
(2)数据中的标点会对模型的PPL产生很大影响,一个句号能让PPL波动几十,标点的预测总是不稳定的。
(3)预测语句中的“的、了”等词也对PPL有很大影响,可能“我借你的书”比“我借你书”的指标小几十,但从语义上分析有没有这些停用词并不能完全代表句子生成的好坏。
2、BLEU和ROUGE
BLEU和ROUGE是机器翻译任务中两个常用的评价指标,BLEU根据精确率(Precision)衡量翻译的质量,而ROUGE则根据召回率(Recall)衡量翻译的质量。
BLEU(Bilingual Evaluation Understudy):BLEU是一种用于评估机器翻译结果质量的指标。它主要侧重于衡量机器翻译输出与参考翻译之间的相似程度,着重于句子的准确性和精确匹配。BLEU通过计算N-gram(连续N个词)的匹配程度来估计机器翻译的精确度(Precision)。
ROUGE(Recall-Oriented Understudy for Gisting Evaluation):ROUGE是一种用于评估文本摘要(或其它NLP任务)质量的指标。与BLEU不同,ROUGE主要关注机器生成的摘要中是否捕捉到了参考摘要的信息,着重于涵盖参考摘要的内容和信息的完整性。ROUGE通过计算N-gram的共现情况来评估机器生成的摘要的召回率(Recall)。
简言之,BLEU侧重于衡量翻译的准确性和精确匹配程度,更偏向于Precision,而ROUGE侧重于衡量摘要的信息完整性和涵盖成都,更偏向于Recall。这两个指标在不同的任务和应用场景中都有其重要性,因此在评估nlp模型时,经常会同时使用它们来综合考虑模型的表现。
几个问题详解
1、自注意力机制中为什么要除以![]()

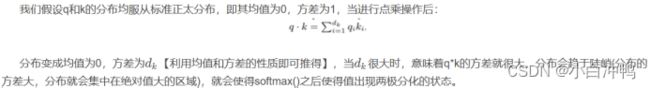

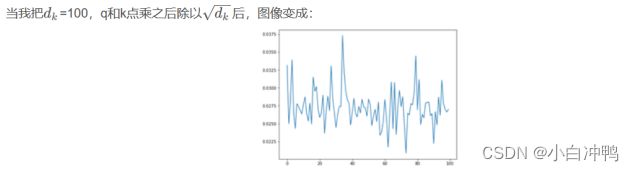
如果有没太看明白的,想深入了解的可以参考这篇博客:
https://blog.csdn.net/qq_44846512/article/details/114364559
2、为什么要使用层归一化?
神经网络中,每一层的计算结果会导致上层的输入分布发生变化。因此,在层数较多的模型中,高层的输入往往会变化巨大,导致上层参数需要根据底层输入数据的分布不断进行调整,而且更高层的参数会对底层输入非常敏感。
为了解决以上问题,采用了层归一化(layer normalization),对每一层的输入进行归一化操作,即计算该层输入的平均值和标准差,将输入的每个维度标准化。
3、残差网络(residual network)
将一个网络层的输出与输入相加的方法来自残差网络,目的是降低计算导数时链式法则路径的平均长度。
以上就是剩下的看视频学习的知识总结,还有我看视频时想到的问题的相关解答,希望能够帮助到大家~