通俗易懂介绍机器学习与深度学习的差别
机器学习和深度学习变得越来越火。突然之间,不管是了解的还是不了解的,所有人都在谈论机器学习和深度学习。无论你是否主动关注过数据科学,你应该已经听说过这两个名词了。
为了展示他们的火热程度,我在 Google trend 上搜索了这些关键字:
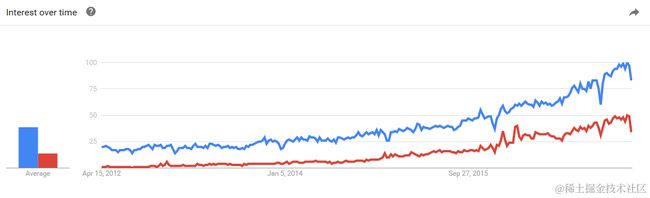
如果你想让自己弄清楚机器学习和深度学习的区别,请阅读本篇文章,我将用通俗易懂的语言为你介绍他们之间的差别。下文详细解释了机器学习和深度学习中的术语。并且,我比较了他们两者的不同,别说明了他们各自的使用场景。
什么是机器学习和深度学习?
让我们从基础知识开始:什么是机器学习?和什么是深度学习?如果你对此已有所了解,随时可以跳过本部分。
什么是机器学习?
一言以蔽之,由 Tom Mitchell 给出的被广泛引用的机器学习的定义给出了最佳解释。下面是其中的内容:
“计算机程序可以在给定某种类别的任务 T 和性能度量 P 下学习经验 E ,如果其在任务 T 中的性能恰好可以用 P 度量,则随着经验 E 而提高。”
是不是读起来很绕口呢?让我们用简单的例子来分解下这个描述。
示例 1:机器学习和根据人的身高估算体重
假设你想创建一个能够根据人的身高估算体重的系统(也许你出自某些理由对这件事情感兴趣)。那么你可以使用机器学习去找出任何可能的错误和数据捕获中的错误,首先你需要收集一些数据,让我们来看看你的数据是什么样子的:

图中的每一个点对应一个数据,我们可以画出一条简单的斜线来预测基于身高的体重
例如这条斜线:
Weight (in kg) = Height (in cm) - 100
…这些斜线能帮助我们作出预测,尽管这些斜线表现得很棒,但是我们需要理解它是怎么表现的,我们希望去减少预测和实际之间的误差,这也是衡量其性能的方法。
深远一点地说,我们收集更多的数据 (experience),模型就会变得更好。我们也可以通过添加更多变量(例如性别)和添加不同的预测斜线来完善我们的模型。
示例2:飓风预测系统
我们找一个复杂一点的例子。假如你要构建一个飓风预测系统。假设你手里有所有以前发生过的飓风的数据和这次飓风产生前三个月的天气信息。
如果要手动构建一个飓风预测系统,我们应该怎么做?
首先我们的任务是清洗所有的数据找到数据里面的模式进而查找产生飓风的条件。
我们既可以将模型条件数据(例如气温高于40度,湿度在80-100等)输入到我们的系统里面生成输出;也可以让我们的系统自己通过这些条件数据产生合适的输出。
我们可以把所有以前的数据输入到系统里面来预测未来是否会有飓风。基于我们系统条件的取值,评估系统的性能(系统正确预测飓风的次数)。我们可以将系统预测结果作为反馈继续多次迭代以上步骤。
让我们根据前边的解释来定义我们的预测系统:我们的任务是确定可能产生飓风的气象条件。性能P是在系统所有给定的条件下有多少次正确预测飓风。经验E是我们的系统的迭代次数。
什么是深度学习?
深度学习的概念并不新颖。它已经存在好几年了。但伴随着现有的所有的炒作,深度的学习越来越受到重视。正如我们在机器学习中所做的那样,先来看看深度学习的官方定义,然后用一个例子来解释。
“深度学习是一种特殊的机器学习,通过学习将世界使用嵌套的概念层次来表示并实现巨大的功能和灵活性,其中每个概念都定义为与简单概念相关联,而更为抽象的表示则以较不抽象的方式来计算。”
这也有点让人混乱。下面使用一个简单示例来分解下此概念。
示例1: 形状检测
先从一个简单的例子开始,从概念层面上解释究竟发生了什么的事情。我们来试试看如何从其他形状中识别的正方形。

我们眼中的第一件事是检查图中是否有四条的线(简单的概念)。如果我们找到这样的四条线,我们进一步检查它们是相连的、闭合的和相互垂直的,并且它们是否是相等的(嵌套的概念层次结构)。
所以,我们完成了一个复杂的任务(识别一个正方形),并以简单、不太抽象的任务来完成它。深度学习本质上在大规模执行类似逻辑。
示例2: 猫 vs. 狗
我们举一个动物辨识的例子,其中我们的系统必须识别给定的图像中的动物是猫还是狗。阅读下此文,以了解深度学习在解决此类问题上如何比机器学习领先一步。
机器学习和深度学习的对比
现在的你应该已经对机器学习和深度学习有所了解,接下来我们将会学习其中一些重点,并比较两种技术。
数据依赖性
深度学习与传统的机器学习最主要的区别在于随着数据规模的增加其性能也不断增长。当数据很少时,深度学习算法的性能并不好。这是因为深度学习算法需要大量的数据来完美地理解它。另一方面,在这种情况下,传统的机器学习算法使用制定的规则,性能会比较好。下图总结了这一事实。

硬件依赖
深度学习算法需要进行大量的矩阵运算,GPU 主要用来高效优化矩阵运算,所以 GPU 是深度学习正常工作的必须硬件。与传统机器学习算法相比,深度学习更依赖安装 GPU 的高端机器。
特征处理
特征处理是将领域知识放入特征提取器里面来减少数据的复杂度并生成使学习算法工作的更好的模式的过程。特征处理过程很耗时而且需要专业知识。
在机器学习中,大多数应用的特征都需要专家确定然后编码为一种数据类型。
特征可以使像素值、形状、纹理、位置和方向。大多数机器学习算法的性能依赖于所提取的特征的准确度。
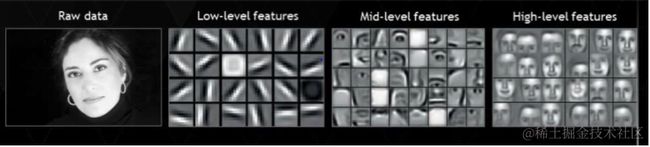
深度学习尝试从数据中直接获取高等级的特征,这是深度学习与传统机器学习算法的主要的不同。基于此,深度学习削减了对每一个问题设计特征提取器的工作。例如,卷积神经网络尝试在前边的层学习低等级的特征(边界,线条),然后学习部分人脸,然后是高级的人脸的描述。更多信息可以阅读神经网络机器在深度学习里面的有趣应用。
问题解决方式
当应用传统机器学习算法解决问题的时候,传统机器学习通常会将问题分解为多个子问题并逐个子问题解决最后结合所有子问题的结果获得最终结果。相反,深度学习提倡直接的端到端的解决问题。
举例说明:
假设有一个多物体检测的任务需要图像中的物体的类型和各物体在图像中的位置。

传统机器学会将问题分解为两步:物体检测和物体识别。首先,使用一个边界框检测算法扫描整张图片找到可能的是物体的区域;然后使用物体识别算法(例如 SVM 结合 HOG )对上一步检测出来的物体进行识别。
相反,深度学习会直接将输入数据进行运算得到输出结果。例如可以直接将图片传给 YOLO 网络(一种深度学习算法),YOLO 网络会给出图片中的物体和名称。
执行时间
通常情况下,训练一个深度学习算法需要很长的时间。这是因为深度学习算法中参数很多,因此训练算法需要消耗更长的时间。最先进的深度学习算法 ResNet完整地训练一次需要消耗两周的时间,而机器学习的训练会消耗的时间相对较少,只需要几秒钟到几小时的时间。
但两者测试的时间上是完全相反。深度学习算法在测试时只需要很少的时间去运行。如果跟 k-nearest neighbors(一种机器学习算法)相比较,测试时间会随着数据量的提升而增加。不过这不适用于所有的机器学习算法,因为有些机器学习算法的测试时间也很短。
可解释性
至关重要的一点,我们把可解释性作为比较机器学习和深度学习的一个因素。
我们看个例子。假设我们适用深度学习去自动为文章评分。深度学习可以达到接近人的标准,这是相当惊人的性能表现。但是这仍然有个问题。深度学习算法不会告诉你为什么它会给出这个分数。当然,在数学的角度上,你可以找出来哪一个深度神经网络节点被激活了。但是我们不知道神经元应该是什么模型,我们也不知道这些神经单元层要共同做什么。所以无法解释结果是如何产生的。
另一方面,为了解释为什么算法这样选择,像决策树(decision trees)这样机器学习算法给出了明确的规则,所以解释决策背后的推理是很容易的。因此,决策树和线性/逻辑回归这样的算法主要用于工业上的可解释性。
机器学习和深度学习用于哪些领域?
维基百科上关于机器学习的文章概述了所有使用机器学习的领域。这些包括:
- 1.计算机视觉 用于车牌识别和面部识别等的应用。
- 2.信息检索 用于诸如搜索引擎的应用 - 包括文本搜索和图像搜索。
- 3.市场营销 针对自动电子邮件营销和目标群体识别等的应用。
- 4.医疗诊断 诸如癌症识别和异常检测等的应用。
- 5.自然语言处理,如情绪分析和照片标记等的应用。
未来发展趋势
本文概述了机器学习和深度学习及其差异。在本节中,我将分享我对机器学习和深度学习未来发展的观点。
首先,随着业内对数据科学和机器学习使用的日益增长的趋势,对于每个想要生存下来的公司来说,重视机器学习将变得非常重要。苹果正在 iPhone X 中使用机器学习,这标志着这项技术的发展方向。
深入学习让我们每天都感到惊讶,并将在不久的将来继续如此。这是因为深度学习是被证明为最先进的性能最好的技术之一。
针对机器学习和深度学习的研究将是持续的。但与前几年的研究仅限于学术界不同的是,机器学习和深度学习方面的研究将在业界和学术界都有爆发式的发展。而且拥有比以往更多的资助,更有可能成为人类整体发展的主旋律。