图的遍历(深度优先遍历 + 广度优先遍历)
目录
广度优先遍历
(1)邻接矩阵BFS
(2)邻接表BFS
(3)非连通图BFS
(4)复杂度分析
深度优先遍历
(1)邻接矩阵的DFS
(2)邻接表的DFS
(3)非连通图的DFS
(4)复杂度
刷题
油田
理想路径
骑士的旅程
抓住那头牛
广度优先遍历
《啊哈算法第四章之bfs》(17张图解)-CSDN博客
Breadth First Search,BFS
一层一层地访问
秘籍:先被访问的节点,其邻接点先被访问
可用队列实现
广度优先遍历经过的节点和边,被称为,广度优先生成树
如果遍历非连通图,每个连通分量,都会产生一棵广度优先生成树

以下代码结合图的存储的结构体进行理解
图的存储(邻接矩阵,边集数组,邻接表,链式前向星)-CSDN博客
(1)邻接矩阵BFS
void BFS_AM(AMGraph G, int v) // 基于邻接矩阵的广度优先遍历
{
int u, w;
queueQ; // 创建队列(先进先出), 存放 int
cout << G.Vex[v] << "\t";
visited[v] = true;
Q.push(v); // 源点 v 入队
while(!Q.empty()) {
u = Q.front(); // 取队头元素
Q.pop(); // 队头出队
for (w = 0; w < G.vexnum; w++) { // 遍历 u 所有邻接点
if (G.Edge[u][w] && !visited[w]) { // u,w 邻接 且 w 未被访问
cout << G.Vex[w] << "\t";
visited[w] = true; // 标记
Q.push(w); // 入队
}
}
}
} (2)邻接表BFS
void BFS_AL(ALGraph G, int v) // 基于邻接表的广度优先遍历
{
int u, w;
AdjNode *p; // 邻接表结构体的指针
queueQ; // 创建队列
cout << G.Vex[v].data << "\t";
visited[v] = true; // 该邻接点下标 v 已访问
Q.push(v); // 源点 v 入队
while (!Q.empty()) {
u = Q.front(); // 取队头元素
Q.pop(); // 队头出队
p = G.Vex[u].first; // u 的第 1 个邻接点
while (p) { // 依次遍历 u 所有邻接点
w = p->v; // u 邻接点下标
if (!visited[w]) { // w 未被访问
cout << G.Vex[w].data << "\t";
visited[w] = true;
Q.push(w);
}
p = p->next; // u 下一个邻接点
}
}
} (3)非连通图BFS
void BFS_AL(ALGraph G)
{
for (int i = 0; i < G.vexnum; i++) { // 检查未被访问的点
if (!visited[i]) // 以 i 为起点, 再次广度优先遍历
BFS_AL(G, i); // 基于邻接表, 也可换邻接矩阵
}
}(4)复杂度分析
基于邻接矩阵 OR 邻接表的,空间复杂度,都是 O(n)
都使用一个辅助队列,每个节点只入队 1 次,共 n 个节点,所以是 O(n)
时间
(1)邻接矩阵
每个节点邻接表 -> O(n)
共 n 个节点,O(n^2)
(2)邻接表
d(vi) 为 vi 的出度
每个节点邻接点 -> O( d(vi) )
有向图,出度的和 = 边数 e,所以查找邻接点为 O(e)
无向图,所有所有节点的度的和为 2e,即每条边被记录 2 次,O(2e),即O(e)
加上初始化的 O(n),总的时间复杂度为 O(n + e)
深度优先遍历
《啊哈算法》之DFS深度优先搜索-CSDN博客
Depth First Search,DFS
秘籍:后被访问的节点,其邻接点先被访问
通过栈实现,因为递归本身就是用栈实现的
当某个节点,没有未被访问过的邻接点时,需要 回退 到上一个节点
(1)邻接矩阵的DFS
void DFS_AM(AMGraph G, int v) // 节点下标 v
{
cout << G.Vex[v] << "\t";
visited[v] = true;
for (int w = 0; w < G.vexnum; w++) // 依次遍历 v 所有邻接点
if (G.Edge[v][w] && !visited[w]) // v, w邻接, 且 w 未被访问
DFS_AM(G, w); // w 节点出发, 递归深度优先遍历
}(2)邻接表的DFS
void DFS_AL(ALGraph G, int v)
{
AdjNode *p; // AdjNode 邻接点结构体
cout << G.Vex[v].data << "\t";
visited[v] = true;
p = G.Vex[v].first; // v 的第 1 个邻接点
while(p) { // 依次遍历 v 所有邻接点
int w = p->v; // w 为 v 邻接点下标
if (!visited[w]) // w 未被访问
DFS_AL(G, w); // w出发, 递归深度优先遍历
// 由上面DFS, 先被访问节点, 邻接点后被访问
p = p->next; // v 下一邻接点
}
}(3)非连通图的DFS
void DFS_AL(ALGraph G)
{
for (int i = 0; i < G.vexnum; i++) {
if (!visited[i])
DFS_AL(G, i); // i 出发, 继续DFS
}
}(4)复杂度
邻接矩阵,时间 O(n^2),空间 O(n)
邻接表,时间 O(n + e),空间 O(n)
图和邻接矩阵是唯一对应的,那么,基于邻接矩阵的BFS和DFS,也唯一对应
但是邻接表,会因为 边的输入顺序 OR 正序逆序建表,的不同,影响邻接表中邻接点的顺序,所以,基于邻接表的BFS,DFS,的序列不唯一
刷题
油田
Oil Deposits - UVA 572 - Virtual Judge (vjudge.net)
思路
(1)两层 for 遍历所有位置,如果该位置,未标记连通分量 且 是油田 '@',从这个位置开始DFS
(2)每次DFS开始前,需要判断是否出界
(3)水平 / 垂直 / 对角线,算作相邻,那么从一个位置出发,有 8 个方向需要 DFS
解释
(1)连通分量
比如 setid[x][y] = 1,(x, y) 表示一个点,如果这一堆点 setid[][] 都是 1,那么它们属于同一个连通分量,利用 cnt++,cnt 从0开始,最后输出 cnt 即可,表示有 cnt 个油藏
(2)坑
a. 每次 dfs 都要给该点的 setid 标记非 0 值,所以,每个 dfs 开头,要对
“已有连通分量 || 不是油田” 的情况,进行 return
b. 每次 cin >> m >> n 后,记得 memset setid 数组(多组输入常犯错误)
AC 代码
#define REP(i,b,e) for(int i=(b); i<=(e); i++)
#include
#include
using namespace std;
const int N = 110;
string str[N]; // 字符矩阵
int m, n, setid[N][N]; // 行, 列, 连通分量
void dfs(int x, int y, int cnt)
{
// 出界
if (x < 0 || y < 0 || x >= m || y >= n)
return;
// 已有连通分量 OR 不是油田
if (setid[x][y] || str[x][y] != '@')
return;
// 标记
setid[x][y] = cnt;
// 递归遍历 8 个方向
REP(i,-1,1)
REP(j,-1,1) {
if (!i && !j) continue; // 同时为0, 原来的点
dfs(x+i, y+j, cnt);
}
}
int main()
{
while(cin >> m >> n) {
if (!m && !n) break;
// 初始化
memset(setid, 0, sizeof(setid));
int cnt = 0; // 油藏数量
// 读入字符矩阵
REP(i,0,m-1) // m 行
cin >> str[i];
// 对每个点 dfs
REP(i,0,m-1)
REP(j,0,n-1) // n 列
if (!setid[i][j] && str[i][j] == '@') // 未标记且油田
dfs(i, j, ++cnt);
cout << cnt << endl;
}
return 0;
} 理想路径
理想路径 Ideal Path - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
Ideal Path - UVA 1599 - Virtual Judge (vjudge.net)
基于BFS的最短路径算法。它首先进行逆向标高求最短距离,然后求解经过边的颜色序列最小,即字典序最小
具体意思是:比如 3 5 1 9 9 < 3 5 2 1 1
求的是,最小字典序的序列,而不是最小权值和
结合题目就是

采取 BFS,因为 边权为 1
本题采用 链式前向星 存储

bfs1() + bfs2()
队列 q1:邻接边终点
队列 q2:邻接边边权(颜色的值)
队列 q3:最小边权终点
总体脉络
看着很复杂,其实很多重复的代码
(1)你需要知道 链式前向星 的存图方式
(2)访问邻接点的代码(板子)
(3)BFS 的代码(板子)
(4)bfs1() 和 bfs2(),都需要 vis[] 防止重复访问已访问过的点
(5)bfs1() 从终点出发,找到每个点到终点的最小距离
(6)add() 加边(板子)
bfs2() 从起点出发,按照 距离-1 的方向,找到边的最小权值的点,再从这些点,再次扩展
关于为什么,不能从起点找最短距离( bfs1() ),我还不是很理解,因为没有现成的例子
先记板子吧
想要非常流畅地敲出来,一遍AC,你需要熟记
1,链式前向星的板子(add() 加边,struct结构体,访问邻接点)
2,BFS 遍历图的板子
AC 代码
评测系统有点问题,《算法训练营》源码 OR 洛谷题解代码,都是 Unknown Error 或者 Runtime Error,所以,过了样例就当 AC 了吧
#include
#include // memset()
#include
using namespace std;
const int N = 1e5 + 10, M = 2e5 + 10, inf = 0x7fffffff;
int n, m, cnt; // 节点数, 边数, 边的计数
int head[N], dis[N]; // 邻接表头节点, 节点到终点最短距离
bool vis[N];
queue q1, q2, q3; // q1邻接边终点, q2边权, q3最小边权终点
struct Edge
{
int to, c, next; // 边的终点, 边权, 下一条边索引
}e[M]; // 边数组
void add(int u, int v, int c) // 起点u, 终点v, 边权c
{
// 边的下标 1 开始
e[++cnt].to = v; // 终点
e[cnt].c = c; // 权值
// 头插法(倒序插入)
e[cnt].next = head[u]; // 下一条边索引
head[u] = cnt; // 更新头节点的第 1 条边
}
void bfs1() // 逆向求最短距离
{
int u, v; // 边的起点, 终点
memset(vis, 0, sizeof(vis)); // 初始化标记数组
dis[n] = 0;
q1.push(n); // 终点加入队列
vis[n] = 1;
while (!q1.empty()) {
u = q1.front(); // 取队首
q1.pop();
vis[u] = 1;
// 从节点第 1 条边开始, 依次遍历邻接点
for (int i = head[u]; i; i = e[i].next) {
v = e[i].to; // 边终点编号, 即邻接点编号
if (vis[v]) continue; // 防止重复访问
dis[v] = dis[u] + 1; // 更新邻接点到终点最短距离
q1.push(v);
vis[v] = 1;
}
}
}
void bfs2() // 正向求最小字典序
{
int u, v, minc, c; // 边的起点, 终点, 最小边权, 边权
bool first = 1; // 第 1 个边权前不要空格
memset(vis, 0, sizeof(vis));
vis[1] = 1;
// 遍历 起点 邻接点 -- 类似初始化, 为后续循环提供条件
for (int i = head[1]; i; i = e[i].next)
if (dis[e[i].to] == dis[1] - 1) { // 往终点方向距离 -1 的点
q1.push(e[i].to); // 加入邻接点
q2.push(e[i].c); // 加入边权
}
while (!q1.empty()) { // 队列不为空, 未扩展完
minc = inf; // 最小初始化为无穷大
// 寻找当前队列最小边权
while (!q1.empty()) {
v = q1.front(); // 取邻接点下标
q1.pop();
c = q2.front(); // 取边权
q2.pop();
if (c < minc) {
// 先清空 q3
while (!q3.empty()) q3.pop();
minc = c; // 更新最小边权
}
if (c == minc)
q3.push(v); // 所有边权是最小值的邻接点, 都加入 q3
}
// 输出路径边权
if (first) first = 0; // 第 1 个边权前, 不输出 空格
else cout << " ";
cout << minc;
// 对,最小边权的邻接点, 进行扩展
while (!q3.empty()) {
u = q3.front(); q3.pop(); // 取队首
if (vis[u]) continue;
vis[u] = 1;
// 遍历最小边权邻接点的, 每一个邻接点
for (int i = head[u]; i; i = e[i].next) {
v = e[i].to;
if (dis[v] == dis[u] - 1) { // 往终点距离 -1 的点
q1.push(v); // 邻接点入队列
q2.push(e[i].c); // 边权入队
}
}
}
}
}
int main()
{
int u, v, c;
while (cin >> n >> m) { // 多组输入
// dis[] 在 bfs1() 被更新, vis[] 在1, 2都有被更新
memset(head, 0, sizeof(head)); // 更新 头节点数组
cnt = 0; // 更新边的计数
// 添加边
for (int i = 1; i <= m; ++i) {
cin >> u >> v >> c; // 起点, 终点, 边权
add(u, v, c), add(v, u, c); // 无向
}
bfs1(); // 反向求最短距离
cout << dis[1] << endl; // 起点到终点最短距离
bfs2(); // 根据最短距离, 求最小字典序
cout << endl; // 多组输入
}
return 0;
}
骑士的旅程
链接
2488 -- A Knight's Journey (poj.org)
A Knight's Journey - POJ 2488 - Virtual Judge (vjudge.net)
题解
马走日,可以在棋盘,任一地方开始和结束
为了字典序最小,只需要从 A1 开始DFS
贴几个题解博客
POJ 2488 - A Knight's Journey | 眈眈探求 (exp-blog.com)
POJ2488-A Knight's Journey(DFS+回溯)-腾讯云开发者社区-腾讯云 (tencent.com)
解释1
解释下代码中的 return flag = 1;
等价于 flag = 1; return flag;
还有就是 dfs() 中, if() 的判断条件 !flag,因为 if() 里面还有 dfs() 递归,如果不加上 !flag 的判断,会得到所有路径,而不只是按字典序排序的第 1 条路径
2
题目分析(腾讯云):
1. 应该看到这个题就可以想到用DFS,当首先要明白这个题的意思是能否只走一遍(不回头不重复)将整个地图走完,而普通的深度优先搜索是一直走,走不通之后沿路返回到某处继续深搜。所以这个题要用到的回溯思想,如果不重复走一遍就走完了,做一个标记,算法停止;否则在某种DFS下走到某一步时按马跳的规则无路可走而棋盘还有为走到的点,这样我们就需要撤消这一步,进而尝试其他的路线(当然其他的路线也可能导致撤销),而所谓撤销这一步就是在递归深搜返回时重置该点,以便在当前路线走一遍行不通换另一种路线时,该点的状态是未访问过的,而不是像普通的DFS当作已经访问了
2. 如果有多种方式可以不重复走一遍的走完,需要输出按字典序最小的路径,而注意到国际象棋的棋盘是列为字母,行为数字,如果能够不回头走一遍的走完,一定会经过A1点,所以我们应该从A1开始搜索,以确保之后得到的路径字典序是最小的(也就是说如果路径不以A1开始,该路径一定不是字典序最小路径),而且我们应该确保优先选择的方向是字典序最小的方向,这样我们最先得到的路径就是字典序最小的。
3
本题 dfs() 中,最后只需要 vis[][] = 0;
用来取消标记,便于回溯
那么为什么不需要对 path[step][0] 和 path[step][1] 归0呢
因为每次新的 dfs( , , step) 递归时,会对上一步的 path 进行覆盖
4
if (!flag) { // 关键一步, 否则输出的不是第 1 条路径代码第 23 行,dfs() 中,每一步递归前,都需要判断,是否已经满足字典序顺序的第 1 条路径
5
// int dir[8][2] = {1,2,1,-2,-1,2,-1,-2,2,1,2,-1,-2,1,-2,-1};
int dir[8][2]={-2,-1,-2,1,-1,-2,-1,2,1,-2,1,2,2,-1,2,1}; // 方向数组也要按字典序注释掉的方向数组,没按字典序,因为字典序的第 1 条路径,必须保证,行 / 列 尽可能的小
所以行从 -2 到 -1 到 1 到 2,列也是依次小到大
AC 代码
#include
#include
using namespace std;
// 列 行 标记数组 满足条件 输出路径
int m, n, vis[30][30], flag, path[30][2];
// int dir[8][2] = {1,2,1,-2,-1,2,-1,-2,2,1,2,-1,-2,1,-2,-1};
int dir[8][2]={-2,-1,-2,1,-1,-2,-1,2,1,-2,1,2,2,-1,2,1}; // 方向数组也要按字典序
int dfs(int x, int y, int step) // (x, y), 第 step 步
{
if (step == n*m) { // 步数 = 格子总数
// return flag = 1;
flag = 1;
return flag;
}
// 遍历 8 个方向
for (int i = 0; i < 8; ++i) {
int tx = x + dir[i][0];
int ty = y + dir[i][1];
if (tx < 1 || tx > n || ty < 1 || ty > m || vis[tx][ty]) // 注意行列反转
continue; // 越界 或 已访问
if (!flag) { // 关键一步, 否则输出的不是第 1 条路径
// 标记
vis[tx][ty] = 1;
path[step][0] = tx;
path[step][1] = ty;
// 递归
dfs(tx, ty, step + 1);
// 取消标记(回溯)
vis[tx][ty] = 0;
}
}
return flag;
}
int main()
{
int t, cnt = 1;
cin >> t;
while (t--) {
cin >> m >> n;
// 初始化
memset(vis, 0, sizeof(vis));
flag = 0;
// 起点 (1 ,1) 加入 path
path[0][0] = 1;
path[0][1] = 1;
vis[1][1] = 1; // 起点已走过
cout << "Scenario #" << cnt++ << ":" << endl;
if (dfs(1, 1, 1)) // 1,1 是起点, 第 3 个参数, 起点算 1 步
for (int i = 0; i < n*m; ++i)
cout << char(path[i][0] + 'A' - 1) << path[i][1]; // 记得 -1
else cout << "impossible";
cout << endl << endl; // 两次换行, 才有间隔一行的效果
}
return 0;
} 抓住那头牛
3278 -- Catch That Cow (poj.org)
Catch That Cow - POJ 3278 - Virtual Judge (vjudge.net)
一道很好的,加深对 DFS 和 BFS 理解的,简单题(当然,首先要找规律)
(1)n 为 0,只能先往前走 1 步,此时 n = 1,ans++
(2)分类讨论
dfs(t) 表示人位置 n,到位置 t 的最小步数
1) t <= n,只能一步一步后退,需要 n - t 步
2)t 为偶数,取 min( dfs(t/2) + 1, t - n )
3)t 为奇数,取 min( dfs(t - 1) + 1, dfs(t + 1) + 1 )
int dfs() 中 return 即可
AC DFS
#include
#include
using namespace std;
int n, k, ans; // n 人位置, k 牛位置
int dfs(int t) // t 牛位置
{
if (t <= n) return n - t;
if (t % 2) {
// cout << t << endl;
return min(dfs(t-1) + 1, dfs(t+1) + 1);
}
else if (t % 2 == 0) {
// cout << t << endl;
return min(dfs(t/2) + 1, t - n);
}
return -1; // 非法返回
}
int main()
{
cin >> n >> k;
if (n == 0) n = 1, ans++;
ans += dfs(k);
cout << ans;
return 0;
}
(1) k <= n,只能一步一步后退,输出 n - k
(2)从 人的位置 n 开始 BFS,每个节点可以扩展 3 个位置
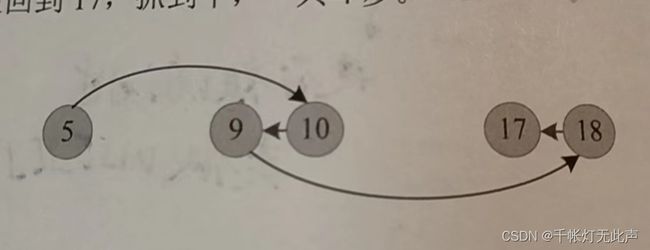
上图,从 人的位置 5 开始,第一次扩展得到 4, 6, 10,第二次扩展,再分别从4,6,10开始

AC BFS
#include
#include
using namespace std;
const int N = 1e5 + 10;
int n, k, d[N], vis[N]; // d[] 答案数组, vis[] 标记数组
void bfs()
{
queue q;
// 当前位置加入队列
d[n] = 0; // 距离(时间)为 0
vis[n] = 1; // 已访问
q.push(n); // 起点入队
while (!q.empty()) { // 直到扩展到目标点, 或者访问完所有点
int u = q.front(); q.pop(); // 取队头
if (u == k) { // 到达目标点
cout << d[u];
return;
}
// 每个节点可以扩展 3 个位置
int x;
// 左一步
x = u - 1;
if (x >= 0 && x <= 1e5 && !vis[x]) { // 不超限 且 未访问
// 加入队列
d[x] = d[u] + 1; // 时间 + 1
vis[x] = 1; // 标记
q.push(x);
}
// 右一步
x = u + 1;
if (x >= 0 && x <= 1e5 && !vis[x]) {
d[x] = d[u] + 1;
vis[x] = 1;
q.push(x);
}
// 坐车 * 2
x = u * 2;
if (x >= 0 && x <= 1e5 && !vis[x]) {
d[x] = d[u] + 1;
vis[x] = 1;
q.push(x);
}
}
}
int main()
{
cin >> n >> k; // n 人位置, k 牛位置
if (k <= n) cout << n - k;
else {
bfs();
}
}