大语言模型(LLM)框架及微调 (Fine Tuning)
大语言模型(LLM) 技术作为人工智能领域的一项重要创 新在今年引起了广泛的关注。
LLM 是利用深度学习和大数据训练的人工智能系统,专门 设计来理解、生成和回应自然语言。这些模型通过分析大量 的文本数据来学习语言的结构和用法,从而能够执行各种语 言相关任务。
LLM 技术也发挥了关键作用。此外,它还在代码 生成、文本摘要、翻译等任务中展现了强大的通用性。
LLM 技术应用类型分别为 大模型、AI编程、工具和平台、基础设施、算力等。
一、LLM技术背景
Transformer 架构和预训练与微调策略是 LLM 技术的核心,随着大规模语言数据集的可用性和计算能力的提升,研究者们开始设计更大规模的神经网络,以提高对语言复杂性的理解。
GPT (Generative Pre-trained Transformer) 的提出标志着 LLM 技术的飞速发展,其预训练和微调的方法为语言任务提供了前所未有的性能,以此为基础,多模态融合的应用使得 LLM 更全面地处理各种信息,支持更广泛的应用领域。

图源:https://postgresml.org/docs/.gitbook/assets/ml_system.svg
二、LLM底座基础设施
2.1、向量数据库及向量支持
向量数据库是专门用于存储和检索向量数据的数据库,它可以为 LLM 提供高效的存储和检索能力。通过数据向量化,实现了在向量数据库中进行高效的相似性计算和查询。 根据向量数据库的的实现方式,可以将向量数据库大致分为两类:
向量数据库:原生的向量数据库专门为存储和检索向量而设计, 所管理的数据是基于对象或数据点的向量表示进行 组织和索引。 包括 Chroma、LanceDB、Margo、Milvus、Pinecone等均属于原生向量数据库。

传统数据库支持向量:除了选择专业的向量数据库,对传统数据库添加“向量支持”也是主流方案。比如Redis、PostgreSQL、ClickHome、Elasticsearch等传统数据库均已支持向量检索。

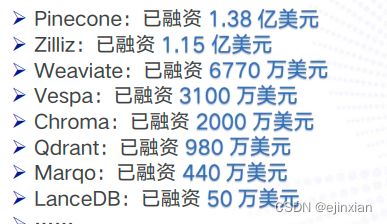
向量数据库市场及融资情况
ChatGPT 问世以来,大模型星火初始,向量数据 库不但获得了技术领域的关注,也逐渐吸引了市场和资本的注 意力。近两年来,向量数据库公司迎来了一波融资潮:
2.2、LLM大模型框架及微调
大模型框架指专门设计用于构建、训练和部署大型机器 学习模型和深度学习模型的软件框架。这些框架提供了 必要的工具和库,使开发者能够更容易地处理大量的数 据、管理巨大的网络参数量,并有效地利用硬件资源。
微调(Fine Tuning)是在大模型框架基础上进行的一个 关键步骤。在模型经过初步的大规模预训练后,微调是 用较小、特定领域的数据集对模型进行后续训练,以使 其更好地适应特定的任务或应用场景。这一步骤使得通 用的大型模型能够在特定任务上表现出更高的精度和更 好的效果。
大模型框架提供了 LLM 的基本能力和普适性,而微调 则是实现特定应用和优化性能的关键环节。两者相结合, 使得 LLM 在广泛的应用场景中都能发挥出色的性能。

2.2、LLM大模型框架特点
抽象和简化:大模型开发框架通过提供高 层次的 API 简化了复杂模型的构建过程。这 些 API 抽象掉了许多底层细节,使开发者能 够专注于模型的设计和训练策略
性能优化:这些框架经过优化,以充分利用 GPU、TPU 等高性能计算硬件,以加速模型 的训练和推理过程。
大型数据集:它们提供工具来有效地加 载、处理和迭代大型数据集,这对于训练大 型模型尤为重要。
生态扩展:为了处理大型数据集和大规模参 数网络,这些框架通常设计得易于水平扩展, 支持在多个处理器或多个服务器上并行处理。

国产深度学习框架 OneFlow 架构 (图源:https://www.oneflow.org/a/chanpin/oneflow/)
2.3、微调模型步骤
1.选择预训练模型:选取一个已经在大量数据上进 行过预训练的模型作为起点;
2.准备任务特定数据:收集与目标任务直接相关的 数据集,这些数据将用于微调模型;
3.微调训练:在任务特定数据上训练预训练的模型, 调整模型参数以适应特定任务;
4.评估:在验证集上评估模型性能,确保模型对新 数据有良好的泛化能力;
5.部署:将性能经验证的模型部署到实际应用中去。
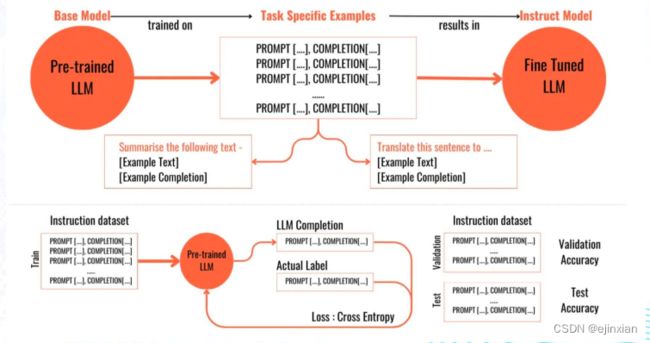
微调的过程也是分类模型训练的过程
(图源:https://medium.com/mlearning-ai/what-is-a-fine-tuned-llm-67bf0b5df081)
原文:《LLM技术报告》