互联网加竞赛 基于Django与深度学习的股票预测系统
文章目录
- 0 前言
- 1 课题背景
- 2 实现效果
- 3 Django框架
- 4 数据整理
- 5 模型准备和训练
- 6 最后
0 前言
优质竞赛项目系列,今天要分享的是
**基于Django与深度学习的股票预测系统 **
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:5分
更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题背景
随着经济的发展,我国的股票市场建设正不断加强,社会直接融资正获得重要发展。股票市场行情的涨落与国民经济的发展密切相关。股票作为一种资本融资和投资的工具,是一种资本的代表形式,股票市场可以让上市公司便捷地在国内和国际市场融资。个人投资者、投资机构期望通过技术手段进行投资分析,能够从股票市场获得一定相对高额的投资收益。
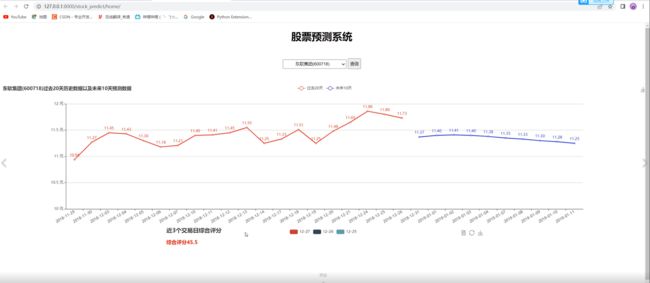
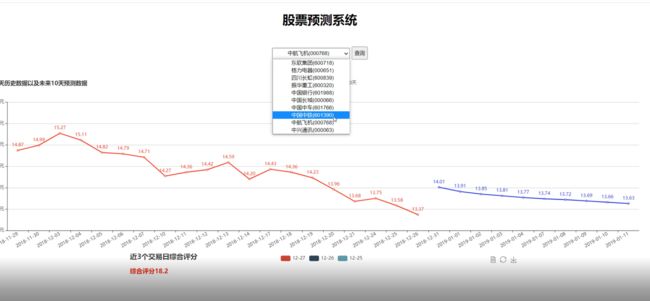
2 实现效果
主界面
详细数据查看

股票切换
相关html
DOCTYPE html>
股票预测系统title>
{% load static %}
3 Django框架
Django是一个基于Web的应用框架,由python编写。Web开发的基础是B/S架构,它通过前后端配合,将后台服务器的数据在浏览器上展现给前台用户的应用。Django本身是基于MVC模型,即Model(模型)+View(视图)+
Controller(控制器)设计模式,View模块和Template模块组成了它的视图部分,这种结构使动态的逻辑是剥离于静态页面处理的。
Django框架的Model层本质上是一套ORM系统,封装了大量的数据库操作API,开发人员不需要知道底层的数据库实现就可以对数据库进行增删改查等操作。Django强大的QuerySet设计能够实现非常复杂的数据库查询操作,且性能接近原生SQL语句。Django支持包括PostgreSQL、My
Sql、SQLite、Oracle在内的多种数据库。Django的路由层设计非常简洁,使得将控制层、模型层和页面模板独立开进行开发成为可能。基于Django的Web系统工程结构示意图如图所示。
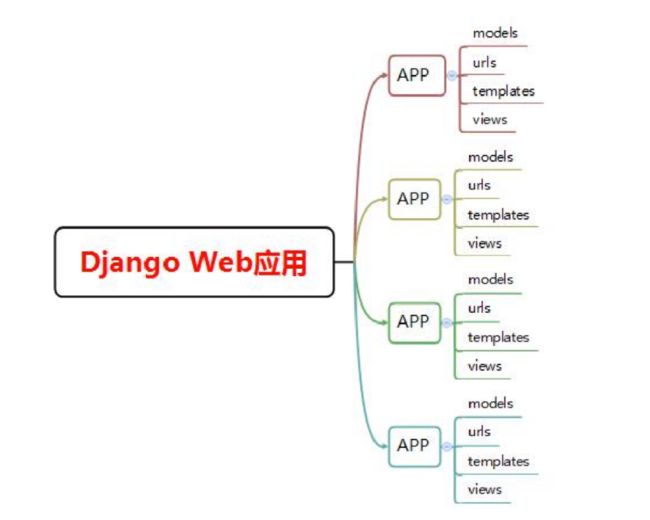
从图中可以看到,一个完整的Django工程由数个分应用程序组成,每个分应用程序包括四个部分:
urls路由层 :决定Web系统路由结构,控制页面间的跳转和数据请求路径

views视图层
:业务层,主要进行逻辑操作和运算,是前端页面模板和后端数据库之间的桥梁。Django框架提供了大量的数据库操作API,开发人员甚至不需要使用SQL语句即可完成大部分的数据库操作。

models模型层
:Web应用连接底层数据库的关键部分,封装了数据库表结构和实现。开发人员可以在Model层按照Django的指令要求进行建表,无须使用SQL语句或者第三方建表工具进行建表。建表的过程类似于定义变量和抽象编程语言中的类,非常方便。
templates模板层
:HTML模板文件,后端数据会填充HTML模板,渲染之后返回给前端请求。考虑到项目周期尽可能小,尽快完成平台的搭建,项目决定采用开源的Django框架开发整个系统的Web应用层。

关键代码
def main():
os.environ.setdefault(‘DJANGO_SETTINGS_MODULE’, ‘ExamOnline.settings’)
try:
from django.core.management import execute_from_command_line
except ImportError as exc:
raise ImportError(
"Couldn’t import Django. Are you sure it’s installed and "
"available on your PYTHONPATH environment variable? Did you "
“forget to activate a virtual environment?”
) from exc
execute_from_command_line(sys.argv)
4 数据整理
对于LSTM来说,至少需要两步整理过程:
- 归一化
- 变成3D样本(样本,时间步,特征数)
对于神经网络来说,归一化至关重要。如果缺失,会无法顺利训练和学习,俗称:Train不起来。对于LSTM来说,更为重要,因为LSTM内部包含tanh函数使得输出范围在-1到1之间。这就需要我们将预测值也进行归一化,常见的做法就是直接归一化到0和1之间。
将一般的特征X和目标y变成3D,我这里提供了一个函数,输入为原始的X_train_raw,X_test_raw,y_train_raw,y_test_raw。n_input
为需要多少步历史数据,n_output为预测多少步未来数据。
def transform_dataset(train_set, test_set, y_train, y_test, n_input, n_output):
all_data = np.vstack((train_set, test_set))
y_set = np.vstack((y_train, y_test))[:,0]
X = np.empty((1, n_input, all_data.shape[1]))
y = np.empty((1, n_output))
for i in range(all_data.shape[0] - n_input - n_output):
X_sample = all_data[i:i + n_input, :]
y_sample = y_set[i + n_input:i + n_input + n_output]
if i == 0:
X[i] = X_sample
y[i] = y_sample
else:
X = np.append(X, np.array([X_sample]), axis=0)
y = np.append(y, np.array([y_sample.T]), axis=0)
train_X = X[:train_set.shape[0] - n_input, :, :]
train_y = y[:train_set.shape[0] - n_input, :]
test_X = X[train_set.shape[0] -
n_input:all_data.shape[0] -
n_input -
n_output, :, :]
test_y = y[train_set.shape[0] -
n_input:all_data.shape[0] -
n_input -
n_output, :]
return train_X, train_y, test_X, test_y
5 模型准备和训练
Keras已经包含LSTM
网络层,调用方式和普通的神经网络没有特别大的区别,仅仅需要指定输入数据的shape。这里我们设计一个简单的神经网络,输入层为LSTM,包含20个节点,输出层为普通的Dense,损失函数采用mean_absolute_error。
n_timesteps, n_features, n_outputs = train_X.shape[1], train_X.shape[2], train_y.shape[1]
# create a model
model = Sequential()
model.add(LSTM(10, input_shape=(n_timesteps, n_features),kernel_initializer=‘glorot_uniform’,
kernel_regularizer=regularizers.l2(0.0),return_sequences=False))
#model.add(LSTM(20, input_shape=(n_timesteps, n_features),kernel_initializer=‘glorot_uniform’,
# kernel_regularizer=regularizers.l2(0.0)))
model.add(Dense(n_outputs,kernel_initializer='glorot_uniform',
kernel_regularizer=regularizers.l2(0.0)))
model.compile(optimizer='adam', loss='mean_absolute_error')
print(model.summary())
调用fit函数对训练集进行学习。由于时间序列具有很明显的趋势,因此有必要将样本打乱。这里需要说明:我们打乱的是“样本”,不影响每个样本内在的序列关系。LSTM只会根据样本内在的序列关系(时间步)来更新自己的隐状态。
from sklearn.utils import shuffle
train_X,train_y = shuffle(train_X,train_y,random_state=42)
plt.plot(train_y)
# fit the RNN model
history = model.fit(
train_X,
train_y,
epochs=300,
batch_size=512,
validation_split=0.3)
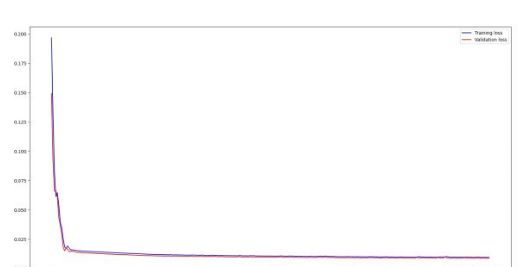
figure = plt.Figure()
plt.plot(history.history[‘loss’],
‘b’,
label=‘Training loss’)
plt.plot(history.history[‘val_loss’],
‘r’,
label=‘Validation loss’)
plt.legend(loc=‘upper right’)
plt.xlabel(‘Epochs’)
plt.show()
查看loss曲线,确保训练已经稳定。
6 最后
更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate