005、数据类型
1. 关于数据类型
Rust中,每个值都有其特定的数据类型,Rust会根据数据的类型来决定如何处理它们。
Rust是一门静态类型语言,它在编译程序的过程中就需要知道所有变量的具体类型。在大部分情况下,编译器可以根据我们如何绑定、使用变量的值来自动推导出变量的类型。
但在某些情况下编译器是推导不了的,举个:
let guess:u32 = "42".parse().expect("这不是一个数字!");当我们需要使用 parse 将一个 String 类型转换为数值类型时,为了避免混淆,就必须像上面的例子中一样显式地指定类型,否则就会报错。
在具体讲某个数据类型之前,我们先看一下下面的思维导图,先对本篇内容有个大概的框架。

2. 标量类型
标量类型是单个值类型的统称,Rust中内建了4种基础的标量类型,分别是:整数、浮点、布尔值和字符。
2.1 整数类型
整数指的是那些没有小数部分的数字。
下表展示了Rust中内建的整数类型,每个长度不同的值都有无符号和有符号两种变体,可以被用来描述不同类型的整数。
| 长度 | 有符号 | 无符号 |
| 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| arch | isize | usize |
每个整数类型的变体都会标明自身是否存在符号,并且拥有一个明确的大小。
有无符号代表一个整数类型是否拥有描述负数的能力。换言之,无符号的整数数值永远为正,不需要符号,而有符号是正数、负数都包含。比如,i32 类型的整数范围是从 -2,147,483,648 到 2,147,483,647。
u 代表无符号,i 代表有符号,我们可以这样形象记忆。这个字母 u 是不是像一个容器,但是里面是空的,没有盖子,所以是无符号。字母 i 上面有一个点,就是有东西在上面,就是有符号。
对于一个位数为 n 的有符号整数类型,它可以存储从 -(2n-1) 到 2n-1-1 范围内的所有整数。比如对于 i8 来讲,它可以存储从 -(27) 到 27-1 ,也就是从 -128 到 127 之间的所有整数。
而对于无符号整数类型而言,则可以存储从 0 到 2n-1 范围内的所有整数。以 u8 为例,它可以存储从 0 到 28-1 ,也就是从 0 到 255 之间的所有整数。
除了指明位数的类型,还有 isize 和 usize 两种特殊的整数类型,它们的长度取决于程序运行的目标平台。在 64位 架构上,它们就是 64位 的,而在 32位 架构上,它们就是 32位 的。
你可以使用下表中列出的所有方式在代码中书写整数字面量。注意,除了 Byte,其余所有的字面量都可以使用类型后缀,比如 57u8,代表一个使用了 u8 类型的整数 57。同时你也可以使用_ 作为分隔符以方便读数,比如 1_000。
| 整数字面量 | 示例 |
| Decimal | 98_222 |
| Hex | 0xff |
| Octal | 0o77 |
| Binary | 0b1111_0000 |
| Byte(u8 only) | b'A' |
可能有些小伙伴不知道什么叫整数字面量,这里我解释一下。
在Rust中,整数字面量是指直接在代码中写出的整数值。它们可以是十进制、十六进制、二进制或八进制。
下面是一些示例:
- 十进制整数字面量:123
- 十六进制整数字面量(以0x或0X开头):0x1a 或 0X1A
- 二进制整数字面量(以0b或0B开头):0b1010 或 0B1010
- 八进制整数字面量(以0o或0O开头):0o26 或 0O26
代码示例:
let x = 123; // 十进制
let y = 0x1a; // 十六进制
let z = 0b1010; // 二进制
let w = 0o26; // 八进制可以看到,整数类型很多,那么如何确定自己需要的是哪一种呢?
Rust对于整数字面量的默认推导类型 i32 通常就是一个很好的选择:它在大部分情形下都是运算速度最快的那一个,即便是在64位系统上也是如此。较为特殊的两个整数类型 usize 和 isize 则主要用作某些集合的索引。
2.2 整数溢出
现在假设有一个 u8 类型的变量,它可以存储 0 到 255 的数字,但我们修改为 256 ,此时就会导致整数溢出。
Rust中对此情形有以下几种规则:
调试(debug)模式下,在程序运行时触发 panic(恐慌)。注:这里的 panic 是 Rust中的一个术语,表示程序因错误导致退出的情形,具体我们会在后面详细讨论。
发布(release)模式下,不会触发 panic,在溢出发生时执行二进制补码环绕。以 u8 为例,256 就会被“环绕”为 0,257 “环绕”为 1,以此类推。
若你本来就想让它产生环绕,那么你可以使用标准库中的类型 Wrapping(包装)。
2.3 浮点数类型
浮点数就是带小数的数字,它有两种子类型分别是:f32 和 f64。
在现代CPU中,两者运行效率相差无几,但 f64 拥有更高精度,因此Rust会默认将浮点数字面量的类型推导为 f64。
下面代码示例中声明了2个浮点数类型的变量(截图中灰色的 f64 是编译器自动推导并标注上去的):
let x = 1.0;
let y:f32 = 3.0;
Rust的浮点数使用了 IEEE-754 标准来进行表述,f32 和 f64 类型分别对应着标准中的单精度浮点数和双精度浮点数。
对于所有的数值类型,Rust都支持常见的数学运算:加法、减法、乘法、除法及取余。
代码示例:
//加法
let sum = 1 + 2;
//减法
let difference = 3.5 - 2.4;
//乘法
let product = 4 * 25;
//除法
let quotient = 6.8 / 3.4;
//取余
let remainder = 47 % 7;2.4 布尔类型
布尔类型只有2个值,分别是:true 和 false,每个占单个字节大小。
你可以使用 bool 关键字来表示一个布尔类型,例如:
let x = true;
let y:bool = false;
上面截图中,变量 x 是编译器自动推导的,变量 y 是显式声明。
布尔类型最主要的用途是在if表达式内作为条件使用,这个后面再详细讨论。
2.5. 字符类型
char 类型被用于描述语言中最基础的单个字符。需要注意的是,char 类型使用单引号指定,而不同于字符串使用双引号指定。

char 类型占4字节,是一个 Unicode 标量值,这也意味着它可以表示比 ASCII 多得多的字符内容。拼音字母、中文、日文、韩文、零长度空白字符,甚至是 emoji 表情都可以作为一个有效的 char 类型值。
实际上,Unicode 标量可以描述从 U+0000 到 U+D7FF 以及 从 U+E000 到 U+10FFFF 范围内的所有值。由于 Unicode 中没有“字符”的概念,所以你现在从直觉上认为的“字符”也许与Rust中的概念并不相符。这个后面再详细讨论。
3. 复合类型
复合类型(Compound Type)可以将多个不同类型的值组合为一个类型,它有两个子类型,分别是:元组(Tuple)和 数组(Array)。
3.1 元组类型
元组类型可以将其他不同类型的多个值组合进一个复合类型中。元组还拥有一个固定的长度,即:你无法在声明结束后增加或减少其中的元素数量。
要创建元组,则需要把一系列的值使用逗号分隔后放置到一对圆括号中。元组每个位置的值都有一个类型,这些类型不需要是相同的。
代码示例:
let tup = (1, 2.2, 'A');编译器自动推导的代码截图:

由于一个元组也被视作一个单独的复合元素,所以这里的变量tup被绑定到了整个元组上。为了从元组中获得单个的值,我们可以像下面这样使用模式匹配来解构元组:
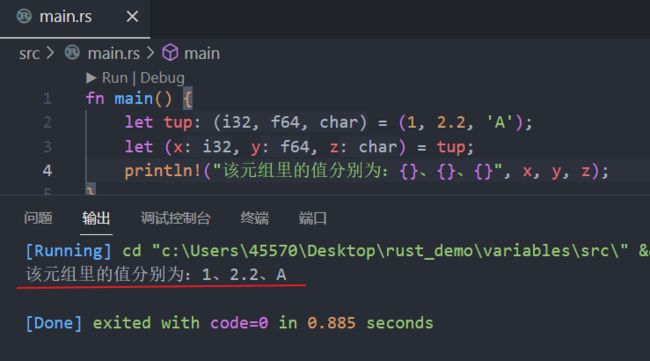
除了解构,我们还可以通过索引并使用点号(.)来访问元组中的值:

3.2 数组类型
我们同样可以在数组中存储多个值的集合。与元组不同,数组中的每一个元素都必须是相同的类型。
Rust中的数组拥有固定的长度,一旦声明就再也不能随意更改大小,这与其他某些语言有所不同。在Rust中,你可以将以逗号分隔的值放置在一对方括号内来创建一个数组:
let arr = [1, 2, 3, 4, 5];通常而言,当你想在栈上而不是堆上为数据分配空间时,或者想要确保总有固定数量的元素时,数组是一个非常有用的工具(栈和堆的区别后面会详细讨论)。
当然,Rust标准库也提供了一个更加灵活的动态数组(vector)类型。动态数组是一个类似于数组的集合结构,但它允许用户自由地调整数组长度。
假如你还不确定什么时候应该使用数组,什么时候应该使用动态数组,那就先使用动态数组好了。后面会深入讨论有关动态数组的更多细节。
在下面这种情形中,你也许会选择使用数组而非动态数组。假设在某个程序中需要知道一周中每个周几,我们就可以使用数组来存储这个名字列表。因为我们知道它有且仅有7个元素,且不太可能添加或删除。
let week = ["周一", "周二", "周三", "周四", "周五", "周六", "周日"];假如你想要初始化一个含有相同元素的数组,那么你可以在方括号中指定元素的值,并接着填入一个分号及数组的长度,如下所示:
let arr = [3;5];
let brr = [3, 3, 3, 3, 3];数组 arr 表示其中有5个元素,每个元素都是3,所以 arr 和 brr 是等价的,但 arr 的写法更加精简。
3.3 访问数组中的元素
数组由一整块分配在栈上的内存组成,你可以通过索引来访问一个数组中的所有元素,就像下面演示的一样:

3.4 非法的数组元素访问
以上面声明的数组为例,arr 数组有5个值,但是我们却访问第6个值,虽然编译通过了,但会因为错误而崩溃退出。

实际上,每次通过索引来访问一个元素时,Rust都会检查这个索引是否小于当前数组的长度。假如索引超出了当前数组的长度,Rust就会发生 panic。
这应该是我们遇到的第一个涉及Rust安全原则的示例。有许多底层语言没有提供类似的检查,一旦尝试使用非法索引,你就会访问到某块无效的内存。
在这种情况下,逻辑上的错误常常会蔓延至程序的其他部分,进而产生无法预料的结果。通过立即中断程序而不是自作主张地去继续运行,Rust帮助我们避开了此类错误。在后面的文章中,我们将接触到更多的错误处理机制。
4. 结语
由于能力有限、本人也还在学习摸索阶段,文中难免有错漏之处,若有读者大大发现,欢迎在评论区留言。
最后,码字不易,即便只有一个赞也可以让我动力满满,感谢你的支持!