requests+xpath之贴吧图片爬取
这篇博客介绍怎么爬取百度贴吧的图片。使用的是爬虫技术最基础的requests请求加xpath定位提取。
写这个爬虫是因为有很多贴吧有很多图片,比如表情包吧啊,我很像得到里面的图片,但是如果一张张保存难免太慢了。所以就产生了这个爬虫。
我是为了爬取任意一个贴吧的图片,所以第一个进入的页面肯定是百度贴吧的主页面。
https://tieba.baidu.com/
然后我随便输入一个贴吧名,我用表情包吧举例(谁叫他图片多呢)。
然后进入到表情包吧后,他的URL为:https://tieba.baidu.com/f?ie=utf-8&kw=%E8%A1%A8%E6%83%85%E5%90%A7&fr=search
我返回主页在随便进入一个贴吧,这次我进入Python爬虫吧。
他的URL为:https://tieba.baidu.com/f?ie=utf-8&kw=Python%E7%88%AC%E8%99%AB&fr=search
我发现这两个URL只是他的kw属性不同,而且网页会吧我输入的中文自动转码,这样我在构建代码时,网址中直接输入中文即可。然后我尝试能不能缩短URL,然后发现能把后面的&fr=search去掉,一样可以请求。所以我就能得到请求贴吧信息的URL:https://tieba.baidu.com/f?ie=utf-8&kw=(你要爬取的吧名,不要带“吧”字)。
然后我分析具体贴吧页面,我需要进入每个贴子里面,且我只需要图片,所以我只需得到每个贴子的链接就行了。
F12进入开发者模式,任意定位到一个贴子,我能找到:
"noreferrer" href="/p/5788129292" title="【表情吧官方群】欢迎大家加入!" target="_blank" class="j_th_tit ">【表情吧官方群】欢迎大家加入!
然后进入这个贴子产看他的URL:https://tieba.baidu.com/p/5788129292
发现他后半块内容在上面的@href属性,所以我提取到href元素,然后前面加上“https://tieba.baidu.com”就能进入到每个贴子了。下面我测试下:
import requests
from lxml import etree #要用xpath需要导入的
from my_fake_useragent import UserAgent #随机请求头的一个包
def get_one_page(url):
headers = {
'User-Agent': UserAgent().random(),
'Referer': 'https: // tieba.baidu.com / index.html',
}
base = 'https://tieba.baidu.com'
response = requests.get(url, headers).text
html = etree.HTML(response)
link_list = html.xpath('//ul[@id="thread_list"]//a[@rel="noreferrer"and@class="j_th_tit "]/@href')
link_list = map(lambda link: base + link, link_list)
for link in link_list:
print(link)
def main():
url = 'https://tieba.baidu.com/f?ie=utf-8&kw=%E8%A1%A8%E6%83%85%E5%90%A7'
get_one_page(url)
if __name__ == '__main__':
main()
输出结果部分:
C:\Users\User\AppData\Local\Programs\Python\Python37\python.exe G:/Python/code/requeats/try.py
https://tieba.baidu.com/p/5788129292
https://tieba.baidu.com/p/4789404681
https://tieba.baidu.com/p/6478509408
https://tieba.baidu.com/p/6497831229
https://tieba.baidu.com/p/6497828481
……
这里我要推荐一个包,就是上面的fake_useragent 包,这个包是随机返回一个User-Agent,这样我就不用辛苦构建一个User-Agent池了。如果你要安装只需pip install fake_useragent 就行了。
以及上面我headers里面的referer测试的时候是不加也能请求的,但是如果你大量爬取,难免要检查,所以headers写入的参数越多可能效果就会更好。
回到原题,我已经提取到每个贴子的URL了,我需要进入每个贴子爬取图片。
因为我要找到图片所在块的规律,所以我得进入一个至少有两三张图片且有广告的贴子,且我不要广告的图片。
然后我进入:https://tieba.baidu.com/p/6299996178
我会发现这个贴子有非常多的图,我们需要找到不同区域的图片,以确保我找的是一个普遍的规律。
第一张图
"j_ueg_post_content p_forbidden_tip" style="display:none;">该楼层疑似违规已被系统折叠 ;"noopener" href="###" class="p_forbidden_post_content_unfold" style="display:;">隐藏此楼"noopener" href="###" class="p_forbidden_post_content_fold" style="display:none;">查看此楼"post_content_127945257402" class="d_post_content j_d_post_content " style="display:;"> 长更,图源各处,自己搜集
![]() "BDE_Image" src="https://imgsa.baidu.com/forum/w%3D580/sign=7015ef856381800a6ee58906813533d6/8a274b90f603738d083a1a28bc1bb051f819ec6a.jpg" size="52322" changedsize="true" width="560" height="560">
"BDE_Image" src="https://imgsa.baidu.com/forum/w%3D580/sign=7015ef856381800a6ee58906813533d6/8a274b90f603738d083a1a28bc1bb051f819ec6a.jpg" size="52322" changedsize="true" width="560" height="560">
![]() "BDE_Image" src="https://imgsa.baidu.com/forum/w%3D580/sign=cf7758d65be736d158138c00ab514ffc/b2ed38dbb6fd5266a76f2a1ea418972bd407361d.jpg" size="44412" changedsize="true" width="560" height="560">
"BDE_Image" src="https://imgsa.baidu.com/forum/w%3D580/sign=cf7758d65be736d158138c00ab514ffc/b2ed38dbb6fd5266a76f2a1ea418972bd407361d.jpg" size="44412" changedsize="true" width="560" height="560">
![]() "BDE_Image" src="https://imgsa.baidu.com/forum/w%3D580/sign=4d6f86f8721ed21b79c92eed9d6fddae/500163d0f703918f6a172ac05e3d269758eec498.jpg" size="11218" width="240" height="240">
"BDE_Image" src="https://imgsa.baidu.com/forum/w%3D580/sign=4d6f86f8721ed21b79c92eed9d6fddae/500163d0f703918f6a172ac05e3d269758eec498.jpg" size="11218" width="240" height="240">
![]() "BDE_Image" src="https://imgsa.baidu.com/forum/w%3D580/sign=c3ee0de7accc7cd9fa2d34d109012104/97e47c1ed21b0ef474948e54d2c451da81cb3e65.jpg" size="28050" width="482" height="360">
"BDE_Image" src="https://imgsa.baidu.com/forum/w%3D580/sign=c3ee0de7accc7cd9fa2d34d109012104/97e47c1ed21b0ef474948e54d2c451da81cb3e65.jpg" size="28050" width="482" height="360">
![]() "BDE_Image" src="https://imgsa.baidu.com/forum/w%3D580/sign=7d835c046809c93d07f20effaf3cf8bb/14599f2f07082838aba4ca1eb799a9014c08f131.jpg" size="79960" changedsize="true" width="560" height="479">
"BDE_Image" src="https://imgsa.baidu.com/forum/w%3D580/sign=7d835c046809c93d07f20effaf3cf8bb/14599f2f07082838aba4ca1eb799a9014c08f131.jpg" size="79960" changedsize="true" width="560" height="479">
第二张图,来自另一个回复:
"j_ueg_post_content p_forbidden_tip" style="display:none;">该楼层疑似违规已被系统折叠 ;"noopener" href="###" class="p_forbidden_post_content_unfold" style="display:;">隐藏此楼"noopener" href="###" class="p_forbidden_post_content_fold" style="display:none;">查看此楼"post_content_127945275558" class="d_post_content j_d_post_content " style="display:;"> ![]() "BDE_Image" src="https://imgsa.baidu.com/forum/w%3D580/sign=731151b14810b912bfc1f6f6f3fdfcb5/2eb30b7b02087bf4b4d141e3fdd3572c11dfcfa5.jpg" size="73764" changedsize="true" width="560" height="560">
"BDE_Image" src="https://imgsa.baidu.com/forum/w%3D580/sign=731151b14810b912bfc1f6f6f3fdfcb5/2eb30b7b02087bf4b4d141e3fdd3572c11dfcfa5.jpg" size="73764" changedsize="true" width="560" height="560">
第三张图,来自广告:
这里从我截取的HTML代码就能知道,我需要的图片,直接在CC标签下属性@class="BDE_Image的img标签里的@src属性里,并且能避免提取到广告里的图片。
然后我试着爬取一页贴子里的第一页回复里的图片。
代码如下:
import requests
from lxml import etree
from my_fake_useragent import UserAgent
def get_one_page(url):
headers = {
'User-Agent': UserAgent().random(),
'Referer': 'https: // tieba.baidu.com / index.html',
}
base = 'https://tieba.baidu.com'
response = requests.get(url, headers).text
html = etree.HTML(response)
link_list = html.xpath('//ul[@id="thread_list"]//a[@rel="noreferrer"and@class="j_th_tit "]/@href')
link_list = map(lambda link: base + link, link_list)
return link_list
def parse_one_page(link):
headers = {
'User-Agent': UserAgent().random(),
'Cookie': '(填你自己的)',
}
imgs = []
url = link
response = requests.get(url, headers).text
html = etree.HTML(response)
img = html.xpath('//cc//img[@class="BDE_Image"]//@src')
imgs.append(img)
return imgs
def main():
url = 'https://tieba.baidu.com/f?ie=utf-8&kw=%E8%A1%A8%E6%83%85%E5%90%A7'
for page in get_one_page(url):
for imgs in parse_one_page(page):
for img in imgs:
print(img)
if __name__ == '__main__':
main()
输出结果部分:
C:\Users\User\AppData\Local\Programs\Python\Python37\python.exe G:/Python/code/requeats/try.py
https://imgsa.baidu.com/forum/w%3D580/sign=9fa533f53cadcbef01347e0e9caf2e0e/f0dbfd039245d6889b38b895a9c27d1ed21b24ea.jpg
https://imgsa.baidu.com/forum/w%3D580/sign=cdf24ef44ba98226b8c12b2fba83b97a/facc14ce36d3d5399036c3423287e950342ab0ca.jpg
http://tiebapic.baidu.com/forum/w%3D580/sign=d106bd7a4e82b2b7a79f39cc01accb0a/7436b812c8fcc3ceb3bfec4d8545d688d43f2072.jpg
http://tiebapic.baidu.com/forum/w%3D580/sign=7cbc896bab315c6043956be7bdb0cbe6/c8cbaa64034f78f06b74bf8d6e310a55b3191c72.jpg
http://tiebapic.baidu.com/forum/w%3D580/sign=6c8ab7c8de177f3e1034fc0540ce3bb9/92ad86d6277f9e2fba4a38760830e924b899f373.jpg
http://tiebapic.baidu.com/forum/w%3D580/sign=c8b5121def1986184147ef8c7aec2e69/81379213b07eca801e96ae9b862397dda04483e5.jpg
http://tiebapic.baidu.com/forum/w%3D580/sign=fc409f2142fbb2fb342b581a7f4b2043/ae30fcfaaf51f3de11212e1883eef01f3b2979e5.jpg
http://tiebapic.baidu.com/forum/w%3D580/sign=6b8fd58ab0efce1bea2bc8c29f50f3e8/ad770eb30f2442a722536bd9c643ad4bd1130217.jpg
http://tiebapic.baidu.com/forum/w%3D580/sign=0e1dfe512d292df597c3ac1d8c305ce2/b1245bafa40f4bfb611ea52a144f78f0f63618a3.jpg
http://tiebapic.baidu.com/forum/w%3D580/sign=43e7890afcf81a4c2632ecc1e72b6029/a17ed009b3de9c829e8cc2f17b81800a18d8438c.jpg
http://tiebapic.baidu.com/forum/w%3D580/sign=7b203fe3dcef76093c0b99971edca301/cf259345d688d43ff040aa8c6a1ed21b0ff43b8c.jpg
……
这样我就提取到了每个图片的网址了。
然后我要添加多的操作方便人为的控制:
①爬取什么贴吧,是自己输入贴吧名,当然如果你只是为了爬取某个贴吧可以不要这个。
②要爬取几页贴子,因为有些贴吧图片众多,如果你只是为了用来斗斗图,就不用爬取很多,所以我可以设置爬取多少页,当然也设置爬取多少张图片就停止程序也很不错。
③爬取每个贴子里面的每页回复。因为贴子质量不同,有些贴子无人问津,有的贴子却有数不胜数的图片,所以我也不可能找到一个适当的值来约束所有的贴子,所以这里我是提取每个贴子里面的总页数,然后用总页数进行循环来爬取每一页回复。
④我要提取图片网址后面他的名字来保存,这里我用os包下的os.path.split。
比如:http://tiebapic.baidu.com/forum/w%3D580/sign=7b203fe3dcef76093c0b99971edca301/cf259345d688d43ff040aa8c6a1ed21b0ff43b8c.jpg这个图片,我保存时他的名字是cf259345d688d43ff040aa8c6a1ed21b0ff43b8c.jpg。
这样的的好处,是不用干巴巴的用1,2,3,4这样累计加来当图片名显得很low,而且图片后缀名也有不同,我们自己手动写很容易出错,比如gif图片,你加jpg他就不动了,这样的图片就毫无意义了。所以我使用os.path.split就能直接提取到图片后半部分,方便了不少。
⑤保存图片,我使用的是urllib下的urlretrieve,导入:from urllib.request import urlretrieve。
全部代码:
import requests
from lxml import etree
from urllib.request import urlretrieve
from my_fake_useragent import UserAgent
import os
def get_one_page(url):
headers = {
'User-Agent': UserAgent().random(),
'Referer': 'https: // tieba.baidu.com / index.html',
}
base = 'https://tieba.baidu.com'
response = requests.get(url, headers).text
html = etree.HTML(response)
link_list = html.xpath('//ul[@id="thread_list"]//a[@rel="noreferrer"and@class="j_th_tit "]/@href')
link_list = map(lambda link: base + link, link_list)
return link_list
# for link in link_list:
# print(link)
def parse_one_page(link):
headers = {
'User-Agent': UserAgent().random(),
'Cookie': '(填你自己的)',
}
imgs = []
url = link + "?pn=1"
response = requests.get(url, headers).text
html = etree.HTML(response)
maxnumber = html.xpath('//li[@class="l_reply_num"]/span[2]/text()')[0]
for i in range(1, int(maxnumber) + 1):
try:
url = link + "?pn={}".format(i)
response = requests.get(url, headers).text
html = etree.HTML(response)
img = html.xpath('//cc//img[@class="BDE_Image"]//@src')
imgs.append(img)
except:
break
return imgs
def main():
print('该爬虫功能为百度贴吧图片爬取!!!')
kw = input('请输入所需爬取贴吧名:')
number = input('请输入所需爬页数:')
j = 1
for i in range(int(number)):
url = 'https://tieba.baidu.com/f?kw=' + kw + '&ie=utf-8&pn={}'.format(i * 50)
try:
for page in get_one_page(url):
print(page)
for imgs in parse_one_page(page):
for img in imgs:
print('正在保存第' + str(j) + '张图片。')
suffix = os.path.split(img)[1]
urlretrieve(img, 'C:\\Users\\User\\Desktop\\图片\\' + kw + '\\' + str(suffix))
j += 1
except:
break
print('保存完毕!')
if __name__ == '__main__':
main()
这里我使用了自己的cookie,大家要用的话请添加你自己的。我保存的使桌面上的一个文件夹,保存时会输出保存了多少页。当然因为我是自己使用图片,并不是工作需要,所以没用多线程来写,大家有需要可以自己添加多线程。
输出结果部分:
C:\Users\User\AppData\Local\Programs\Python\Python37\python.exe G:/Python/code/requeats/tieba.py
该爬虫功能为百度贴吧图片爬取!!!
请输入所需爬取贴吧名:表情包
请输入所需爬页数:1
https://tieba.baidu.com/p/6416580758
正在保存第1张图片。
正在保存第2张图片。
正在保存第3张图片。
正在保存第4张图片。
正在保存第5张图片。
正在保存第6张图片。
正在保存第7张图片。
正在保存第8张图片。
正在保存第9张图片。
正在保存第10张图片。
正在保存第11张图片。
……
……
……
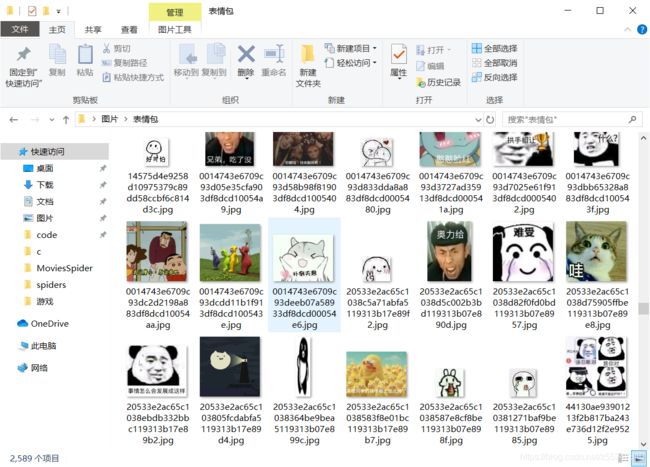
下面是爬取结果,一页贴子居然爬了两千多张,可见表情包吧的产量。