计网——网络层
网络层
网络层的主要任务就是将分组从源主机经过多个网络和多段链路传输到目的主机,可以将该任务划分为分组转发和路由选择两种重要的功能。
4.1网络层向其上层提供的两种服务
-
面向连接的虚电路服务
-
核心思想是“可靠通信应由网络自身来保证”。
-
必须首先建立网络层连接
-
通信双方沿着已建立的虚电路发送分组。
-
通信结束后,需要释放之前所建立的虚电路。
-
-
无连接的数据报服务
-
核心思想是“可靠通信应由用户主机来保证”。
-
不需要建立网络层连接。
-
每个分组可走不同的路径。因此,每个分组的首部都必须携带目的主机的完整地址。
-
通信结束后,没有需要释放的连接。
-
4.2网际协议IP
网际协议(Internet Protocol,IP)是TCP/IP体系结构网际层中的核心协议
IPv4地址及其编址方法
IPv4地址是给因特网上的每一个主机(或路由器)的每一个接口分配的一个在全世界范围内唯一的32比特的标识符。
分类编址方法
-
两级结构的IPv4地址

-
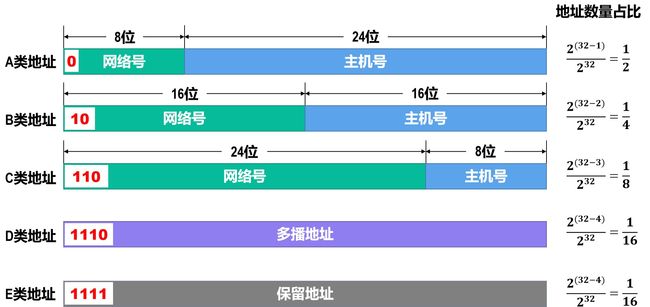
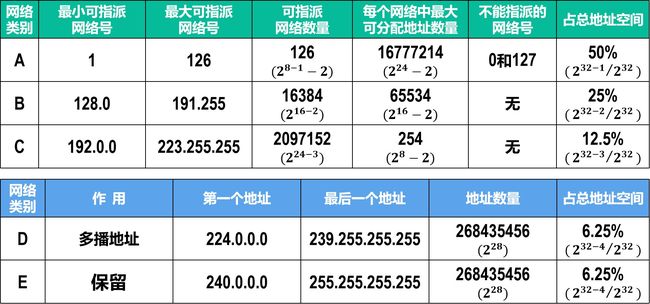
IPv4地址分为A~E五类
-
一般不使用的特殊IPv4地址

-
缺点 : 类似于内存对齐,会造成主机号浪费
划分子网
因为三级结构的ip划分会造成浪费问题,所以我们借助主机号的比特作为网络号。
-
子网掩码也是由32比特构成的,可以表明分类IPv4地址的主机号部分被借用了几个比特作为子网号。
-

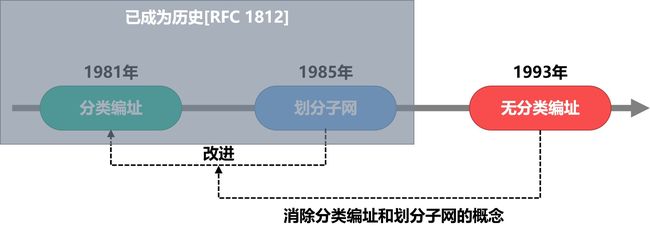
无分类编制方法
划分子网编址方法一定程度上缓解浪费问题,但是IPV4的仍面临全部耗尽的威胁。
CIRD无分类域间路由选择
-
CIDR消除了传统A类、B类和C类地址以及划分子网的概念
-
CIDR可以更加有效地分配IPv4地址资源,并且可以在IPv6使用之前允许因特网的规模继续增长。

地址掩码
与子网掩码类似,用左起多个连续的比特1对应IPv4地址中的网络前缀,之后的多个连续的比特0对应IPv4地址中的主机号。(实际就是完全采用了子网掩码)。
CIDR的斜线记法

CIDR地址块
只要知道CIDR地址块中的任何一个地址,就可以知道该地址块的全部细节。
-
地址块中的最小地址
-
地址块中的最大地址
-
地址块中的地址数量
-
地址块中聚合某类网络(某分类网络)的数量
-
地址掩码
根据客户的需要分配适当大小的CIDR地址块,因此可以更加有效地分配IPv4的地址空间。
路由聚合(构造超网)
通过一个聚合地址块表示路由表中CIRD地址块的超集。

-
网络前缀越长,地址块越小,路由越具体。
-
若路由器查表转发分组时发现有多条路由条目匹配,则选择网络前缀最长的那条路由条目,这称为最长前缀匹配,因为这样的路由更具体。
IPv4地址的应用规划
IPv4地址的应用规划是指将给定的IPv4地址块(或分类网络)划分成若干个更小的地址块(或子网),并将这些地址块(或子网)分配给互联网中的不同网络,进而可以给各网络中的主机和路由器的接口分配IPv4地址。
-
定长的子网掩码进行子网划分
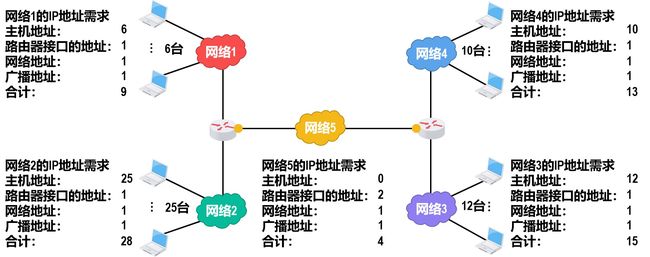
得到一个ip号后,首先 需求分析,然后确定最大的地址需求后划分子网,最后所有网络的地址掩码是一样的(但是这么划分会造成地址资源浪费)。
-
变长的子网掩码进行子网划分
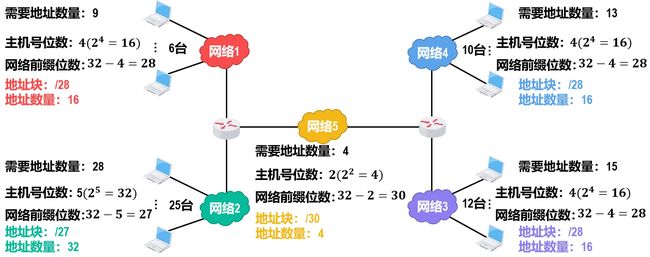
需求分析后,我们先为大的子块选地址(每个子块的起点必须是块大小整数倍作为网络地址,最后的地址作为广播地址)。
IPv4地址与MAC地址
-
在数据包的传送过程中,数据包的源IP地址和目的IP地址保持不变;
-
在数据包的传送过程中,数据包的源MAC地址和目的MAC地址逐链路(或逐网络)改变。
因特网的网际层使用IP地址进行寻址,就可使因特网中各路由器的路由表中的路由记录的数量大大减少,因为只需记录部分网络的网络地址,而不是记录每个网络中各通信设备的各接口的MAC地址。
地址解析协议ARP
我们虽然知道目的IP地址,但是我们不知道目的MAC地址!
我们需要通过ARP协议知道目的MAC地址。
-
ARP广播请求
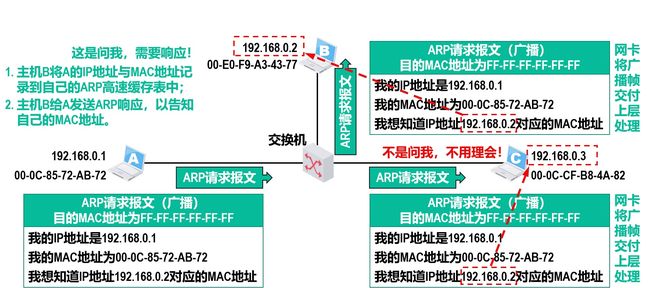
-
ARP单播响应
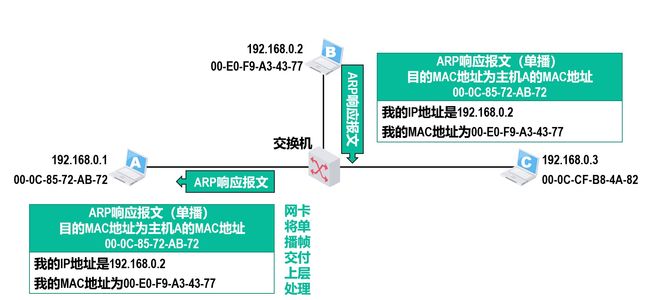
-
ARP高速缓存表中的记录类型和生命周期
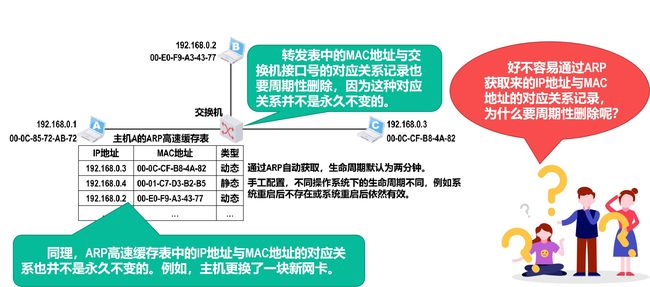
-
因为ARP协议制定较早,ARP有安全问题。
IP数据报的发送和转发过程
-
直接交付和间接交付
同一网络直接交付,不同网络通过路由器间接交付。
-
路由器转发IP数据报
-
如果IP数据报生成周期过,首部误码,路由表没有,则丢弃该IP数据报并向源IP发送差错报告。
-
-
查表转发
路由表中记录 目的网络 地址掩码 下一跳接口号 三个字段。
-
路由器隔离广播域
-
默认网关 记录了本网络的CIDR地址
IPv4数据报的首部格式

标识、标志和片偏移

-
标识
-
长度为16个比特,属于同一个IPv4数据报的各分片数据报应该具有相同的标识。
-
IP软件会维持一个计数器,每产生一个IPv4数据报,计数器值就加1,并将此值赋给标识字段。
-
-
标志
-
最低位(More Fragment,MF)
-
MF=1表示本分片后面还有分片
-
MF=0表示本分片后面没有分片
-
中间位(Don’t Fragment,DF)
-
DF=1表示不允许分片
-
DF=0表示允许分片
-
最高位为保留位,必须设置为0
-
-
片偏移
-
长度为13个比特,该字段的取值以8字节为单位,用来指出分片IPv4数据报的数据载荷偏移其在原IPv4数据报的位置有多远。
-
-
生成时间TTL
-
长度为8个比特,最初以时间为单位后面,最大为255秒,后来以“跳数”为单位,当TTL为0时,就丢弃该IP数据报。
-
-
协议

-
首部检验和
-
长度为16个比特,用于检测IPv4数据报在传输过程中其首部是否出现了差错。
-
IPv4数据报每经过一个路由器,其首部中的某些字段的值(例如生存时间TTL、标志以及片偏移等)都可能发生变化,因此路由器都要重新计算一下首部检验和。
-
计算方法为 协议中16比特段摞起来求和,然后取反码得到首部检验和字段。检验的时候就直接求和,如果为0则说明没错。(开始首部检验和为全0)。
-
4.3因特网的路由选择协议
因特网是全球最大的互联网,它所采取的路由选择协议具有以下三个主要特点
-
自适应
-
因特网采用动态路由选择,能较好地适应网络状态的变化。
-
-
分布式
-
因特网中的各路由器通过相互间的信息交互,共同完成路由信息的获取和更新。
-
-
分层次
-
将整个因特网划分为许多较小的自治系统(Autonomous System,AS)。
-
在自治系统内部IGP和外部EGP采用不同类别的路由选择协议,分别进行路由选择。
-
路由信息协议RIP
路由信息协议(Routing Information Protocol,RIP)是内部网关协议中最先得到广泛使用的协议之一。
-
RIP距离
-
RIP要求自治系统AS内的每一个路由器,都要维护从它自己到AS内其他每一个网络的距离记录。这是一组距离,称为距离向量(Distance-Vector,D-V)。
-
RIP使用跳数(Hop Count)作为度量(Metric)来衡量到达目的网络的距离。
-
RIP将路由器到直连网络的距离定义为1
-
RIP允许一条路径最多只能包含15个路由器,距离等于16时相当于不可达。因此RIP只适用于小型互联网。
-
-
RIP判断好路由的标准
-
RIP认为好的路由就是“距离短”的路由,也就是所通过路由器数量最少的路由。
-
等价负载均衡:当到达同一目的网络有多条RIP距离相等的路由时,可以进行等价负载均衡,也就是将通信量均衡地分布到多条等价的路径上。
-
-
RIP的三个重要特点
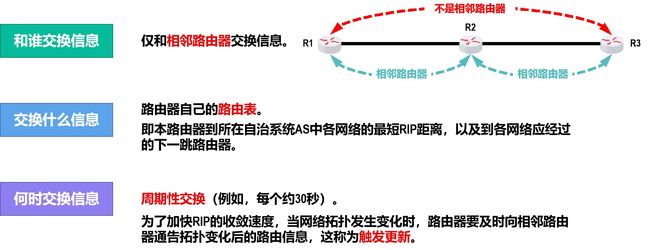
RIP的基本工作过程
(1) 路由器刚开始工作时,只知道自己到直连网络的RIP距离为1。
(2)每个路由器仅和相邻路由器周期性地交换并更新路由信息。
(3)若干次交换和更新后,每个路由器都知道到达本自治系统AS内各网络的最短距离和下一跳路由器,称为收敛。
RIP的路由表存储 目标网络 RIP距离 下一跳节点 3个字段
RIP的距离向量算法
(1)给相邻路由器发送封装有自己所知路由信息的RIP更新报文 (2)修改来自邻居路由器的路由信息
-
如果 目的网络 与 下一跳相同 RIP路由表会按照最新的来更新
-
如果RIP距离和邻居表一样就记录下用来负载均衡。
-
如果下一跳不同,则RIP距离用最小的那个。
-
没有的节点直接加上。
(3)基于修改好的来自邻居路由器的路由信息更新自己的路由表
时间参数
-
路由器每隔大约30秒向其所有相邻路由器发送路由更新报文。
-
若180秒(默认)没有收到某条路由条目的更新报文,则把该路由条目标记为无效(即把RIP距离设置为16,表示不可达),若再过一段时间(如120秒),还没有收到该路由条目的更新报文,则将该路由条目从路由表中删除。
RIP存在的问题
-
“坏消息传得慢”
-
因为他们按照邻居RIP路由表来更新自身RIP路由表,所以会被误导形成路由环路。(这是距离向量算法的一个固有问题)
-
当路由表发生变化时就立即发送路由更新报文(即“触发更新”),而不仅是周期性发送。
-
让路由器记录收到某个特定路由信息的接口,而不让同一路由信息再通过此接口向反方向传送(即“水平分割”)。
-
RIP相关报文使用运输层的用户数据报协议UDP进行封装,使用的UDP端口号为520。
-
从RIP报文封装的角度看,RIP属于TCP/IP体系结构的应用层。
-
但RIP的核心功能是路由选择,这属于TCP/IP体系结构的网际层。
RIP的优缺点
-
优点
-
实现简单,路由器开销小。
-
如果一个路由器发现了RIP距离更短的路由,那么这种更新信息就传播得很快,即“好消息传播得快”。
-
-
缺点
-
RIP限制了最大RIP距离为15,这就限制了使用RIP的自治系统AS的规模。
-
相邻路由器之间交换的路由信息是路由器中的完整路由表,因而随着网络规模的扩大,开销也随之增大。
-
“坏消息传播得慢”,使更新过程的收敛时间过长。因此,对于规模较大的自治系统AS,应当使用OSPF协议。
-
开放最短路径优先OSPF
开放最短路径优先(Open Shortest Path First,OSPF)协议是为了克服路由信息协议RIP的缺点在1989年开发出来的。
-
“最短路径优先”是因为使用了Dijkstra提出的最短路径算法(SPF)
-
“开放”表明OSPF协议不是受某一厂商控制,而是公开发表的。
-
OSPF是基于链路状态的,而不像RIP是基于距离向量的。
-
OSPF基于链路状态并采用最短路径算法计算路由,从算法上保证了不会产生路由环路。
-
OSPF不限制网络规模,更新效率高,收敛速度快。
OSPF的相关基本概念
-
链路状态LS

-
邻居关系的建立和维护
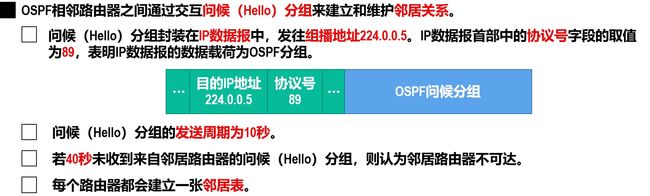
-
链路状态通告LSA

-
链路状态更新分组LSU

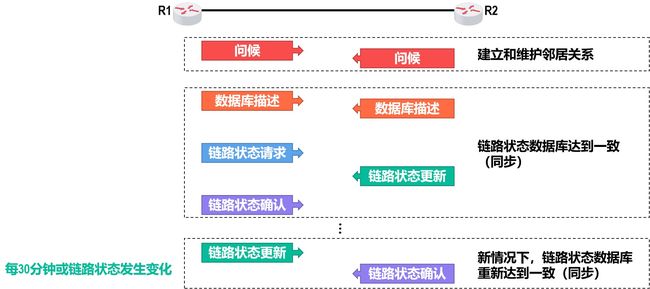
发送确认的意思是 我收到啦,不要再给我发啦!
-
链路状态数据库LSDB

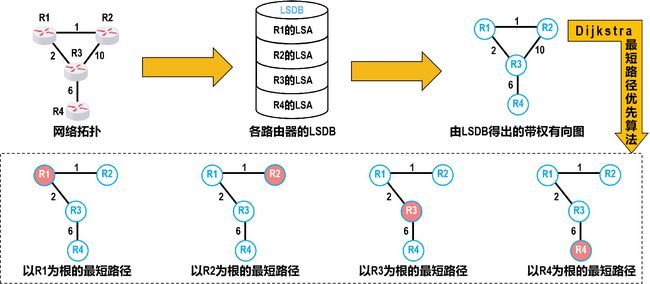
OSPF的五种分组类型
-
问候分组
-
数据库描述分组
-
链路状态请求分组
-
链路状态更新分组
-
链路状态确认分组
OSPF的基本工作过程
多点接入网络中的OSPF路由器

这样可以有效减少邻居关系
OSPF划分区域
-
为了使OSPF协议能够用于规模很大的网络,OSPF把一个自治系统AS再划分为若干个更小的范围。
-
每个区域的规模不应太大,一般所包含的路由器不应超过200个。
-
划分区域的好处就是把利用洪泛法交换链路状态信息的范围局限于每一个区域,而不是整个自治系统AS,这样就减少了整个网络上的通信量。
-
采用划分区域的方法,虽然使交换信息的种类增多了,同时也使OSPF协议更加复杂了,但这样做能使每一个区域内部交换路由信息的通信量大大减小,因而使OSPF协议能够用于规模更大的自治系统AS。
边界网关协议BGP
边界网关协议(Border Gateway Protocol,BGP)属于外部网关协议EGP这个类别,用于自治系统AS之间的路由选择协议。
-
由于在不同AS内度量路由的“代价”(距离、带宽、费用等)可能不同,因此对于AS之间的路由选择,使用统一的“代价”作为度量来寻找最佳路由是不行的。
-
AS之间的路由选择还必须考虑相关策略(政治、经济、安全等)
BGP边界路由器
-
配置BGP时,每个AS的管理员要选择至少一个路由器作为该AS的“BGP发言人”。
-
一般来说,两个BGP发言人都是通过一个共享网络连接在一起的,而BGP发言人往往就是BGP边界路由器。
-
使用TCP连接交换路由信息的两个BGP发言人,彼此称为对方的邻站(neighbor)或对等站(peer)。
-
BGP发言人除了运行BGP协议外,还必须运行自己所在AS所使用的内部网关协议IGP,例如RIP或OSPF。
-
BGP发言人交换网络可达性的信息,也就是要到达某个网络所要经过的一系列自治系统。
-
当BGP发言人相互交换了网络可达性的信息后,各BGP发言人就根据所采用的策略,从收到的路由信息中找出到达各自治系统的较好的路由,也就是构造出树形结构且不存在环路的自治系统连通图(生成树)。
BGP-4的四种报文
-
打开报文
-
更新报文
-
保活报文
-
通知报文
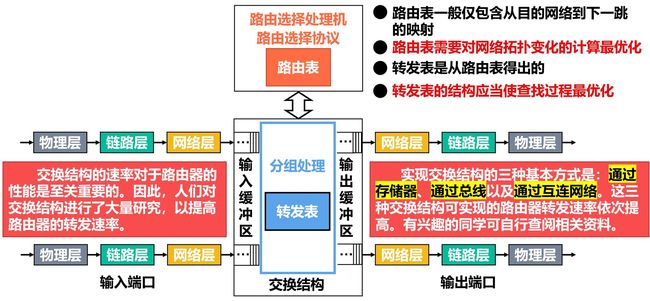
路由器的基本工作原理
路由器是一种具有多个输入端口和输出端口的专用计算机,其任务是转发分组。
-
路由选择部分:核心构件是路由选择处理机,其任务是根据所使用的路由选择协议,周期性地与其他路由器进行路由信息的交换,以便构建和更新路由表。
-
分组转发部分:由一组输入端口、交换结构以及一组输出端口。
4.4网际控制报文协议ICMP
为了更有效地转发IP数据报以及提高IP数据报交付成功的机会,TCP/IP体系结构的网际层使用了网际控制报文协议(Internet Control Message Protocol,ICMP)
主机或路由器使用ICMP来发送差错报告报文和询问报文。
ICMP报文被封装在IP数据报中发送
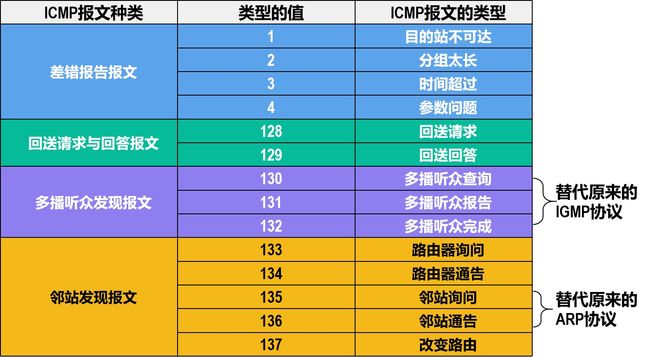
ICMP报文的种类
-
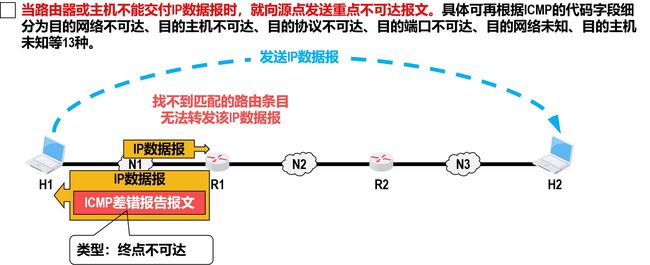
终点不可达
-
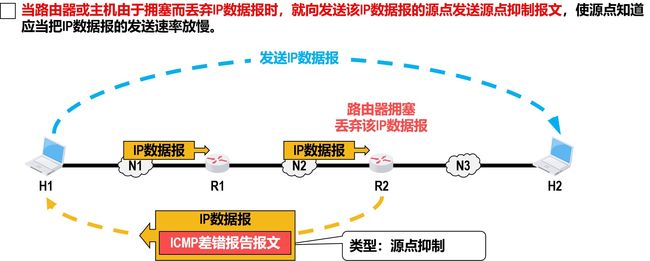
源点抑制
-
时间超过(超时)

-
参数问题
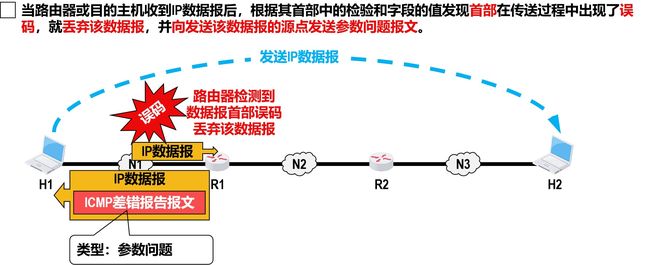
-
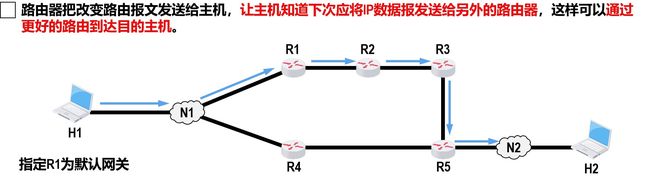
改变路由(重定向)
ICMP询问报文
-
回送请求和回答
-
由主机或路由器向一个特定的目的主机或路由器发出。
-
收到此报文的主机或路由器必须给发送该报文的源主机或路由器发送ICMP回送回答报文。
-
这种询问报文用来测试目的站是否可达以及了解其有关状态。
-
-
时间戳请求和回答
-
用来请求某个主机或路由器回答当前的日期和时间。
-
在ICMP时间戳回答报文中有一个32比特的字段,其中写入的整数代表从1900年1月1日起到当前时刻一共有多少秒。
-
这种询问报文用来进行时钟同步和测量时间。
-
ICMP的典型应用
-
分组网间探测PING 用于测试主机或路由器之间的连通性。(PING是TCP/IP体系结构的应用层直接使用网际层ICMP)
-
跟踪路由traceroute 用于探测IP数据报从源主机到达目的主机要经过哪些路由器。
4.5虚拟专用网VPN和网络地址转换NAT
虚拟专用网VPN
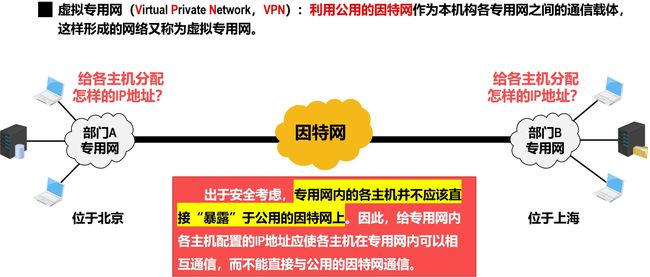
专用地址(私有地址)
给专用网内各主机配置的IP地址应该是该专用网所在机构可以自行分配的IP地址,这类IP地址仅在机构内部有效,称为专用地址(Private Address),不需要向因特网的管理机构申请。


VPN也被叫做IP隧道技术
VPN的类型
-
内联网VPN 同一机构内不同部门的内部网络所构成的VPN,又称为内联网VPN。
-
外联网VPN 有时,一个机构的虚拟专用网VPN需要某些外部机构(通常是合作伙伴)参加进来,这样的VPN就称为外联网VPN。
-
远程接入VPN 在外地工作的员工需要访问公司内部的专用网时,只要在任何地点接入因特网,运行驻留在员工PC中的VPN软件,在员工的PC和公司的主机之间建立VPN隧道,就可以访问专用网中的资源,这种虚拟专用网又称为远程接入VPN。
网络地址转换NAT
网络地址转换(Network Address Translation,NAT)技术于1994年被提出,用来缓解IPv4地址空间即将耗尽的问题。
-
NAT能使大量使用内部专用地址的专用网络用户共享少量外部全球地址来访问因特网上的主机和资源。
-
这种方法需要在专用网络连接到因特网的路由器上安装NAT软件。装有NAT软件的路由器称为NAT路由器,它至少要有一个有效的外部全球地址IPG。这样,所有使用内部专用地址的主机在和外部因特网通信时,都要在NAT路由器上将其内部专用地址转换成IPG。
就是局域网就可以都用专用地址,对外连接就用一个共同的IP地址。
NAT路由器有几个全球IP地址,就最多能有几台主机同时接入因特网。
网络地址与端口号转换NAPT
-
将NAT和运输层端口号结合使用,称为网络地址与端口号转换(Network Address and Port Translation,NAPT)。
-
这样就可以使内部专用网中使用专用地址的大量主机,共用NAT路由器上的1个全球IP地址,因而可以同时与因特网中的不同主机进行通信。
-
现在很多家用路由器将家中各种智能设备(手机、平板、笔记本电脑、台式电脑、物联网设备等)接入因特网,这种路由器实际上就是一个NAPT路由器,但往往并不运行路由选择协议。
4.6IP多播
多播(Multicast,也称为组播)是一种实现“一对多”通信的技术,与传统单播“一对一”通信相比,多播可以极大地节省网络资源。
在因特网上进行的多播,称为IP多播。
IP多播地址和多播组
在IPv4中,D类地址被作为多播地址。
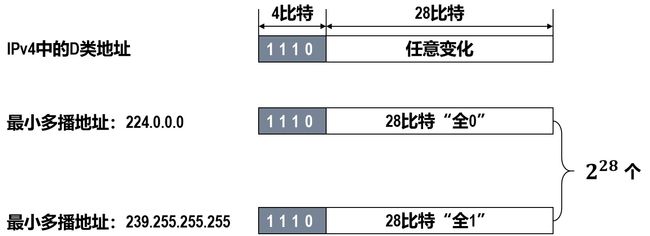
多播地址只能用作目的地址,而不能用作源地址。
用每一个D类地址来标识一个多播组,使用同一个IP多播地址接收IP多播数据报的所有主机就构成了一个多播组。
-
每个多播组的成员是可以随时变动的,一台主机可以随时加入或离开多播组。
-
多播组成员的数量和所在的地理位置也不受限制,一台主机可以属于几个多播组。
-
非多播组成员也可以向多播组发送IP多播数据报。
-
与IP数据报相同,IP多播数据报也是“尽最大努力交付”,不保证一定能够交付给多播组内的所有成员。
IP多播地址分类
-
预留的多播地址(永久多播地址)
-
全球范围可用的多播地址
-
本地管理的多播地址
在局域网上进行硬件多播
-
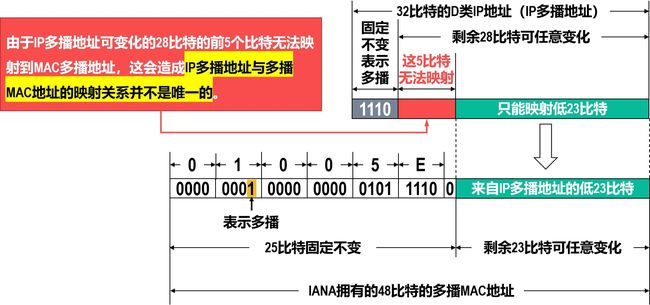
由于MAC地址(也称为硬件地址)有多播MAC地址这种类型,因此只要把IPv4多播地址映射成多播MAC地址,即可将IP多播数据报封装在局域网的MAC帧中,而MAC帧首部中的目的MAC地址字段的值,就设置为由IPv4多播地址映射成的多播MAC地址。这样,可以很方便地利用硬件多播来实现局域网内的IP多播。
-
当给某个多播组的成员主机配置其所属多播组的IP多播地址时,系统就会根据映射规则从该IP多播地址生成相应的局域网多播MAC地址。
以太网多播MAC地址
-
因特网号码指派管理局IANA,将自己从IEEE注册管理机构申请到的以太网MAC地址块中从01-00-5E-00-00-00到01-00-5E-7F-FF-FF的多播MAC地址,用于映射IPv4多播地址。
-
这些多播MAC地址的左起前25个比特都是相同的,剩余23个比特可以任意变化。
IP多播地址到以太网多播MAC地址的映射
-
映射关系并不唯一
-

-

-
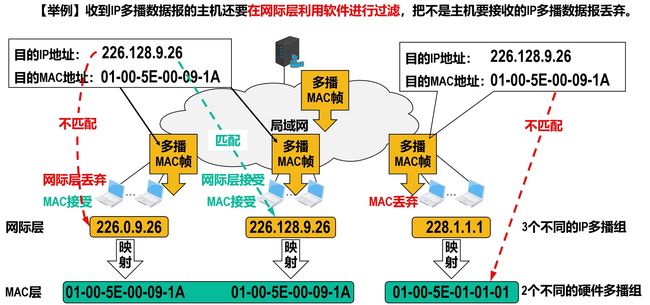
在因特网上进行IP多播需要的两种协议
-
网际组管理协议IGMP
-
网际组管理协议(Internet Group Management Protocol,IGMP)是TCP/IP体系结构网际层中的协议,其作用是让连接在本地局域网上的多播路由器知道本局域网上是否有主机(实际上是主机中的某个进程)加入或退出了某个多播组。
-
IGMP仅在本网络有效,使用IGMP并不能知道多播组所包含的成员数量,也不能知道多播组的成员都分布在哪些网络中。
-
-
多播路由选择协议
-
多播路由选择协议的主要任务是:在多播路由器之间为每个多播组建立一个多播转发树。
-
多播转发树连接多播源和所有拥有该多播组成员的路由器。
-
IP多播数据报只要沿着多播转发树进行洪泛,就能被传送到所有拥有该多播组成员的多播路由器。
-
之后,在多播路由器所直连的局域网内,多播路由器通过硬件多播,将IP多播数据报发送给该多播组的所有成员。
-
针对不同的多播组需要维护不同的多播转发树,而且必须动态地适应多播组成员的变化,但此时网络拓扑并不一定发生变化,因此多播路由选择协议要比单播路由选择协议(例如RIP、OSPF等)复杂得多。
-
即使某个主机不是任何多播组的成员,它也可以向任何多播组发送多播数据报。
-
为了覆盖多播组的所有成员,多播转发树可能要经过一些没有多播组成员的路由器。
-
网际组管理协议IGMP
IGMP的三种报文类型
-
成员报告报文
-
成员查询报文
-
离开组报文
IGMP报文的封装
-
IGMP报文被封装在IP数据报中传送

IGMP的基本工作原理
-
加入多播组
-
-
监视多播组的成员变化
-
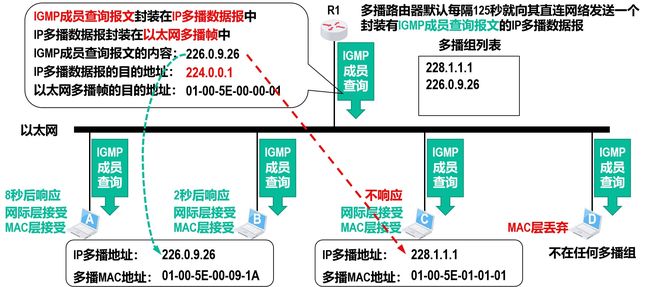
-
如果同一多播组的成员响应了,则其他的多播组成员就可以取消响应。
-
-
退出多播组
-
IGMPv2在IGMPv1的基础上增加了一个可选项:当主机要退出某个多播组时,可主动发送一个离开组报文而不必等待多播路由器的查询。这样可使多播路由器能够更快地发现某个组有成员离开。
-

-
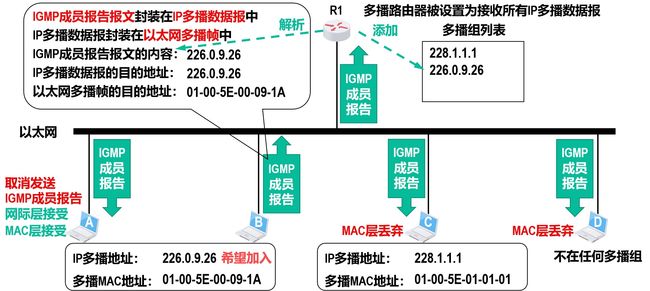
多播路由选择协议
多播路由选择协议的主要任务是:在多播路由器之间为每个多播组建立一个多播转发树。 多播转发树连接多播源和所拥有该多播组成员的路由器。
-
基于源树的多播路由选择
-
基于源树的多播路由选择的最典型算法是反向路径多播(Reverse Path Multicasting,RPM)算法。
-
利用反向路径广播(Reverse Path Broadcasting,RPB)算法建立一个广播转发树。
-
利用剪枝(Pruning)算法,剪除广播转发树中的下游非成员路由器,获得一个多播转发树。
-
-
组共享树多播路由选择
-
组共享树多播路由选择采用基于核心的分布式生成树算法来建立共享树。
-
该方法在每个多播组中指定一个核心(core)路由器,以该路由器为根,建立一棵连接多播组的所有成员路由器的生成树,作为多播转发树。
-
每个多播组中除了核心路由器,其他所有成员路由器都会向自己多播组中的核心路由器单播加入报文。
-
-
因特网的多播路由选择协议
-
目前还没有在整个因特网范围使用的多播路由选择协议。一些建议使用的多播路由选择协议
-
距离向量多播路由选择协议(Distance Vector Multicast Routing Protocol,DVMRP)
-
开放最短路径优先的多播扩展(Multicast Extensions to OSPF,MOSPF)
-
协议无关多播-稀疏方式(Protocol Independent Multicast-Sparse Mode,PIM-SM)
-
协议无关多播-密集方式(Protocol Independent Multicast-Dense Mode,PIM-DM)
-
基于核心的转发树(Core Based Tree,CBT)
目前IP多播主要应用在一些局部的园区网络、专用网络或者虚拟专用网中。
-
4.7移动IP技术

移动IP技术的基本工作原理
-
代理发现与注册
-
-
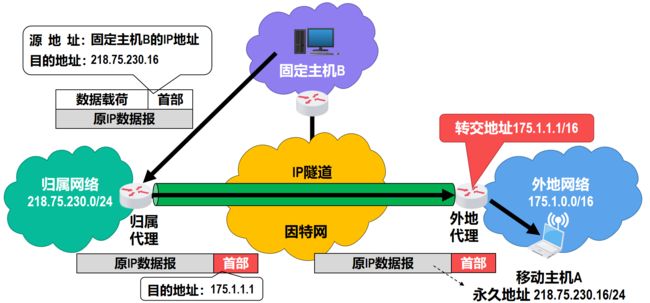
固定主机向移动主机发送IP数据报
-
当外地代理和移动主机不是同一台设备时,转交地址实际上是外地代理的地址而不是移动主机的地址,转交地址既不会作为移动主机发送IP数据报的源地址,也不会作为移动主机所接收的IP数据报的目的地址。
-
所有使用同一外地代理的移动主机都可以共享同一个转交地址。
-
当外地代理从IP隧道中收到并解封出原IP数据报时,会在自己的代理注册表中查找移动主机的永久地址所对应的MAC地址,并将该数据报封装到目的地址为该MAC地址的帧中发送给移动主机。这与我们之前介绍的IP数据报的正常转发流程是不同的,否则会造成该数据报又被发回移动主机的归属网络。
-
-
-
移动主机向固定主机发送IP数据报
-
IP数据报被移动主机A按照正常的发送流程发送出去即可。
-
由于IP路由器并不关心IP数据报的源地址,因此该IP数据报被直接路由到固定主机B,而无须再通过归属代理进行转发。
-
为此,移动主机可以将外地代理作为自己的默认路由器,也可以通过代理发现协议从外地代理获取外地网络中其他路由器的地址,并将其设置为自己的默认路由器。
-
-
同址转交地址

就是使用外地网络的一个地址作为自己的IP地址和外地代理地址。
-
三角形路由问题
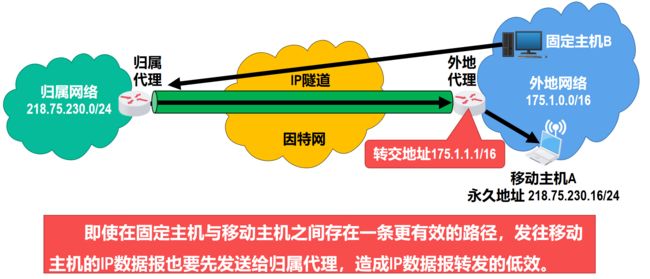
-
解决三角形路由问题的一种方法
-
给固定主机配置一个通信代理,固定主机发送给移动主机的IP数据报,都要通过该通信代理转发。
-
通信代理先从归属代理获取移动主机的转交地址,之后所有发送给移动主机的IP数据报,都利用转交地址直接通过IP隧道发送给移动主机的外地代理,而无须再通过移动主机的归属代理进行转发。
-
这种方法以增加复杂性为代价,并要求固定主机也要配置通信代理,也就是对固定主机不再透明。
-

4.8下一代网际协议IPv6
因特网经过几十年的飞速发展,到2011年2月3日,因特网号码分配管理局IANA宣布IPv4地址已经分配完毕,因特网服务提供者ISP已经不能再申请到新的IPv4地址块。
如果没有网络地址转换NAT技术的广泛应用,IPv4早已停止发展。然而,NAT仅仅是为了延长IPv4使用寿命而采取的权宜之计,解决IPv4地址耗尽的根本措施就是采用具有更大地址空间(IP地址的长度为128比特)的新版本IP,即IPv6。
-
直接将因特网的核心协议从IPv4更换成IPv6是不可行的。
-
到目前为止,IPv6还只是草案标准阶段

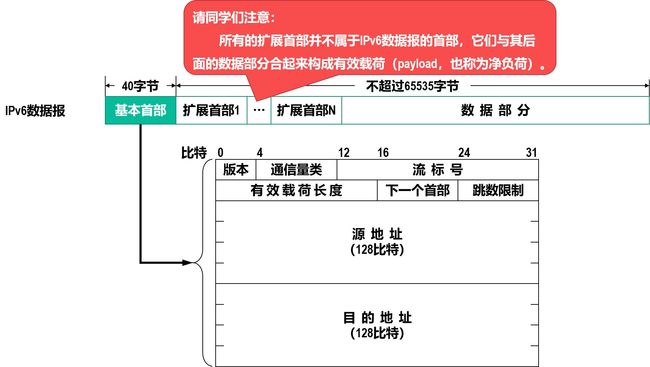
IPv6数据报的基本首部
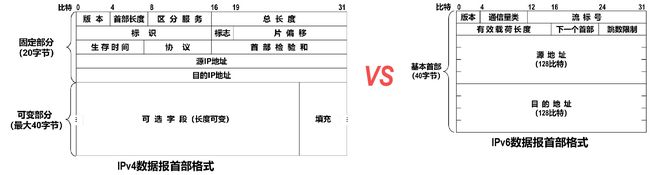
IPv4首部与IPv6基本首部的对比
-
IPv6将IPv4数据报首部中不必要的功能取消了,这使得IPv6数据报基本首部中的字段数量减少到只有8个。
-
但由于IPv6地址的长度扩展到了128比特,因此使得IPv6数据报基本首部的长度反而增大到了40字节,比IPv4数据报首部固定部分的长度(20字节)增大了20字节。
-
取消了首部长度字段,因为IPv6数据报的首部长度是固定的40字节。
-
取消了区分服务(服务类型)字段,因为IPv6数据报首部中的通信量类和流标号字段实现了区分服务字段的功能。
-
取消了总长度字段,改用有效载荷长度字段。这是因为IPv6数据报的首部长度是固定的40字节,只有其后面的有效载荷长度是可变的。
-
取消了标识、标志和片偏移字段,因为这些功能已包含在IPv6数据报的分片扩展首部中。
-
把生存时间TTL字段改称为跳数限制字段,这样名称与作用更加一致。
-
取消了协议字段,改用下一个首部字段。
-
取消了首部检验和字段,这样可以加快路由器处理IPv6数据报的速度。
-
取消了选项字段,改用扩展首部来实现选项功能。
IPv6基本首部中的各字段
-
版本 长度为4比特,用来表示IP协议的版本。对于IPv6该字段的值是6。
-
通信量类 长度为8比特,该字段用来区分不同的IPv6数据报的类别或优先级。目前正在进行不同的通信量类性能的实验。
-
流标号 长度为20比特。IPv6提出了流的抽象概念。
-
所有属于同一个流的IPv6数据报都具有同样的流标号。换句话说,流标号用于资源分配。
-
流标号对于实时音视频数据的传送特别有用,但对于传统的非实时数据,流标号则没有用处,把流标号字段的值置为0即可。
-
-
有效载荷长度 长度为16比特,它指明IPv6数据报基本首部后面的有效载荷(包括扩展首部和数据部分)的字节数量。
-
下一个首部 长度为8比特。该字段相当于IPv4数据报首部中的协议字段或可选字段。
-
当IPv6数据报没有扩展首部时,该字段的作用与IPv4的协议字段一样,它的值指出了IPv6数据报基本首部后面的数据是何种协议数据单元PDU。
-
当IPv6数据报基本首部后面带有扩展首部时,该字段的值就标识后面第一个扩展首部的类型。
-
-
跳数限制 长度为8比特。该字段用来防止IPv6数据报在因特网中永久兜圈。(最大255跳)
IPv6数据报的扩展首部
实际上,在路径中的路由器对很多选项是不需要检查的。因此,为了提高路由器对数据包的处理效率,IPv6把原来IPv4首部中的选项字段都放在了扩展首部中,由路径两端的源点和终点的主机来处理,而数据报传送路径中的所有路由器都不处理这些扩展首部(除逐跳选项扩展首部)。
六种扩展首部
-
逐跳选项
-
路由选择
-
分片
-
鉴别
-
封装安全有效载荷
-
目的站选项
-
每一个扩展首部都由若干个字段组成,它们的长度也各不相同。
-
所有扩展首部中的第一个字段都是8比特的下一个首部字段。该字段的值指出在该扩展首部后面是何种扩展首部。
-
当使用多个扩展首部时,应按以上的先后顺序出现。
IPv6地址
IPv6地址空间大小 2的128次方个
IPv6地址的表示方法
-
冒号十六进制表示法
-
左侧零”省略和“连续零”压缩。
-
“左侧零”省略是指两个冒号间的十六进制数中最前面的一串0可以省略不写。
-
”连续零”压缩是指一连串连续的0可以用一对冒号取代
-
-
只能使用一次“连续0”压缩,否则会造成歧义。
-
-
冒号十六进制结合点分十进制
-
这在过渡阶段非常有用
-
-
冒号十六进制结合CIDR斜线记法
IPv6地址分类
IPv6数据报的目的地址有三种基本类型
-
单播(unicast) 传统的点对点通信
-
多播(multicast) 一点对多点的通信。数据报发送到一组计算机中的每一个。IPv6没有采用广播的术语,而将广播看作多播的一个特例。
-
任播(anycast) 这是IPv6新增的一种类型。任播的终点是一组计算机,但数据报只交付其中的一个,通常是按照路由算法得出的距离最近的一个。
IPv6地址分类
-
未指明地址
-
128个比特为“全0”的地址,可缩写为两个冒号“::”。
-
该地址不能用作目的地址,只能用于还没有配置到一个标准IPv6地址的主机用作源地址。
-
-
环回地址
-
最低比特为1,其余127个比特为“全0”,即0:0:0:0:0:0:0:1,可缩写为::1。
-
-
多播地址
-
最高8比特为“全1”的地址,可记为FF00::/8。
-
-
本地链路单播地址
-
最高10比特为1111111010的地址,可记为FE80::/10。
-
即使用户网络没有连接到因特网,但仍然可以使用TCP/IP协议。连接在这种网络上的主机都可以使用本地链路单播地址进行通信,但不能和因特网上的其他主机通信。
-
-
全球单播地址
-
全球单播地址是使用得最多的一类地址。
-
IPv6全球单播地址采用三级结构,这是为了使路由器可以更快地查找路由。
-
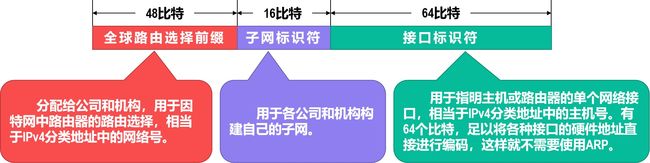
-
从IPv4向IPv6过渡
因特网上使用IPv4的路由器的数量太大,要让所有路由器都改用IPv6并不能一蹴而就。因此,从IPv4转变到IPv6只能采用逐步演进的办法。
新部署的IPv6系统必须能够向后兼容,也就是IPv6系统必须能够接收和转发IPv4数据报,并且能够为IPv4数据报选择路由。
-
使用双协议栈
-
双协议栈(Dual Stack)是指在完全过渡到IPv6之前,使一部分主机或路由器装有IPv4和IPv6两套协议栈。
-
双协议栈主机通过域名系统DNS查询目的主机采用的IP地址
-
若DNS返回的是IPv4地址,则双协议栈的源主机就使用IPv4地址;
-
若DNS返回的是IPv6地址,则双协议栈的源主机就使用IPv6地址。
-
-
使用隧道技术
-
当IPv6数据报要进入IPv4网络时,将IPv6数据报重新封装成IPv4数据报,即整个IPv6数据报成为IPv4数据报的数据载荷。
-
封装有IPv6数据报的IPv4数据报在IPv4网络中传输。
-
当IPv4数据报要离开IPv4网络时,再将其数据载荷(即原来的IPv6数据报)取出并转发到IPv6网络。
-
网际控制报文协议ICMPv6
由于IPv6与IPv4一样,都不确保数据报的可靠交付,因此IPv6也需要使用网际控制报文协议ICMP来向发送IPv6数据报的源主机反馈一些差错信息,相应的ICMP版本为ICMPv6。
-
ICMPv6比ICMPv4要复杂得多,它合并了原来的地址解析协议ARP和网际组管理协议IGMP的功能。因此与IPv6配套使用的网际层协议就只有ICMPv6这一个协议。
ICMPv6报文的封装
-
ICMPv6报文需要封装成IPv6数据报进行发送
-
下一首部取值为 58 表明为ICMPv6报文
ICMPv6报文的分类
-
ICMPv6报文可被用来报告差错、获取信息、探测邻站或管理多播通信。
-
在对ICMPv6报文进行分类时,不同的RFC文档使用了不同的策略
-
常用的几种ICMPv6报文
-
4.9软件定义网络SDN
软件定义网络(Software Defined Network,SDN)的概念最早由斯坦福大学的Nick McKeown教授于2009年提出。
SDN最初只是学术界讨论的一种新型网络体系结构。
SDN是当前网络领域最热门和最具发展前途的技术之一,成为近年来的研究热点。
-
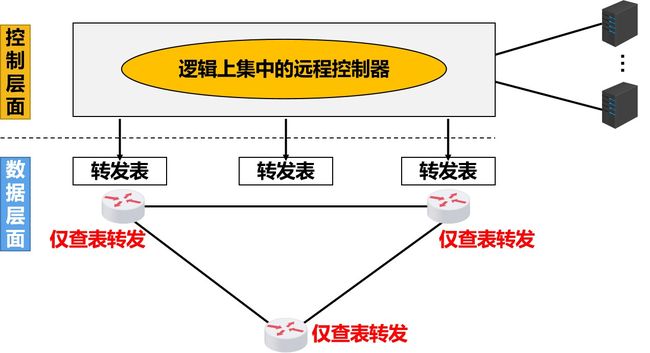
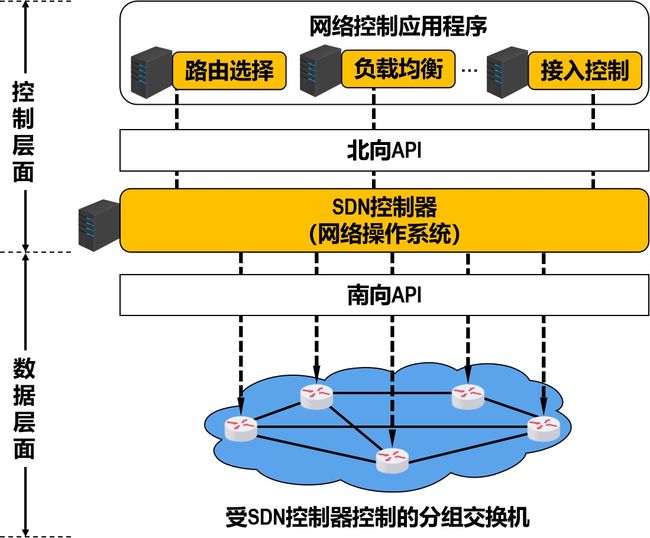
在SDN体系结构中,路由器中的路由软件都不存在了。因此,路由器之间不再交换路由信息。
-
在控制层面中,有一个在逻辑上集中的远程控制器。
逻辑上集中的远程控制器在物理上可由不同地点的多个服务器组成。
-
远程控制器掌握各主机和整个网络的状态。
-
远程控制器能够为每一个分组计算出最佳的路由。
-
远程控制器为每一个路由器生成其正确的转发表。
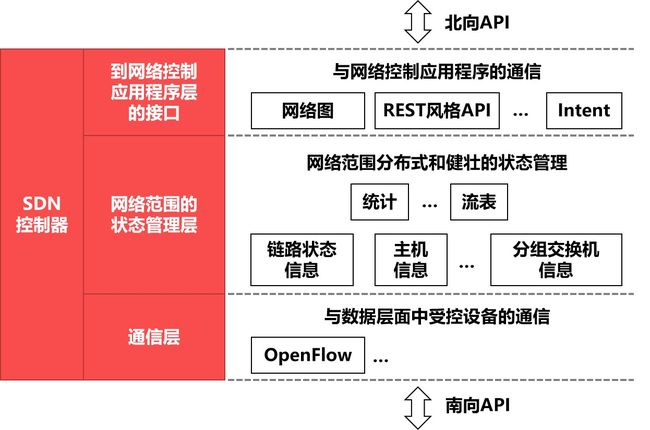
SDN这种新型网络体系结构的核心思想:把网络的控制层面和数据层面分离,而让控制层面利用软件来控制数据层面中的许多设备。

OpenFlow协议
OpenFlow协议是一个得到高度认可的标准,在讨论SDN时往往与OpenFlow一起讨论。
OpenFlow协议可被看成是SDN体系结构中控制层面与数据层面之间的通信接口。
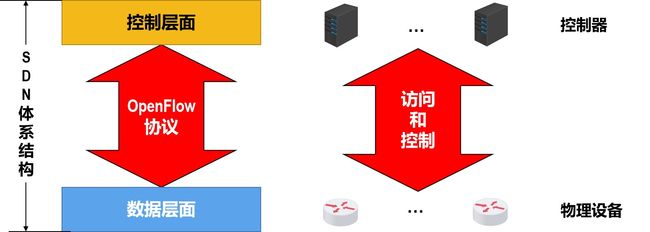
OpenFlow协议使得控制层面的控制器可以对数据层面中的物理设备进行直接访问和控制。
-
传统意义上的数据层面的任务
-
(1)进行“匹配”:查找转发表中的网络前缀,进行最长前缀匹配。
-
(2)执行“动作”:把分组从匹配结果指明的接口转发出去。
-
-
SDN中的广义转发
-
(1)进行“匹配”:能够对网络体系结构中各层(数据链路层、网络层、运输层)首部中的字段进行匹配。
-
(2)执行“动作”:不仅转发分组,还可以负载均衡、重写IP首部(类似NAT路由器中的地址转换)、人为地阻挡或丢弃一些分组(类似防火墙一样)。
-
-
OpenFlow交换机和流表
-
在SDN的广义转发中,完成“匹配+动作”的设备并不局限在网络层工作,因此不再称为路由器,而称为“OpenFlow交换机”或“分组交换机”,或更简单地称为“交换机”。
-
相应的,在SDN中取代传统路由器中转发表的是“流表(Flow Table)”。
-
OpenFlow交换机中的流表是由SDN远程控制器来管理的。SDN远程控制器通过一个安全信道,使用OpenFlow协议来管理OpenFlow交换机中的流表。
-
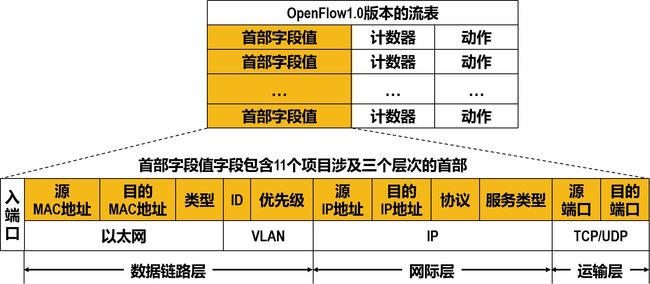
每个OpenFlow交换机必须有一个或多个流表。每一个流表可以包含多个流表项。每个流表项包含三个字段:首部字段值(或称匹配字段)、计数器、动作。
-
-
首部字段值字段 在OpenFlow交换机中,既可以处理数据链路层的帧,也可以处理网际层的IP数据报,还可以处理运输层的TCP或UDP报文。
-
计数器字段 计数器字段是一组计数器
-
记录已经与该流表项匹配的分组数量的计数器;
-
记录该流表项上次更新到现在经历时间的计数器。
-
-
动作字段 动作字段是一组动作,执行该流表项中动作字段指明的以下某个或多个动作
-
把分组转发到指明的端口
-
丢弃分组
-
把分组进行复制后再从多个端口转发出去
-
重写分组的首部字段(包括数据链路层、网际层以及运输层的首部)
-
-
SDN体系结构
-
SDN体系结构的四个关键特征
-
基于流的转发
-
数据层面与控制层面分离
-
位于数据层面分组交换机之外的网络控制功能
-
可编程的网络
-
-
SDN控制器