文献阅读:Exchange-of-Thought: Enhancing Large Language Model Capabilities through Cross-Model Communicat
- 文献阅读:Exchange-of-Thought: Enhancing Large Language Model Capabilities through Cross-Model Communication
- 1. 文章简介
- 2. 方法介绍
- 1. 交流范式
- 1. Memory
- 2. Report
- 3. Relay
- 4. Debate
- 2. 终止条件
- 3. 置信度评估
- 1. 交流范式
- 3. 实验考察 & 结论
- 1. 实验设计
- 2. 基础实验结果
- 3. 细节讨论 & 分析
- 1. 不同communication范式的影响
- 2. 不同终止条件的情况对回答效果的影响
- 3. 置信度评估
- 4. 迭代轮次分析
- 5. 调用成本考察
- 6. 不同大模型下的泛化性
- 7. 不同节点模型的影响
- 4. 总结 & 思考
- 文献链接:https://arxiv.org/abs/2312.01823
1. 文章简介
这篇文章是23年12月复旦发表的一篇关于prompt tuning的文章。
文中作为主要参照的Prompt Tuning的方法主要是CoT(Chain of Thought)以及SC(Self-Correction),前者主要是通过将问题拆解为多个中间问题进行逐一回答,后者则是通过反复迭代检查纠正自身的回答来获得一个经过反复检查的可靠回答。
但尽管如此,模型依然在某些问题上会出现错误地回答,不过纵使如此,文中发现,如下图所示,如果增加temperature然后让模型多次回答,模型还是有较大的可能性可以回答出正确答案的。

因此,文中提出了一个Exchange of Thought(EoT)的方法,具体思路上来说有点类似于ensemble方法,就是让模型进行多次独立回答,然后尝试从各个回答当中有效的挑选出最好的回答进行输出。
具体到实现上,让多个模型进行多次独立生成,然后将各自的输出结果进行整合拼接之后交给模型重新进行分析思考,然后生成各自去生成下一轮的回答,最终输出一个稳定且统一的回答。

上图就是EoT的一个整体的示意图,可以看到,相较于CoT的拆解式Reasoning,以及SC的迭代检查自己的answer,EoT主要还是让不同的模型独立回答,然后交流不同回答间的答案,不断整合之后回答出一个最终的同意结果。
通过这种方式,可以令多个模型在不断“讨论”之后给出一个更加“深思熟虑”的回答,从而提升模型的回答正确率。
下面,我们就来看一下文中给出的EoT方法的具体实现方式以及对应的实验效果。
2. 方法介绍
下面,我们来看一下EoT方法的具体实现。
如前所述,它的整体思路就是:
- 多个模型同时独立对问题进行回答;
- 各个模型一起对答案,将其他模型的回答也作为输入进行统一分析考察,然后重新回答问题;
- 重复2的步骤,直到各个模型给出一个统一且稳定的答案。
但是这里就会有几个问题需要回答:
- 模型之间如何进行通信和交流
- 迭代过程何时结束以及如何给出最终的回答
- 如何评价回答的置信度
下面,我们来逐一看一下文中对这几个问题的回答。
1. 交流范式
首先,我们来看一下文中给出的各个模型之间的交流范式。
文中一共给出了四种实现方式:
- Memory
- Report
- Relay
- Debate
其各自的方法说明可以参考下述示意图:

下面,我们来具体看一下这四种范式的具体实现细节。
1. Memory
首先,我们来看一下Memory的方式。
这种模型间的交流方式算是最为暴力和直接的方式了,就是让每个模型都看到其他所有模型的上一轮回答的答案,然后重新进行生成。
因此,要整合所有的回答反馈,只需要一轮沟通就行了,但是一轮沟通的成本将会是 n 2 n^2 n2,且每一个节点都需要整合全部 n n n个节点的回答。
2. Report
然后,关于第二种Report形式的实现方式,则是以一个节点作为核心节点,来整合其他所有节点的回答结果,因此一轮沟通的总的沟通成本就是 3 n − 2 3n-2 3n−2(即: n + 2 ( n − 1 ) n + 2(n-1) n+2(n−1))。
同样的,要统合所有的意见,只需要一轮沟通就行,但是核心节点的计算量就非常大,需要一个人整合全部 n n n个节点的回答。
3. Relay
第三种沟通的方式是Relay的方式,即循环沟通的方式,每一个节点只需要整合自己的回答与其下一个节点的回答即可,因此一轮沟通的沟通成本只需要 2 n 2n 2n即可,但是相对的信息的传输速度就会很慢,要让所有节点都见到过其他节点的回答,需要 n − 1 n-1 n−1轮沟通才行。
4. Debate
最后,文中给出的第四种沟通方式是Debate的方式,即小组讨论的方式。
具体来说的话就是先构造一个二叉树,然后每个叶子节点都只和自己的兄弟节点进行讨论,然后父节点则能够同时看到下述子节点的答案并于自己的答案进行整合。
此时,对于一棵完全二叉树,总的深度就是 h = ⌈ l o g 2 ( n + 1 ) ⌉ h = \lceil log_2(n+1) \rceil h=⌈log2(n+1)⌉,而总的沟通成本则是 7 ( n − 1 ) 2 \frac{7(n-1)}{2} 27(n−1)。
而要统合所有的意见,则需要 h − 1 h-1 h−1轮沟通。
2. 终止条件
关于EoT的迭代停止条件,文中给出了两种方法:
- 两次迭代之后模型的回答都不再发生变化了,那么就可以终止迭代了;
- 当大部分的模型回答的结果都一致了,那么也可以终止迭代了。
3. 置信度评估
最后,我们还可以对每一个模型的回答可靠度进行评估,文中给出的评估方法也比较简单:
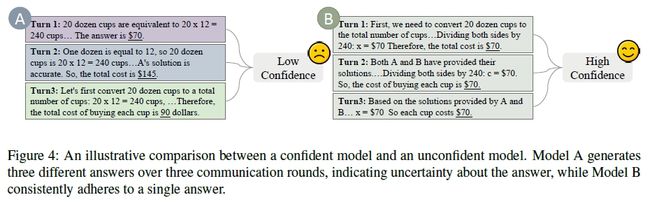
- 考察每一个模型在迭代过程中的所有回答结果,如果变化越频繁,说明他对答案的置信度就越低;反之,如果无论怎么讨论,它的答案都始终没有发生过改变,那么他的回答就有很高的置信度。
文中给出了一个形象化的图示说明如下:
3. 实验考察 & 结论
下面,我们就来看一下文中给出的EoT的具体实验以及其对应的结果。
1. 实验设计
文中主要是在以下三个任务当中进行的EoT效果考察:
- Mathematical Reasoning
- Commonsense Reasoning
- Symbolic Reasoning
而作为baseline的prompt则是以下几种方法:
- Chain-of-Thought (CoT)
- Complexity-based prompting (ComplexCoT)
- Self-Consistency (SC)
- Progressive Hint Prompting (PHP)
而模型方面,则是使用GPT-3.5(GPT-3.5-Turbo-0301)与GPT-4(GPT-4-0314)进行考察。
其中,EoT默认使用3个模型来进行实验。
2. 基础实验结果
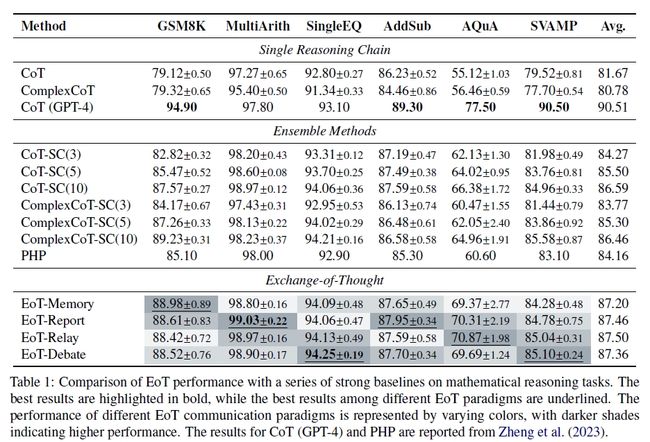
下面,我们首先给出在上述数据集上的基础实验效果如下:
-
Mathematical Reasoning
-
Commonsense & Symbolic Reasoning

可以看到:
- 整体来说EoT基本都可以达到SOTA的结果,效果是由于其他几种方法的。
3. 细节讨论 & 分析
下面,我们再来考察一下文中给出的关于EoT的一些细节讨论。
1. 不同communication范式的影响
首先,文中考察了一下不同的communication范式对生成效果的影响。
具体结果的话参考Mathematical Reasoning的结果即可,从上表中可以看到:
- 对于不同的任务,不同的范式得到的效果是不同的,各有优劣。
2. 不同终止条件的情况对回答效果的影响
其次,文中还考察了前面提到的两种终止条件下EoT的效果差异,得到结果如下:

可以看到:
- 多数一致作为终止条件的效果还是优于前后一致性作为终止条件时的效果的。
3. 置信度评估
然后,文中还考察了一下是否加入置信度条件来调整输出结果的选择对生成效果的影响,得到结果如下:

可以看到:
- 将置信度考虑到各个模型的输出结果当中时,能够有效地提升EoT的最终输出质量。
4. 迭代轮次分析
同样的,文中还考察了一下达到终止条件是所需要的轮次分布:

可以看到:
- 对所有的模式而言,一般5轮都足够模型达到统一的终止条件了;
- Relay的方式下降的斜率是最快的,而Debate方式达到统一所需的轮次最多;
- Report和Memory的方式更具备泛用性,可以使得所有的问题都在5轮以内达到终止条件,而剩下的两种都或多或少会有一些特殊情况需要很多轮。
5. 调用成本考察
此外,由于EoT需要重复多轮地调用模型,因此文中还考察了一下EoT的成本分析,得到结果如下:

可以看到:
- 相较于SC的方式,EoT增加的成本并没有那么多,却能过获得不属于SC的回答质量,是非常具有性价比的。
6. 不同大模型下的泛化性
另外,文中还考察了一下EoT方法在不同的LLM下的泛化性,得到结果如下:

可以看到:
- 在GPT3.5,GPT4以及Claude2上面,EoT均可以提升模型的输出质量;
- 当初始模型的效果越平庸,EoT的价值就越高(EoT对GPT3.5的提升效果明显比较高于GPT4上的EoT带来的增益)。
7. 不同节点模型的影响
最后,文中还考察了一下不同节点上使用不同模型时的效果变化,得到结果如下:

可以看到:
- 当三个节点使用不同的模型时,模型效果是最好的,说明外部信息引入时,最好使用不同类型的大模型,而且单一大模型的多次不同生成。
4. 总结 & 思考
综上,文中提出了一种名叫EoT的新型的类似系综方式的prompt优化方法,获得了很好的效果。
但是坦率地说,这个方式虽然好,但是感觉在实际的工作当中比较难应用,毕竟当前的共识就是prompt越写越长,尤其当你的输入context本来就很多的时候,这个问题就愈发被放大了,很难说是否还能够塞得下多个模型的输出结果进行多轮讨论。
更何况,现在的调用成本本就已经很夸张了,再多加几轮调用,带来的效果提升很难说能不能够cover住成本的提升。
不过另一方面,如果把这个方法和其他的prompt压缩的方法连用,比如之前读到的LLMLingua的方法(可参见我之前的拙作:文献阅读:LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models),或许能够有一些增益,不过个人感觉可能比较鸡肋。
Anyway,先备着吧,多知道一些总是好的,也许未来某一天能够用得上呢。