Python|30行代码实现微博热榜爬虫(及可视化进阶)
1. 项目简介
当你想要跟踪微博的热门话题时,通过编写一个Python爬虫,来获取微博热搜榜单上的实时数据,并将其可视化展示出来,通过邮件或QQ机器人将其推送,亦可以将其存档,用以保留不同时期的舆论热点。
此外,排行榜项目一向是学习Python爬虫时必备的练手项目,通过本项目,可以学习如何轻松制作仿微博热搜结果的图片、学习基础的代码能力以及相关的数据可视化,数据推送等多方面知识。
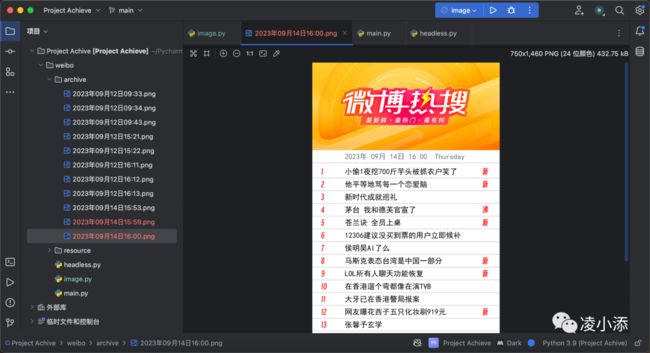
该项目主要思路:
-
寻找热搜榜数据接口(获取数据)
-
解析获取的数据提取热搜话题(格式化数据)
-
使用Pillow库创建一个图像,然后将话题绘制到图像上(数据展示)
此外,还有更多的进阶思路,在此处抛砖引玉:
-
使用selenium库无头浏览器进行截图,获取原生热榜截图
-
引入邮件库,定期向邮箱中推送爬取的结果
-
部署到服务器或设置定时任务,整理微博热搜库到Excel或其他存储结构
-
获取某一时间段的热搜并生成词云进行分析
-
使用nonebot库将其制作为QQ/社交软件机器人插件
2. 项目实现
2.1. 数据获取
在对一个网站或网页进行爬虫时,选择正确的方法往往能够事半功倍,因此观察网站结构和网站提供的各种API就非常重要,下面我们将举例对不同方法进行分析。
2.1.1. 直接从网页上抓取
顾名思义,该方法就是通过直接分析网页页面,抓取到网页内容。
例如在本例中,可以获取到热搜本页的html页面,获取其
- 元素
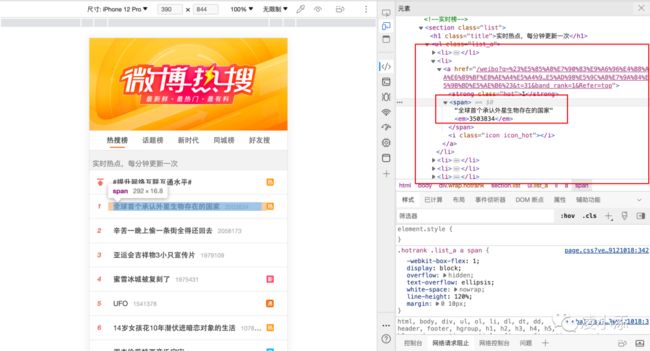
利用Xpath或者beautifulsoup对html页面进行解析,获取到数据后再格式化。
例如,使用xpath获取到html对象后,对其进行解析
import requests
from lxml import html
# 发送HTTP请求并获取页面内容
url = "https://s.weibo.com/top/summary?cate=realtimehot"
response = requests.get(url)
# 使用lxml解析页面内容
tree = html.fromstring(response.text)
# 使用XPath表达式提取指定元素的文本内容
xpath_expression = "/html/body/div/section/ul/li[2]/span/text()"
result = tree.xpath(xpath_expression)
这是一种通用的,直观的爬虫方式,但存在几个问题。
-
需要伪装请求头,特别是cookie,否则返回的页面为空
-
cookie一旦过期,需要重新获取,或者根据cookie内容的规律设置变量
-
获取内容时比较复杂
因此笔者一直强调在爬取页面时先要多观察,找到数据接口比直接爬取页面来说要方便的多。
2.1.2. 从数据接口抓取
微博开放平台提供了众多接口,微博热搜拥有自己的API接口,其url为:https://weibo.com/ajax/side/hotSearch

这个接口直接get后就会返回一个json文件。
这种方法无需设置请求头,无需设置cookie!十分方便快捷!
其文件结构如图:
第一个为置顶热搜,后面的列表为此时的热搜排行,包含标题、热度、标签等内容。

据此,我们就可以开始动手了,我们直接通过这个API请求到json文件结果,并作为函数返回
#引入requests库
import requests
# 获取json文件
def hot_search():
url = 'https://weibo.com/ajax/side/hotSearch'
response = requests.get(url)
if response.status_code != 200:
return None
return response.json()['data']
这样,我们就得到了微博热搜的数据文件。
2.2. 数据解析
2.2.1. 基础代码
json文件是非常好的数据载体,它可以作为字典格式进行数据的读取。
我们在得到数据源后,就可以开始着手进行解析。
我们写一个main()函数,并调用hot_search()函数获取数据源
def main(num):
data = hot_search()
if not data:
print('获取微博热搜榜失败')
return
print(f"置顶:{data['hotgov']['word'].strip('#')}")
for i, rs in enumerate(data['realtime'][:num], 1):
title = rs['word']
try:
label = rs['label_name']
if label in ['新','爆','沸']:
label = label
else:
label = ''
except:
label = ''
print(f"{i}. {title} {label}")
if __name__ == '__main__':
num = 20 #获取热搜的数量
main(num)
由于置顶热搜与普通热搜有所不同,我们先读取置顶热搜。
后面通过遍历即可获得每一条热搜的信息,其中变量num代表获取热搜的数量,可以传递参数控制。
运行后如图所示:

2.2.2. 拓展代码
可以看到,我们已经成功的实现了解析的功能,将热搜解析为文本,并选取了标题和热度标签两个主要内容。
当然,也可以提取"raw_hot" 键中对应的热度,即热搜榜中的搜索热度。
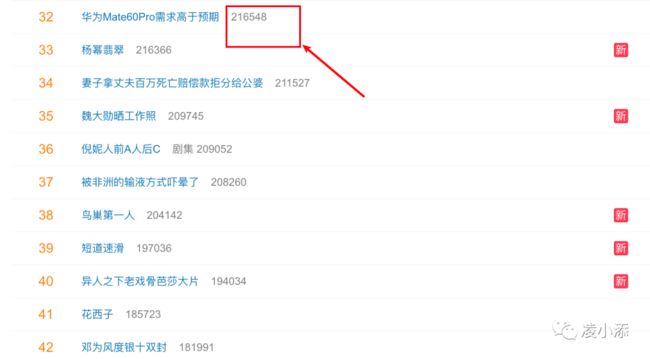
加上这个数据后,结果又缺少了什么,没错,是时间,微博热搜都是具有时效性的,所以我们应该为其加入时间显示。
from datetime import datetime
print(datetime.now().strftime('微博热搜榜 20%y年%m月%d日 %H:%M'))
加入上述代码后,运行结果如下:

但是依然缺少了些什么,例如我们对某个热搜感兴趣,想进一步浏览相关信息,那么就需要链接。
为此,我们首先应该观察在热搜榜点击后的链接结构。
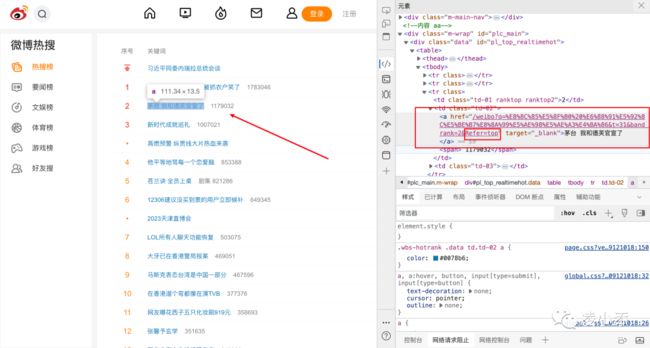
点击链接后url为:https://s.weibo.com/weibo?q=%E8%8C%85%E5%8F%B0%20%E6%88%91%E5%92%8C%E5%BE%B7%E8%8A%99%E5%AE%98%E5%AE%A3%E4%BA%86&t=31&band_rank=2&Refer=top
不难发现,其url组合为:https://s.weibo.com/weibo?q=+热搜标题+&Refer=top等后缀
由于url并不能为中文,因此在链接中会呈现为类似8%8C%85%E这样的编码。
如果我们要实现对url的组合,首先应该对中文字符串进行转码。
为此需要引入urllib库,对中文转码,代码如下。
from urllib.parse import quote
link = (f"链接:https://s.weibo.com/weibo?q={quote(title)}&Refer=top")
print(f"{i}. {title} {label} ")
运行后结果如图:
我们随意点击链接进行测试,发现可以正常进行搜索。

一点思路…
此外,还可以将爬取到的结果保存到Excel表格中,并设置定期任务,形成一个月的热搜表格
可以对其进行进行词频分析,生成词云等可视化分析。
3. 进阶操作
3.1. pillow绘图
在上面的基础代码中,我们已经实现了获取微博热搜的文字信息,如果我们想要更直观的,更友好的展示界面,就需要对其进行可视化,在本例中我们将其生成为如下的图片来进行展示。

由于我们绘图的基础是本文前一部分的代码内容,我们只需要新增一个函数来实现绘图功能,并不影响基础代码。
这也是程序中非常重要的模块化思想,同样的还有面向对象中的封装,都是为了便于后期对功能的增加和更改。
下面是基础代码部分,我们只去掉了部分输出,并为函数增加了返回值。
import requests
from datetime import datetime
def hot_search():
url = 'https://weibo.com/ajax/side/hotSearch'
response = requests.get(url)
if response.status_code != 200:
return None
return response.json()['data']
def decoding(num):
data = hot_search()
if not data:
print('获取微博热搜榜失败')
return
top = (f"置顶:{data['hotgov']['word'].strip('#')}")
hot_li = []
hot_label = []
for i, rs in enumerate(data['realtime'][:num], 1):
title = rs['word']
try:
label = rs['label_name']
if label in ['新','爆','沸']:
label = label
else:
label = ''
except:
label = ''
# hot_li.append(f"{i}. {title} {label}")
hot_li.append(f"{title}")
hot_label.append(f"{label}")
return hot_li,hot_label
接下来就是我们的主程序,对结果进行绘图
首先我们需要引入PIL库进行绘图。
from PIL import Image, ImageDraw, ImageFont
PIL绘图的原理先创建一个指定的画板,然后通过对坐标轴X和Y轴的调整实现内容的布局。
我们的思路是首先创建一个与微博热搜图片等宽的白色幕布,然后为每行内容分配50像素的高度,根据获取的热搜数量计算出幕布的高度。
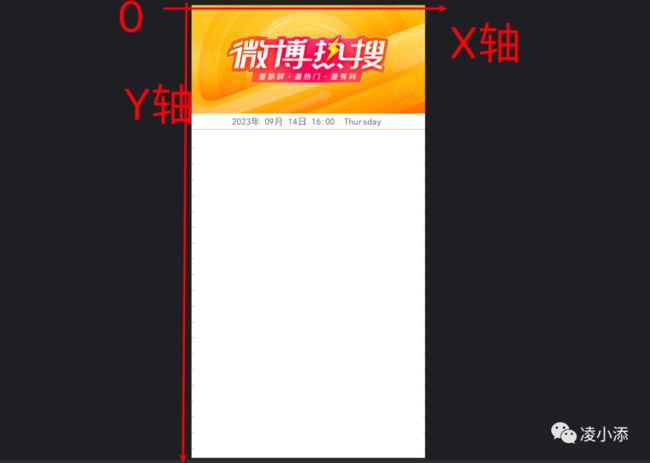
我们写出此部分的代码
def img():
# 创建图像,设置高度和宽度
width= 750
height = 350+ 70 + len(li)*52
background = Image.new('RGB', (width, height), color=(255, 255, 255))
# 添加热搜图片,替代顶部像素的背景
background_image = Image.open('resource/hot_research.jpg') # 替换为你的背景图片
background.paste(background_image, (0, 0))#
接下来我们需要将文字绘制到图片上,这部分的难点主要是文字布局。
在对文字布局调整前,我们首先应该对字体进行配置,否则无法绘制。
line_height = 50 # 每行文字高度
num_lines = len(li) # 总行数
font_size = 30 # 字体大小
text_color = (0, 0, 0) # 文本颜色
background_color = (255, 255, 255) # 背景颜色
separator_color = (200, 200, 200) # 分隔符颜色
separator_height = 1 # 分隔符高度
image_height = num_lines * line_height # 图像高度
# 字体配置
draw = ImageDraw.Draw(background)
font = ImageFont.truetype("resource/heiti.ttf", font_size)
num_font = ImageFont.truetype("resource/SmileySans.ttf", font_size)
配置字体文件时需要提前将对应的字体ttf或者ttc文件放置于资源文件中,我选择黑体作为热搜标题字体,得意黑为编号与标签的字体,并对颜色和字体进行配置。
在配置完成后,我们即可进行绘制!
如果你有前端经验,接触过CSS,可以结合绝对定位来理解。
我们首先绘制第一行的时间信息,用time库获取当前时间,并绘制分隔符
time = datetime.now().strftime('20%y年 %m月 %d日 %H:%M %A')
time_name = datetime.now().strftime('20%y年%m月%d日%H:%M')
draw.text((130, 360), str(time), fill=(101, 109, 118), font=font,font_size=24)
draw.rectangle([(0, 400), (width, 400+ separator_height)], fill=separator_color)

这块的重点就是对x轴和y轴数值的计算,这里的计算可以多调整尝试,或者精确的在画板中计算后填入。
文本的绘制就是循环遍历,每绘制一行后,y轴高度增加52。
# 逐行绘制文本和分隔符
y = 420
i = 1
for line in lines:
# 绘制编号
draw.text((35,y-3),str(i), fill=(255,0,0),font=num_font)
# 绘制文本
draw.text((130, y),line, fill=text_color, font=font)
# 绘制热度
draw.text((680, y-3), label[i-1], fill=(255,0,0), font=num_font)
y += line_height
i +=1
# 绘制分隔符
draw.rectangle([(0, y-10), (width, y-10 + separator_height)], fill=separator_color)
y += separator_height
# 保存图像
try :
background.save(f"archive/{time_name}.png")
print("保存成功!")
except:
print("保存失败!!!")
每一行的编号和文本只需要调整x轴的位置,就可以调整左右方向的位置,例如将编号固定在左侧35像素的位置,标题文本从135像素开始,是不是有种熟悉的感觉?就是CSS中left:130px的效果,或者padding-left:35px。
以下是绘图的完整代码:
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
'''
@Project :Project Achive
@File :image.py
@IDE :PyCharm
@Author :lingxiaotian
@Date :2023/9/5 15:54
'''
import requests
from datetime import datetime
from PIL import Image, ImageDraw, ImageFont
def hot_search():
url = 'https://weibo.com/ajax/side/hotSearch'
response = requests.get(url)
if response.status_code != 200:
return None
return response.json()['data']
def decoding(num):
data = hot_search()
if not data:
print('获取微博热搜榜失败')
return
top = (f"置顶:{data['hotgov']['word'].strip('#')}")
hot_li = []
hot_label = []
for i, rs in enumerate(data['realtime'][:num], 1):
title = rs['word']
try:
label = rs['label_name']
if label in ['新','爆','沸']:
label = label
else:
label = ''
except:
label = ''
# hot_li.append(f"{i}. {title} {label}")
hot_li.append(f"{title}")
hot_label.append(f"{label}")
return hot_li,hot_label
def img(li,label):
# 创建图像
width= 750
height = 350+ 70 + len(li)*52
background = Image.new('RGB', (width, height), color=(255, 255, 255))
# 添加背景图片(如果需要替代顶部像素的背景)
background_image = Image.open('resource/hot_research.jpg') # 替换为你的背景图片
background.paste(background_image, (0, 0))
line_height = 50 # 每行文字高度
num_lines = len(li) # 总行数
font_size = 30 # 字体大小
text_color = (0, 0, 0) # 文本颜色
background_color = (255, 255, 255) # 背景颜色
separator_color = (200, 200, 200) # 分隔符颜色
separator_height = 1 # 分隔符高度
image_height = num_lines * line_height # 图像高度
# 字体配置
draw = ImageDraw.Draw(background)
font = ImageFont.truetype("resource/heiti.ttf", font_size)
num_font = ImageFont.truetype("resource/SmileySans.ttf", font_size)
# 生成文本列表
lines = li
# 获取当前时间
time = datetime.now().strftime('20%y年 %m月 %d日 %H:%M %A')
time_name = datetime.now().strftime('20%y年%m月%d日%H:%M')
draw.text((130, 360), str(time), fill=(101, 109, 118), font=font,font_size=24)
draw.rectangle([(0, 400), (width, 400+ separator_height)], fill=separator_color)
# 逐行绘制文本和分隔符
y = 420
i = 1
for line in lines:
# 绘制编号
draw.text((35,y-3),str(i), fill=(255,0,0),font=num_font)
# 绘制文本
draw.text((130, y),line, fill=text_color, font=font)
# 绘制热度
draw.text((680, y-3), label[i-1], fill=(255,0,0), font=num_font)
y += line_height
i +=1
# 绘制分隔符
draw.rectangle([(0, y-10), (width, y-10 + separator_height)], fill=separator_color)
y += separator_height
# 保存图像
try :
background.save(f"archive/{time_name}.png")
print("保存成功!")
except:
print("保存失败!!!")
if __name__ == "__main__":
num = 20 #获取热搜数
hot_li = decoding(num)[0]
hot_label = decoding(num)[1]
img(hot_li,hot_label)
3.2. selenium无头浏览器截图
相比于直接绘图,直接截图无疑是一种更加简单快捷的方法,而且能够实现原生的微博热搜的效果,操作也十分简单,那么手动截图的话我们固然会,但如何使用selenium进行截图就是本项目中的重点。
什么是selenium?
selenium是Pyhton爬虫中非常重要的一种方式,由于selenium是使用真实的浏览器来进行访问,因此可以绕过很多反爬措施,其次,selenium可以控制浏览器对网页内容进行点击,滚动,输入等多种操作,例如输入账号密码和验证码并登录,滚动屏幕获取ajax内容。
下面是一个直观的演示:
而selenium有两种运行模式,刚刚我们演示的是第一种模式,即展示浏览器界面的模式,我们可以看到浏览器的打开界面以及对网页的操作。
而无头浏览器顾名思义,即不弹出浏览器窗口,直接在后台进行操作。
那我们直接上手!
首先依然是配置相关设置,selenium是基于浏览器操作,因此首先需要保证电脑具有chromedrive
可以从官网下载与自己谷歌浏览器对应的版本 https://chromedriver.storage.googleapis.com/index.html

具体的配置教程不是本文讨论的重点,可以从互联网上参考相关教程,本文主要强调代码思想。
由于微博热搜的移动端界面的表现效果更好,因此我们需要模拟浏览器的UA和分辨率,模拟手机操作,并设置窗口大小,由此方可进入移动端界面,否则为PC端。
import time
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# 配置浏览器选项
opts = Options()
mobile_emulation = {"deviceMetrics": {"width": 375, "height": 667, "pixelRatio": 2.0},"userAgent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1 Edg/116.0.0.0"}
opts.add_experimental_option("mobileEmulation", mobile_emulation)
# opts.add_argument('--headless') # 启用无头模式
# 创建浏览器
driver = webdriver.Chrome(options=opts)
driver.set_window_size(375, 750) # 窗口大小
name = datetime.now().strftime('20%y年%m月%d日%H:%M')
设置好后我们直接访问热搜榜url,并进行截图即可完成。
注意:由于打开网页后需要一定时间才会完全显示界面,因此设置了10秒钟的休眠,可以根据自己设备和网络情况具体调整时间。
# 导航到要截图的页面
url = 'https://s.weibo.com/top/summary?cate=realtimehot'
driver.get(url)
# 截取整个页面
print("正在运行,请稍后……")
#
time.sleep(10)
screenshot = driver.get_screenshot_as_file(f'screenshot/{name}.png')
# 关闭浏览器
driver.quit()
print("运行完毕,请于文件夹中查看")
当然,直接截图的话不会完整,可以通过滚动窗口,截屏后将所有图片拼接,获取长截图。
要启动无头模式,可以直接在配置中加入opts.add_argument('--headless') 即可。
4. 总结
在本项目中,我们探讨了如何使用30行不到的代码创建一个微博热搜爬虫,意图强调的是爬虫方式的选择的重要性,并提出了一些拓展思路。
同样的使用selenium无头模式也可以通过不到30行代码实现对热榜的爬取,但仅有图片信息,难以对数据进行固化和分析,所以说不同的爬虫方式有不同的特点,而选择适合需求的方法至关重要。
感兴趣的小伙伴,完整代码和全套Python学习资料免费赠送,包含面试题、简历资料等具体看下方。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

六、面试宝典


简历模板
若有侵权,请联系删除