线段树基础(上)
普通线段树
线段树原理
(证明)
线段树是一种维护序列操作的二叉树数据结构。
线段树存在以下五个操作:
build:创建一颗线段树push_up:根据子节点计算父节点的信息push_down:根据父节点的修改标记去更新子节点的信息(用于区间修改)push:修改(分为单点修改和区间修改)find:查询
可以证明,线段树是一颗Leafy tree,也就是说,它的非叶子点一定有左右儿子。
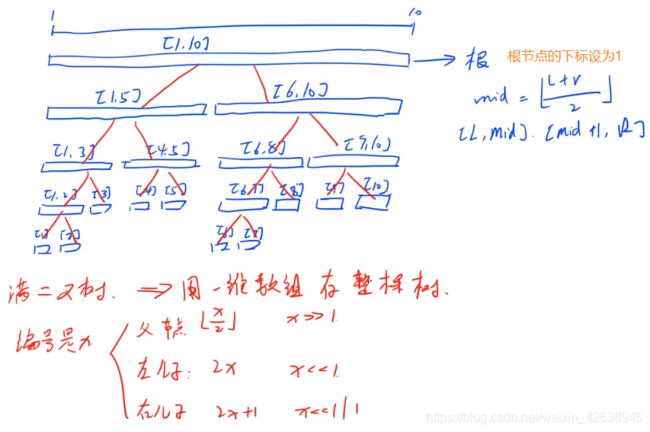
线段树的节点对应着序列上的一段区间。对于一段长度为 n n n的区间,根节点对应着 [ 1 , n ] [1,n] [1,n],对于一个对应区间为 [ l , r ] [l,r] [l,r]的节点,令 m i d = ⌊ l + r 2 ⌋ mid=\left\lfloor\frac{l+r}2\right\rfloor mid=⌊2l+r⌋,则它的左儿子对应的区间为 [ l , m i d ] [l,mid] [l,mid],右儿子对应的区间为 [ m i d + 1 , r ] [mid+1,r] [mid+1,r]。
普通线段树一个节点用一个结构体表示:
struct node{
int l,r;节点对应的区间范围
int info;节点存储的某些信息
};
通常我们把一颗线段树用堆式存储在数组里。即根节点编号为 1 1 1,编号为 u u u的节点左儿子为 2 ⋅ u 2\cdot u 2⋅u,右儿子为 2 ⋅ u + 1 2\cdot u+1 2⋅u+1。相应的, u u u节点的父亲编号为 ⌊ u 2 ⌋ \left\lfloor\frac u2\right\rfloor ⌊2u⌋。
对于对应区间为 [ 1 , N ] [1,N] [1,N]的一颗线段树,可以证明,它用到的空间可以存储在大小为 4 N 4N 4N的数组以内。
因此我们通常这样定义一颗线段树:
const int N=1e5;
struct node{
int l,r;
int info;//...
}t[N<<2];
习惯上线段树对应的区间是从 1 1 1开始编号的,例如 [ 1 , n ] [1,n] [1,n]。但其实线段树也可以维护从 0 0 0开始编号的区间。但是如果区间从负数开始编号,则需要对线段树的实现进行特殊处理,或者增加一个偏移量。(这是由于c++默认的int取整方式不是向下取整,而是向零取整)
需要尤其注意的是,对应的区间为 [ 0 , n ] [0,n] [0,n]的一颗线段树,事实上对应的区间长度为 n + 1 n+1 n+1,因此空间需要开到 4 ( n + 1 ) 4(n+1) 4(n+1),而不是 4 n 4n 4n。
可以证明,线段树大概有 O ( log 2 n ) O(\log_2n) O(log2n)层。
P3374
线段树维护单点加区间求和。
我们要实现快速进行区间求和,因此线段树节点还要额外维护区间和(sum)。
const int N=5e5;
struct node{
int l,r;
int sum;
}t[N<<2];
建树(build)
然后我们通过build创建一颗线段树。(默认线段树维护一个全 0 0 0序列)
build(u,l,r)递归到节点 u u u,设置这个节点的对应的区间为 [ l , r ] [l,r] [l,r],然后递归到它的左右儿子。
void build(int u,int l,int r) {
t[u]={l,r,0};
if(l==r) return ;
int mid=l+r>>1;
build(u<<1,l,mid);
build(u<<1|1,mid+1,r);
}
每个节点只被创建一次,因此build的复杂度是 O ( n log n ) O(n\log n) O(nlogn)
上传标记(push_up)
push_up(u)表示 u u u为父亲,现在用 u u u的左右儿子的信息来合并 u u u的信息。
我们约定调用push_up(u)的前提是, u u u必须要有左右儿子。
在这个题目里面,我们维护的是区间和。
void push_up(int u) {
t[u].sum=t[u<<1].sum+t[u<<1|1].sum;
}
单点修改(push)
想要在线段树上做单点修改,我们需要根节点一直递归下去到对应为止的节点,并更新递归路径上所有节点的信息。
push(u,pos,val),表示目前在编号为 u u u的节点,修改操作为,给 p o s pos pos位置的值增加 v a l val val。
我们从根节点出发开始递归,我们递归进入编号为 u u u的节点,前提是 p o s ∈ [ l u , r u ] pos\in[l_u,r_u] pos∈[lu,ru]。
单点修改的push函数具体是这样运作的:
- 若 u u u为叶子,因为 p o s ∈ [ l u , r u ] pos\in[l_u,r_u] pos∈[lu,ru]才会递归下来,说明 p o s = l u = r u pos=l_u=r_u pos=lu=ru,进行修改
- 若 u u u不是叶子,要递归到 p o s pos pos对应方向的儿子,然后
push_up(u),更新 u u u节点的信息
这里能够push_up(u),是因为 u u u有儿子,说明 u u u不是叶子。
void push(int u,int p,int val) {
if(t[u].l==t[u].r&&t[u].r==p) t[u].sum+=val;
else {
int mid=t[u].l+t[u].r>>1;
if(p<=mid) push(u<<1,p,val);
if(mid<p) push(u<<1|1,p,val);
第二个if(mid<p)可以改为else,但是由于区间修改不能这么写,习惯上不这么写。
push_up(u);
}
}
这样我们的递归路线最终形成了线段树上一条从根节点到叶子节点的路径:

单点修改的复杂度与树高有关,因此复杂度为 O ( log n ) O(\log n) O(logn)
查询(find)
查询操作find(u,l,r)表示目前递归到了节点 u u u,要查询区间 [ l , r ] [l,r] [l,r]的和。
能够递归到节点 u u u,前提是 u u u与 [ l , r ] [l,r] [l,r]有交。
find函数具体是这样运作的:
- 如果节点 u u u包含于 [ l , r ] [l,r] [l,r],则返回 s u m u sum_u sumu
- 否则:令 m i d = ⌊ l + r 2 ⌋ mid=\left\lfloor\frac{l+r}2\right\rfloor mid=⌊2l+r⌋
- 若 l ≤ m i d l\leq mid l≤mid,说明区间与左儿子有交,递归到左儿子
之所以 l ≤ m i d l\leq mid l≤mid就说明区间与左儿子有交,是因为保证了 [ l , r ] [l,r] [l,r]与 u u u有交,右儿子同理。 - 若 m i d < r mid
mid<r ,说明区间与右儿子有交,递归到右儿子
int find(int u,int l,int r) {
if(l<=t[u].l&&t[u].r<=r) return t[u].sum;包含就返回
int mid=t[u].l+t[u].r>>1;不包含就递归到左右儿子
int ans=0;
if(l<=mid) ans+=find(u<<1,l,r);
if(mid<r) ans+=find(u<<1|1,l,r);
注意这里不是else,即使访问了左儿子,右儿子可能需要递归
return ans;
}
这样我们发现,一次区间查询事实上访问了线段树上 O ( log n ) O(\log n) O(logn)个节点,例如我们要查询区间 [ 2 , 8 ] [2,8] [2,8],具体来说是这样的:
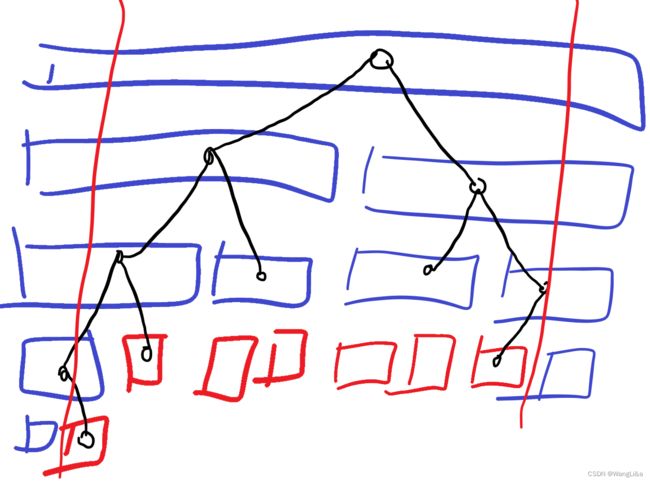
其中黑色节点表示访问到的节点,红色的叶子节点表示实际要查询的区间。
现在我们来分析一下查询操作的时间复杂度。
对于所有与 [ l , r ] [l,r] [l,r]有交的节点,显然它们一定是连通的,因为与 [ l , r ] [l,r] [l,r]有交的一个节点的父亲也与 [ l , r ] [l,r] [l,r]有交,而它们最终都会与根节点连通。
所以他们会形成一个线段树的一个导出连通图,这个图是一颗树。
显然所有可能被访问的节点都位与这棵树上,接下来我们具体分析一下哪些节点会被访问:
- 第一类节点:对于不被 [ l , r ] [l,r] [l,r]完全包含的节点来说,这样的节点每层最多有 2 2 2个,一个与 l l l相交,另一个与 r r r相交。因此这样的节点至多有约 O ( 2 log n ) O(2\log n) O(2logn)个。我们认为它们全部被访问(事实也是如此)
因为如果同一层有多余两个的节点与 l l l或 r r r相交,则必然有两个节点相交,但同一层节点显然无交。因此一层之中这样的节点最多两个。 - 第二类节点:对于被 [ l , r ] [l,r] [l,r]完全包含的节点来说, u u u被访问到的充要条件是, u u u的父亲不被 [ l , r ] [l,r] [l,r]完全包含。也就是说它必须是第一类节点的儿子,显然得到它的数量上界为 O ( 4 log n ) O(4\log n) O(4logn)。
但是注意到一个第一类节点至多有一个第二类儿子,否则它自身就是第二类节点,显然所以第二类被访问节点的数量至多有 O ( 2 log n ) O(2\log n) O(2logn)个。
线段树的重要思想就是,把一次区间操作对应为线段树上 O ( log n ) O(\log n) O(logn)个节点。
因此每次查询大约访问 O ( 4 log n ) O(4\log n) O(4logn)个线段树节点,时间复杂度为 O ( log n ) O(\log n) O(logn)。
实现
剩余的就是主函数部分,没什么好说的。
#include例题2
本题是线段树维护区间修改的模板题。
题目要求维护区间加,区间求和。
我们需要使用push_down操作完成区间修改操作,也称为懒标记(延迟标记)。
具体我们需要在每个线段树节点上维护一个加法懒标记(add):
struct node{
int l,r;
long long sum,add;
}t[N<<2];
add标记表示 u u u的儿子需要完成区间加 a d d add add的操作
( u u u已经完成这个操作,也就是说 s u m u sum_u sumu已经计算了 a d d add add操作的影响。)
如果 u u u没有儿子,那add标记没有意义。
下放标记(push_down)
具体来说,push_down(u)将 u u u的懒标记下放给 u u u的两个儿子。所以调用这个函数表示 u u u有左右儿子。
void push_down(int u) {
int l=u<<1,r=u<<1|1;
下放懒标记:
t[l].add+=t[u].add;
t[r].add+=t[u].add;
处理懒标记对区间和标记的影响:
t[l].sum+=t[u].add*(t[l].r-t[l].l+1);
t[r].sum+=t[u].add*(t[r].r-t[r].l+1);
清空u的懒标记:
t[u].add=0;
}
在push,find访问到 u u u时,如果要访问 u u u的儿子,就必须先下放懒标记。
void push(int u,int l,int r,long long val) {
if(l<=t[u].l&&t[u].r<=r) t[u].sum+=val*(t[u].r-t[u].l+1),t[u].add+=val;
else {
push_down(u);下放懒标记
int mid=t[u].l+t[u].r>>1;
if(l<=mid) push(u<<1,l,r,val);
if(mid<r) push(u<<1|1,l,r,val);
push_up(u);上传标记
}
}
long long find(int u,int l,int r) {
if(l<=t[u].l&&t[u].r<=r) return t[u].sum;
push_down(u);下放懒标记
int mid=t[u].l+t[u].r>>1;
long long ans=0;
if(l<=mid) ans+=find(u<<1,l,r);
if(mid<r) ans+=find(u<<1|1,l,r);
find函数可以不需要push_up,因为push的时候push_up的作用是计算当前push操作对儿子的作用。
这个作用没有在父亲处计算。(有时也无法在父亲处计算)
而find函数对子节点唯一的影响是,可能会下放懒标记,但push_down的影响在之前计算过了。
return ans;
}
实现
#include例题3
本题要求同时维护区间加乘,区间求和。因此需要维护比较复杂的懒标记。
我们需要维护三个标记,分别是区间和标记(sum)、区间加标记(add)、区间乘标记(mul)
如何维护加乘标记的合并呢?假设我们把对一个节点的操作写出来,它可能是则这样的:
+ x , + y , × z , × w , + p , × q +x,+y,\times z,\times w,+p,\times q +x,+y,×z,×w,+p,×q
假设这个节点的区间和为 s u m sum sum,则它依次变为:
s u m + x sum+x sum+x
s u m + x + y sum+x+y sum+x+y
( s u m + x + y ) × z (sum+x+y)\times z (sum+x+y)×z
( s u m + x + y ) × z × w (sum+x+y)\times z\times w (sum+x+y)×z×w
( s u m + x + y ) × z × w + p (sum+x+y)\times z\times w+p (sum+x+y)×z×w+p
( ( s u m + x + y ) × z × w + p ) × q ((sum+x+y)\times z\times w+p)\times q ((sum+x+y)×z×w+p)×q
首先我们知道可以把同类操作合并起来。那操作序列就变成了一个加乘交错序列。
如何把加乘交错的变化维护在一个节点上呢。
有一种观察是:
s u m × m u l + a d d = s u m × m u l + a d d sum\times mul+add=sum\times mul+add sum×mul+add=sum×mul+add
( s u m + a d d ) × m u l = s u m × m u m + a d d × m u l (sum+add)\times mul=sum\times mum+add\times mul (sum+add)×mul=sum×mum+add×mul
这说明先乘后加的话,对乘法标记没有影响。先加后乘,则加法标记可以分配出来。
因此我们维护一个 k ⋅ x + b k\cdot x+b k⋅x+b的形式,表示懒标记将对它的儿子先乘后加的做修改。
这时候懒标记的作用是有先后顺序的。
(这时候就会有人会问了,能不能维护先加后乘呢?)
其实是不行的,如果维护 k ( x + b ) k(x+b) k(x+b)的懒标记修改形式的话,那对于先乘后加的修改序列维护起来是方便了,但是如果要维护先乘后加的话,会发生什么呢?
x → k ⋅ x → k ⋅ x + b = k ( x + b k ) x\rightarrow k\cdot x\rightarrow k\cdot x+b=k\left(x+\frac bk\right) x→k⋅x→k⋅x+b=k(x+kb),出现了分数,这是不好的。
我们具体这样维护标记:
struct node{
int l,r;
long long sum,add,mul;
}t[N<<2];
乘法修改(set_mul)
如果要对节点进行一次乘法,懒标记的改动用set_mul函数实现:
( m u l u × s u m u + a d d u ) × m u l = ( m u l u × m u l ) × s u m + ( a d d u × m u l ) (mul_u\times sum_u+add_u)\times mul=(mul_u\times mul)\times sum+(add_u\times mul) (mulu×sumu+addu)×mul=(mulu×mul)×sum+(addu×mul)
m u l u ← m u l u × m u l mul_u\leftarrow mul_u\times mul mulu←mulu×mul
a d d u ← a d d u × m u l add_u\leftarrow add_u\times mul addu←addu×mul
void set_mul(int u,long long mul) {
(t[u].add*=mul)%=M;
(t[u].mul*=mul)%=M;
(t[u].sum*=mul)%=M;
}
加法修改(set_add)
如果要对节点进行一次加法,懒标记的改动用set_add函数实现:
void set_add(int u,long long add) {
(t[u].add+=add)%=M;
(t[u].sum+=add*(t[u].r-t[u].l+1))%=M;注意加法操作对于sum的影响要乘以区间长度
}
下放标记(push_down)
标记下放相当于对子节点进行修改,注意先乘后加。
void push_down(int u) {
set_mul(u<<1,t[u].mul);
set_mul(u<<1|1,t[u].mul);
set_add(u<<1,t[u].add);
set_add(u<<1|1,t[u].add);
t[u].mul=1;
t[u].add=0;
}
这样的话,修改也有两个版本,一个是区间加,一个是区间乘法:
void pushadd(int u,int l,int r,long long add) {
if(l<=t[u].l&&t[u].r<=r) set_add(u,add);
else {
push_down(u);
int mid=t[u].l+t[u].r>>1;
if(l<=mid) pushadd(u<<1,l,r,add);
if(mid<r) pushadd(u<<1|1,l,r,add);
push_up(u);
}
}
void pushmul(int u,int l,int r,long long mul) {
if(l<=t[u].l&&t[u].r<=r) set_mul(u,mul);
else {
push_down(u);
int mid=t[u].l+t[u].r>>1;
if(l<=mid) pushmul(u<<1,l,r,mul);
if(mid<r) pushmul(u<<1|1,l,r,mul);
push_up(u);
}
}
实现
#include其他题目
P1198
P4588
P1471
权值线段树
通常的线段树是区间树,每个节点对应一段区间。
权值树维护的是值域。
权值线段树即值域线段树,每个节点对应一段值域连续段的信息。
可以认为,权值线段树是维护桶数组的区间线段树。
维护负数值域需要加上偏移,除此之外,写法上来说没有区别。
动态开点线段树
通常的线段树是堆式存储的,这样需要开辟 4 N 4N 4N的空间。事实上宽度为 N N N的线段树至多有 2 N − 1 2N-1 2N−1个节点,只需要开辟 2 N 2N 2N的空间。
更进一步来说,假设对于宽度为 T T T的线段树进行 m m m次修改操作,那么最多访问到其中的 O ( m log T ) O(m\log T) O(mlogT)个节点,因此空间只需要开到 O ( m log T ) O(m\log T) O(mlogT)即可。在 T T T很大的时候(例如权值线段树)往往很有帮助。
动态开点权值线段树在空间计算上要尤其注意,防止空间超限。并且要注意 n , m , T n,m,T n,m,T很可能不相等,即使在 log 2 \log_2 log2中计算,也尽量不要混用。
还要注意,单点修改和区间修改会创建的节点数是不同的,对于宽度为 T T T而言,单点修改会创建 ⌈ log 2 T ⌉ \lceil\log_2T\rceil ⌈log2T⌉个节点,而区间修改会创建 4 ⌈ log 2 T ⌉ 4\lceil\log_2T\rceil 4⌈log2T⌉个节点。
例题1
如果我们枚举顺序 i i i,则以 i i i为结尾的逆序对数量为, i i i之前的数中比 a i a_i ai大的数的数量。
那么我们考虑这样一个算法:
- 维护一个桶 b b b
- 顺序枚举 i i i
- 以 i i i为结尾的逆序对数量为:桶中比 a i a_i ai大的数的数量 = ∑ j > a i b j =\underset{j>a_i}\sum b_j =j>ai∑bj
- 把 a i a_i ai加入桶: b a i + + b_{a_i}++ bai++
问题在于桶非常大,不能直接开下。所以可以使用动态开点权值线段树。
首先我们来计算一下空间。这个题值域为 1 0 9 10^9 109,由于我们只有单点修改操作,因此一次操作是从根节点到叶子的一条链,至多会创建 ⌈ log 2 T ⌉ = 30 \lceil\log_2T\rceil=30 ⌈log2T⌉=30个节点,共有 N = m = 5 × 1 0 5 N=m=5\times 10^5 N=m=5×105次修改操作,所以需要的空间为 30 N 30N 30N
我们这样定义节点:
const int N=5e5;
struct node{
int l,r,lc,rc;
int sum;
}t[N*30];
其中lc表示左儿子编号,rc表示右儿子编号。因为没有再使用堆式存储,而是动态开点了。如果等于 0 0 0就表示没有。
除此以外,我们为了方便再定义两个函数lc(u),rc(u),用于获得 u u u的左右儿子,如果不存在,就创建一个,因此这两个函数不能用于判断左右儿子是否存在。
int tot;
int&lc(int u) {
if(t[u].lc) return t[u].lc;
t[++tot]={t[u].l,t[u].l+t[u].r>>1};
return t[u].lc=tot;
}
int&rc(int u) {
if(t[u].rc) return t[u].rc;
t[++tot]={(t[u].l+t[u].r>>1)+1,t[u].r};
return t[u].rc=tot;
}
动态开点线段树一般是不需要build函数的,其建树代码只需要创建根节点即可:
t[++tot]={1,int(1e9)};
根节点编号为 1 1 1。
其push_up,push和find函数也有对应的改变,具体看实现。
#include
t[++tot]={1,int(1e9)};
int n;
cin>>n;
for(int i=1;i<=n;i++) cin>>a[i];
long long ans=0;
for(int i=1;i<=n;i++) {
if(a[i]!=1e9)
注意我们的find函数不接受l>r的参数,因此需要特判a[i]=1e9,或者建树的时候开大
当然不加这个判断也跑过去了。(数据真水)
ans+=find(1,a[i]+1,int(1e9));
push(1,a[i],a[i],1);
}
cout<<ans;
}
标记永久化
通常的区间修改标记,通过在访问该节点时下放懒标记更新儿子节点来实现。永久标记没有下放懒标记的操作,它通过在递归查询计算出对儿子节点的影响来实现区间修改的效果。
并不是所有标记都可以永久化。
例题1
区间加法标记(add)可以永久化。永久加法标记add表示节点 u u u对应的区间 [ l , r ] [l,r] [l,r]在这个节点上被增加了 a d d add add
标记永久化后,各个函数的实现略有不同。
建树(build),修改(push)的实现完全相同。
下放标记(push_up)
由于儿子节点的 s u m sum sum不再是它们真实值,而是它们去除了被祖先节点永久化后的加法标记造成的影响之后的值,因此在push_up的时候要把本层的加法标记算上。
我们维护sum为考虑子树内全部标记的区间和。
void push_up(int u) {
t[u].sum=t[u<<1].sum+t[u<<1|1].sum+t[u].add*(t[u].r-t[u].l+1);
}
查询(find)
查询要注意,在查询时计算本层永久标记对答案的影响。
long long find(int u,int l,int r) {
if(l<=t[u].l&&t[u].r<=r) return t[u].sum;
int mid=t[u].l+t[u].r>>1;
long long ans=0;
if(l<=mid) ans+=find(u<<1,l,r);
if(mid<r) ans+=find(u<<1|1,l,r);
return ans+t[u].add*(min(t[u].r,r)-max(t[u].l,l)+1);
这里加上了t[u].add*(u对应的区间与[l,r]相交的大小),计算了永久标记对答案的影响。
}
实现
值得一提的是,这里使用long long是不严谨的,因为题设并没有保证这种做法不会爆long long。但是它过了。
#include常见可永久化标记
标记永久化局限非常大,一般只在不得不使用或使用大幅减少码量时使用。
常见有以下标记单独出现时可以永久化:
- 区间加标记
- 区间乘标记
区间加乘标记不可永久化 - 扫描线段树标记(线段覆盖标记)
- 李超线段树标记
- 可持久化线段树标记必须永久化
后记
下篇