第三章在多张表格中检索数据
第三章:在多张表格中检索数据
内容来自:
1、b站mosh老师的SQL课程(第三章) 【中字】SQL进阶教程 | 史上最易懂SQL教程!10小时零基础成长SQL大师!!_哔哩哔哩_bilibili www.bilibili.com/video/BV1UE41147KC/?p=17&spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=171e84ea90c06aa5a434d7fa2502e75c
2、https://zhuanlan.zhihu.com/p/222865842(非常感谢这位知乎大佬,笔记、课件写的很详细)
由于《SQL必知必会(第五版)》这部分内容分布在多章,且是靠后的位子,书上第六章-第十二章是处理数据的内容,和Mosh老师的课程节奏不一样,预计在本月25号之前会将书上的内容补充在本博客中。
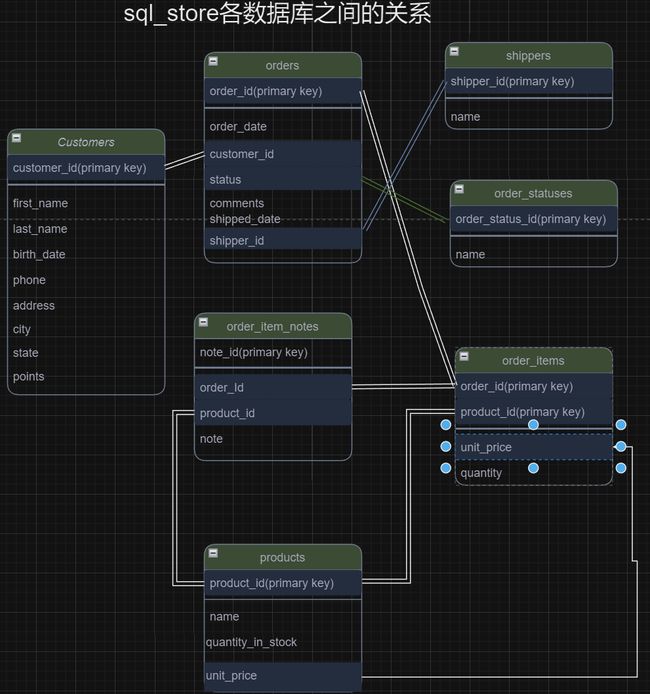
sql_store中各数据库之间的关系
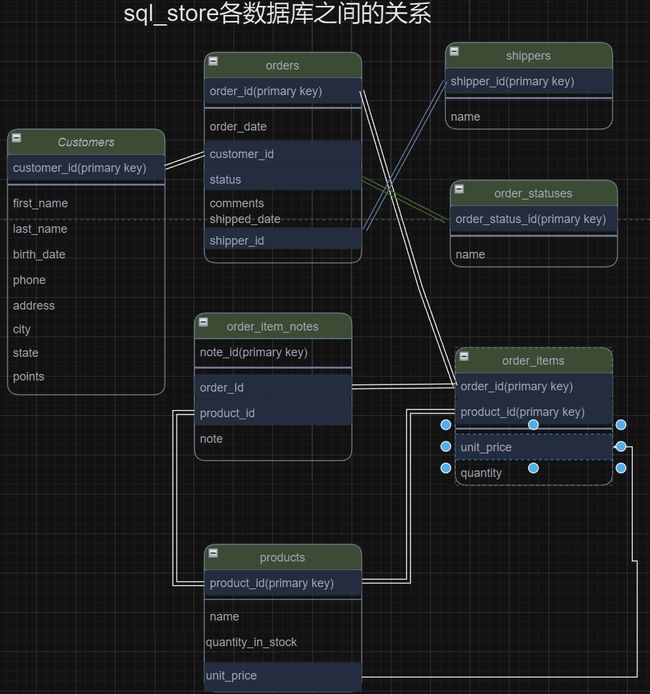
本章概要
各表分开存放是为了减少重复信息和方便修改,需要时可以根据相互之间的关系连接成相应的合并详情表以满足相应的查询。
FROM 表A JOIN 表B ON A.feature1 = B.feature2语句就是告诉sql: 将哪几张表以什么基础连接/合并起来。这种有多表合并的查询语句可分两部分从后往前看:
- 后面的
from表Ajoin表BonA.feature1 = B.feature2 的关系,就是以某些相关联的列为依据(关系型数据库就是这么来的)进行多表合并得到所需的详情表;- 前面的 select 就是在合并详情表中找到所需的列。
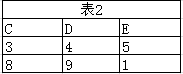
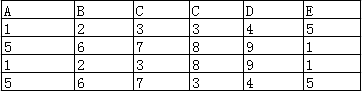
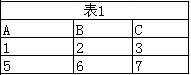
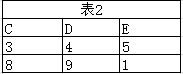
笛卡尔积
它将两个表中的每一行数据组合在一起,形成所有可能的行对(相当于是两表中所有记录进行两两组合的全集)。如果表A有M行,表B有N行,那么它们的笛卡尔积将有M × N行。
例子:
表1 和表2 经过笛卡尔积后筛选出的记录有:

内连接
内连接返回两个表中匹配的记录,可以自定义以两张表的不同列字段进行连接。如果在一个表中有记录而在另一个表中没有匹配的记录,则这些记录不会出现在结果中。通常用于需要找出两个表中相匹配记录的情况。
内连接有两种形式:
- 隐式的内连接,没有inner join;
- 显示的内连接,一般称为内连接,有inner join(inner可以省略).
e.x.:假设有两个表,一个是员工表和一个是部门表,内连接可以用来找出每个员工所属的部门。
实例1
题目:通过orders表中的customer_id字段将orders表与customers表进行内连接
-- 显示的内连接
select * from sql_store.orders inner join sql_store.customers
on orders.customer_id = customers.customer_id
-- 隐式的内连接
use sql_store;
select * from orders, customers
where orders.customer_id = customers.customer_id
结果解析:筛选出来的表格保留俩表中customer_id字段值一样的记录,只展示有订单的顾客(及其订单),也就是两张表的交集.
实例2
题目:通过orders表中的customer_id字段将orders表与customers表进行内连接,并检索出order_id,customer_id, first_name, last_name字段
use sql_store;
select order_id, orders.customer_id, first_name, last_name
from orders join customers
on orders.customer_id = customers.customer_id
若select语句变成
select order_id, customer_id, first_name, last_name会报错Error Code: 1052. Column 'customer_id' in field list is ambiguous
解析原因:因为两个表都有这个customer_id列,只写customer_id的,DBMS无法分辨是选取哪个表格的customer_id字段,所以会造成ambiguous error。因此必须要必须指定一个表的customer_id,这里指定任意一个表的都行,因为正是按相等的customer_id来链接两个表的(最后两个表的合表中customer_id字段的值是每个表customer_id字段的子集)。
总结:选择多张表里都有的同名列时,必须加上表名前缀来明确列的来源。
题目:可以看到在上个代码,orders和customers出现了好多次,为了避免重复,让代码更简洁,可以对表名使用别名(as可以省略)
use sql_store;
select order_id, o.customer_id, first_name, last_name
from orders as o join customers as c
on o.customer_id = c.customer_id
-- 注意on o.customer_id = customers.customer_id会报错(原因在本章后面会详细解释,这里简单解释:表的原名被别名所覆盖,SQL就只能识别别名而认为原名不存在了,该别名成为引用该表的唯一标识符表的原名被别名所覆盖,SQL就只能识别别名而认为原名不存在了)
注意:
(INNER) JOIN结果只包含两表的交集,另外注意“广播(broadcast)”效应广播效用:
即一条顾客信息被多条订单记录共用。在此例中,INNER JOIN以后顾客信息其实是是广播了的,
练习
题目:通过 product_id 链接 orders_items 和 products:
use sql_store;
select * from order_items as oi join products as p
on oi.product_id = p.product_id
题目:通过 product_id 链接 orders_items 和 products,筛选order_id, product_id,quantity, unit_price字段
use sql_store;
select order_items, oi.product_id, quantity, unit_price
from order_items as oi join products as p
on oi.product_id = p.product_id
注解:由于order_items字段只在order_items表中出现,而quantity、unit_price字段只在products表中出现,所以不用特别指明。
跨数据库连接(合并)
有时需要选取不同库的表的列,其他都一样,就只是from...join...on里对于非现在正在用的库的表要加上库名前缀而已,仍然可用别名来简化。
案例
题目:假设sql_store中没有products表格,而此时这张表格在sql_inventory数据库(和sql_store.products完全一样)中,现在需要通过 product_id 链接 orders_items 和 products筛选order_id
-- 写法1
use sql_store;-- 或者左边schemas中选中sql_store,此时左边的左边schemas的sql_store就会加粗显示
select * from order_items oi
join sql_inventory.products p
on oi.product_id = p.product_id
-- 写法2
use sql_inventory;-- 或者左边schemas中选中sql_inventory,此时左边的左边schemas的sql_inventory就会加粗显示
select * from sql_store.order_items oi-- sql_inventory中没有order_items表,需要额外声明
join products p
on oi.product_id = p.product_id
自连接
一个表和它自己合并。
引例:员工的上级也是员工,所以也在员工表里,所以想得到的有员工和他的上级信息的合并表,就要员工表自己和自己合并
方法:用两个不同的表别名,并给每个需要选取的字段都要加
表格名.,必要时需要给重复的字段设置别名即可实现。
SELECT * FROM sql_hr.employees;
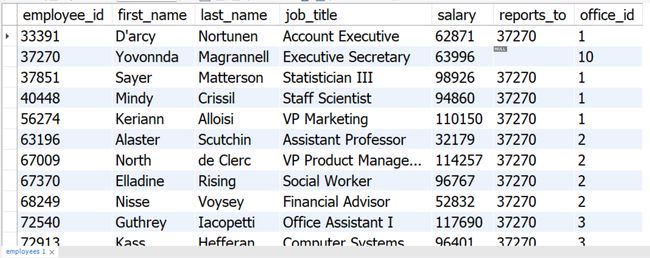
案例1
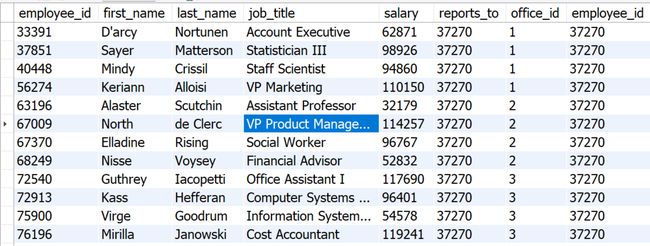
题目:自连接employees表格,从而显示上司的个人信息
use sql_hr;
select * from employees as e join employees m on e.reports_to = m.employee_id
结果:
案例2
自连接employees表格,从而显示上司的个人信息,并筛选出员工的id、员工的first_name、上司的first_name
use sql_hr;
select e.employee_id, e.first_name, m.first_name
from employees as e join employees m
on e.reports_to = m.employee_id

有两个first_name字段,会产生歧义,需要修改某个字段的别名
use sql_hr;
select e.employee_id, e.first_name, m.first_name as manager
from employees as e join employees m
on e.reports_to = m.employee_id
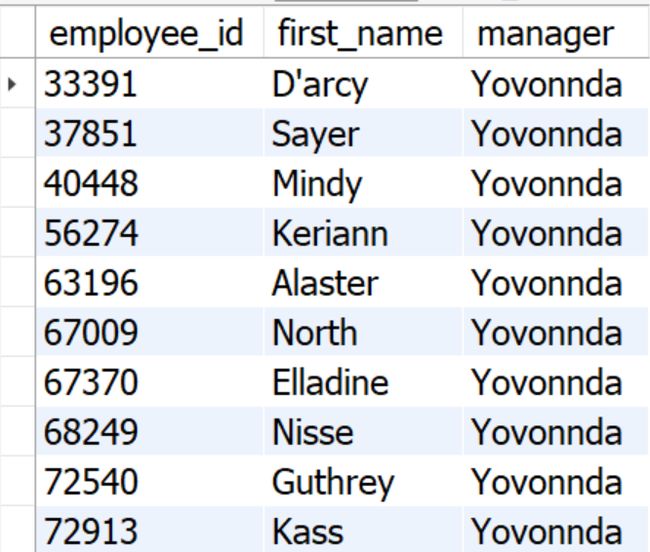
总结
from...join..时要用两个不同的表别名,并给每个需要select选取的字段都要加表格名.,必要时需要给重复的字段设置别名即可实现
多表连接
FROM 一个核心表A(与BCD三个表都有关系),用多个 JOIN …… ON …… 分别通过不同的链接关系链接不同的表B、C、D……,通常是让表B、C、D……为表A提供更详细的信息从而得到一张合并了BCD……等表详细信息的合并版A表(只有表里有相同的列才能连接)。同时也允许各表之间随便排列,只要保证表与表之间的关联条件正确且能把几个表连在一起即可。即:
FROM A
JOIN B ON AB的关系
JOIN C ON AC的关系
JOIN D ON AD的关系
-- 或者
FROM A
JOIN B ON AB的关系
JOIN C ON BC的关系
JOIN D ON CD的关系
……
案例1
题目:订单表同时连接顾客表和订单状态表(要将状态的数字编码在复合表中详细成状态信息),合并为有顾客和状态信息的详细订单表,筛选出订单id列、订单日期、first_name、last_name以及状态名

USE sql_store;
SELECT o.order_id,
o.order_date,
c.first_name,
c.last_name,
os.name AS status
FROM orders o
JOIN customers c
ON o.customer_id = c.customer_id
JOIN order_statuses os
ON o.status = os.order_status_id
练习
题目:支付记录表连接顾客表和支付方式表形成支付记录详情表,并筛选交易日期、支票id、支票金额、客户姓名、支付方式
USE sql_invoicing;
SELECT
p.invoice_id,
p.date,
p.amount,
c.name,
pm.name AS payment_method
FROM payments p
JOIN clients c
ON p.client_id = c.client_id
JOIN payment_methods pm
ON p.payment_method = pm.payment_method_id
复合连接条件
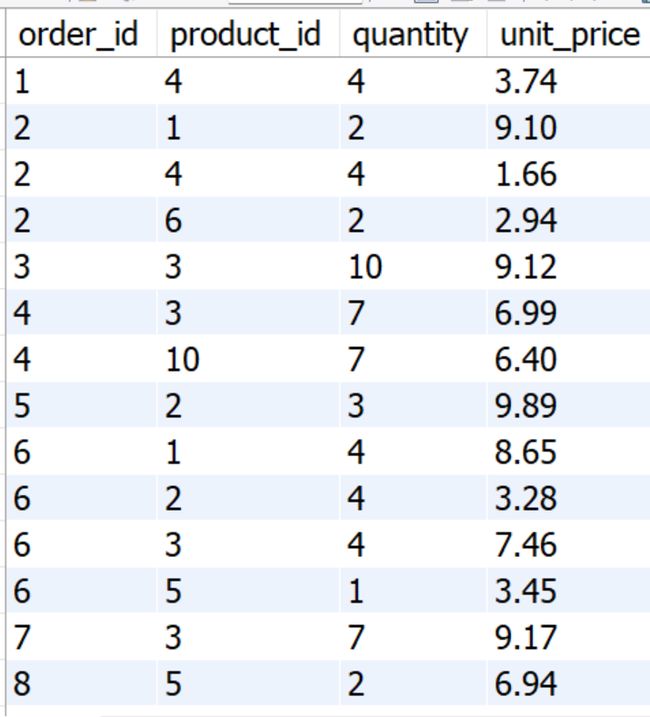
在order_items表中,我们可以发现,order_id和product_id都存在重复值,也就意味着,无法单独通过这两个字段来进行记录筛选,因此在order_items表,我们可以用order_id和product_id字段联合来进行记录筛选,我们能一一对应单独记录筛选的这两个字段称为复合主键。
案列1
题目:通过联合主键将order_items表和order_item_notes表进行连接
USE sql_store;
SELECT *
FROM order_items as oi
JOIN order_item_notes as oin
ON oi.order_Id = oin.order_Id
AND oi.product_id = oin.product_id
隐式连接
用FROM WHERE取代FROM JOIN ON
注意:
尽量别用,因为若忘记WHERE条件筛选语句,不会报错但会得到交叉合并(cross join),即oder表的10条记录会分别与customers表的10条记录结合,得到100条记录。最好使用显性合并语法,因为会强制要求你写合并条件ON语句(join和on是捆绑语句),不至于漏掉。
案例
题目:通过customer_id合并顾客表和订单表,显性合并:
USE sql_store;
SELECT *
FROM orders as o
JOIN customers as c
ON o.customer_id = c.customer_id
隐式合并语法:
SELECT *
FROM orders as o, customers as c
WHERE o.customer_id = c.customer_id
注意:
- FROM 子句中多个表需要用逗号隔开,此时若忘记WHERE条件筛选语句则得到这几张表的交叉合并结果;
- ON和 WHERE 以及后面会学的 HAVING 的作用是类似的,本质上都是对行进行筛选的条件语句,只不过使用的位置不一样而已
外连接
包括LEFT/RIGHT (OUTER) JOIN (out可以省略),筛选结果里除了交集,还包含只出现在左/右表中的记录(没有和另一个表有匹配的),相当于取某个表的并集或者是取两个表未匹配记录的并集(和交叉连接做区分)。
-
from A left join B:返回表A(左表)的全部记录(的select字段)+表B(右表)对应的记录(的select字段),不管筛选条件是否正确;如果表A中数据在右表中没有与其相匹配的行,则在查询结果集中显示为空值; -
from A right join B:返回表B(右表)的全部记录(的select字段)+表A(左表)对应的记录(的select字段),如果表B中数据在右表中没有与其相匹配的行,则在查询结果集中显示为空值。补充:
全外连接:在自然连接的基础上,只把左表和右表要舍弃的都保留在结果集中,相对应的列上填null。也就是说将两表在on对比的字段上取值一样的拼成一条记录,其余无法匹配的记录仍然保留,在合表空缺的相应位置用null值填充。
e.x.:
经过全外连接后
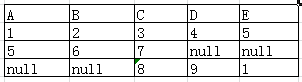
注意:MySQL不支持全外连接
案例1
题目:将orders表与customers表进行外连接,展示全部顾客
USE sql_store;
SELECT
c.customer_id,
c.first_name,
o.order_id
FROM customers as c
left JOIN orders as o
ON o.customer_id = c.customer_id
案列2
题目:将orders表与customers表进行外连接,展示全部订单(用两种方法实现)
-- 法一
USE sql_store;
SELECT
c.customer_id,
c.first_name,
o.order_id
FROM customers c
right JOIN orders o
ON o.customer_id = c.customer_id
-- 法二:利用left join,并调换两表的位置
USE sql_store;
SELECT
c.customer_id,
c.first_name,
o.order_id
FROM orders as o
left JOIN customers as c
ON o.customer_id = c.customer_id
练习
题目:展示各产品在订单项目中出现的记录和销量,也要包括没有订单的产品
USE sql_store;
select p.*, oi.quantity
from order_items as oi
right join products as p
on oi.product_id = p.product_id
多表外连接
与内连接类似,我们可以对多个表(3个及以上)进行外连接,最好只用 JOIN 和 LEFT JOIN
案例
题目:查询顾客、订单和发货商记录,要包括所有顾客(包括无订单的顾客),也要包括所有订单(包括未发出的)
USE sql_store;
SELECT
c.customer_id,
c.first_name,
o.order_id,
sh.name AS shipper
FROM customers as c
LEFT JOIN orders as o
ON c.customer_id = o.customer_id
LEFT JOIN shippers as sh
-- 如果是 JOIN shippers as sh,则是筛选出已经发货的订单和顾客信息(此时是取三个表的交集)
ON o.shipper_id = sh.shipper_id
ORDER BY customer_id
练习
题目:查询 订单 + 顾客 + 发货商 + 订单状态,包括所有的订单(包括未发货的)
prompt:
订单与顾客的关系:多对一对应,且无缺失值;
订单与发货商(shipper_id)的关系:多对一关系,存在缺失值(未发货);
订单与订单状态:多对一关系,不存在缺失值。
USE sql_store;
SELECT
o.order_id,
o.order_date,
c.first_name AS customer,
sh.name AS shipper,
os.name AS status
FROM orders as o
JOIN customers as c -- 也可以left join(订单与顾客是多对一关系)
ON o.customer_id = c.customer_id
LEFT JOIN shippers as sh
ON o.shipper_id = sh.shipper_id
JOIN order_statuses as os-- 也可以left join(订单与顾客是多对一关系)
ON o.status = os.order_status_id
第2个 JOIN 必须是 LEFT JOIN,否者会筛掉没发货的订单(shippers表中对null值没有定义)
自外连接
一个表和它自己合并,但要有表内所有主键信息
案列
题目:对员工表进行自合并,同时要有老板本人的信息
use sql_hr;
select
e.employee_id,
e.first_name,
m.first_name as manager
from employees as e
left join employees as m -- 包含所有雇员(包括没有report_to的老板本人,老板本人的report_to为NULL)
-- 如果是JOIN employees m,则筛选出的信息中只有打工人,没有资本家老板了
on e.reports_to = m.employee_id
Using
当作为合并条件(join condition)的列在两个表中有相同的列名时:
-
单一主键可用
USING (……)代替on....,当两个表原本要on的字段名称不一样时,则必须得用on... = ...; -
复合主键可用
USING (……, ……)取代ON …… AND ……予以简化,当两个表原本要on的字段名称不一样时,则必须得用on... = ... and ... on ...。注意:
using对内外连接都适用。
实例1
题目:查询 订单 + 顾客 + 快递员信息,包括所有的订单(包括未发货的)
prompt:
- 订单和顾客的关系:多对一,且无缺失值;
- 订单和快递员状态:一一对应,有缺失值。
SELECT
o.order_id,
c.first_name,
sh.name AS shipper
FROM orders as o
JOIN customers as c -- 也可以left join customers as c
USING (customer_id)
LEFT JOIN shippers as sh
USING (shipper_id)
ORDER BY order_id
实例2
题目:通过product_id和order_id将order_items表和order_item_notes连接
SELECT *
FROM order_items AS oi
JOIN order_item_notes AS oin
USING (order_id, product_id)
练习
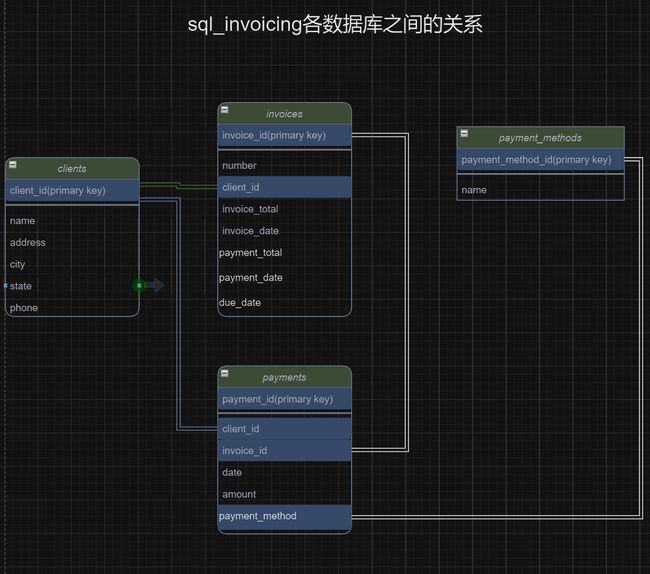
题目:sql_invoicing库里,将payments、clients、payment_methods三张表合并起来,以知道什么日期哪个顾客用什么方式付了多少钱
USE sql_invoicing;
SELECT
p.date,
c.name AS client,
pm.name AS payment_method,
p.amount
FROM payments AS p
JOIN clients AS c USING (client_id)
JOIN payment_methods AS pm
ON p.payment_method = pm.payment_method_id
自然连接
让MySQL自动检索同名列作为合并条件
注意
最好别用,因为不确定合并条件是否找对了,有时会造成无法预料的问题,编程时保持对结果的控制是非常重要的
案列
题目:将订单表和客户表进行自然连接,筛选出订单编号和first_name字段
USE sql_store;
SELECT
o.order_id,
c.first_name
FROM orders AS o
NATURAL JOIN customers AS c
交叉连接
得到两个表中字段的所有组合,相当于是两个表的全集
e.x.:
oders表的10条记录会分别与customers表的10条记录结合,得到100条记录
两种语法结构:
- 显示:
select ...... from A cross join B - 隐式(忽略合并条件,加上逗号):
select ...... from A,B
实例
用显示和隐式语法分别得到顾客和产品的全部组合(笛卡尔积),并筛选出顾客名字和产品名字,按照名字排列
-- 显示
USE sql_store;
SELECT
c.first_name AS customer,
p.name AS product
FROM customers AS c
CROSS JOIN products AS p
ORDER BY c.first_name
-- 也可以order by customer
-- 隐式
USE sql_store;
SELECT
c.first_name,
p.name
FROM customers AS c, products AS p
ORDER BY c.first_name
-- 也可以order by customer
Question1:from语句中一旦给表使用了别名,order by后面只可以加c.first_name,不能是customers.first_name?
Question2:为什么where语句只能用字段原名,不能用别名?
首先得知道MySQL语句执行顺序的关系(其中每一个操作都会产生一张虚拟的表,这个虚拟的表作为一个处理的输入,只是这些虚拟的表对用户来说是透明的,只有最后一个虚拟的表才会被作为结果返回)。对于MySQL的语句
select...distinct...from...join...on...where...(group by...having...后面会学)order by...limit...,在SQL的执行顺序(不一定反映了数据库管理系统内部的实际操作顺序):from...join...on...where...(group by...having...后面会学)select..distinct....order by...limit...。解释问题1先从
FROM子句开始,确定表及其别名。接着解析其他部分,例如SELECT、WHERE、GROUP BY等。在FROM子句中为表指定别名后,表的原名被别名所覆盖,SQL就只能识别别名而认为原名不存在了,该别名成为引用该表的唯一标识符表的原名被别名所覆盖,SQL就只能识别别名而认为原名不存在了。数据库期望在查询的后续部分使用这个别名来引用表的列。使用别名的一个主要目的是在涉及多个表时消除歧义。如果允许混合使用原始表名和别名来引用列,则可能导致查询解析上的混淆和歧义。别名定义了表在特定查询中的作用域和可见性。一旦表被赋予别名,其原始名称在查询的后续部分(特别是在
SELECT、WHERE、GROUP BY子句中)不再可用,这意味着,如果给customers表指定了别名c,则必须使用c来引用其列,例如c.first_name。解释问题2:where的执行顺序是在select的前面,也就是说在where语句进行识别时,select语句(可以对字段进行别名命名)还没有运行。
练习
题目:分别用显式和隐式语法交叉合并shippers和products,按照shipper的名字来进行排序,筛选出产品名字和shipper的名字
-- 显示
USE sql_store;
SELECT
sh.name AS shippers,
p.name AS product
FROM shippers AS sh
CROSS JOIN products AS p
ORDER BY sh.name
-- 隐式
SELECT
sh.name AS shippers,
p.name AS product
FROM shippers AS h, products AS p
ORDER BY sh.name
联合(Union)
FROM …… JOIN …… 可对多张表进行横向列合并,而 …… UNION …… 可用来按行纵向合并多个查询结果,这些查询结果可能来自相同或不同的表:
- 同一张表:可通过UNION添加新的分类字段,即先通过分类查询并添加新的分类字段再UNION合并为带分类字段的新表;
- 不同表:通过UNION合并的情况如:将一张18年的订单表和19年的订单表纵向合并起来在一张表里展示
注意:
- 合并的查询结果必须列数相等,否则会报错(因为是纵向合并);
- 合并表里的列名由排在 UNION 前面的决定;
- union前的语句不用加分号;
- 最后合并后的结果,union前面的筛选出的字段会排在前面。
案列1:合并同一张表
题目:给订单表增加一个新字段——status,用以区分今年(2019年)的订单(status的状态则为active)和今年以前的订单(status的状态则为archive)
USE sql_store;
SELECT
order_id,
order_date,
'Active' AS status-- 字段status的对应记录取值为active
FROM orders
WHERE order_date >= '2019-01-01'-- 注意这里没有分号
UNION
SELECT
order_id,
order_date,
'Archived' AS status -- Archived 归档
FROM orders
WHERE order_date < '2019-01-01';
案列2:合并不同表
题目:在同一列里显示所有顾客名以及所有商品名
USE sql_store;
SELECT first_name AS name_of_all
-- 新列名由排UNION前面的决定
FROM customers
UNION
SELECT name
FROM products
注意:新列名由排UNION前面定义的别名来决定
练习
题目:给顾客按积分大小分类,添加新字段type,并按顾客id排序,分类标准如下
points type <2000 Bronze 2000~3000 Silver >3000 Gold
SELECT
customer_id,
first_name,
points,
'Bronze' AS type
FROM customers
WHERE points < 2000
UNION
SELECT
customer_id,
first_name,
points,
'Silver' AS type
FROM customers
WHERE points BETWEEN 2000 and 3000
UNION
SELECT
customer_id,
first_name,
points,
'Gold' AS type
FROM customers
WHERE points > 3000
ORDER BY customer_id
注意:
对于SQL的执行顺序:
from...join...on...where...(group by...having...后面会学)select...distinct...union...order by...limit...,union的位置是在select…distinct后面,会根据select的个数来循环执行`from…join…on…where…(group by…having…后面会学)。
总结
- 横纵筛选
SELECT ……WHERE …… - 选表
FROM …… - 横纵连接
…… JOIN ……``…… UNION …… - 排序、限制
ORDER BY ……``LIMIT ……