Airbnb系列三《Managing Diversity in Airbnb Search》 搜索多样性
abstract
搜索系统中一个长期的问题是结果多样性。从产品角度讲,给用户多种多样的选择,有助于提升用户体验及业务指标。
多样性需求和模型的目标是相矛盾的,因为传统ctr模型是 point wise,只看单个相关性不管相邻之间item差异。
论文解决多样性的问题,从启发式的方法开始,最后介绍了结合RNN 的创新性的 DL 方法。
多样性问题背景
多样性问题背景:发现对一些热门location的排序展示结果,top几个都非常相似,在可见的listing属性上,如价格、类型、容量、位置等。
这种现象对那些没有在top中找到满意结果的用户不利,因为他们可能会觉得,怎么推出来的都是相似的,并且还不满意,就会减少搜索欲望。
DNN 会给相似属性的item打相似分,所以排序结果上相似属性的item会集中在一块。
下图是Airbnb房源库中多种风格的item 示例。

为了对精排结果进行二次排序以保证item多样性,在排序架构上增加了重排模块(Second Stage Ranker)
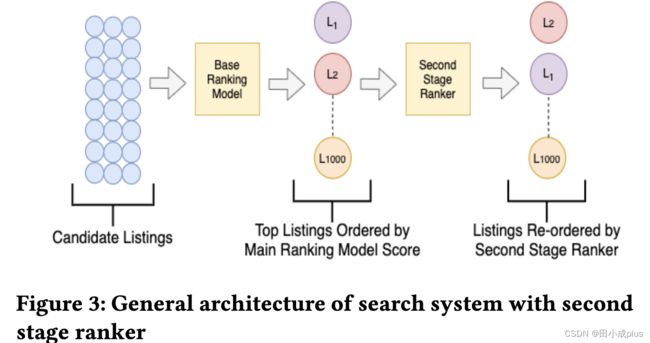
重排方法1 贪心Ranker
MMR
https://blog.csdn.net/m0_62577727/article/details/125585630

MRR更适合推荐业务,在搜索业务的重排序阶段不太适合,很多推荐业务还是会用 MMR来做初始的多样性 baseline
MMR算法思想:每次采取贪心策略,生成 topK结果列表。第一次从 topN中选取第一个加到候选,第二次 从topN中选择和当前候选相似度最低同时和query匹配度最高的物品,这两个条件怎么平衡呢,就是 λ去调节。直到选出K个 重排集合
MLR (Mean Listing Relevance)

几点不同:
-
想要在多样性中考虑 positional bias,item相关性 = book概率 * 位置衰减函数权重
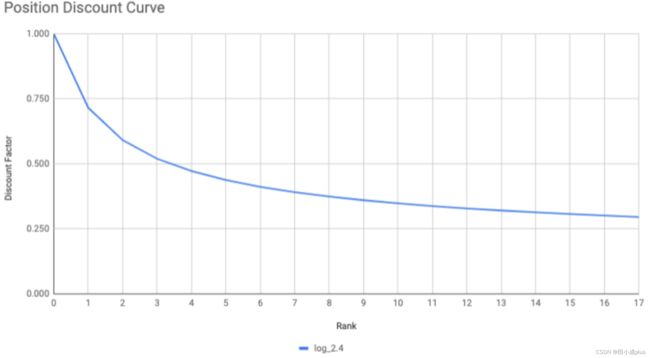
-
和 MMR 相比,衡量多样性部分,不是用 max而是用 mean。
- mean会使得多样性的惩罚更加平滑。
- MMR有个假设前提,用户只对一个类别中的一个item感兴趣,适合推荐,因为推荐可以推不同类别,但是search结果的范围更小,所以这个限制在搜索上过于严格
实践中,N 至少是一个页面大小,即最终呈现给用户的一页listing是多样性重排之后的
- 注意之前的MRR是 -,这里是 +,因为之前是 相似度函数,越大越相似,所以是-。 这里是距离函数,距离越小越相似。
但是不管是 MLR 还是 MRR,都有一个问题:如何表示一个 listing的向量?
listing向量表示
当然可以用深度学习方法,抽取item embedding向量,但是这种方式过于黑盒,不太适合于业务初期。所以这里 airbnb 用listing可解释属性表示成一个向量,如 [价格、经纬度位置、容量、浴室数量、房间数量、房间类型], 确定了用哪些属性之后,这个向量的长度就是固定的。其中属性特征可以分为两类:
- 连续性特征:计算均值和方差,进行标准归一化,上一篇论文讲过的手段
- 类别特征:one-hot
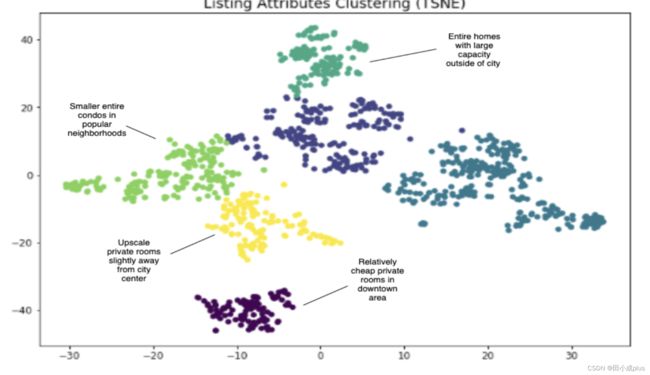
表示后的向量 通过tsne 二维平面聚类可视化,kmeans分成6个类,然后分析每一类的 Listing属性,每一堆确实有共性属性。之所以用可解释属性,没有用word2vec等embedding向量表示,是因为这些属性有业务含义,比较好解释。
选出来的多样性好坏如何衡量
MLR算法,是来选出多样性重排的 topK,那这 topK的列表该怎么衡量好不好呢?思路就是把这 topK 列表和理想(上帝视角)的多样性列表分布进行对比,那么
如何找到理想(上帝视角)的多样性分布?airbnb选取了两个方面的多样性来衡量:
- Location diversity 地理位置多样性
- Price diversityzh 价格多样性
假设找到了这个上帝视角的多样性分布,那么如何对比当前列表和理想列表的差距呢?对比差距当然是用距离函数了,这里用的是 Hellinger 距离,专门用于衡量两个离散概率分布相似性,并且值域是 [0,1]

总体验证思路:
- 找到这次query请求对应的理想localtion分布/price分布
- 计算当前重排列表 topk的 localtion分布/price分布
- 用Hellinger距离计算1和2两个分布的距离,距离越小越接近理想分布,多样性越好
接下来用这三步来看下是如何验证多样性列表好坏的,个人觉得这里的做法还是挺有意思的?
location diversity
上帝视角的理想分布必然是不存在,回到现实还是要通过历史搜索日志去构建,比较历史搜索中含有用户的真实反馈,这些反馈信息是实打实的。
- 找到这次query请求对应的理想price分布
- KD-Tree 把地球划分为listing密度大概相同 的叶节点,每个叶节点就是一个桶
- 对过去的一个具体搜索Q,book了 listingA,则在 listingA的叶节点中放入Q,计数加1
- 不断重复2,则每个历史query都会落在一个桶中
- 递归合并数量不满足某个阈值的叶节点,直到超过这个阈值
- 最终每个query都落入一个桶中,并且这个桶中的 Listing数和命中的query数是固定的
- 假设总共ABCDE 5个桶,每个桶的理想概率=命中query数/ listing 数,则可以得到5个理想概率
[20/100, 10/30, 5/40, 6/50, 10/20],这表示什么意思呢?就是对于任意一个列表,落入每个桶的比例已经知道了并且这个比例就是理想比例,这个比例构成的向量就是在地里位置维度的多样性分布
- 计算当前重排列表的localtion分布
- 线上query请求 -> 精排 [L1, L2, … L1000] -> 重排 [L2, L9, L1, … L100] 得到一个长为100的重排列表
- 计算当前列表落入每个桶的概率,得到5个概率值,假设是
[20/100, 0/100, 40/100, 10/100, 30/100],表示这个列表落入A桶20个,B桶0个,以此类推
- 计算 1和2两个概率分布的 Hellinger 距离,距离越小说明重排的地理位置多样性越好
price diversity
理想的价格多样性应该符号正态分布,以某个期望价格为中心,同时具有多个其它区间价格。并且期望价格肯定是不同的query条件不一样的,这里用一个回归神经网络对不同query条件进行预测得到期望价格
- 找到这次query请求对应的理想price分布:通过回归神经网络预测出来
- 训练:训练数据是 query侧特征,比如人数、价格、地理位置、住几晚等,label是这次搜索产生book的listing的价格。
- 预测:输入是线上的query侧特征,输出是这此query的理想期望价格 Ep
有了期望价格怎么找理想区间?因为Ep上下误差范围内都可以认为是理想的。其实就是人工指定超参数来控制,定义最小值最大值,pmin= α * EP, pmax = β * Ep,
这个[pmin, pmax],就表示对于当前query,理想的listing的价格应该处于这个区间。 - 怎么找其它的多样性区间以及理想概率?根据paper描述,个人猜测应该是这样的:
- 比如 Ep=100,pmin=80, pmax=120, 则区间大小=40
- 找左右其它区间,如
…, [40, 80], [80, 120], [120, 160], …,假设有10个价格区间 - 每个区间做归一化
(x-Ep)/Ep, 如 [80, 120] -> [-0.2, 0.2] - 正态分布计算落入每个区间的概率,如落入理想区间 [-0.2, 0.2]的概率是可以算出来的,这样就得到10个概率分布向量,这个向量就是 理想价格多样性分布
- 计算当前重排列表的price分布
- 线上query请求 -> 精排 [L1, L2, … L1000] -> 重排 [L2, L9, L1, … L100] 得到一个长为100的重排列表
- 计算当前列表落入每个价格区间的概率,得到10个概率值,假设是
[2/100, 6/100, 10/100, 10/100, 30/100,...],表示这个列表落入第一个区间桶2个,第二个区间6个,以此类推
- 计算 1和2两个概率分布的 Hellinger 距离,距离越小说明重排的价格多样性越好
下图是10个区间的理想价格多样性分布
重排方法2 Location diversity ranker
同时优化多个多样性比较难,所以集中在比较重要的地理位置的多样性上,构造新的 Loss,同时考虑 了地理位置多样性和相关性:

-
S: 精排的打分列表
-
Lq:是对于query Q在KD-Tree节点的理想位置分布
-
Ls:S中的每个候选,在 KD-Tree上的先验分布
-
H : 用重排序结果和理想地理分布的距离,表示重排结果的多样性得分。两个离散距离后验概率列表的 Hellinger distance,范围是[0,1]
-
NDCGf:把精排阶段分数作为 ground truth label, 用来衡量当前重排 列表 S 和 精排打分排序后的列表 S‘的 NDCG差值,衡量和精排相关性的偏离程度。如 精排序是 [1,2,3,4,5], 重排后是 [3,2,1,4,5],范围是[0,1]
以精排阶段分数作为ground truth label, 来衡量重排序结果和精排结果的偏差,表示重排结果的相关性得分
-
λ l o c \lambda_{loc} λloc 是超参数来平衡相关性和多样性,值越大,多样性惩罚越大,越在意相关性
-
loss值越小越好,说明越接近理想分布同时相关性最好
如何求解 loss?
标准的 SGD方法不能优化,因为地理位置表示的映射是固定的,导致 Lq 和 Ls都是固定的,没办法通过梯度下降优化。
用模拟退火算法,多次迭代进化。每次迭代通过交换重排序结果列表中两个item的位置生成新的结果,如果交换后, loss下降则接受这次交互,否则以一定概率接受。
重排方法3 Combined Loss Function
前面几种方法,计算 relevance 和 diversity 相分离,限制了重排序的效果。为了更好的建模 listing 、query 和 diversity 目标间的复杂交互关系,作者提出了将多个目标融合到一个可以用SGD优化的损失函数的方法
基于以下假设,将重排序优化问题,转化为优化生成结果和目标结果多样性分布的Hellinger距离:

几个需要明确的前提:
- 每个训练样本包含 N 个 listing
- 地理位置的目标分布是离散化的,对应 K 个可能的 bucket
- 每个listing到bucket的映射是固定的
- 最小化 TopT listing 的目标分布与经验分布之间的Hellinger distance,这里T <= N。
但是,直接使用Hellinger距离作为loss function是不可行的:因为每个listing对应的bucket是常数,和DNN的权重没有直接依赖,所以无法用SGD优化。然后设计了一个巧妙的替代loss,总体思想是,对于每个桶而言,我们可以有个二元判别器,来判别候选房宿分布中的这个桶里面的值是不是超过了理想分布中这个桶的固定值。
设计替代loss:
如果item集合中,落入某个bucket的 item数量超过理想分布阈值,就缩小该bucket的item的打分,这个item的打分时 DNN可以控制
基于此思想,定义总体损失函数为相关性的 Pairwise loss 、位置多样性loss、价格多样性loss 的和 L h = L r + L d l + L d p L_h = L_r + L_dl + L_dp Lh=Lr+Ldl+Ldp,其中相关性 loss L r L_r Lr
保证了重排序结果的相关性,位置分布多样性loss L d l L_{dl} Ldl 、价格分布loss L d p L_{dp} Ldp, 保证了重排序结果的多样性。

某个item所属的bucket中listing数超过一定阈值,则说明该桶的相关性比较大了,因此优化方向将使得bucket中的listing数量减少并向目标阈值移动
假设 batch=1, num_listing=3, num_bucket = 5,总共有 ABCDE个切好的bucket
-
输入变量:
- top_rank_logits: 重排网络预测分数 shape=[1, 3]
- bucket_vals: shape=[1,3,5] 当前列表每个item落入的bucket的 one-hot表示
- target_dist: query理想分布, shape[1, 5],value都是0-1的小数, 如
[ 0.2, 0.3, 0.4, 0.1, 0.5] 表示大数据统计的 每个桶应该落入的理想比例
-
distribution: [1, 5] ,重排列表落入每个桶的listing的比例
- ABCDE五个桶,3个listing分布属于 [A, A, C], 则桶分布=[2/3, 0, 1/3, 0, 0]
-
direction_mask: [1, 5],当前distribution 是否小于 target_distribution,对应每个listing所属的桶是否超标了,0是超标,1是没有。
[2/3, 0, 1/3, 0, 0] < [0.2, 0.3, 0.4, 0.1, 0.5] -
mask_tiled:mask=[B, N] → [B, N, L] → [B, L, N]。比如 [0,1,0,1,0] 是BD 两个桶超标了,则这个向量复制3份,也就是每个 listing 都知道这个信息
[0,1,0,1,0, 0,1,0,1,0, 0,1,0,1,0] → # [B, L, N], 每个listing都知道当前列表,哪个桶超标了 [ [0,1,0,1,0,], [0,1,0,1,0,], [0,1,0,1,0,] ] -
sg_label:
-
filtered_bucket:没说是啥,但应该是把一个列表里的多个1过滤掉只留一个1,因为后面要进行 sum变成2分类的问题。从物理意义上来说,只要有一个桶超标,就说明这个列表是需要多样性的
-
filtered_buckets * mask_tile → [1, 3, 5],每个值是0或者1
-
axis=2 进行 reduce_sum → [1, 3] ,每个值是0或者1,表示这个列表是否有在地里位置上超标
[ [0,1,0,1,0,], [0,1,0,1,0,], [0,1,0,1,0,] ] - > [1, 1,1] 表示当前列表不满足位置多样性了,有的桶落入过多item了
-
-
sqdiff: [1, 5] ,当前 distribution和理想 distribution之间的 Hellinger 距离,
- [B, N, L] → [B, L, N] ,每个listing知道每个桶的 H 距离
-
target_weight:
- sq_diff* bucket_vals,每个listing 知道自己落入的那个桶的 H 距离, buckt_val是 one_hot,所以没有落入的桶都成0 了
- reduce_sum, shape=[B, L]。结果就是每个 item所落入的 bucket的 H 距离。shape=[1, 3]
-
sg_loss:label=sg_label, logit = top_rank_logit 算交叉熵loss,然后再乘 target_weight
使用这种方法,我们现在可以定义一个整体损失,它是标准pairwise损失,位置分布损失和价格分布损失的线性组合。然后,我们使用此组合损失函数训练了第二阶段模型。
重排方法4 利用上下文特征
我们的目标是使模型学习与给定查询相关的结果,但是缺少的一个关键数据是检索集本身的上下文。例如,很可能预订了一个listing,因为它是热门区域中仍然可用的少数几个listing之一
把搜索本身的上下文信息编码到模型中,作者加入了一些上下文特征,例如目标位置空闲房子数量,query对应的top K结果的价格、位置、房间类型、可容纳客人数的平均值和方差等信息。
在模型中加入人工的聚合特征,mean and variance of the price, location, room type, and person capacity,期望模型能利用这些特征学到列表维度的上下文信息。
重排方法5 query context embedding
非常吃基建设施,两个模型,利用上下文信息来做re-rank,这对架构通路其实要求较高
4的方法使用的人为定义的上下文特征,使用手工聚合可能不是代表查询上下文的最佳方法,因为缺乏一定准确度和泛化性,为了更好的建模 query context特征,使用深度学习 RNN来建模 query对应的精排结果(Learning a deep listwise context model for ranking refinement, SIGIR 2018),表示为 listwise context
最后一个时刻的 cell的输出状态 hn,作为 整个列表的 sequence emebedding,用来概括该列表的全部信息。
重排序模型H的结构,实际是有两个模型,一个模型用来生成 query context embedding,一个模型
1 生成 query context embedding的网络
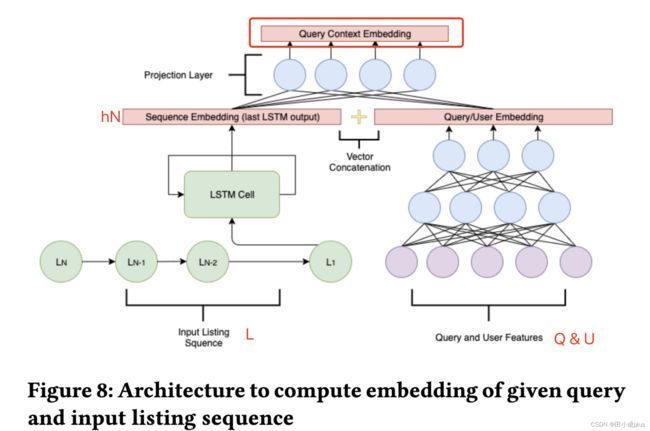
- 左下方 LSTM 计算 context embedding。输入是精排 TopN结果 (L),输出是 hN
- 右下方DNN,输入是 query和user feature (Q & U)
- 将 LSTM 的 sequence embedding和 右侧网络的输出进行拼接
- 拼接后加一层全连接,输出为 query context embedding,用来表示理想的 listing embedding
这个网络只是为了得到最终的 query context embedding
2 重排序打分的网络 H
用下面的网络对 listing 列表进行重排序打分
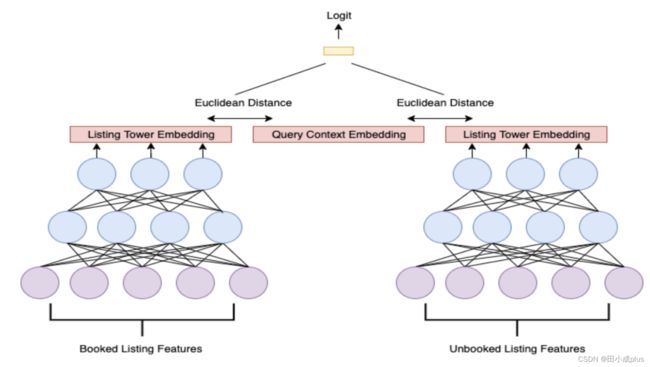
此时的模型可以学习到匹配模式,如果一个listing是 query附近流行区域里的唯一一个,模型会对这个listing进行强化升级。
我们使用了pairwise损失函数,该函数具有将预订listing embedding移动到更接近查询上下文嵌入的效果,同时将未预订的listing推开
下面代码是 pairwise loss的实现,和 aribnb 2020年paper Improving Deep Learning For Airbnb Search 一样。

- query_context_embedding: L Q U
- 这里用两个子网络表示双塔结构,其实只有一个 网络。只不过输入特征不同,训练数据是很多个pair样本
,每个pair的label 都是1,两个房源的特征分别输入到同一个网络,得到两个分数。 - 重排打分时,将精排列表的每个 listing输入到网络中,得到一个基于 欧式距离的 Logit分数,这个分数代表了当前房源与理想房源之间的差距,差距越小越好,所以 loss越小越好。所以线上排序时应该是按 Logit分数从小到大排序。
distance_diff 是未预定listing到理想分布的距离-预定listing到理想分布的距离,越大说明前者是大的后者是小的,因此是越大越好,大是希望看到的。因此logit_diff是 越接近1越好
实验结果
offline

baseline 是 只用精排模型,exp是加了各个重排方法
线上实验效果
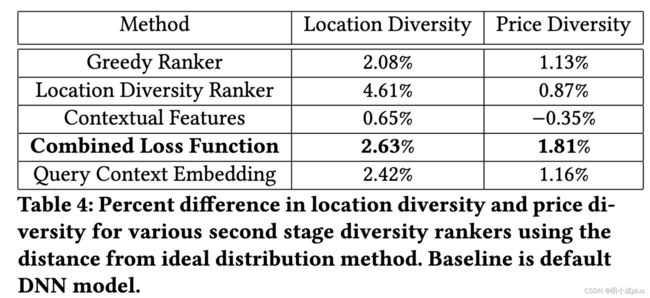
- Greedy Ranker:持平/略负,分析是过于多样性
- Second Stage Location Diversity Ranker: 正向,尤其是对于新用户,booking +1%,中国的用户+3.6%(之前的策略更倾向于城中心的,现在这个也有其他位置的item
- Combined Loss Function: 持平,出现了一些极端价格,新用户 booking 降低比较多,推测是对于价格敏感的用户体验有伤害
- Contextual Features: 持平,推测人工高级特征没有用
- Query Context Embedding: 正向,online NDCG +1.2%, booking +0.44%, 新用户booking +0.61%,说明多样性对新用户很重要。分析了不同价格档位的位置变动情况
模型行为可解释性
DNN模型比较黑盒,如何去解释模型的行为,验证
搜索结果的位置分布,更加多样了

搜索结果的价格分布,更加接近期望价格,减少极端的价格。可以看到绿色的期望价格附近的房源,被重排改动的位置变化更小,而两端的价格对应的房源,被重排带来的位置变化比较大。
如果同一个list中已经出现了极端价格,则对剩余的候选极端价格惩罚加大。物理含义就是避免极端价格的房源重复出现
参考文档
- https://zhuanlan.zhihu.com/p/359330317
- https://zhuanlan.zhihu.com/p/239824669
- https://zhuanlan.zhihu.com/p/369498198
- https://www.modb.pro/db/580111