一文教会pandas
今天的笔试题令我感触很深,回顾一下之前写的都是低代码想想都。。。
anareport[['reportid','anndt','stockid']].drop_duplicates().rolling(window=10,min_periods=1).sum().groupby(['anndt','stockid'])['reportid'].count()
df=anareport[['reportid','anndt','stockid']].drop_duplicates()
pd.crosstab(df['anndt'],df['stockid']).rolling(window=10,min_periods=1).sum().fillna(0)能看懂以上代码可自行跳过本文
1、joining and merging
下面是三个数据框:
import pandas as pd
df1 = pd.DataFrame({'HPI':[80,85,88,85],
'Int_rate':[2, 3, 2, 2],
'US_GDP_Thousands':[50, 55, 65, 55]},
index = [2001, 2002, 2003, 2004])
df2 = pd.DataFrame({'HPI':[80,85,88,85],
'Int_rate':[2, 3, 2, 2],
'US_GDP_Thousands':[50, 55, 65, 55]},
index = [2005, 2006, 2007, 2008])
df3 = pd.DataFrame({'HPI':[80,85,88,85],
'Unemployment':[7, 8, 9, 6],
'Low_tier_HPI':[50, 52, 50, 53]},
index = [2001, 2002, 2003, 2004])
用merge合并
print(pd.merge(df1,df3, on='HPI'))
结果为:

merge 的时候, 会自动忽略索引列. 当然, 我们也可以使用多个列做基准如下:
print(pd.merge(df1,df2, on=['HPI','Int_rate']))
结果:

不共享公共列时, 所以两个列都会保留
可以将其设置成索引:
df4.set_index('HPI', inplace=True)
df4结果为:

如果在合并之前,有相同的索引列就可以用join了:
df1.set_index('HPI', inplace=True)
df3.set_index('HPI', inplace=True)
joined = df1.join(df3)
print(joined)
结果为:

对上述数据稍加修改:
df1 = pd.DataFrame({
'Int_rate':[2, 3, 2, 2],
'US_GDP_Thousands':[50, 55, 65, 55],
'Year':[2001, 2002, 2003, 2004]
})
df3 = pd.DataFrame({
'Unemployment':[7, 8, 9, 6],
'Low_tier_HPI':[50, 52, 50, 53],
'Year':[2001, 2003, 2004, 2005]})
按照year合并得到:
merged = pd.merge(df1,df3, on='Year')
merged.set_index('Year', inplace=True)
print(merged)
结果为:

merge默认取的是交集,这就引出了另一个参数 "how", 通过对这个参数的定义, 可以选择以什么样的方式合并数据. 参数值有以下四种:
Left - 以左边的索引值为准.
Right - 以右边的索引值为准.
Outer - 取并集.
Inner - 取交集
这里展示outer效果:
merged = pd.merge(df1,df3, on='Year', how='outer')
merged.set_index('Year', inplace=True)
print(merged)
结果为:

取并集的时候, 有时可能会想要知道,某个数据是来自哪边, 可以通过 indicator 参数来获取:
df = pd.merge(df1, df2, on='city', how='outer', indicator=True)
会添加merge列,显示数据来自哪一个数据框
缺失值直接用NA填充。
此时用join效果和merge一致:
df1.set_index('Year', inplace=True)
df3.set_index('Year', inplace=True)
joined = df1.join(df3, how="outer")
print(joined)
结果为:
 2、生成dataframe方式
2、生成dataframe方式
更多可参考:IO Tools (Text, CSV, HDF5, ...) — pandas 0.22.0 documentation
#读取csv文件:
df = pd.read_csv("/Users/rachel/Downloads/weather.csv")
#读取excel文件:,末尾为sheet参数
df = pd.read_excel("/Users/rachel/Downloads/weather.xlsx", "weather")
#字典转换:
weather_data = {
'day': ['1/1/2017','1/2/2017','1/3/2017'],
'temperature': [32,35,28],
'windspeed': [6,7,2],
'event': ['Rain', 'Sunny', 'Snow']
}
df = pd.DataFrame(weather_data)
#元组转换:
weather_data = [
('1/1/2017',32,6,'Rain'),
('1/2/2017',35,7,'Sunny'),
('1/3/2017',28,2,'Snow')
]
df = pd.DataFrame(data=weather_data, columns=['day','temperature','windspeed','event'])
#列表转换:
weather_data = [
{'day': '1/1/2017', 'temperature': 32, 'windspeed': 6, 'event': 'Rain'},
{'day': '1/2/2017', 'temperature': 35, 'windspeed': 7, 'event': 'Sunny'},
{'day': '1/3/2017', 'temperature': 28, 'windspeed': 2, 'event': 'Snow'},
]
df = pd.DataFrame(data=weather_data, columns=['day','temperature','windspeed','event'])
#自行指定列名生成数据框
df=pd.DataFrame(columns=['a','b'])3、缺失值处理
new_df = df.fillna(method='ffill')#参考上一行的值填充
new_df = df.fillna(method='bfill')#参考下一行的值填充
new_df = df.fillna(method='bfill', axis='columns')#横向从右向左填充
new_df = df.fillna(method='ffill', axis='columns')#横向从左向右填充
new_df = df.interpolate()#取空值前后的中间值
new_df = df.dropna()#舍弃所有NA的行
new_df = df.dropna(how='all')#舍弃所有列都为空值的行
new_df = df.dropna(thresh=1)#保留至少有一个列有值的行,thresh=1至少有两个列有值的行
df['value'] = df.groupby('group')['value'].transform(lambda x: x.fillna(x.mean()))# 分组后用组内均值填充NA
df['value'] = df.groupby('group')['value'].transform(lambda x: x.fillna(x.mode()[0]))#分组后用组内众数填充NA值
#补足所缺的日期
dt = pd.date_range('2024-01-01', '2024-11-11')#设置日期范围
idx = pd.DatetimeIndex(dt)#重新定义索引
df = df.reindex(idx)4、replace函数
new_df = df.replace([-99999, -88888], np.NaN)#用na替代列表中的异常值
new_df = df.replace({'temperature' : -99999,'windspeed':[-99999, -88888],'event': '0'}, np.NaN)#用字典处理每一列中异常值
new_df = df.replace({'temperature': '[A-Za-z]','windspeed': '[A-Za-z]'} ,'', regex=True)#正则表达式+字典处理每一列值格式
df = pd.DataFrame({'score': ['exceptional', 'average', 'good', 'poor', 'average', 'exceptional'],
'student': ['rob', 'maya', 'jorge', 'tom', 'july', 'erica']})
new_df = df.replace(['poor', 'average', 'good', 'exceptional'], [1, 2, 3, 4])#指代功能

5、用pivot table做格式转换
import akshare as ak
code_list = ['000001','000002','000004','000005','000006','000007','000008']
df = pd.DataFrame(columns = ['date','code','open','high','low','close','volume'])
for code in code_list:
data = ak.stock_zh_a_hist(code, period="daily", start_date = '20231214', end_date = '20231219', adjust="qfq")
data = data[['日期','开盘','最高','最低','收盘','成交量']]# 选取日期、高开低收价格、成交量数据
data = data.rename(columns={'日期': 'date','开盘': 'open','最高': 'high','最低': 'low','收盘': 'close','成交量':'volume'})
data['code'] = code
df = pd.concat([df,data])
print(df)
原来:

格式转换:#格式转换, 设置 'date' 为索引列, 也就让'date' 做每一行的输出依据, 然后设置'code' 为每一列输出的依据,输出值为close
df.pivot(index='date', columns='code', values='close')
不指定输出值:
df.pivot(index='date', columns='code')
用 pivot table 来做整合:
df.pivot_table(index='date', columns='code', values='close')
对于 pivot_table() 函数, 可以通过第三个参数 'aggfun' 来做很多的变化:
适用于:如果某个变量在同一时刻有多个值:(上海在同一天温度有多个值,我需要统计)
df.pivot_table(index='city', columns='date', aggfunc='sum')#取和
df.pivot_table(index='city', columns='date', aggfunc='count')#计数
df.pivot_table(index='city', columns='date', aggfunc='diff')#求差异
df.pivot_table(index='city', columns='date', aggfunc='mean')#求均值
df.pivot_table(index='city', columns='date', margins=True)#横向纵向分别求和的平均值6、group by 用法
常用于替代循环操作
print(df.groupby('code')['close'].sum())#显示分组后某变量的特征
循环输出分组后的数据:
df1 = df.groupby('code')
for code, code_df in df1:
print(code)
print(code_df)
获取其中的某一组的数据:
df1.get_group('000001')
df1.min()#每一组的最小值
df1.max()#每一组的最大值
df1.describe()#每一组的描述
%matplotlib inline
df1.plot()#每一组数据分别画图
7、concat用法
将两个数据框进行拼接,数据分别来自两个 dataframe 的索引值, 可以通过忽略原本的索引来做改变:
按行拼接:
df = pd.concat([india_weather, us_weather], ignore_index=True)#会重置索引
df = pd.concat([india_weather, us_weather])将每个数据框设置关键字进行拼接(索引会保留),同时关键字也会成为索引:
df = pd.concat([india_weather, us_weather], keys=['india', 'us'])
df.loc['india']

按列拼接:
df = pd.concat([temperature_df, windspeed_df], axis=1)
当两个数据框的行数不同时,添加索引按列拼接:
temperature_df = pd.DataFrame({
'city': ['newyork', 'chicago', 'orlando'],
'temperature': [21, 24, 32],
}, index=[0, 1, 2])
windspeed_df = pd.DataFrame({
'city': ['chicago', 'newyork'],
'temperature': [12, 7],
}, index=[1, 0])
df = pd.concat([temperature_df, windspeed_df], axis=1)
df结果为(自动补全NA):

8、melt格式转换
宽数据框变窄数据框:id_vars=['code','date']是不进行转换的列,
df1 = pd.melt(df, id_vars=['code','date'])
df1变量是列名,结果为:

也可以自定义列名:
df1 = pd.melt(df, id_vars=['code','date'], var_name='var', value_name='price')
9、stack 和 unstack
字面意思就是"组成堆"和"解除堆"。其实, 也是对数据格式的一种转变方式:
模拟首先设置两个表头:
import akshare as ak
code_list = ['000001','000002','000004','000005','000006','000007','000008']
df = pd.DataFrame(columns = ['date','code','open','high','low','close','volume'])
for code in code_list:
data = ak.stock_zh_a_hist(code, period="daily", start_date = '20231218', end_date = '20231219', adjust="qfq")
data = data[['日期','开盘','最高','最低','收盘','成交量']]# 选取日期、高开低收价格、成交量数据
data = data.rename(columns={'日期': 'date','开盘': 'open','最高': 'high','最低': 'low','收盘': 'close','成交量':'volume'})
data['code'] = code
df = pd.concat([df,data])
columns = pd.MultiIndex.from_arrays([['date','code','code', 'code', 'volume','volume','volume'], ['date','code','open','high','low','close','volume']])
# 为DataFrame设定一级表头和二级表头
df.columns = columns
print(df.head(4))
df['code'].head(4)结果为:

实际数据df为:

df_stacked = df.stack()
df_stacked
原来的数据结构是有两行表头, 经过 stack 之后, 就变成一行了, 也就是 Facebook Google Microsoft 这一行, 从原来的列名, 变成了索引:

再 unstack:
df_stacked.unstack()
数据df2:

stack 一下:
df2.stack()结果为(第三行表头成为列索引):

设置参数 level=1:
df2.stack(level=1)
这次是第二行表头被 stack 了,结果为:
可以总结, stack 的作用就是可以将横向的表头(列名)转成纵向的索引列展示, 对于多行表头而言, 具体要转换哪一行取决于 level 参数, 如果不指定, 则默认转换最下面一行表头。
10、crosstab交叉列表取值
生成模拟数据:
import pandas as pd
import random
# 创建空的数据框
df = pd.DataFrame(columns=['name', 'nation', 'sex', 'age'])
# 生成8行数据
for i in range(8):
name = f"Person{i+1}"
nation = random.choice(['USA', 'China', 'Japan'])
sex = random.choice(['male', 'female'])
age = random.randint(18, 60)
# 检查name是否已经存在
while name in df['name']:
name = f"Person{i+1}"
# 添加数据到数据框
df.loc[i] = [name, nation, sex, age]
# 打印数据框
print(df)
数据如:

交叉表:
pd.crosstab(df.nation, df.sex)结果为:

crosstab 第一个参数是列, 第二个参数是行. 还可以添加第三个参数:
pd.crosstab(df.nation, df.sex, margins = True)#统计边缘总个数的
同时, 行和列都可以是复合的:
pd.crosstab(df.nation,[df.sex,df.age], margins = True)结果为:

交叉表还有其他很多强大功能:
import numpy as np
pd.crosstab(df.nation, df.sex, normalize='index')#百分比
pd.crosstab(df.nation, df.sex, values=df.age, aggfunc=np.average)#求平均值
从定义可以看到有很多方法:

11、datetimeindex 和resample
将字符型日期转换成日期格式并设置成索引
import akshare as ak
code_list = ['000001','000002','000004','000005','000006','000007','000008']
df = pd.DataFrame(columns = ['date','code','open','high','low','close','volume'])
for code in code_list:
data = ak.stock_zh_a_hist(code, period="daily", start_date = '20231211', end_date = '20231219', adjust="qfq")
data = data[['日期','开盘','最高','最低','收盘','成交量']]# 选取日期、高开低收价格、成交量数据
data = data.rename(columns={'日期': 'date','开盘': 'open','最高': 'high','最低': 'low','收盘': 'close','成交量':'volume'})
data['code'] = code
df = pd.concat([df,data])
print(df.head(3))
df['date'] = pd.to_datetime(df['date'])
df=df.set_index('date')
print(df.head(3))
type(df.index)结果为:

有了日期可以灵活运用:
df[df.index=='2023-12-11'].close.mean()结果为:

下面来看下关于 resample() 函数的使用:
df.close.resample('d').mean()首先我们要获取所有的闭市数据, 在这个数据基础上又通过 resample() 函数加以加工, 函数里传的参数是 D, 就是 Day 的缩写, 也就是我们要以天为单位, 也就是说要每个整天的数据, 那要每个天的什么值, 这个是必须要指定的, 否则计算机不知道是返回每个月的合计,还是最小值, 还是平均值等等, 所以后面用了 mean(), 也就是说要取平均值。还可以画图:
df.close.resample('D').mean().plot()
12、设置交易日历date_range和asfreq
rng = pd.date_range(start='1/1/2024', end='1/31/2024', freq='B')#只取工作日
rng = pd.date_range(start='1/1/2017', periods=72, freq='B')#另外一种方式设置交易日历 # H 为小时
df.set_index(rng, inplace=True)#设置成交日历索引日期序列的补充函数 asfreq().上面的例子数据里缺少了周末的数据, 所以如果想要补充这部分数据的话, 可以用下面的方式.:
df.asfreq('D', method='pad') #W为周参数 D 表示以"天"为单位, 连续取值
13、redis
Redis 的含义: REmote DIctionary Server 远程词典服务器;由于支持 string, list, set, ordered set, hash 等多重数据结构, 因此, 经常被称作数据结构服务器.
Redis 的特点:开源;以 key-value 形式存在;存储在内存中;支持持久化;用底层是C语言;;非关系型数据库(同为非关系型数据库的还有 MongoDB, memcached, CouchDB)
用途:非关系数据库;缓存;信息订阅(message broker)
下载传送门:Releases · tporadowski/redis (github.com)下载zip格式的
下载后解压到指定位置如:C:\Users\59980\redis
命令行进入该目录下,输入:启动redis服务
redis-server.exe redis.windows.conf
默认端口为6379,出现图上的图标说明redis服务启动成功。命令里面的 redis.windows.conf 可以省略,省略后,使用redis-server.exe命令会使用默认的配置。
建议把redis目录添加到环境变量中,就比较方便了。
此时不要关闭上面窗口,重新开个cmd窗口,输入以下命令配置
用redis-cli.exe命令来打开Redis客户端:
redis-cli.exe -h 127.0.0.1 -p 6379显示:

再输入:
ping
至此连接成功,到此Redis的安装和部署也就完成了。
Redis默认拥有16个数据库,初始默认使用0号库,在命令行中通过select命令将数据库切换到8号数据库:
select 8 
在命令中通过set命令设置键值,通过get命令取出键值:
set key hello
get key
在命令中通过shutdown命令来关闭redis服务:

同时启动窗口会出现提示:

Redis常用的服务指令
卸载服务:redis-server --service-uninstall
开启服务:redis-server --service-start
停止服务:redis-server --service-stop
可视化工具有:RedisStudio;treeNMS
redis 的数据结构就是一系列的键值对
键 -> printable ASCII (可打印的 ASCII 码, 最大值是 512MB)
值 ->
- Primitives (基本的)
- string 字符串 (最大值是 512MB)
- Containers (of string) (以其他形式包裹的字符串)
- hash (哈希)
- list (序列)
- set (集合)
- ordered set (有序集合)

获取所有键:
keys *
删除一条数据:
del key
更新某个键的值:
set hello world
get hello
set hello wrold?
get hello
一次性删除所有数据:
flushall介绍一些进阶命令:
清理终端:
clear
设置一个键值对, 同时设置过期时间为10秒:
setex name 10 max
get name
"max"查看剩余的过期时间:
127.0.0.1:6379> ttl name
(integer) 4
127.0.0.1:6379> ttl name
(integer) 0
127.0.0.1:6379> get name
(nil)
设置一个键值对, 同时设置过期时间为30000毫秒, 注意, 使用 psetex 设置过期时间, 时间的单位为毫秒:
127.0.0.1:6379> psetex name3 30000 july
OK
127.0.0.1:6379> ttl name3
(integer) 26
设置一个键值对, 但是想要确认这个键是否已被占用, 可以用 setnx, 如果已经被占用, 则返回0, 即没有执行成功:
127.0.0.1:6379> set name tom
OK
127.0.0.1:6379> setnx name join
(integer) 0
127.0.0.1:6379> get name
"tom"
如果未被占用, 则返回1, 即操作成功:
127.0.0.1:6379> setnx name2 join
(integer) 1
127.0.0.1:6379> get name2
"join"
127.0.0.1:6379> keys *
1) "name2"
2) "name"
获取值的字符串长度:
127.0.0.1:6379> get name
"tom"
127.0.0.1:6379> strlen name
(integer) 3
127.0.0.1:6379> get name2
"join"
127.0.0.1:6379> strlen name2
(integer) 4
同时设置多个键值对, 这里故意设置了两个 num2 的值, 可以看到会存入后者:
127.0.0.1:6379> mset num1 40 num2 60 num2 70
OK
127.0.0.1:6379> keys *
1) "name"
2) "name2"
3) "num1"
4) "num2"
127.0.0.1:6379> get num2
"70"
以 1 为单位, 增加/减少值:
127.0.0.1:6379> get num1
"40"
127.0.0.1:6379> decr num1
(integer) 39
127.0.0.1:6379> get num1
"39"
127.0.0.1:6379> incr num1
(integer) 40
127.0.0.1:6379> get num1
"40"
增加/减少值, 但是可以自定义每次增加/减少的量:
127.0.0.1:6379> incrby num1 5
(integer) 45
127.0.0.1:6379> get num1
"45"
127.0.0.1:6379> decrby num1 10
(integer) 35
127.0.0.1:6379> get num1
"35"
附加拼接命令:
127.0.0.1:6379> set mykey hello
OK
127.0.0.1:6379> get mykey
"hello"
127.0.0.1:6379> append mykey " world"
(integer) 16
127.0.0.1:6379> get mykey
"hello world"哈希值:
redis 存储的是键值对, 键永远都是可以打印的 ASCII 码, 值是字符串, 或者是以其他形式包裹的字符串. 上面介绍了单纯字符串值的相关命令, 现在开始接触第一个所谓的"以其他形式包裹的字符串" --- 哈希值,下图中哈希值的部分, 一共有4行, 可以看作是一个数组, 里面包含了4个元素, 再看每一个元素(也就是每一行)都有一个 field 与 value 对应, 可以看作是一个映射(map). 总结哈希值的数据结构就是数组包含映射(list > map, 这是从 python 的角度理解的, 如果从 php 的角度, 我觉得有点像是一个二维数组)

设置一条哈希数据存储:
127.0.0.1:6379> hmset stu-1 name max age 16 sex male
OK
获取值中的某个字段, 要指定字段名:
127.0.0.1:6379> hget stu-1 name
"max"
获取某个键的哈希值的指定字段的值:
127.0.0.1:6379> hmget stu-1 name
1) "max"
127.0.0.1:6379> hmget stu-1 name age
1) "max"
2) "18"
获取全部的哈希值:
127.0.0.1:6379> hgetall stu-1
1) "name"
2) "max"
3) "age"
4) "16"
5) "sex"
6) "male"
判断某个键的哈希值的某个字段是否存在:
127.0.0.1:6379> hexists stu-1 surname
(integer) 0
127.0.0.1:6379> hexists stu-1 name
(integer) 1
删除某个键的哈希值的某个字段:
127.0.0.1:6379> hdel stu-1 sex
(integer) 1
127.0.0.1:6379> hgetall stu-1
1) "name"
2) "max"
3) "age"
4) "16"
设置某个键的哈希值的某个字段:
127.0.0.1:6379> hmset stu-1 sex male
OK
127.0.0.1:6379> hgetall stu-1
1) "name"
2) "max"
3) "age"
4) "16"
5) "sex"
6) "male"
设置某个键的哈希值的某个字段前, 先判断这个字段是否可用, 如果可用则返回1, 表示设置成功, 如果不可用则返回0, 表示设置失败:
127.0.0.1:6379> hsetnx stu-1 name tom
(integer) 0
127.0.0.1:6379> hsetnx stu-1 surname tom
(integer) 1
127.0.0.1:6379> hsetnx stu-1 class 3
(integer) 1
127.0.0.1:6379> hgetall stu-1
1) "name"
2) "max"
3) "age"
4) "16"
5) "sex"
6) "male"
7) "class"
8) "3"
9) "surname"
10) "tom"
判断某个键的哈希值的某个字段是否存在, 如果存在则返回1:
127.0.0.1:6379> hexists stu-1 class
(integer) 1
127.0.0.1:6379> hget stu-1 class
"3"
获取某个键的所有字段名:
127.0.0.1:6379> hkeys stu-1
1) "name"
2) "age"
3) "sex"
4) "class"
5) "surname"
获取某个键的所有字段的值:
127.0.0.1:6379> hvals stu-1
1) "max"
2) "16"
3) "male"
4) "3"
5) "tom"
以自定义的幅度, 增加某个键的哈希值的某个字段的值:
127.0.0.1:6379> hincrby stu-1 age 2
(integer) 18
127.0.0.1:6379> hgetall stu-1
1) "name"
2) "max"
3) "age"
4) "18"
5) "sex"
6) "male"
7) "class"
8) "3"
9) "surname"
10) "tom"
查看某个键的哈希值一共有几个字段:
127.0.0.1:6379> hlen stu-1
(integer) 5
以上, 就是关于哈希值的基本命令
list值:
list 值就是一组根据插入顺序排列的字符串, 从左向右排列, 左边为头(head), 右侧为尾(tail). 左边为顶部, 右边为底部.
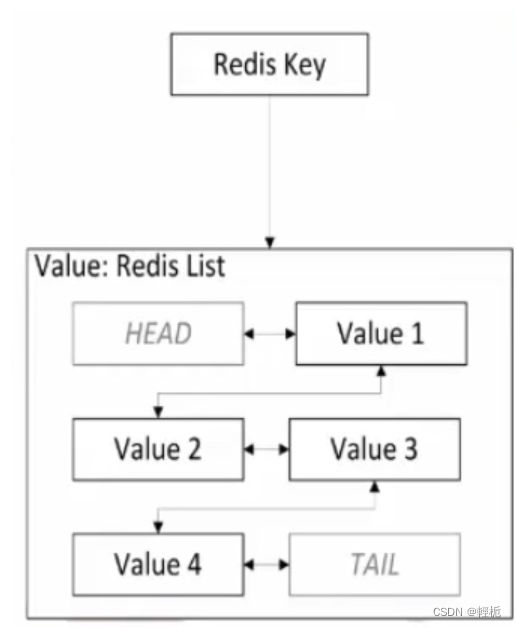
从左侧开始向键为 num 的 list 插入数据:
127.0.0.1:6379> lpush num 1 2 3 4
(integer) 4
查看 num 里的数据, 因为数据是从左侧开始插入, 并且插入的先后顺序是从1到4, 所以1在最底层, 4在最顶层:
127.0.0.1:6379> lrange num 0 10
1) "4"
2) "3"
3) "2"
4) "1"
再从左侧插入一个数据:
127.0.0.1:6379> lpush num 5
(integer) 5
127.0.0.1:6379> lrange num 0 10
1) "5"
2) "4"
3) "3"
4) "2"
5) "1"
从左侧弹出一个数据, 因为5在最顶层, 所以最先弹出:
127.0.0.1:6379> lpop num
"5"
127.0.0.1:6379> lrange num 0 10
1) "4"
2) "3"
3) "2"
4) "1"
从右侧插入数据:
127.0.0.1:6379> rpush num 5
(integer) 5
127.0.0.1:6379> lrange num 0 10
1) "4"
2) "3"
3) "2"
4) "1"
5) "5"
127.0.0.1:6379> rpush num 6
(integer) 6
127.0.0.1:6379> lrange num 0 10
1) "4"
2) "3"
3) "2"
4) "1"
5) "5"
6) "6"
从右侧弹出数据:
127.0.0.1:6379> rpop num
"6"
127.0.0.1:6379> lrange num 0 10
1) "4"
2) "3"
3) "2"
4) "1"
5) "5"
查看一个 list 的长度:
127.0.0.1:6379> lrange num 0 10
1) "4"
2) "3"
3) "2"
4) "1"
5) "5"
127.0.0.1:6379> llen num
(integer) 5
根据索引查看 list 中某个位置的值:
127.0.0.1:6379> lindex num 3
"1"
127.0.0.1:6379> lindex num 0
"4"
根据索引修改 list 中某个位置的值:
127.0.0.1:6379> lset num 0 8
OK
127.0.0.1:6379> lrange num 0 10
1) "8"
2) "3"
3) "2"
4) "1"
5) "5"
在未知 list 长度的情况下, 可以使用 0 -1 的范围来查看 list 中的所有值:
127.0.0.1:6379> lrange num 0 -1
1) "8"
2) "3"
3) "2"
4) "1"
5) "5"
在插入数据之前, 先检查指定的键是否存在, 如果存在则插入, 如果不存在, 则返回0. 用这个命令插入, 一次只能插入一个值, 多个会报错:
127.0.0.1:6379> lpushx num 9
(integer) 6
127.0.0.1:6379> lrange num 0 -1
1) "9"
2) "8"
3) "3"
4) "2"
5) "1"
6) "5"
127.0.0.1:6379> lpushx sub 9
(integer) 0
在 list 中间的某个位置插入数据, 可以用 linsert 命令, 借助关键字 before 和 after 确定位置:
127.0.0.1:6379> lrange num 0 -1
1) "5"
2) "1"
3) "2"
4) "3"
5) "8"
6) "9"
127.0.0.1:6379> linsert num before 8 55
(integer) 7
127.0.0.1:6379> lrange num 0 -1
1) "5"
2) "1"
3) "2"
4) "3"
5) "55"
6) "8"
7) "9"
127.0.0.1:6379> linsert num after 1 66
(integer) 8
127.0.0.1:6379> lrange num 0 -1
1) "5"
2) "1"
3) "66"
4) "2"
5) "3"
6) "55"
7) "8"
8) "9"
以上, 就是关于 list值的相关命令
set值:
set值是唯一的字符串的无序集合, 把握住两个特点: 唯一, 无序.
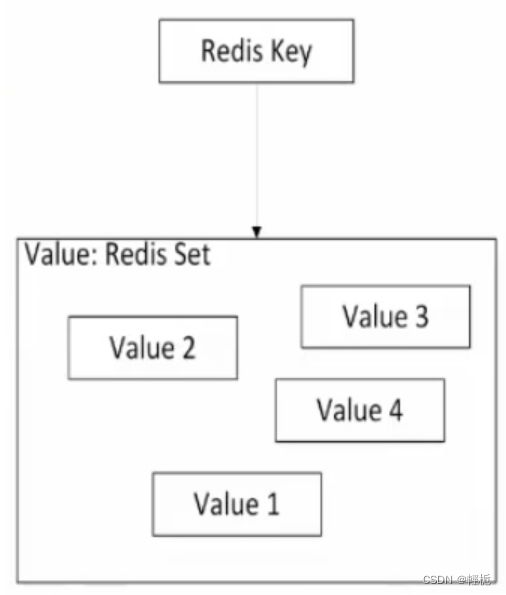
清空所有的数据, 并清理显示界面:
127.0.0.1:6379> flushall
OK
127.0.0.1:6379> clear
保存一条 set 数据, 键是 myset1, 值是 1, 2, 3, 4 四个数字:
127.0.0.1:6379> sadd myset1 1 2 3 4
(integer) 4
查看键myset1 的值:
127.0.0.1:6379> smembers myset1
1) "1"
2) "2"
3) "3"
4) "4"
在键myset1里增加一个已有的数字3, 返回0, 表示添加不成功, 因为 set值是要求唯一的:
127.0.0.1:6379> sadd myset1 3
(integer) 0
127.0.0.1:6379> smembers myset1
1) "1"
2) "2"
3) "3"
4) "4"
在键myset1里增加一个新数字5, 返回1, 表示添加成功:
127.0.0.1:6379> sadd myset1 5
(integer) 1
127.0.0.1:6379> smembers myset1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
查看键myset1的值里一共有几天数据:
127.0.0.1:6379> scard myset1
(integer) 5
新增一条 set 数据myset2:
127.0.0.1:6379> sadd myset2 5 8 7 6 4 9
(integer) 6
127.0.0.1:6379> smembers myset2
1) "4"
2) "5"
3) "6"
4) "7"
5) "8"
6) "9"
查看两条 set 数据 myset1 和 myset2 值的区别, myset1 写在前面, 表示查出所有 myset1 里有, 而 myset2 里没有的值:
127.0.0.1:6379> smembers myset1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
127.0.0.1:6379> sdiff myset1 myset2
1) "1"
2) "2"
3) "3"
查出 myset1 相对于 myset2 里值的差别, 并且保存成一个新 set --- myset3:
127.0.0.1:6379> sdiffstore myset3 myset1 myset2
(integer) 3
127.0.0.1:6379> smembers myset3
1) "1"
2) "2"
3) "3"
合并 myset1 和 myset2 里的所有值, 由于 set值唯一性的特点, 重复的部分只保留一个:
127.0.0.1:6379> sunion myset1 myset2
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "8"
9) "9"
合并 myset1 和 myset2 里的所有值, 并且保存成一个新 set --- myset4:
127.0.0.1:6379> sunionstore myset4 myset1 myset2
(integer) 9
127.0.0.1:6379> smembers myset4
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "8"
9) "9"
指定删除 set值里的某一个数
127.0.0.1:6379> srem myset4 8
(integer) 1
127.0.0.1:6379> smembers myset4
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
7) "7"
8) "9"
指定删除 set值里的某几个数
127.0.0.1:6379> srem myset4 6 7 9
(integer) 3
127.0.0.1:6379> smembers myset4
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
随机删除 set值里的某一个数
127.0.0.1:6379> spop myset4 1
1) "5"
127.0.0.1:6379> smembers myset4
1) "1"
2) "2"
3) "3"
4) "4"
随机删除 set值里的某几个数
127.0.0.1:6379> spop myset4 3
1) "2"
2) "4"
3) "1"
取两个 set值的并集:
127.0.0.1:6379> smembers myset1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
127.0.0.1:6379> smembers myset2
1) "4"
2) "5"
3) "6"
4) "7"
5) "8"
6) "9"
127.0.0.1:6379> sinter myset1 myset2
1) "4"
2) "5"
取两个 set值的并集, 并保存:
127.0.0.1:6379> sinterstore myset5 myset1 myset2
(integer) 2
127.0.0.1:6379> smembers myset5
1) "4"
2) "5"
把 myset1 的值里的数字 1 挪到 myset2
127.0.0.1:6379> smove myset1 myset2 1
(integer) 1
127.0.0.1:6379> smembers myset2
1) "1"
2) "4"
3) "5"
4) "6"
5) "7"
6) "8"
7) "9"
127.0.0.1:6379> smembers myset1
1) "2"
2) "3"
3) "4"
4) "5"
以上就是关于 set值的一些常用命令
ordered set 值:
ordered set 是根据 score值有序排列的数据集合

新建一条 ordered set 数据 myset1, 并存入4个字符串, score 的排列顺序为1-4:
127.0.0.1:6379> zadd myset1 1 a 2 b 3 c 4 d
(integer) 4
查看这个数据:
127.0.0.1:6379> zrange myset1 0 -1
1) "a"
2) "b"
3) "c"
4) "d"
给 myset1 的值里新加一个字符e, score=100:
127.0.0.1:6379> zadd myset1 100 e
(integer) 1
查看最新的 myset1 的值:
127.0.0.1:6379> zrange myset1 0 -1
1) "a"
2) "b"
3) "c"
4) "d"
5) "e"
查看 myset1 的值里一共有几条数据:
127.0.0.1:6379> zcard myset1
(integer) 5
根据指定的 score 的范围查看 myset1 的值里一共有几条数据:
127.0.0.1:6379> zcount myset1 1 3
(integer) 3
127.0.0.1:6379> zcount myset1 1 5
(integer) 4
127.0.0.1:6379> zcount myset1 1 55
(integer) 4
127.0.0.1:6379> zcount myset1 1 101
(integer) 5
127.0.0.1:6379> zcount myset1 1 100
(integer) 5
127.0.0.1:6379> zcount myset1 1 99
(integer) 4
删除 myset1 值里的某个数据:
127.0.0.1:6379> zrem myset1 b
(integer) 1
127.0.0.1:6379> zrange myset1 0 -1
1) "a"
2) "c"
3) "d"
4) "e"
127.0.0.1:6379> zrem myset1 d
(integer) 1
127.0.0.1:6379> zrange myset1 0 -1
1) "a"
2) "c"
3) "e"
查看某个数据的索引值:
127.0.0.1:6379> zrank myset1 e
(integer) 2
127.0.0.1:6379> zrank myset1 a
(integer) 0
反排序后查询索引:
127.0.0.1:6379> zrevrank myset1 a
(integer) 2
127.0.0.1:6379> zrevrank myset1 e
(integer) 0
查询 score值, 没有的返回 nil:
127.0.0.1:6379> zscore myset1 e
"100"
127.0.0.1:6379> zscore myset1 a
"1"
127.0.0.1:6379> zscore myset1 jsjs
(nil)
支持对同一个 score值设置多个不同的数据:
127.0.0.1:6379> zrange myset1 0 -1
1) "a"
2) "c"
3) "e"
127.0.0.1:6379> zadd myset1 1 aaaa
(integer) 1
127.0.0.1:6379> zrange myset1 0 -1
1) "a"
2) "aaaa"
3) "c"
4) "e"
127.0.0.1:6379> zadd myset1 1 bbbb
(integer) 1
127.0.0.1:6379> zrange myset1 0 -1
1) "a"
2) "aaaa"
3) "bbbb"
4) "c"
5) "e"
查询 score值, 再次证明 ordered set 支持对同一个 score值设置多个不同的数据:
127.0.0.1:6379> zscore myset1 a
"1"
127.0.0.1:6379> zscore myset1 aaaa
"1"
127.0.0.1:6379> zscore myset1 bbbb
"1"
查询索引:
127.0.0.1:6379> zrank myset1 a
(integer) 0
127.0.0.1:6379> zrank myset1 aaaa
(integer) 1
127.0.0.1:6379> zrank myset1 bbbb
(integer) 2
根据指定的 score值的范围查出数据:
127.0.0.1:6379> zrangebyscore myset1 1 2
1) "a"
2) "aaaa"
3) "bbbb"
127.0.0.1:6379> zrangebyscore myset1 1 4
1) "a"
2) "aaaa"
3) "bbbb"
4) "c"
以上就是关于 ordered set 的相关命令
publish subscribe 消息订阅:
在窗口1开通一个名为 redis 的通道:
127.0.0.1:6379> SUBSCRIBE redis
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "redis"
3) (integer) 1
从窗口2传入信息:
127.0.0.1:6379> PUBLISH redis hi
(integer) 1
此时窗口1会收到这条信息:
127.0.0.1:6379> SUBSCRIBE redis
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "redis"
3) (integer) 1
1) "message"
2) "redis"
3) "hi"
以上, 就是通过 SUBSCRIBE 和 PUBLISH 实现了一个简单的消息传递的过程. 目前是有一个窗口开通 redis 通道, 另一个窗口向这个通道传递消息, 大家可以试下再多开一个窗口, 也开通 redis 通道, 然后再向 redis 通道传递消息的时候, 会发现, 这两个通道会同时接收到这条消息.
下面再另开一个窗口, 演示另外一个命令. 这里用命令 PSUBSCRIBE 开通一个通道, 通道名不是具体的, 而是有点像正则匹配, 即凡是向以字母 r 开头的通道发送消息, 这个通道都可以接收:
127.0.0.1:6379> PSUBSCRIBE r*
Reading messages... (press Ctrl-C to quit)
1) "psubscribe"
2) "r*"
3) (integer) 1
这时, 在另外一个窗口执行:
127.0.0.1:6379> PUBLISH rr "hi"
(integer) 1
这时, 在刚刚开通通道的窗口就可以接收到信息:
127.0.0.1:6379> PSUBSCRIBE r*
Reading messages... (press Ctrl-C to quit)
1) "psubscribe"
2) "r*"
3) (integer) 1
1) "pmessage"
2) "r*"
3) "rr"
4) "hi"
以上, 就是关于 SUBSCRIBE 和 PUBLISH 的基本原理。