【数据结构】单向链表的模拟实现
目录
1、ArrayList存在的缺陷
2、链表
2.1、链表的分类
2.1.1、单向带头非循环
2.1.2、单项不带头非循环
3、链表的模拟实现
3.1、定义类(MySingleList)
3.2、了解每个结点是如何串起来的
3.3、遍历输出链表
3.4、查找关键字key是否在单链表当中
3.5、计算链表的长度
3.6、头插法
3.7、尾插法
3.8、任意位置插入元素
3.9、删除第一次出现关键字为key的结点
3.10、删除所有key的节点
3.11、回收链表的每一个节点
1、ArrayList存在的缺陷
在顺序表的博客中写道了,ArrayList任意位置插入或者删除元素时,就需要将后续元素整体往前后者往后移动,时间复杂度为O(N)、效率比较低,因此ArrayList不适合做任意位置的插入和删除比较多的场景。这一问题Java集合当中引入了LinkedList,即链表结构来解决这个问题。
2、链表
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。

2.1、链表的分类
链表至少有8中分类
单向带头循环、单项带头非循环、单项不带头循环、单项不带头非循环、双向带头循环、双向带头非循环、双向不带头循环、双向不带头非循环。
我们主要学习:单项不带头非循环和双向不带头非循环。
这篇博客主要学习的是单向的链表
2.1.1、单向带头非循环

2.1.2、单项不带头非循环

❗❗❗ 总结:
- 链表的物理存储结构上不一定是连续,但是在逻辑上是连续的。
- 链表有两个域,数据域和指针域,两者组成一个模块,称为结点。
- 链表通过结点的指针域将结点链接在一起,形成链表。

3、链表的模拟实现
3.1、定义类(MySingleList)
定义一个MySingleList类,在其内部实现一个类Node(内部类)。内部类在这里的作用是,链表当中的结点,链表当中有结点,也有head头节点。
public class MySingleList {//链表
//定义一个内部类
class Node{//结点
public int val;//存储数据
public Node next;//存储下一个节点的地址
public Node(int val) {
this.val = val;//这里给next定义参数,因为在定义一个新的结点的时候,我们不知道下一个节点的地址是什么。
}
}
public Node head;//代表当前链表的头节点的引用,head头节点,他还是结点,所以还是用Node作为类型
}
3.2、了解每个结点是如何串起来的
来开一个方法
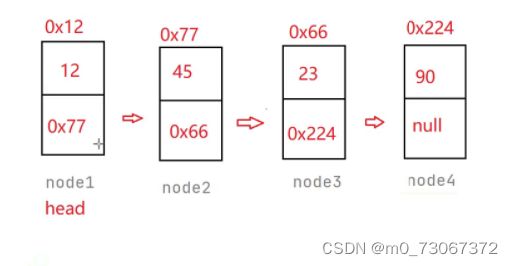
public void createLink(){
Node node1 = new Node(12);
Node node2 = new Node(45);
Node node3 = new Node(23);
Node node4 = new Node(90);//初始化结点,并给每个节点的val域赋值。
node1.next = node2;//将后一个结点的地址,赋值给前一个结点的next域
node2.next = node3;
node3.next = node4;
head = node1;//将node1传给head,那么node1为链表的头节点
//这里加一个头节点的一个作用是,遍历的链表的时候可以通过head来遍历。
}
3.3、遍历输出链表
❓❓❓这里有一个疑问,遍历链表,通过头节点遍历,那么头节点如何向后移动???
✨也很简单,通过head = head.next;这句代码就可以实现,head头节点的后移。
public void display(){
while (head!=null){
System.out.print(head.val+" ");
head = head.next;//通过这句代码实现了,head的后移,也就实现了遍历链表
}
System.out.println();//换行
}
在个方法中,while循环当中的判断条件,很多人会写成 head.next != null; 这样写会导致单向的非循环链表的最后一个结点,数字不能输出。
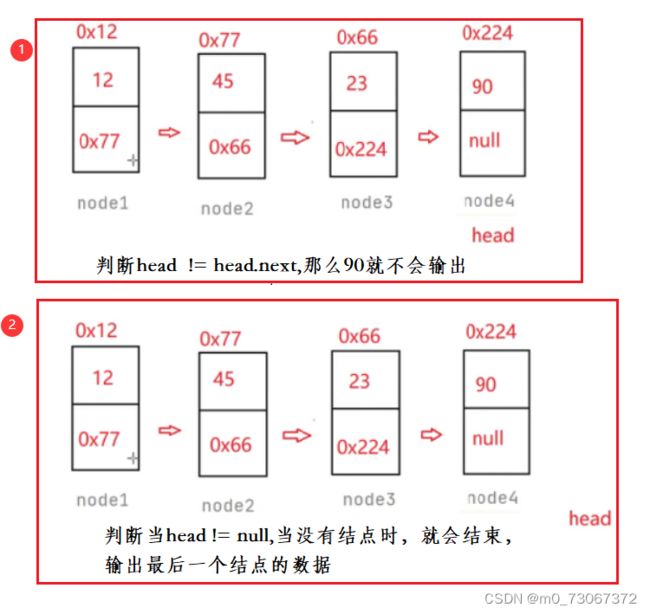
❗❗❗ 总结:
- 如果要遍历完链表的每个元素,那么判断时就需要使用head != null;
- 如果要遍历到链表的最后一个元素,那么判断时就需要使用head.next != null;
❓❓❓ 但是上述代码还有一个问题,就是在你打印完一遍链表之后,想要打印第二遍的时候,第二遍没有结果。
那么这个问题要如何解决。
我们可以不让head在遍历的时候跑,我们可以定义一个变量,来实现代跑,这样就解决了这个问题,在第二次遍历的时候,可以回到链表的头节点。
public void display(){
Node cur = head;//将head的值传给cur,让cur代替head来实现代跑,那么每次遍历完链表后,下次遍历可以回到开头
while (cur!=null){
System.out.print(cur.val+" ");
cur = cur.next;
}
System.out.println();//换行
}
3.4、查找关键字key是否在单链表当中
public boolean contains(int key){
Node cur = head;//通过cur带跑,遍历链表
while(cur != null){//结束条件,当将链表每个元素都便利完成,代码结束
if(cur.val == key){//判断cur结点的数据是否和查找的相同。
//当在比较的时候,是引用类型的时候,我们使用equals方法进行比较,时基本数据类型的时候,我们可以使用==进行比较。
return true;
}
cur = cur.next;//不同继续向后序结点遍历
}
return false;//遍历完成之后没有该关键字,返回false.
}
}
3.5、计算链表的长度
有两种方法
- 第一种:我们可以在定义类的时候,定义一个属性size,用来记录节点的个数,新增一个结点++,删除一个结点--。这种方法的时间复杂度时O(1);
- 第二种:写个计数方法,来计算节点的个数,也就是计算链表的长度。这种方法的时间复杂度为O(n);
public int size(){
int count = 0;//定义count用来计数
Node cur = head;
while (cur != null){
count++;
cur = cur.next;
}
return count;
}3.6、头插法
✨头插法的思路:
- 要插入结点,首先得有结点。通过实例化,创建节点。
- 在进行插入。
- 修改头节点。
public void addFirst(int data){
Node node = new Node(data);//实例化结点
//这两句代码的循序不能颠倒。
node.next = head;
head = node;
}画图解释

3.7、尾插法
✨尾插法的思路:
- 首先要有一个结点,通过实例化来得到。
- 再判断链表是否为空,为空则让头节点直接等于新增结点。
- 若不为空,找到当前链表的最后一个结点。
- 再修改原本链表的最后一个结点的next域,将新节点的地址传给最后一个结点的next域。
public void addLast(int data){
Node node = new Node(data);
if(head == null){//判断链表是否为空,若为空,插入时,直接让其等于新增的结点
head = node;//若不判断,那么当链表为空时,再进行while循环的时候,进行的判断会报空指针异常。
return;
}
Node cur = head;
while(cur.next != null){
cur = cur.next;
}
cur.next = node;
}
}
✨ 测试尾插法:
1、链表不为空的情况
public class Test {
public static void main(String[] args) {
MySingleList mySingleList = new MySingleList();
mySingleList.createLink();
mySingleList.addLast(10);
mySingleList.addLast(20);
mySingleList.addLast(30);
mySingleList.display();
}
}
2、链表为空的情况
public class Test {
public static void main(String[] args) {
MySingleList mySingleList = new MySingleList();
System.out.println("=====测试尾插======");
mySingleList.addLast(10);
mySingleList.addLast(20);
mySingleList.addLast(30);
mySingleList.display();
}
}
❗❗❗ 总结:尾插法的时间复杂度是O(n),因为他有找尾巴的过程。
链表的插入只是修改指向。
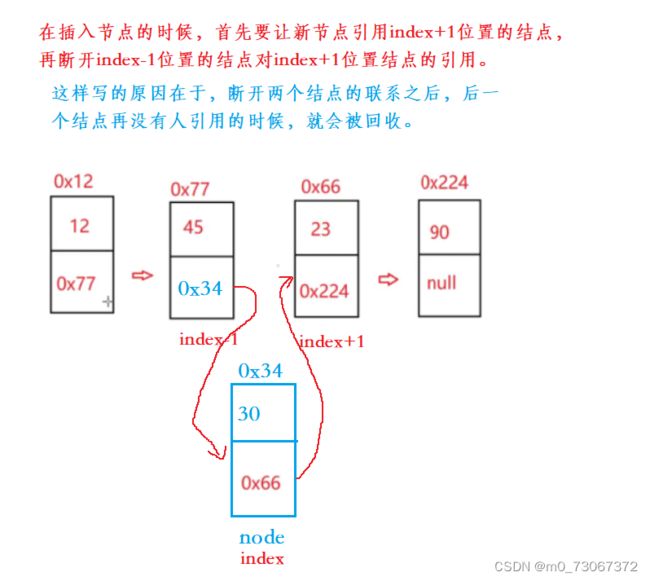
3.8、任意位置插入元素
✨思路:
- 首先判断要插入的位置(index),是否合法,若如何法,报异常。
- 再判断要插入的结点,是否在链表的开头或者结尾,若是,将调用头插法和尾插法
- 再找到要插入位置的前一个位置。
- 再将新的结点插入。
public void addIndex(int index,int data){
checkIndex(index);//在插入之前先判断,index是否合法
if(index == 0){//如果在链表的开头插入
addFirst(data);//调用头插法
return;
}
if(index == size()){//如果在链表的结尾插入
addLast(data);//调用尾插法
return;
}
Node cur = findIndexSubOne(index);//调用findIndexSubOne方法,找到index-1位置
Node node = new Node(data);
//将结点插入链表之后,先要和插入结点的后一个结点建立联系。
node.next = cur.next;//这里的cur.next域node.next表示的都是cur的地址域
cur.next = node;
}
/*
* 找到index-1位置的结点的地址
* */
private Node findIndexSubOne(int index){
Node cur = head;
int count = 0;
while(count != index -1){//判断是否为index前一个位置的结点
cur = cur.next;//不是,向后移动,找index位置的前一个位置的结点
count++;
}
return cur;
}
//判断index位置是否合法
private void checkIndex(int index){
if(index < 0 || index > size()){
throw new IndexOutOfException("Index位置不合法");
}
}
/*
*异常类
*/
public class IndexOutOfException extends RuntimeException{
public IndexOutOfException(){
}
public IndexOutOfException(String message){
super(message);
}
}
画图理解
✨测试插入方法

可以在Test类当中通过try...catch来解决这个问题
public class Test {
public static void main(String[] args) {
MySingleList mySingleList = new MySingleList();
System.out.println("===测试插入===");
mySingleList.addLast(1);
mySingleList.addLast(2);
mySingleList.addLast(3);
mySingleList.addLast(4);
try{
mySingleList.addIndex(12,99);
}catch(IndexOutOfException e){
e.printStackTrace();
}
mySingleList.display();

try...catch部分的内容不会输出,也不会影响其他内容的输出
3.9、删除第一次出现关键字为key的结点
✨思路:
- 判断当要删除的节点是链表的第一个节点,将头节点向后移,删除第一个节点。
- 要删除的节点不是第一个节点,那么通过searchPrev方法查找key的前一个结点。
- 在将要删除的数字所对应的结点删除。
/*
* 删除第一次出现关键字为key的节点
* */
public void remove(int key){
if(head.val == key){
head = head.next;
return;
}
Node cur = searchPrev(key);//通过这个找key数据所对应的结点的前驱
if(cur == null){//这里的判断,表示没有要删除的节点
return;
}
Node del = cur.next;//记录要删除的节点
cur.next = del.next;
}
/*
* 找到关键字的前一个结点
* */
private Node searchPrev(int key){
if(head == null){//这个判断是必要的,没有这个判断,在进行下面的操作时,会报空指针异常
return null;//说明链表当中一个节点都没有
}
Node cur = head;
while(cur.next != null){//当cur.next等于null时,说明这个链表当中没有要找的关键字
if(cur.next.val == key){//cur将来是key的前驱节点。
return cur;
}
cur = cur.next;
}
return null;//代表没有你要删除的节点
}
3.10、删除所有key的节点
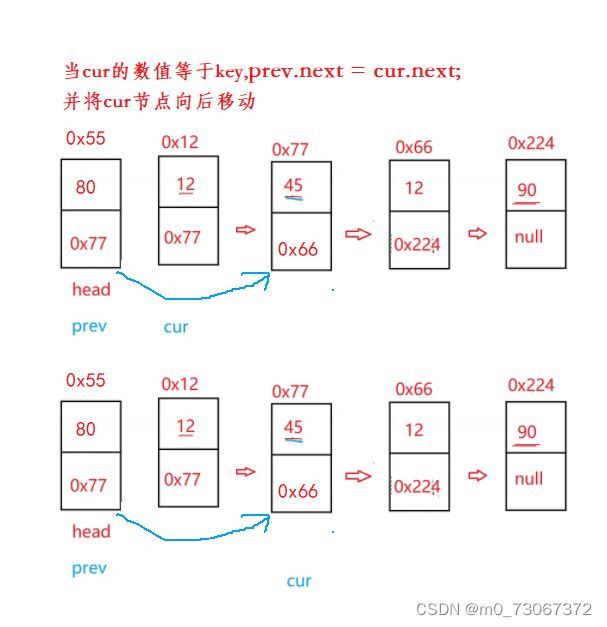
✨主要思路:
- 将cur节点当作要删除的节点,prev节点为要删除的前一个节点。
- 当链表不为空链表时,节点删除的时候有两种情况,为cur节点的值等于key;cur节点的值不等于key.
- 当第一个cur节点的值等于key时,让cur节点的前一个结点prev的地址域,等于cur节点的地址域,让prev节点指向cur节点的后一个节点。
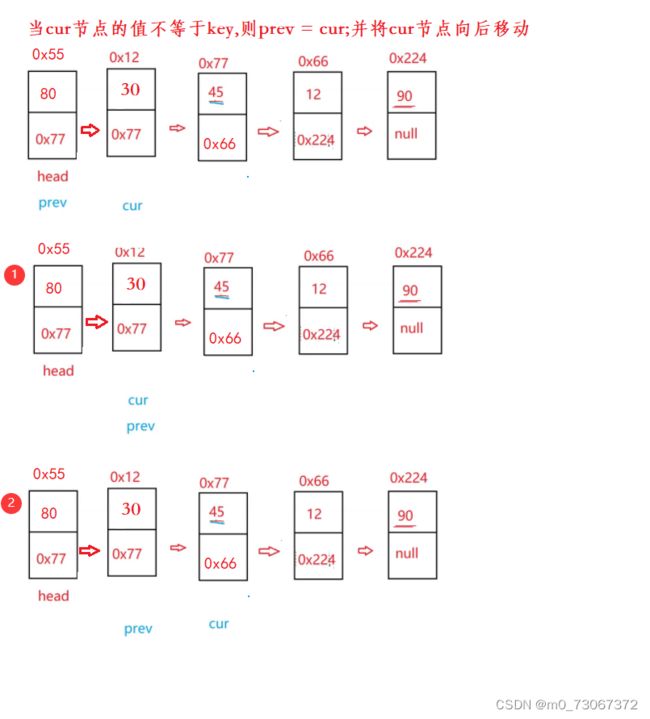
- 删除一个key值对应的cur节点后,cur向后移动,查找链表当中是否还有key值对应的cur节点。
- 当第一个cur节点的值不等于key时,那么就需要cur向后移动,继续寻找。所以他的操作为,将先将prev节点挪到cur节点的位置,cur节点向后移动。
画图理解:
以删除12为例,
cur节点:代表要删除的节点
/*
* 删除所有值为key的节点
* */
public void removeAllKey(int key){
if(head == null){//若链表为空直接返回
return;
}
// while(head.val == key){//头节点的数值与key相等时
// head = head.next;//头节点向后移动,直接删除第一个节点
// }
Node prev = head;
Node cur = head.next;//这句代码可以表明,删除元素是从链表的第二个节点开始
while(cur != null){//将所有节点都查找完,也没有和key值相等的节点,循环结束
if(cur.val == key){//如果key等于cur节点的值,进入删除cur节点
prev.next = cur.next;
cur = cur.next;
}else{//如果key不等于cur节点的值,将prev和cur节点整体后移
prev = cur;
cur = cur.next;
}
//这里写一个if判断的作用是,上面的删除操作只是从链表的第二个节点开始,所以这里需要判断链表的头节点,是否和key相等
if(head.val == key){
head = head.next;
}
}
}3.11、回收链表的每一个节点
这里将head置为null,表示head引用不再引用这个链表的第一个结点。链表当中的节点在没有被引用时,会被回收。这样就起到了清空链表的作用。
/*
* 保证链表当中的所有节点都可以被回收
* */
public void clear(){
head = null;//会将链表的每个节点都置为空
}