使用python进行英语文档词频统计开发
很多人免不了参加各种英语考试,词汇量就是参加英语考试的一个拦路虎,单词不认识,技巧再多也枉然。但考试大纲要求的单词太多了,时间紧,任务重,背了又容易忘,如果能知道真题中词汇出现的频率高低,那么有意识的去记忆出现频率较高的词汇,不失为一种有效的记单词方法。本文为了解决这个问题,本文使用Python开发了一个简单的统计单词频率的程序。
第一步:准备英文文档
本文用到的txt文档文件夹压缩包下载:2016年12月~2019年6月英语六级真题word、txt版本_python英语六级-讲义文档类资源-CSDN下载
新建文件夹,命名为:file_library_txt
也可使用自定义的文件名,但是需要改变python程序中file_library变量值为对应文件名
从网上下载近三年真题的word文档,并复制全文,新建tx文档,粘贴,另存为utf-8格式文件
本文下载了英语六级近三年(2016年12月到2019年6月)共6次考试的真题
每次考试3套题,一共18套题

第二步:编写Python程序文件
#!/usr/bin/python3.7
# -*- coding: utf-8 -*-
# function 自动统计英语单词词频,不翻译
import re
import os
from matplotlib import pyplot as plt
file_library = "./file_library_txt"
txt_file_name = 'combine.txt'
result_file_name = 'result.txt'
# 合并txt文件
def combine_txt(folder, combine_file_name):
# 获取目标文件夹中的文件名称列表
filenames = os.listdir(folder)
# 打开当前目录下的result.txt文件,如果没有则创建
f = open(combine_file_name, 'w', encoding='utf-8')
# 先遍历文件目录
for filename in filenames:
filepath = folder + '/' + filename
filenames_txt = os.listdir(filepath)
for filename_txt in filenames_txt:
file_txt = filepath + '/' + filename_txt
# print(file_txt)
# 遍历单个文件,读取行数
for line in open(file_txt, encoding='utf-8'):
f.writelines(line)
f.write('\n')
# 关闭文件
f.close()
# 获取txt文件内容
def gettext(file):
txt = open(file, "r", errors='ignore', encoding='utf-8').read()
txt = txt.lower()
return txt
# 统计txt文件中英文单词出现频率
def stat_freq(file_name, min_len=2, max_len=20):
content = gettext(file_name)
words = re.split(r'[^A-Za-z]+', content)
new_words = []
for word in words:
if (len(word) >= min_len) and (len(word) <= max_len):
new_words.append(word)
total_word = len(new_words)
counts = {}
for word in new_words:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key=lambda w: w[1], reverse=True)
f = open(result_file_name, 'w', encoding='utf-8')
f.writelines("{0:<6}\t{1:<20}\t{2:<6}\t{3:<5}\t{4:>5}".format("No", "Word", "Count", "Freq", "Cum_Freq"))
f.write('\n')
f.writelines("{0:<6}\t{1:<20}\t{2:<6}\t{3:<5}\t{4:>5}".format(len(items), "all_word", total_word, "100%", "100%"))
f.write('\n')
f.writelines("___________________________________________________________________")
f.write('\n')
cnt = []
cum_fre = 0
for i in range(len(items)):
word, count = items[i]
cum_fre = cum_fre + count
f.writelines("{0:<6}\t{1:<20}\t{2:<6}\t{3:.4%}\t{4:.4%}".format(i+1, word, count, count/total_word, cum_fre/total_word))
f.write('\n')
cnt.append(count)
# 关闭文件
f.close()
# 绘制频率图
plt.bar(list(range(1, len(cnt)+1)), cnt, align='center')
plt.axis([1, len(cnt)+1, 1, cnt[len(cnt)//30]])
plt.title('Word frequency')
plt.xlabel('X axis')
plt.ylabel('Y axis')
plt.savefig('freq.png')
plt.show()
combine_txt(file_library, txt_file_name)
stat_freq(txt_file_name)第三步:运行程序

文件放置位置如下所示
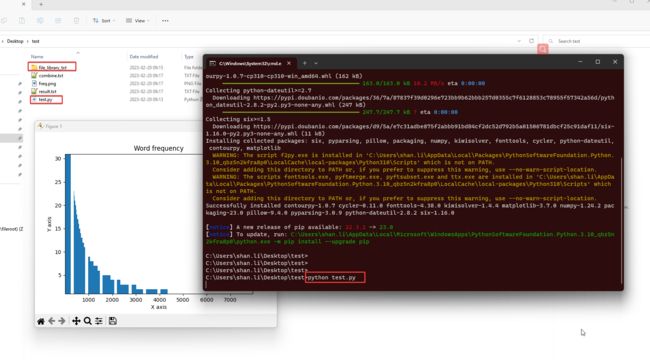
生成的统计结果txt文件如下:

18套题中一共提取出了67595个英语单词,共计有7949个不同的单词,出现频率最高的是the,出现次数高达3643次,频率占比约5.4%,平均每套题就有5.4%左右的单词是the

让人兴奋的是,从概率上讲,掌握了600多个高频单词,就可以认识一套试题中70%左右的单词
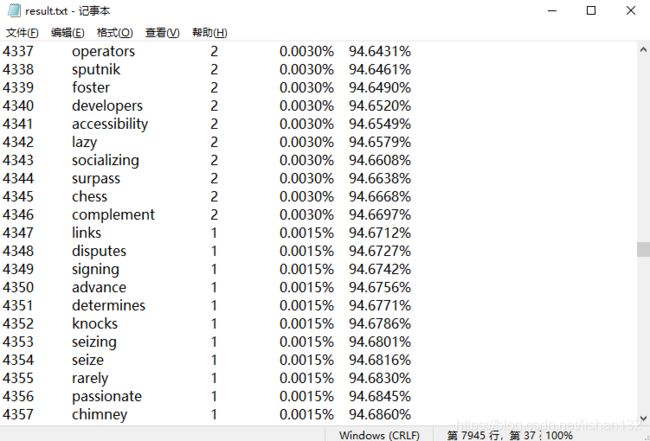

出现次数较少的单词,平均3年才一遇的单词都在末尾,只出现一次的单词总计有7949-4327+1=3603个单词,单词占比约45.33%,频率占比总计约为5.3%

平均每篇真题都出现的单词(必备词汇)大约有520个左右,单词占比约6.54%,频率占比约为67.77%
当然,可以很清楚的看到,超高频词都是一些简单词汇,大部分还是连词、介词等词汇,很多初中就已经学过了,不用再重点记忆

所以本文认为中高频词汇才是最重要的,即累计词频大约在65%~85%之间的单词


按照累计词频65%~85%的标准,本文统计出的英语六级中频词汇量大约为1890-422+1 = 1469个
总结:本文使用Python开发了一个简单的统计单词出现频率的小程序,只需要按要求准备要测试的txt文档即可,可以统计单个文档,也可以统计多个文档。本文实现了对近三年英语六级词频的统计,并确定了1400多个中高频词汇(65%~85%),这部分是需要强化记忆的。当然还可以更改参数,自定义统计单词的最小长度、最大长度等,本文程序默认最小长度为2,最大长度为20。最后祝天下考四六级的小伙伴们顺利通过!
本文还存在一定的不足,统计单词时没有考虑到所有格、缩写、连字符组合词汇、短语等等因素,没有开发一个良好的操作界面,支持的文档必须是txt,频率统计的结果还不够丰富,统计出的单词还没有翻译等等,后面会进一步改进。
#!/usr/bin/python3.7
# -*- coding: utf-8 -*-
# function 自动统计英语单词词频,带翻译
import re
import os
from matplotlib import pyplot as plt
import urllib.request
import urllib.parse
import json
file_library = "./file_library_txt"
txt_file_name = 'combine.txt'
result_file_name = 'result.txt'
# 翻译地址
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
def translate(word):
data = {'i': word, 'doctype': 'json'}
data = urllib.parse.urlencode(data).encode('utf-8')
response = urllib.request.urlopen(url, data)
html = response.read().decode('utf-8')
target = json.loads(html)
result = (target['translateResult'][0][0]['tgt'])
return result
# 合并txt文件
def combine_txt(folder, combine_file_name):
# 获取目标文件夹中的文件名称列表
filenames = os.listdir(folder)
# 打开当前目录下的result.txt文件,如果没有则创建
f = open(combine_file_name, 'w', encoding='utf-8')
# 先遍历文件目录
for filename in filenames:
filepath = folder + '/' + filename
filenames_txt = os.listdir(filepath)
for filename_txt in filenames_txt:
file_txt = filepath + '/' + filename_txt
# print(file_txt)
# 遍历单个文件,读取行数
for line in open(file_txt, encoding='utf-8'):
f.writelines(line)
f.write('\n')
# 关闭文件
f.close()
# 获取txt文件内容
def gettext(file):
txt = open(file, "r", errors='ignore', encoding='utf-8').read()
txt = txt.lower()
return txt
# 统计txt文件中英文单词出现频率
def stat_freq(file_name, min_len=2, max_len=20):
content = gettext(file_name)
words = re.split(r'[^A-Za-z]+', content)
new_words = []
for word in words:
if (len(word) >= min_len) and (len(word) <= max_len):
new_words.append(word)
total_word = len(new_words)
counts = {}
for word in new_words:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key=lambda w: w[1], reverse=True)
f = open(result_file_name, 'w', encoding='utf-8')
f.writelines("{0:<6}\t{1:<20}\t{2:<20}\t{3:<6}\t{4:<5}\t{5:>5}".format
("No",
"Word",
"Translate",
"Count",
"Freq",
"Cum_Freq"))
f.write('\n')
f.writelines("{0:<6}\t{1:<20}\t{2:<20}\t{3:<6}\t{4:<5}\t{5:>5}".format
(len(items),
"all_word",
"翻译",
total_word,
"100%",
"100%"))
f.write('\n')
f.writelines(
"_____________________________________________"
"_____________________________________________")
f.write('\n')
cnt = []
cum_fre = 0
for i in range(len(items)):
word, count = items[i]
cum_fre = cum_fre + count
f.writelines("{0:<6}\t{1:<20}\t{2:<20}\t{3:<6}\t{4:.4%}\t{5:.4%}".format
(i + 1,
word,
translate(word),
count,
count / total_word,
cum_fre / total_word))
f.write('\n')
cnt.append(count)
# 关闭文件
f.close()
# 绘制频率图
plt.bar(list(range(1, len(cnt) + 1)), cnt, align='center')
plt.axis([1, len(cnt) + 1, 1, cnt[len(cnt) // 30]])
plt.title('Word frequency')
plt.xlabel('X axis')
plt.ylabel('Y axis')
plt.savefig('freq.png')
plt.show()
combine_txt(file_library, txt_file_name)
stat_freq(txt_file_name)

当使用有道翻译时,只能连续请求1001次
最近使用基于Qt的Pyside2开发了一个简单的GUI界面,初学Qt界面开发,软件过于简陋,但词频统计的功能可以完全可以实现
软件已上传,点击链接下载 基于Qt的英语词频统计软件,使用python开发-Python文档类资源-CSDN下载
解压缩后,会看到如下图所示文件,其中,ui文件夹里的ui文件是界面设计的布局文件,可供参考,双击main.exe即可运行程序,


可以使用段落统计功能,直接粘贴文本进行统计,也可以对指定文件夹下的所有txt文件进行统计,
界面上可以预览出现频率前10的单词,统计全部结果放在程序所在目录下的result文件夹里



[1]李小罐 使用Python进行英文词频统计 使用Python进行英文词频统计_李小罐的博客-CSDN博客_python英语词频统计
[2]右介 python实现将文件夹内所有txt文件合并成一个文件 python实现将文件夹内所有txt文件合并成一个文件 - 右介 - 博客园