Python爬虫|使用Selenium轻松爬取网页数据
1. 什么是selenium?

Selenium是一个用于Web应用程序自动化测试工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作浏览器一样。支持的浏览器包括IE,Firefox,Safari,Chrome等。
Selenium可以驱动浏览器自动执行自定义好的逻辑代码,也就是可以通过代码完全模拟成人类使用浏览器自动访问目标站点并操作,那我们也可以拿它来做爬虫。
Selenium本质上是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等...进而拿到网页渲染之后的结果,可支持多种浏览器。
在日常开发中我们经常使用selenium来完成自动化操作、数据爬取等任务。
2. 当作为数据爬虫时什么情况下使用Selenium?
(1)使用selenium的优点:
就是可以帮我们避开一系列复杂的通信流程,例如在我们之前学习的requests模块,那么requests模块在模拟请求的时候是不是需要把素有的通信流程都分析完成后才能通过请求,然后返回响应。假如目标站点有一系列复杂的通信流程,例如的登录时的滑动验证等...那么你使用requests模块的时候是不是就特别麻烦了。不过你也不需要担心,因为网站的反爬策略越高,那么用户的体验效果就越差,所以网站都需要在用户的淫威之下降低安全策略。
再看一点requests请求库能不能执行js?是不是不能呀!那么如果你的网站需要发送ajax请求,异步获取数据渲染到页面上,是不是就需要使用js发送请求了。那浏览器的特点是什么?是不是可以直接访问目标站点,然后获取对方的数据,从而渲染到页面上。那这些就是使用selenium的好处!
(2)使用selenium的缺点:
使用selenium本质上是驱动浏览器对目标站点发送请求,那浏览器在访问目标站点的时候,是不是都需要把静态资源都加载完毕。html、css、js这些文件是不是都要等待它加载完成。是不是速度特别慢。那用它的坏处就是效率极低!所以我们一般用它来做登录验证。
(3)总结:
使用Selenium在爬取数据时既有有点也有缺点,因此需要根绝自己的需求明确是否选择和使用Selenium。
3. 安装和使用selenium
selenium支持包括Chrome、Firefox、Safari、Opera、Edge等众多浏览器,针对不同浏览器,需要安装不同的驱动器,本文以FireFox浏览器为例讲解。
(1)安装FireFox浏览器
直接下载和电脑对应版本的friefox浏览器
Firefox 火狐浏览器 - 全新、安全、快速 | 官方最新下载 下载由致力于互联网健康与隐私保护的非营利组织 Mozilla 全力开发的浏览器 — Firefox。Windows、Mac、Linux、Android、与 iOS 版皆可免费下载。 https://www.firefox.com.cn/
https://www.firefox.com.cn/
(2)安装FireFox浏览器驱动geckodriver
geckodriver是由Mozilla基金会和Mozilla公司开发的许多应用程序中使用的Web浏览器引擎。geckodriver是Selenium中的测试和Firefox浏览器之间的链接。
Releases · mozilla/geckodriver · GitHubWebDriver for Firefox. Contribute to mozilla/geckodriver development by creating an account on GitHub.https://github.com/mozilla/geckodriver/releases下载对应版本的geckodriver,同时注意firefox浏览器版本。下载后,解压文件,将解压后的 geokodriver.exe 驱动器放到Python安装目录下
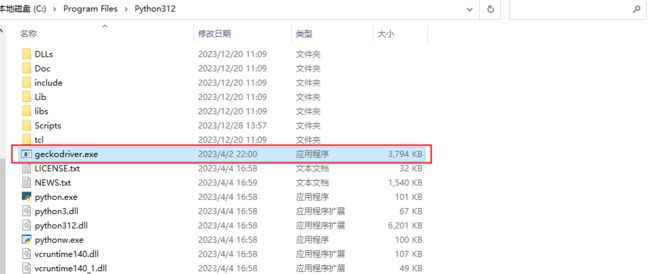
(3)Python下载和安装selenium库
使用pip安装selenium时,可以设置pip国内镜像地址加快selenium包下载速度
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/pip config list![]()
安装selenium
pip install selenium验证是否安装成功
pip show selenium
(4)在Python中使用selenium实现浏览器操作实例
# 浏览器自动化工具
from selenium import webdriver
from selenium.webdriver.common.by import By
# MySQL数据库链接工具
import pymysql
# 文件操作类
import os
# 时间类
from time import sleep
from docx import Document
import pypandoc
#链接MySQL
mysqlCon = pymysql.connect(
host="127.0.0.1",
port=3306,
user="root",
password="123456",
database="toutiao"
)
while True:
cursor = mysqlCon.cursor()
# 执行 SQL 查询语句
cursor.execute("select id,item_id,article_url,title from happy where state = 0 order by read_count asc limit 0,1")
# 获取查询结果
result = cursor.fetchall()
sql = "update happy set state = 1 where id = %s"
id = result[0][0]
cursor.execute(sql,id)
mysqlCon.commit()
articleId = result[0][1]
articleTitle = result[0][3]
# articleId = "7279996073686123068"
# 通过查询列表获取未发布的热门文章信息,根据获取的文章URL 打开URL链接地址
# articleId = "7291869777788666407"
# 创建一个浏览器实例
browser = webdriver.Firefox()
# # 获取请求地址
browser.get("https://toutiao.com/group/"+articleId)
sleep(30)
# 根据元素名称获取元素内容
textContainer = browser.find_element(By.CLASS_NAME,"syl-article-base")
articleHtml = textContainer.get_attribute("innerHTML")
# 根据解析的HTML内容,获取文章文本信息和图片信息,并将文本信息和图片保存到Word文档中
# file = open("E:\\studyproject\\python\\toutiao\data\\"+articleId+"\\"+articleId+".html", "r",encoding='utf-8')
os.mkdir("E:\\studyproject\\python\\toutiao\data\\happy\\"+articleId)
output = pypandoc.convert_text(articleHtml, 'docx','html',outputfile="E:\\studyproject\\python\\toutiao\data\\happy\\"+articleId+"\\"+articleTitle+".docx")
sleep(30)
browser.quit()
今日头条文章做了反爬虫处理,因此无法直接通过requests请求直接获取文章详情信息,因此只能使用selenium。上述代码示例中我们首先从数据库中获取已经爬取到的热门文章id,根据文章id拼接出文章url地址,使用selenium来操作浏览器,根据拼接的url地址打开文章页面,获取到文章内容标签元素,获取页面内容,并将页面文章文本和图片内容保存到word文档中。
一分钟爬取一篇文章,非常低高效

