自然语言处理(第17课 文本分类和聚类)
一、学习目标
1.学习文本分类的两种传统机器学习方法:朴素贝叶斯和支持向量机
2.学习文本分类的深度学习方法
3.学习文本分类的性能评估标准
4.学习文本聚类的相似性度量、具体算法、性能评估
二、文本分类
1.概述
将文本分类,主要工作是让机器分析文章内容,辨别其类别。常见的应用有:新闻文章归类,垃圾邮件识别:

2.传统机器方法
文本分类的传统机器方法,主要包含三个重要核心:文本表示、特征选择、分类算法。放在整体流程,就是:(图中的模式来源于模式识别,这里可以认为是测试文本)
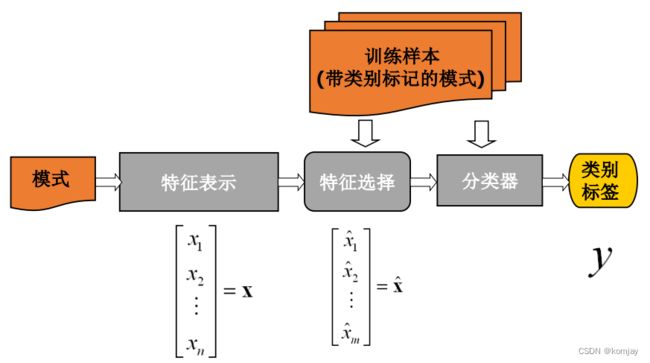
(1)文本表示
之所以要文本表示,是因为机器无法直接看懂原始文本,需要将文本转化为数字向量才行。一般在实验中,我们都会先使用词袋模型来表示一个文章:

一个文章就表示成右边的向量,这个向量长度是词典长度,词的排序认为确定,后面要按照这种顺序进行其他操作。(显然,词袋模型的缺点是不好扩展,有集外词时就要人工重新设定其向量长度,但其好在使用方便,集外词可以用
词袋向量的元素表示某个词的出现次数,一般认为出现多的词说明更重要,但“的”这个词显然对我们没用。所以我们需要对向量元素进行重新订正,让其变成某个词对文本分类的重要程度,于是引入了以下几个参数:

一般实验中,都使用TF-IDF作为最后的向量元素。
(2)特征选择
虽然现在的特征选择都直接使用词向量了,但还是要了解一下前人如何做特征选择的。特征选择的工作是,比如有“文本是否有词x”、“词x和词y接连出现”等一系列特征,要判断这些特征对分类的影响程度,以前一般就统计“文本是否有词x”作为特征了。(相当于上面计算词的权重,这里计算词的得分(也可以说是重要性),两者相乘得到概率,再综合所有词的概率,就能判别整个文本的类别了)。
特征选择的方法:

其中,将互信息应用到特征选择中,反映为点互信息:(MI是评判ti特征对分类的重要性的,MI取max则选择ti对某个分类影响最大的效果,MI取avg则综合ti对所有类别的影响程度。红色字描述有错,忽略即可)

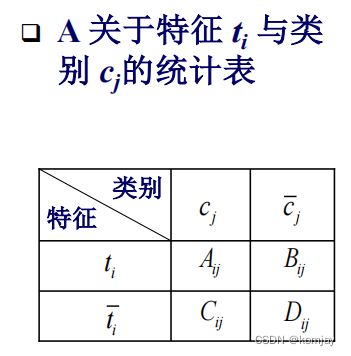
信息增益(IG)定义如下:

例子如下:


通过信息增益,可以对特征进行排序,从而减少没必要的特征,即忽视没用的词:


(3)分类算法
分类算法也有许多方法,我们重点讲述朴素贝叶斯和支持向量机法:

(a)朴素贝叶斯
首先需要了解贝叶斯理论,看一遍就行,应该都知道:

之所以说其理论最优,是因为,如果数据量足够大,贝叶斯通过统计数据库信息学习得到的结果就是最好,没必要用什么神经网络、大模型来实现。但问题在于其要求数据量实在太大,解释性也不够。
我们先要确定文本的特征就是文本中的词,然后根据贝叶斯函数得到我们的目标函数:
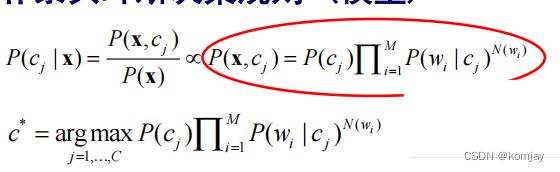
然后要计算P(c)和P(w|c),这两块我们是通过统计数据库情况得到的:

所以,来一个文本,我们就相当于根据文本的词特征,查数据库中的历史信息,判别文本的类别。
(b)线性支持向量机
支持向量机的核心思想就是在向量空间中找到一个超平面,将两类数据分隔开:
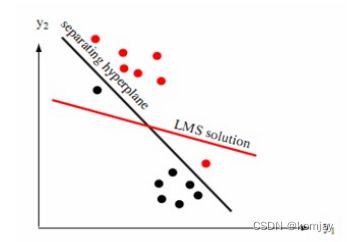
对于一系列的样本点(一个样本点表示一个文本),最开始使用最大间隔作为目标,但通过数学转化,可以转化为最小超平面方向:

列出目标函数和约束函数,就可以使用各种优化算法来求解该问题了(一般用拟牛顿法来求解,详见我另一个专栏:算法中的最优化方法与实现)。求解出超平面后,就通过计算判别函数的正负性来判断。(有人好奇如果是多类别呢,也是有另外的方法实现的,大不了就每一类作一个判别函数,为正就是该类,为负就是别的类)
3.深度学习方法
深度学习方法的效能不不是基于深度学习本身,其本身就是些全连接结构,实际起决定作用的还是文本表示的好坏,神经网络完成的工作对应于传统机器学习中的特征选择和分类算法。例如下面这个经典的文本词向量化后输入到神经网咯作分类:

或者是使用循环神经网络去搞:
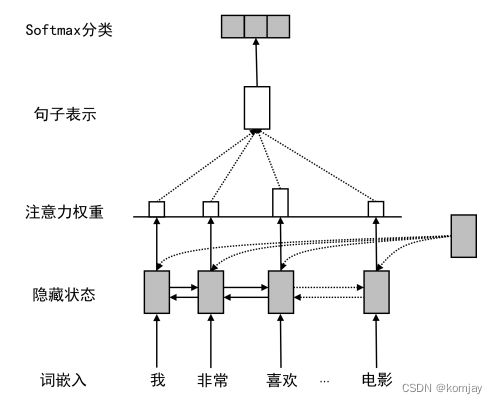
影响分类结果的关键点在于词向量(词嵌入),所以后面人们针对词向量学习,提出预训练+微调的方法,预训练的目标是学习词向量,学习方法是完型填空:
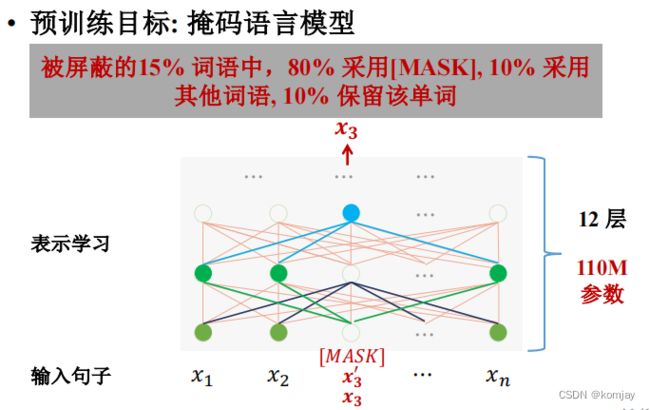
学习得到的词向量表运用到实际任务中,只需要加上一些全连接层就行,就是微调的工作,只调整全连接层的参数,一般不再调词向量表参数。
4.文本分类性能评估
来到分类任务中,性能评估方法就显得简单多了,因为就判断模型结果和实际标签是否对应就可以了;于是要定义四种情况:

于是,简单的召回率、精确率和F1值就可以计算出来:

还有正确率:

后面,又有人提出了宏平均和微平均的概念,直接看公式就明白在干嘛了(公式有点错误,累加符号写的j,但元素下标是i,实际上应该j=i)


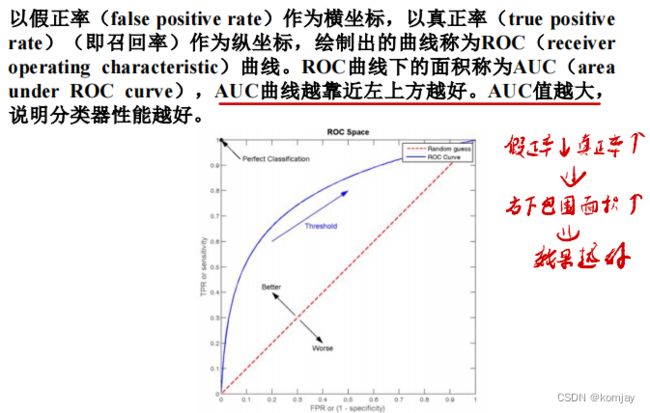
为了更直观展示模型的好坏,人们提出了P-R曲线和ROC曲线:(P-R曲线越往右上,效果越好,ROC曲线越往左上靠,效果越好)

三、文本聚类
文本聚类,即无监督学习,需要模型根据文本样本点相似性计算(没有标签),将相似的文本聚为一类。与文本分类一样,其重点步骤分三个:文本表示,文本相似性度量,聚类算法。文本表示前面说了,这里主要讲后面两步,而文本相似性度量是核心步骤。
1.文本相似性度量
根据对象不同,相似性度量分三种:

(1)文本之间
对于两个文本之间,从样本点的距离角度来考虑,我们可以使用范数来进行度量:

当然还有基于角度、杰卡德相似系数、基于分布的度量等,都不是很常用的方法。
(2)集合之间
与人的基本想法一样,可以有四种方法:



重心法就是对两个集合分别求平均,用平均点的距离作为集合的距离。显然是最方便的方法。此外,还有一个比较好的方法:(这个方法好在其判别两类合并前后的各点到中心距离的变化,能方便后面应该将哪两类进行合并)

(3)文本与集合之间
ppt是如下面这样写(当然也没错),但实际上,就三种常用方法,文本点到集合最近点的距离,文本点戴集合最远点距离,样本点到集合均值点距离。

2.文本聚类算法
聚类算法基本上就是这4种,基本没有什么拓展,建议直接去我的机器学习专栏第6章的讲解。他这里的讲解并没有比那边好太多,且例子不够那边好。

首先先讲一下文本在聚类前需要做的一些准备工作:

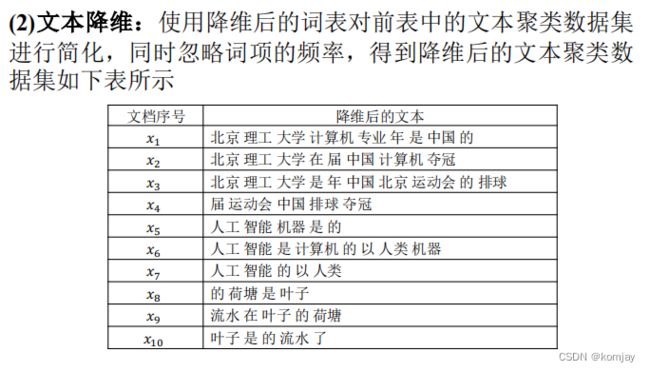
然后再大体上过一遍4个算法的思想。
K-均值聚类法,主要思想和EM很像,分两步:划分和更新。我们初始化n个聚类中心点,计算所有点到这n个点的距离,将样本点划分到离其最近的中心点的类别中,然后更新:将一个类中的点再取平均,更新出新的n个聚类中心点,直到中心点不再变动。
单遍聚类,按照数据库顺序读入一个一个样本,如果样本离某些集合距离小于阈值,则划分到最近的一类,如果大于阈值,则自己划分为一类。
层次聚类,分自顶向下和自底向上两个,自顶向下,相当于将所有样本点看为一类,然后不断切分,自底向上相当于每个样本点都是一类,然后两两聚合。
,密度聚类认为,分布密集的样本点是被稀疏的样本点所分割的,于是那些联通的稠密的样本点集合就是我们的聚类。例子如下:

3.文本聚类性能评估
首先,聚类方法由于没有标签,所以不能用分类方法的评估标准来评判聚类方法。而非要用标签来判别,也不是不行,其就是聚类评估里的外部标准,当然还有内部标准。
(1)外部标准
即使是有标签,我们也无法像分类那样计算,因为聚类并没给数据打标签。所以只能通过一对样本点是否在同一类中,进行评价,于是定于以下参数:


直观上,我们希望a和d更大,b和c越小,效果则越好,于是评价指标就是:

(2)内部指标
缺少标签后,我们只能通过聚类的形状来计算其效果:

轮廓系数是需要计算一个样本点与类内其他的点的平均距离a,以及一个离它最近的别的类均值点的距离b,综合a和b得到的结果来进行评估。计算公式如下:


四、本章小节
1.学习了文本分类的各个步骤和各种实现方法
2.学习文本聚类的准备工作和具体的聚类方法
3.学习了文本分类和聚类不同的评估方法和标准