损失函数总结(十一):Huber Loss、SmoothL1Loss
损失函数总结(十一):Huber Loss、SmoothL1Loss
- 1 引言
- 2 损失函数
-
- 2.1 Huber Loss
- 2.2 SmoothL1Loss
- 3 总结
1 引言
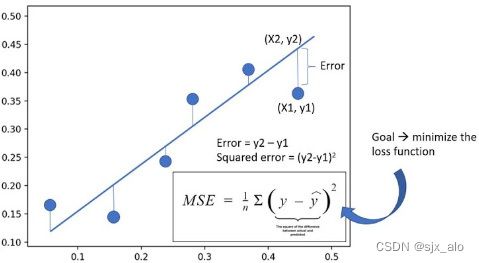
在前面的文章中已经介绍了介绍了一系列损失函数 (L1Loss、MSELoss、BCELoss、CrossEntropyLoss、NLLLoss、CTCLoss、PoissonNLLLoss、GaussianNLLLoss、KLDivLoss、BCEWithLogitsLoss、MarginRankingLoss、HingeEmbeddingLoss、MultiMarginLoss、MultiLabelMarginLoss、SoftMarginLoss、MultiLabelSoftMarginLoss、TripletMarginLoss、TripletMarginWithDistanceLoss)。在这篇文章中,会接着上文提到的众多损失函数继续进行介绍,给大家带来更多不常见的损失函数的介绍。这里放一张损失函数的机理图:
2 损失函数
2.1 Huber Loss
MSE 损失收敛快但容易受 outlier 影响,MAE 对 outlier 更加健壮但是收敛慢,Huber Loss 则是一种将 MSE 与 MAE 结合起来,取两者优点的损失函数,也被称作 Smooth Mean Absolute Error Loss 。其原理很简单,就是在误差接近 0 时使用 MSE,误差较大时使用 MAE。Huber Loss的数学表达式如下:
l ( x , y ) = L = { l 1 , . . . , l N } T l(x, y) = L = \{l_1, ..., l_N\}^T l(x,y)=L={l1,...,lN}T
其中,
l n = { 0.5 ( x n − y n ) 2 , i f ∣ x n − y n ∣ < d e l t a d e l t a ∗ ( ∣ x n − y n ∣ − 0.5 ∗ d e l t a ) , o t h e r w i s e l_n = \left\{\begin{matrix} 0.5(x_n-y_n)^2, \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ if \ |x_n-y_n|
注意:当 d e l t a = 1 delta=1 delta=1 时,该损失函数等价于SmoothL1Loss。
代码实现(Pytorch):
import numpy as np
# 观测值
y = np.array([2.5, 3.7, 5.1, 4.2, 6.8])
# 模型预测值
f_x = np.array([2.2, 3.8, 4.9, 4.5, 7.2])
# 设置Huber损失的超参数
delta = 1.0
# 计算Huber损失
def huber_loss(y, f_x, delta):
loss = np.where(np.abs(y - f_x) <= delta, 0.5 * (y - f_x) ** 2, delta * np.abs(y - f_x) - 0.5 * delta ** 2)
return loss
loss = huber_loss(y, f_x, delta)
print("Huber Loss for each data point:", loss)
print("Mean Huber Loss:", np.mean(loss))
由于存在一个需要迭代的超参数 d e l t a delta delta, 因此在深度学习领域还是MSE等简单损失函数占据独特优势。
2.2 SmoothL1Loss
论文链接:Fast R-CNN
SmoothL1Loss 是一种常用于回归任务的损失函数,是 L1Loss 的平滑版本。相比于L1Loss(MAELoss),SmoothL1Loss 可以收敛得更快;相比于L2Loss(MSELoss),SmoothL1Loss 对离群点、异常值不敏感,梯度变化相对更小,训练时不容易跑飞。SmoothL1Loss 的数学表达式如下:
l n = { 0.5 ( x n − y n ) 2 / b e t a , i f ∣ x n − y n ∣ < b e t a ∣ x n − y n ∣ − 0.5 ∗ b e t a , o t h e r w i s e l_n = \left\{\begin{matrix} 0.5(x_n-y_n)^2/beta, \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ if \ |x_n-y_n|
- beta:指定该损失在 L 1 ∼ L 2之间变化的
阈值,默认为1.0。
代码实现(Pytorch):
import torch.nn as nn
import torch
loss1 = nn.SmoothL1Loss(reduction='none')
loss2 = nn.SmoothL1Loss(reduction='mean')
y = torch.randn(3)
y_pred = torch.randn(3)
loss_value1 = loss1(y, y_pred)
loss_value2 = loss2(y, y_pred)
print(y) # tensor([ 1.6938, -0.3617, -1.2738])
print(y_pred) # tensor([ 0.3932, 0.8715, -0.2410])
print(loss_value1) # tensor([0.8007, 0.7332, 0.5328])
print(loss_value2) # tensor(0.6889)
超参数会限制损失函数的训练速度,整体而言可能还是 MSELoss 更好用。。。。
3 总结
到此,使用 损失函数总结(十一) 已经介绍完毕了!!! 如果有什么疑问欢迎在评论区提出,对于共性问题可能会后续添加到文章介绍中。如果存在没有提及的损失函数也可以在评论区提出,后续会对其进行添加!!!!
如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦。