pandas用法整理
处理表格数据的时候经常用到pandas,每次用的时候都要去查函数,每次记不住,每次都查,哈哈哈,自己整理一下,码住。
一、Pandas的数据类型
进行数据分析时,如何正确使用数据类型,这非常重要。在pandas中的数据类型和python原生数据类型有相似又有不同,这是比较头疼的地方。
1.下表给出Pandas,Python和Numpy数据类型的总结
| Pandas dtype | Python类型 | Numpy类型 | 用途 |
|---|---|---|---|
| object | str | string,unicode | 文本 |
| int64 | int | int_,int8,int16,int64,uint8,uint16,uint32,uint64 | 整数 |
| float64 | float | float_,float16,float32,float64 | 浮点数 |
| bool | bool | bool_ | 布尔值 |
| datetime64[ns] | NA | NA | 日期时间 |
| timedelta[ns] | NA | NA | 时间差 |
| category | NA | NA | 有限长度的文本值列表 |
2.dtype查看数据类型
import pandas as pd
df = pd.read_csv('文件路径')
df.dtypes()
3.astype强制修改数据类型
df.index.astype('int64') # 索引类型转换
df.astype('int64') # 所有数据转换为 int64
df.astype('int64', copy=False) # 不与原数据关联
df.astype({'A': 'int32'}) # 指定字段转换类型
df['A'].astype('float') # 指定字段转换类型
二、生成数据表
1.读取文件
# 导入pandas
import pandas as pd
# 导入numpy
import numpy as np
# 导入csv或xlsx文件
df = pd.read_csv('文件路径')
df = pd.read_excel('文件路径')
2.用pandas创建数据表
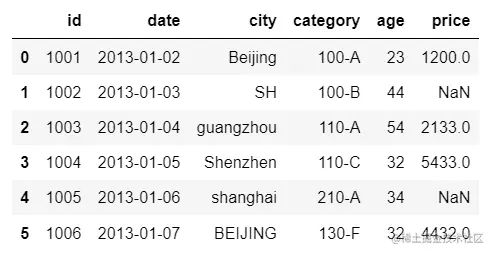
df = pd.DataFrame(
{"id": [1001,1002,1003,1004,1005,1006],
"date": pd.date_range('20130102', periods=6),
"city": ['Beijing ', 'SH', ' guangzhou ', 'Shenzhen', 'shanghai', 'BEIJING '],
"age": [23,44,54,32,34,32],
"category": ['100-A','100-B','110-A','110-C','210-A','130-F'],
"price": [1200,np.nan,2133,5433,np.nan,4432]},
columns=['id','date','city','category','age','price'])
三、数据表信息查看
1.维度查看
df.shape # (6, 6)
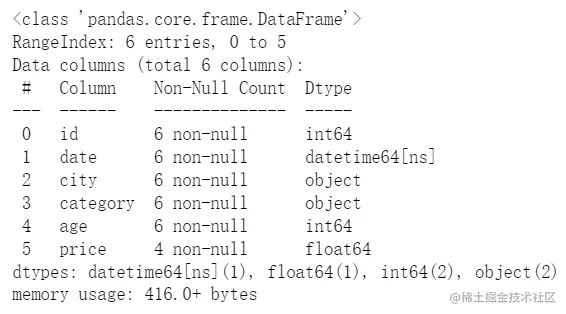
2.数据表基本信息
df.info()
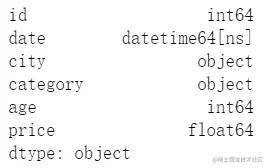
3.每一列的数据类型
df.dtypes
4.查看某一列的数据类型
df['A'].dtype
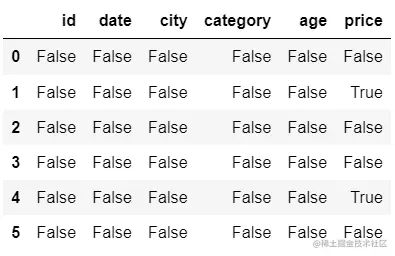
5.空值
df.isnull()
6.查看某一列的空值
df['A'].isnull()
7.查看某一列的唯一值
df['A'].unique()
8.查看数据表的值
df.values

9.查看列名称
df.columns
Output:
Index(['id', 'date', 'city', 'category', 'age', 'price'], dtype='object')
10.查看前五行、后五行数据
df.head() # 默认前五行数据
df.head(100) # 查看前100行数据
df.tail() # 默认后五行数据
四、数据预处理
1.用数字0填充空值
df.fillna(value=0)
2.使用price的均值对NA进行填充
df['price'].fillna(df['price'].mean())
3.清除city字段的空格字符
df['city] = df['city'].map(str.strip)
4.大小写转换
df['city'] = df['city'].str.lower() # 转小写
df['city'] = df['city'].str.upper() # 转大写
5.更改数据类型
df['price'].astype('int')
6.更改列名称
df.rename(columns={'category': 'category-size'})
7.删除重复值 默认保留前面出现的
df['city'].drop_duplicates()
8.删除重复值 保留后面出现的
df['city'].drop_duplicates(keep='last')
9.数据替换
df['city'].replace('sh', 'shanghai')

五、数据表操作
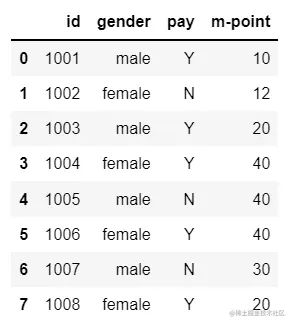
df1=pd.DataFrame({"id":[1001,1002,1003,1004,1005,1006,1007,1008],
"gender":['male','female','male','female','male','female','male','female'],
"pay":['Y','N','Y','Y','N','Y','N','Y',],
"m-point":[10,12,20,40,40,40,30,20]})
1.数据表合并
1.1 merge
默认的连接方法为inner
df_inner=pd.merge(df,df1,how='inner') # 交集 自然连接
df_left=pd.merge(df,df1,how='left') # 左连接 以左数据框中的连接键为基准,匹配右数据框中的信息,并连接
df_right=pd.merge(df,df1,how='right') # 右连接
df_outer=pd.merge(df,df1,how='outer') # 并集
inner: 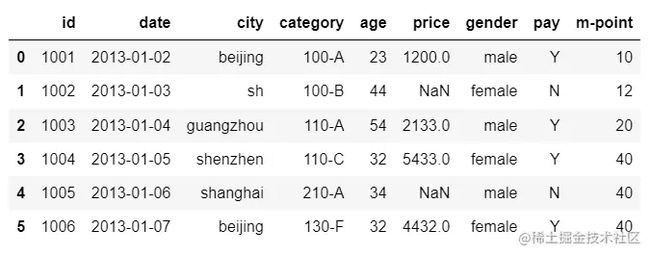
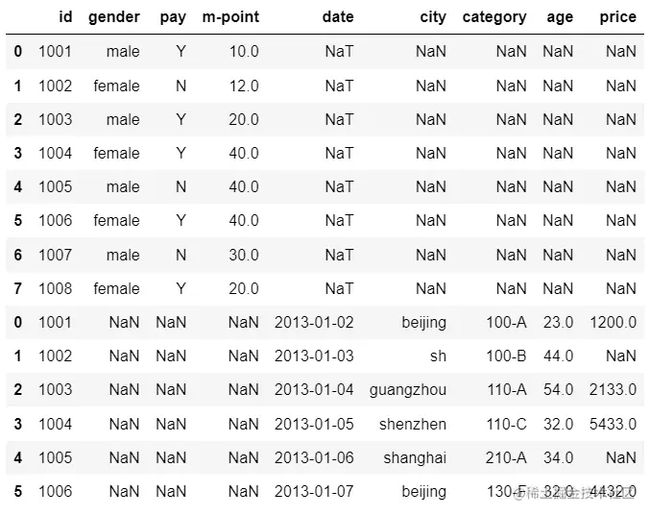
1.2 append
result = df1.append(df)
1.3 join
join方法是一种快速合并的方法,它默认以index作为对齐的列。
join中的how参数和merge中的how参数一样,用来指定表合并保留数据的规则。
on参数:在实际应用中如果右表的索引是左表的某一列的值,这时可以将右表的索引和左表的列对齐合并这样的灵活方式进行合并。
# result = left.join(right, how='right', on='key')
left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3'],'key': ['K0', 'K1', 'K0', 'K1']})
right = pd.DataFrame({'C': ['C0', 'C1'],'D': ['D0', 'D1']},index=['K0', 'K1'])
result=left.join(right,on='key')
1.4 concat
pd.concat(objject, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None,verify_integrity=False,
copy=True)
object:series,dataframe或者是panel构成的序列list
axis:需要合并连接的轴,0是行,1是列
join:连接的方式inner,或者outer
2.设置索引列
df_inner.set_index('id') # 设置索引列为'id'
3.按照指定列的值排序
df_inner.sort_values(by=['age'])
4.按照索引列排序
df_inner.sort_index()
5.如果price列的值>3000,group列显示high,否则显示low
df_inner['group'] = np.where(df_inner['price'] > 3000, 'high', 'low')
6.对符合多个条件的数据进行分组标记
df_inner.loc[(df_inner['city'] == 'beijing') & (df_inner['price'] >= 4000), 'sign'] = 1
7.对category字段的值依次进行分列,并创建数据表,索引值为df_inner的索引列,列名称为category和size
pd.DataFrame((x.split('-') for x in df_inner['category']),index=df_inner.index,columns=['category','size'])
8.将完成分裂后的数据表和原df_inner数据表进行匹配
df_inner = pd.merge(df_inner, split, right_index=True, left_index=True)
六、数据提取
主要用到3个函数:loc,iloc和ix,
loc函数按标签值进行提取,iloc按位置进行提取,ix可以同时按标签和位置进行提取。
1.按索引提取单行的数值
df_inner.loc[3]
2.按索引提取区域行数值
df_inner.iloc[0: 5]
3.重设索引
df_inner.reset_index()
4.设置日期为索引
df_inner = df_inner.set_index('date')
5.提取4日之前的所有数据
df_inner[: '2013-01-04']
6.使用iloc按位置区域提取数据
df_inner.iloc[: 3, : 2] # 提取前3行,前4列
7.使用iloc按位置单独提取数据
df_inner.iloc[[0, 2, 5], [4, 5]] # 提取第0、2、5行,4、5列
8.使用ix按索引标签和位置混合提取数据
df_inner.ix[: '2013-01-03', : 4] # 2013-01-03号之前,前四列数据
9.判断city列里的值是否为北京
df_inner['city].isin(['beijing'])
10.判断city列里是否包含beijing和shanghai,然后将符合条件的数据提取出来
df_inner.loc[df_inner['city'].isin(['beijing', 'shanghai'])]
11.提取前三个字符,并生成数据表
pd.DataFrame(df_inner['category'].str[: 3])
七、数据筛选(逻辑操作
使用与、或、非三个条件配合大于、小于、等于对数据进行筛选,并进行计数和求和。
1.使用“与”进行筛选
df_inner.loc[(df_inner['age'] > 25) & (df_inner['city'] == 'beijing'), ['id', 'city', 'age', 'category', 'gender']]
2.使用“或”进行筛选
df_inner.loc[(df_inner['age'] > 25) | (df_inner['city'] == 'beijing'), ['id','city','age','category','gender']].sort(['age'])
3.使用“非”进行筛选
df_inner.loc[(df_inner['city'] != 'beijing'), ['id','city','age','category','gender']].sort(['id'])
4.对筛选后的数据按city列进行计数
df_inner.loc[(df_inner['city'] != 'beijing'), ['id','city','age','category','gender']].sort(['id']).city.count()
5.使用query函数进行筛选
df_inner.query('city == ["beijing", "shanghai"]')
6.对筛选后的结果按price进行求和
df_inner.query('city == ["beijing", "shanghai"]').price.sum()
八、数据汇总
主要函数是groupby和pivote_table
1.对所有的列进行计数汇总
Input:
df_inner.groupby('city').count()
2.按城市对id字段进行计数
Input:
df_inner.groupby('city')['id'].count()
3.对两个字段进行汇总统计
Input:
df_inner.groupby(['city', 'size'])['id'].count()
4.对city字段进行汇总,并分别计算price的合计和均值
Input:
df_inner.groupby('city')['price'].agg([len, np.sum, np, mean])
九、数据统计
数据采样,计算标准差,协方差和相关系数
1.简单的数据采样
df_inner.sample(n=3)
2.手动设置采样权重
weights = [0, 0, 0, 0, 0.5, 0.5]
df_inner.sample(n=2, weights=weights)
3.采样后不放回
df_inner.sample(n=6, replace=False)
4.采样后放回
df_inner.sample(n=6, replace=True)
5.数据表描述性统计
df_inner.describe().round(2).T # round函数设置显示小数位,T表示转置
6.计算列的标准差
df_inner['price'].std()
7.计算两个字段间的协方差
df_inner['price'].cov(df_inner['m-point'])
8.数据表中所有字段间的协方差
df_inner.cov()
9.两个字段的相关性分析
df_inner['price'].corr(df_inner['m-point'])
# 相关系数在-1到1之间,接近1为正相关,接近-1为负相关,0为不相关
10.数据表的相关性分析
df_inner.corr()
十、数据输出
1.写入Excel
df_inner.to_excel('excel_to_python.xlsx', sheet_name='bluewhale_cc')
2.写入CSV
df_inner.to_csv('excel_to_python.csv')
题外话
感谢你能看到最后,给大家准备了一些福利!
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。
CSDN大礼包:全网最全《Python学习资料》免费赠送!(安全链接,放心点击)
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python兼职渠道推荐*
学的同时助你创收,每天花1-2小时兼职,轻松稿定生活费.

三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

CSDN大礼包:全网最全《Python学习资料》免费赠送!(安全链接,放心点击)
若有侵权,请联系删除