可做毕设/基于opencv的手势识别完整项目/python3.9/万字长文手把手带你学
可做毕设/基于OpenCV的手势识别/python3.9
-
- 前言
- 正文
-
- 图片获取与处理
- 特征提取
- 模型训练
- 界面设计
- 后语
前言
在一切的开始前,我想先感谢 @Brielleqqqqqqjie 大神,
没有ta三年前的文章指导,这个小作品一路的学习尝试恐怕不会有那么顺利。
毕业设计临近,为了做一个更好的作品,和大家一样,我也一直在找一个简单的opencv项目练练手。原作者的code版本太老,于是我在学习了网上许多大佬的开源代码和研究了作者思路之后,便着手改动重制一份。但是由于本人能力有限,加之一时心血来潮,项目仍有诸多不足和错误之处,特行文记录,希望能帮助到有需要的人。
项目简介:基于 Python3.9.13的环境,利用Python的OpenCV、Sklearn和PyQt5等库搭建了一个较为完整的手势识别系统,用于识别日常生活中1-10的静态手势。
环境:Macos 12.6 + Python3.9.13 + OpenCV4.6.0.66 + Sklean1.1.2
这里放一个最终演示图:
限于篇幅,我这里具体讲解步骤流程,其背后的方法与思想(其实有些我也不是很懂)甚至于一些库的安装我就不再赘述。
有疑问的可以留言或者自行google。
整体的脉络,大神的文章已经讲得非常清楚了。整个项目分为4个部分,即图片获取与处理,特征提取,模型训练,界面设计。
正文
图片获取与处理
我们首先需要样本训练,所以要获取手势图片。
首先需要一个能打开摄像头的文件(不妨命名:capture_window.py,之后省略py),如下:
import cv2
import my_picture as pic #图像处理文件
import gesture_capture as gc #图像捕获文件
font = cv2.FONT_HERSHEY_SIMPLEX # 设置字体
size = 0.5 # 设置大小
width, height = 400, 400 # 设置拍摄窗口大小
x0, y0 = 300, 100 # 设置选取位置
cap = cv2.VideoCapture(0) # 开摄像头
current=1 #当前拍摄数量
target=200 #数量上限
while (current<=target):
ret, frame = cap.read() # 读取摄像头的内容,ret bool 判断获取帧
frame = cv2.flip(frame, 1) #frame 获取到的一帧
frame1,roi, res, ret ,fourier_result= pic.binaryMask(frame, x0, y0, width, height) # 取手势所在框图并进行处理
key = cv2.waitKey(1) & 0xFF # 按键判断并进行一定的调整
if key == ord('s'):
y0 += 20
elif key == ord('w'):
y0 -= 20
elif key == ord('d'):
x0 += 20
elif key == ord('a'):
x0 -= 20
if key==ord('f'):
gc.gesture_caption(res,current)
current+=1
if key == ord('q'):
break
cv2.imshow('frame', frame) # 播放摄像头的内容
cap.release()
cv2.destroyAllWindows() # 关闭所有窗口
这里偷懒直接上我的最终代码了,所以我具体讲解一下:
- 一张图片手太小,无用的信息太多,自然我们需要一个函数binaryMask 框范围带处理图像(新建一个处理文件my_picture,下文会讲到)。这里你理解为它会返回一个带框的图像函数就行。
- 有时候移动手不方便,我们需要移动框,自然wasd 控制移动。
- 由于我们需要采集样本(新建一个采集图片的文件gesture_capture),target是要采集的目标数。当我们按f键位的时候会拍摄一张图像,截取框内图像成为一份样本。
可以看到此部分一共三个文件,其中一个代码已经贴上去了,我来讲剩下两个。
首先是gesture_capture,
def gesture_caption(image,current):
if (current%20==0):
gesture_form=current/20
single_number = 20
else:
gesture_form = int(current/20)+1
single_number = current % 20
cv2.imwrite(path + str(int(gesture_form)) + '_' + str(single_number) + '.png', image)
#训练集、测试集都用此采集
print(int(gesture_form),'_',single_number," , ok")
这个函数目的是为了实现共200张,每张编号a_b,a为手势表达,b为数量编号,如手势1的第19张图编号1_19。
在 my_picture文件中,我们还需要完成图片的预处理,标准的流程预处理的主要步骤为:
去噪 -> 肤色检测 -> 二值化 -> 形态学处理 -> 轮廓提取。
见大神文章,这个部分大神讲的很清楚,我主要分享自己的代码为主。
这里考虑到去噪不明显,仅采用方法四YCrCb颜色空间的Cr分量+Otsu法阈值分割算法进行肤色检测+二值化处理
def binaryMask(frame, x0, y0, width, height):
frame1=cv2.rectangle(frame, (x0, y0), (x0 + width, y0 + height), (0, 255, 0)) # 画出截取的手势框图
roi = frame[y0:y0 + height, x0:x0 + width] # roi=手势框图
#cv2.imshow("roi", roi) # 显示手势框图
res = skinMask(roi) # 进行肤色检测
#cv2.imshow("res", res) # res是roi显示肤色检测后的图像
def skinMask(roi):
YCrCb = cv2.cvtColor(roi, cv2.COLOR_BGR2YCR_CB) #转换至YCrCb空间
(y,cr,cb) = cv2.split(YCrCb) #拆分出Y,Cr,Cb值
cr1 = cv2.GaussianBlur(cr, (5,5), 0)
_, skin = cv2.threshold(cr1, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU) #Ostu处理
res = cv2.bitwise_and(roi,roi, mask = skin)
return res
接下来是形态学处理,部分我直接上大神原文,感兴趣的小伙伴自行学习。
即便是比较好的肤色检测算法,分割出来的手势,也难免有黑点,或者背景有白点,这时候需要对分割出来的手势图进行进一步处理,主要是腐蚀膨胀两个操作。
腐蚀和膨胀是针对白色部分(高亮部分而言)。从数学角度来说,膨胀或者腐蚀操作就是将图像(或图像的一部分区域,称之为A)与核(称之为B)进行卷积。
膨胀就是求局部最大值操作,即计算核B覆盖的区域的像素点的最大值,并把这个最大值赋值给参考点指定的像素,这样就会使图像中的高亮区域逐渐增长。
腐蚀就是求局部最小值操作,即计算核B覆盖的区域的像素点的最小值,并把这个最小值赋值给参考点指定的像素,这样就会使图像中的高亮区域逐渐减少。
开运算:先腐蚀后膨胀,去除孤立的小点,毛刺
闭运算:先膨胀后腐蚀,填平小孔,弥合小裂缝
这里在binaryMask函数中加上
kernel = np.ones((3, 3), np.uint8) # 设置卷积核
erosion = cv2.erode(res, kernel) # 腐蚀操作
res= cv2.dilate(erosion, kernel) # 对res膨胀操作 dilation
#cv2.imshow("res_dilation", res)
最后是轮廓提取,我将此部分集成到了第二部分特征提取之中,下图中我仅展示了部分
def find_contours(Laplacian):
#binaryimg = cv2.Canny(res, 50, 200) #二值化,canny检测
h_c,h_i= cv2.findContours(Laplacian,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_NONE) #寻找轮廓
contour = sorted(h_c,key=cv2.contourArea, reverse=True)#对一系列轮廓点坐标按它们围成的区域面积进行排序
return contour
许多拿大神源码的人这部分会报错,我改写成了新版opencv方式,现在可以正常运行。
此部分运行结果我展示一下。
roi 初版 res 肤色检测 dilation卷积腐蚀 ret 轮廓提取
原作者在此部分还将捕获的图像再做旋转翻转等变换,扩充训练集。我也采纳了,毕竟手摆出上千次也挺累。
gesture_name是手势代码,gesture_number是该手势数量。
for gesture_name in range(1, 11):
for gesture_number in range(1, 21):
image = cv2.imread(path + str(gesture_name) + '_' + str(gesture_number) + '.png')
for cnt in range(10):
img_rotation = rotate(image) # 旋转
all=save_txt_number(all,img_rotation,gesture_name)
img_flip = cv2.flip(img_rotation, 1) # 翻转
all = save_txt_number(all, img_flip, gesture_name)
特征提取
这部分的思想是由ret上轮廓点坐标提取出他们的傅里叶描述子,保存为特征文件。
这是github上整理的比较好的相关代码:https://github.com/timfeirg/Fourier-Descriptors
这是知乎上一个比较通俗解释的回答:https://www.zhihu.com/question/21485112
def fourierDescriptor(res):
#Laplacian算子进行八邻域检测
gray = cv2.cvtColor(res, cv2.COLOR_BGR2GRAY)
dst = cv2.Laplacian(gray, cv2.CV_16S, ksize = 3)
Laplacian = cv2.convertScaleAbs(dst)
contour = find_contours(Laplacian)#提取轮廓点坐标
contour_array = contour[0][:, 0, :]#注意这里只保留区域面积最大的轮廓点坐标
ret_np = np.ones(dst.shape, np.uint8) #创建黑色幕布
ret = cv2.drawContours(ret_np,contour[0],-1,(255,255,255),1) #绘制白色轮廓
contours_complex = np.empty(contour_array.shape[:-1], dtype=complex)
contours_complex.real = contour_array[:,0]#横坐标作为实数部分
contours_complex.imag = contour_array[:,1]#纵坐标作为虚数部分
fourier_result = np.fft.fft(contours_complex)#进行傅里叶变换
descriptors = truncate_descriptor(fourier_result)#傅里叶描述子
return ret, descriptors# 返回一个32个的算子集合
这里新建一个computer_feature文件,读入四千张图片逐个计算图片上的傅里叶描述子并保存为txt就完事了。

如上图,每份文件都包含32位的描述手势特征向量。
上图ret便是计算之后对人手轮廓的提取。
值得一说的是,原文中大神还进行了二次降噪,能有效提升图片识别的稳定性和成功率。这里我有所遗漏,现在想来也是下文模型训练中拟合度有所不足的原因之一,特此记录。
模型训练
这部分同样是网格调参,确实香。
不了解的同学可以看下这里,这是一个简单的示例https://cloud.tencent.com/developer/article/1083531
由于版本更迭,我重新改写了代码命名为svm_classify,如下
import numpy as np
from os import listdir
import joblib
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
path = './' + 'feature' + '/'
model_path = "./model/"
test_path = "./test_feature/"
test_accuracy = []
# 读txt文件并将每个文件的描述子改为一维的矩阵存储
def txtToVector(filename, N):
returnVec = np.zeros((1, N))
fr = open(filename)
lineStr = fr.readline()
lineStr = lineStr.split(' ')
for i in range(N):
returnVec[0, i] = int(lineStr[i])
return returnVec
def tran_SVM(N):
svc = SVC()
parameters = {'kernel': ('sigmoid', 'rbf', 'poly', 'linear'),
'C': [0.0001, 0.001, 1, 100, 10000, 100000],
'gamma': [1e-8, 1e-5, 1e-3, 0.01, 1, 10, 100]} # 预设置一些参数值
hwLabels = [] # 存放类别标签
trainingFileList = listdir(path)
m = len(trainingFileList)
trainingMat = np.zeros((m, N))
for i in range(m):
fileNameStr = trainingFileList[i]
classNumber = int(fileNameStr.split('_')[0])
hwLabels.append(classNumber)
trainingMat[i, :] = txtToVector(path + fileNameStr, N) # 将训练集改为矩阵格式
print("数据加载完成")
clf = GridSearchCV(svc, parameters, cv=5, n_jobs=8) # 网格搜索法,设置5-折交叉验证
clf.fit(trainingMat, hwLabels)
print(clf.return_train_score)
print(clf.best_params_) # 打印出最好的结果
best_model = clf.best_estimator_
print("SVM Model save...")
save_path = model_path + "svm_" + "train_model.m"
joblib.dump(best_model, save_path) # 保存最好的模型
def test_SVM(clf, N):
testFileList = listdir(test_path)
errorCount = 0 # 记录错误个数
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
classNum = int(fileNameStr.split('_')[0])
vectorTest = txtToVector(test_path + fileNameStr, N)
valTest = clf.predict(vectorTest)
# print("分类返回结果为%d\t真实结果为%d" % (valTest, classNum))
if valTest != classNum:
errorCount += 1
print("总共错了%d个数据\n错误率为%f%%" % (errorCount, errorCount / mTest * 100))
def test_fd(fd_test):
clf = joblib.load(model_path + "svm_train_model.m")
test_svm = clf.predict(fd_test)
return test_svm
####训练 + 验证#####
if __name__ == "__main__":
tran_SVM(32)
clf = joblib.load(model_path + "svm_" + "train_model.m")
test_SVM(clf, 32
)
运行之后稍等片刻,
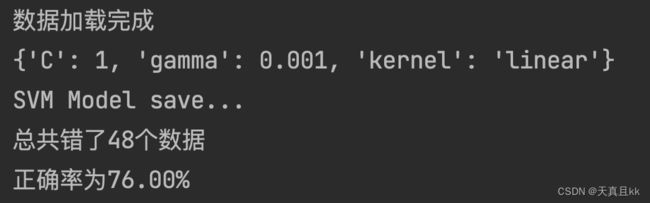
如果大家做了二次去噪的话,效果应该会比我好上很多。
之后有时间的话可能会改用神经网络,加上降噪,肯定不止八成。
到这里其实我们已经大致完成了,只要在原来的capture_window中加点预测的代码就行。
if key == ord('p'):
descriptors = abs(fourier_result)
fd_test = np.zeros((1, 31))
temp = descriptors[1]
for k in range(1, len(descriptors)):
fd_test[0, k - 1] = int(100 * descriptors[k] / temp)
test_svm = cf.test_fd(fd_test)
print("result = ", test_svm[0])
新建一个presentation演示一下
按下p开始预测。
界面设计
依然是熟悉的pyqt5,本来想用designer的,但是想想还是麻烦,就也在原大神的代码上改动精简了一下下,变得我觉得稍微美观实用了点。
原作者没加镜像并且摄像头的范围直接拿roi的,会出现找不到手的情况。
我改过之后也只是稍稍强一点,实际问题还是很多,就不献丑了。
后语
复现原作者的这个小项目大概花了快一周吧。每天就搞一小会时间也不是很够,其中不乏漏洞和错误,还请各位大佬手下留情。
我将原作者中部分过时代码删去,重构了部分内容,也去掉了作者用椭圆傅里叶算子的部分内容,精简了代码量,让主体部分更加清晰。同时我也把自己的理解和补充写下来充实注释,也算是方便有需要的人。
整个项目内容的精华和脉络,以及相关心得我都已经无偿发文记录下来,也已经展示了绝大部分代码,相信对大部分人来说已经足够。