论文速看 Few-shot Image Generation via Cross-domain Correspondence
Few-shot Image Generation via Cross-domain Correspondence

Paper link: link
Github link: link
文章目录
- Few-shot Image Generation via Cross-domain Correspondence
-
-
- Abstract
- Thoughts
- Related Papers
-
- Few-shot learning
- Distance preservarion
- Questions
- What I get?
- Method
-
- Cross-domain distance consistency
- Relaxed realism with few examples
- Final Objective
- Experiments
- Ablations
- Analyzing source ↔ \leftrightarrow ↔ target correspondence
-
- Related source/target domains
- Unrelated source/target domains
- Quantitative analysis of source/target relevance
- Effect of target dataset size
- Conclusion and limitations
- do not know
- Words
- Paper Index
-
Abstract
In this work, we seek to utilize a large source domain for pretraining and transfer the diversity information from source to target.
We propose to preserve the relative similarities and differences between instances in the source via a novel cross-domain distance consistency loss.
To further reduce overfitting, we present an anchor-based strategy to encourage different levels of realism over different regions in the latent space.

Thoughts
In this work, we explore transferring a different kind of information from the source domain, namely how images relate to each other, to address the limited data setting. Intuitively, if the model can preserve the relative similarities and differences between instances in the source domain, then it has the chance to inherit the diversity in the source domain while adapting to the target domain.
We apply an image-level adversarial loss on the synthesized images which should map to one of the real samples. For all other synthesized images, we only enforce a patch-level adversarial loss. In this way, only a small subset of our generated samples(but which subset) need to look like one of the few-shot training images, while the rest are only forced to capture their patch-level texture.
Related Papers
Few-shot learning
Few-shot image generation aims instead to hallucinate new and diverse examples while preventing overfitting to the few training images. Existing work mainly follows an adaptation pipeline, in which a base model is pretrained on a large source domain and then adapted to a smaller target domain. They either embed a small number of new parameters into the source model [23, 32] or directly update the source model parameters, using different forms of regularization[20, 16]. Others employ data augmentation to reduce overfitting [39, 11] but are less effective under the extreme few-shot setting (e.g., 10 images).
[23] Atsuhiro Noguchi and Tatsuya Harada. Image generation from small datasets via batch statistics adaptation. In Int. Conf. Comput. Vis., 2019.
[32] Yaxing Wang, Abel Gonzalez-Garcia, David Berga, Luis Herranz, Fahad Shahbaz Khan, and Joost van de Weijer. Minegan: effective knowledge transfer from gans to target domains with few images. In IEEE Conf. Comput. Vis. Pattern Recog., 2020.
[20] Sangwoo Mo, Minsu Cho, and Jinwoo Shin. Freeze discriminator:A simple baseline for fine-tuning gans. arXiv preprint arXiv:2002.10964, 2020.
[16] Yijun Li, Richard Zhang, Jingwan Lu, and Eli Shechtman.Few-shot image generation with elastic weight consolidation.In Advances in Neural Information Processing Systems,2020.
[39] Shengyu Zhao, Zhijian Liu, Ji Lin, Jun-Yan Zhu, and Song Han. Differentiable augmentation for data-efficient gan training. arXiv preprint arXiv:2006.10738, 2020.
[11] Tero Karras, Miika Aittala, Janne Hellsten, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Training generative adversarial networks with limited data. In Adv. Neural Inform.Process. Syst., 2020.
Distance preservarion
To alleviate mode collapse in GANs, DistanceGAN [2] proposes to preserve the distances between input pairs in the corresponding generated output pairs. A similar scheme has been employed for both unconditional [27, 18] and conditional [19, 35] generation tasks to increase diversity in the generations.
[2] Sagie Benaim and Lior Wolf. One-sided unsupervised domainmapping. In Adv. Neural Inform. Process. Syst., 2017.
[27] Ngoc-Trung Tran, Tuan-Anh Bui, and Ngai-Man Cheung.Dist-gan: An improved gan using distance constraints. In Proceedings of the European Conference on Computer Vision (ECCV), 2018.
[18] Shaohui Liu, Xiao Zhang, Jianqiao Wangni, and Jianbo Shi. Normalized diversification. In IEEE Conf. Comput. Vis. Pattern Recog., 2019.
Questions
- N=?
- how to define the “anchor regions” with the small real datasets?
- how patch discriminator works?
What I get?
- this cross-domain distance consistency may can be used with w vectors or just like the paper to overcome overfit.
- we see how crazy the ability source domain model have to translate to other domains, and the different effects we get when the relevance differs.
- The idea of using target pics and LPIPS distance to evaluate the diversity.
- we see the method doesn’t work at all when 1-shot.
Method
Previous work [34] shows that this works well when the target dataset size exceeds 1000 training samples. However, in the extreme few-shot setting, this method overfits, as the discriminator can memorize the few examples and force the generator to reproduce them.

A consequence of overfitting during adaptation is that relative distances in the source domain are not preserved. As seen in Fig. 2, the visual appearance between z1 and z2 collapses, disproportionately relative to z1 and z3, which remain perceptually distinct. We hypothesize that enforcing preservation of relative pairwise distances, before and after adaptation, will help prevent collapse.
Cross-domain distance consistency
1-> To this end, we sample a batch of N + 1 N+1 N+1 (N set to what)noise vectors { z n } 0 N \{{z_n}\}^N_0 {zn}0N, and use their pairwise similarities in feature space to construct N-way probability distributions for each image.he probability distribution for the ith noise vector, for the source and adapted generators is given by,
y i s , l = S o f t m a x ( s i m ( G s l ( z i ) , G s l ( z j ) ) ∀ i ≠ j ) y_i^{s,l} = Softmax({sim(G_s^l(z_i), G_s^l(z_j))}_{\forall i\neq j}) yis,l=Softmax(sim(Gsl(zi),Gsl(zj))∀i=j)
y i s → t , l = S o f t m a x ( s i m ( G s → t l ( z i ) , G s → t l ( z j ) ) ∀ i ≠ j ) y_i^{s\rightarrow t,l} = Softmax({sim(G_{s\rightarrow t}^l(z_i), G_{s\rightarrow t}^l(z_j))}_{\forall i\neq j}) yis→t,l=Softmax(sim(Gs→tl(zi),Gs→tl(zj))∀i=j)
where sim denotes the cosine similarity between generator activations at the lth layer.
2-> We encourage the adapted model to have similar distributions to the source, across layers and image instances by using KL-divergence:
L d i s t ( G s → t , G s ) = E z i ∼ p z ( z ) ∑ l , i D K L ( y i s → t , l ∣ ∣ y i s , l ) L_{dist}(G_{s\rightarrow t, G_s}) = E_{z_{i}\thicksim p_z(z)}\sum_{l,i}D_{KL}(y_i^{s\rightarrow t,l}||y_i^{s,l}) Ldist(Gs→t,Gs)=Ezi∼pz(z)l,i∑DKL(yis→t,l∣∣yis,l)

Relaxed realism with few examples
With a very small target data size, the definition of what constitutes a “realistic” sample becomes increasingly overconstrained, as the discriminator can simply memorize the few-shot target training set.
We define “anchor” regions(how), Z a n c h ⊂ Z Z_{anch}\subset Z Zanch⊂Z , which form a subset of the entire latent space. When sampled from these regions, we use a full image discriminator D i m g D_{img} Dimg. Outside of them, we enforce adversarial loss using a patch-level discriminator D p a t c h D_{patch} Dpatch,
L a d v ′ ( G , D i m g , D p a t c h ) = E x ∼ D t [ E z ∼ Z a n c h L a d v ( G , D i m g ) + E z ∼ p z ( z ) L a d v ( G , D p a t c h ) ] L'_{adv}(G,D_{img},D{patch})=E_{x\thicksim D_{t}}[E_{z\thicksim Zanch}L_{adv}(G,D_{img})+E_{z\thicksim p_z(z)}L_{adv}(G,D_{patch})] Ladv′(G,Dimg,Dpatch)=Ex∼Dt[Ez∼ZanchLadv(G,Dimg)+Ez∼pz(z)Ladv(G,Dpatch)]
To define the anchor space, we select k random points(what), corresponding to the number of training images, and save them. We sample from these fixed points, with a small added Gaussian noise ( σ = . 05 ) (\sigma = .05) (σ=.05). We use shared weights between the two discriminators by defining D p a t c h D_{patch} Dpatch as a subset of the larger D i m g {D_img} Dimg network [9, 40];using internal activations correspond to patches on the input.The size depends on the network architecture and layer. We read off a set of layers, with effective patch size ranging from 22 × 22 22 \times 22 22×22 to 61 × 61 61\times61 61×61.
Final Objective
Our final objective consists of just these two terms: L a d v ′ L'_{adv} Ladv′for the appearance of the target and L_{dist}, which directly leverages the source model to preserve structural diversity:
G s → t ∗ = arg m i n G m a x D i m g , D p a t c h L a d v ′ ( G , D i m g , D p a t c h ) + λ L d i s t ( G , G s ) G^{*}_{s\rightarrow t} = \arg \mathop{min} \limits _G \mathop{max}\limits_{D_{img},D_{patch}}L'_{adv}(G,D_{img},D_{patch})+\lambda L_{dist}(G,G_s) Gs→t∗=argGminDimg,DpatchmaxLadv′(G,Dimg,Dpatch)+λLdist(G,Gs)
The patch discriminator gives the generator some additional freedom on the structure of the image. The adapted generator is directly incentivized to borrow the domain structure from the source generator, due to the cross-domain consistency loss. As shown in the top and bottom rows in Fig. 2, the model indeed discovers cross-domain correspondences between source and target domains.
Experiments
Baselines: We compare to baselines, which similar to ours, adapt a pre-trained source model to a target domain with limited data. (i) Transferring GANs (TGAN) [34]: finetunes a pre-trained source model to a target domain with the same objective used to train the source model; (ii) Batch Statistics Adaptation (BSA) [23]: only adapts the scale and shift parameters of the model’s intermediate layers; (iii) MineGAN [32]: for a given pre-trained source (e.g. MNIST 0-8) and target (e.g. 9) domain, it transforms the original latent space of source to a space more relevant for the target (e.g. mapping all 0-8 regions to 4, being more similar to 9);(iv) Freeze-D [20]: freezes the high resolution discriminator layers during adaptation; (v) Non-leaking data augmentations[11, 39]: uses adaptive data augmentations (TGAN+ ADA) in a way that does not leak into the generated results; (vi) EWC [16]: extends the idea of Elastic Weight Consolidation [15] for adapting a source model to a target domain, by penalizing large changes to important weights (estimated via Fisher information) in the source model.
 For domains with limited data, however, the FID score would not reflect the overfitting problem.
For domains with limited data, however, the FID score would not reflect the overfitting problem.
Ideally, we wish to assess the number of visually distinct images an algorithm can generate. In the worst case, the algorithm will simply overfit to the original k training images. To capture this, we first generate 1000 images and assign them to one of the k training images, by using lowest LPIPS distance [38]. We then compute the average pairwise LPIPS distance within members of the same cluster and then average over the k clusters. A method that reproduces the original images exactly will have a score of zero by this metric.
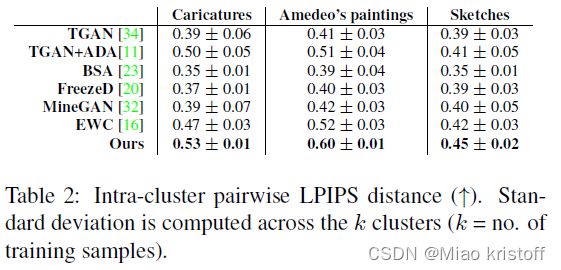
Ablations

We use caricature as the target domain, and first study the effect of our framework with and without L d i s t L_{dist} Ldist;We see that leaving out L d i s t L_{dist} Ldist reduces diversity among the generations, all of which have very similar head structure and hair style. We next study the different ways we enforce realism. What happens if we keep L d i s t L_{dist} Ldist, but use image-level adversarial loss through D i m g D_{img} Dimg on all generations? ‘Ours w/ only D i m g D_{img} Dimg’ results reveal the problem of mode collapse at the part level (same blue hat appears in multiple generations) and the phenomenon where some results are only slight modifications of the same mode (same girl with and without the blue hat). Could we then only use D p a t c h D_{patch} Dpatch to enforce patch-level realism on all generations? ‘Ours w/ only D p a t c h D_{patch} Dpatch’ shows the results, where we observe more diversity, but poorer quality compared to ‘Ours w/ only D i m g D_{img} Dimg’. This is because the discriminator never gets to see a complete caricature image, and consequently does not learn the part-level relations which makes a caricature look realistic. ‘Ours’ combines all the ideas, resulting in generations which are diverse and realistic at both the part and image level.
Analyzing source ↔ \leftrightarrow ↔ target correspondence
Related source/target domains
Unrelated source/target domains


Quantitative analysis of source/target relevance
We translate four source models to four target domains: caricatures, haunted houses, landscape drawings, and abandoned cars. We then test how well a translated model can embed an unseen image from the respective target domain E.g.,after translating the four source models to the caricature domain,
we use a new caricature and embed it into the four models using Image2StyleGAN [1].

Effect of target dataset size

Conclusion and limitations
These show that there is a need for discovering better correspondence between the source and target domains, which will lead to more diverse generations.
do not know
LPIPS distance [38].
Words
caricatures漫画
inordinately过度的
non-saturating非饱和的
disproportionately不成比例地
Paper Index
[1] Rameen Abdal, Yipeng Qin, and Peter Wonka. Image2stylegan: How to embed images into the stylegan latent space? In Int. Conf. Comput. Vis., 2019.
[38] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In IEEE Conf. Comput. Vis. Pattern Recog., 2018.